
 |  |
Chapter 9. HTML Processing with Trees
Treating HTML as a stream of tokens is an imperfect solution to the problem of extracting information from HTML. In particular, the token model obscures the hierarchical nature of markup. Nested structures such as lists within lists or tables within tables are difficult to process as just tokens. Such structures are best represented as trees, and the HTML::Element class does just this.
This chapter teaches you how to use the HTML::TreeBuilder module to construct trees from HTML, and how to process those trees to extract information. Chapter 10, "Modifying HTML with Trees" shows how to modify HTML using trees.
9.1. Introduction to Trees
The HTML in Example 9-1 can be represented by the tree in Figure 9-1.
Example 9-1. Simple HTML
<ul> <li>Ice cream.</li> <li>Whipped cream. <li>Hot apple pie <br>(mmm pie)</li> </ul>
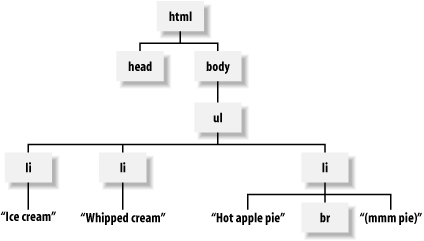
Figure 9-1. HTML tree
In the language of trees, each part of the tree (such as html, li, Ice cream., and br) is a node. There are two kinds of nodes in an HTML tree: text nodes,which are strings with no tags, and elements, which symbolize not mere strings, but things that can have attributes (such as align=left), and which generally came from an open tag (such as <li>), and were possibly closed by an end-tag (such as </li>).
When several nodes are contained by another, as the li elements are contained by the ul element, the contained ones are called children. Children of the same element are called siblings. For example, head and body are siblings, as they are both children of the html element. Text nodes can't have children; only elements can have children.
Example 9-1 shows the difference between a tag and an element. A tag is a piece of markup source, such as the string <li>. An element is a feature of the tree that you get by parsing the source that contains tags. The relationship between the two isn't always easy to figure out by just looking at the source, because HTML lets you omit closing tags (such as </li>) and in some cases omit entire groups of tags (such as <html><head></head><body>...</body></html>, as were omitted above but showed up in the tree anyway). This is unlike XML, where there are exactly as many elements in the tree as there are <foo>...</foo> tag pairs in the source.
Trees let you work with elements and ignore the way the HTML was marked up. If you're processing the tree shown in Figure 9-1, you don't need to worry about whether the </li> tag was or was not present.
In LWP, each element in a tree is an HTML::Element object. The HTML::TreeBuilder module parses HTML and constructs a tree for you. The parsing options in a given HTML::TreeBuilder object control the nature of the final tree (for example, whether comments are ignored or represented in the tree). Once you have a tree, you can call methods on it that search for bits of content and emit parts of it as HTML or text. In the next chapter, we even see how to move nodes around within the tree, and from tree to tree.
|  | |
| 8.7. Alternatives |  | 9.2. HTML::TreeBuilder |

Copyright © 2002 O'Reilly & Associates. All rights reserved.