
 |  |
8.2. Getting the Data
The first step is to figure out what web pages we need to request to get the data in any form. With the BBC extractor, it was just a matter of requesting the single page http://news.bbc.co.uk, but here there's no one page that lists all the data we want. Instead, you can view the program description for each show, one day at a time. Moreover, the URL for each such page looks like this, which displays the program info for July 2, 2001:
http://freshair.npr.org/dayFA.cfm?todayDate=07%2F02%2F2001
It's relatively clear that the format for the bit after the equal sign is the two-digit month, %2F, the two-digit day, %2F, and the four-digit year. (It's even more clear when you consider that %2F is the / character encoded, so that the above means 07/02/2001.) Harvesting all the data is a simple matter of iterating over all the days of the month (or whatever period you want to cover), skipping weekends (because the program listings are only for weekdays), substituting the proper date numbers into that URL. Once each page is harvested, the data can be extracted from it.
Already the outlines of the program's design are becoming clear: there needs to be a loop that harvests the contents of a URL based on each date, then scans the returned content. Scanning the content isn't a distinct enough task that it has to be part of the same block of code as the code that actual harvests the URL. Instead, it can simply be a routine that is given a new stream from which it is expected to extract data. Moreover, that is the hard part of the program, so we might as well do that first (the stuff with date handling and URL interpolation is much less worrisome, and can be put off until last).
So, to figure out the format of the data we want to harvest, consider a typical program listing page in its rendered form in a browser. We establish that this is a "typical" page (shown in Figure 8-1) by flipping through the listings and finding that they all pretty much look like that. (That stands to reason, as the URL tells us that they're being served dynamically, and all through the same .cfm—Cold Fusion—file, such that having each day's bit of content poured into a common template is the easy way for the web site's designers to have implemented this.) So we have good reason to hope that whatever code we work up to extract successfully from one typical page, would hopefully work for all of them. The only remarkable difference is in the number of segments per show: here there's two, but there could be one, or four, or even more. Also, the descriptions can be several paragraphs, sometimes much shorter.
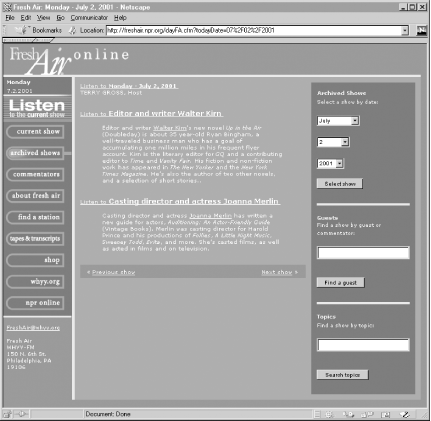
Figure 8-1. Fresh Air web page
What we want to extract here is the link text that says "Monday - July 2, 2001," "Editor and writer Walter Kirn," and "Casting director and actress Joanna Merlin," and for each we also want the link URL as an absolute URL. We don't want the "Listen to" part, since it'd be pointlessly repetitive to have a whole month's worth of listings where every line starts with "Listen to".
|  | |
| 8. Tokenizing Walkthrough |  | 8.3. Inspecting the HTML |

Copyright © 2002 O'Reilly & Associates. All rights reserved.