
 |  |
5.6. POST Example: ABEBooks.com
ABEBooks.com is a
web site that allows users to search
the database of the books for sale at hundreds of used bookstores
mostly in the U.S. and Canada. An eagle-eyed user can find anything
from a $2 used copy of Swahili for Travellers,
to an  11,000 complete set of the 1777 edition of Diderot's Encyclopédie. The trick, as with any kind of bargain hunting, is to always keep looking, because one never knows when something new and interesting will arrive. The manual way of doing this is to fastidiously keep a list of titles, authors, and subjects for which you're keeping an eye out, and to routinely visit the ABEBooks site, key in each of your searches into the HTML search form, and look for anything new. However, this is precisely the kind of drudgery that computers were meant to do for us; so we'll now consider how to automate that task.
11,000 complete set of the 1777 edition of Diderot's Encyclopédie. The trick, as with any kind of bargain hunting, is to always keep looking, because one never knows when something new and interesting will arrive. The manual way of doing this is to fastidiously keep a list of titles, authors, and subjects for which you're keeping an eye out, and to routinely visit the ABEBooks site, key in each of your searches into the HTML search form, and look for anything new. However, this is precisely the kind of drudgery that computers were meant to do for us; so we'll now consider how to automate that task.
As with the license plate form in the previous section, the first step in automating form submission is to understand the form in question. ABEBooks's "Advanced Search" system consists of one form, which is shown in Figure 5-3.
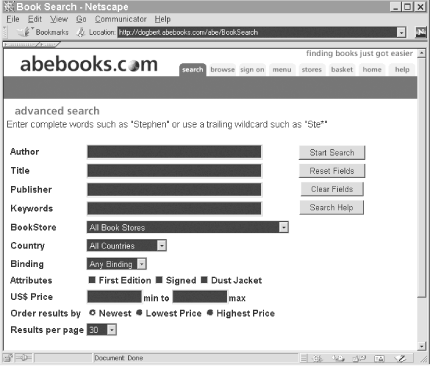
Figure 5-3. ABEBooks query form
The process of searching with this form is just a matter of filling in the applicable fields and hitting "Start Search"; the web site then returns a web page listing the results. For example, entering "Codex Seraphinianus" in the "Title" field returns the web page shown in Figure 5-4.
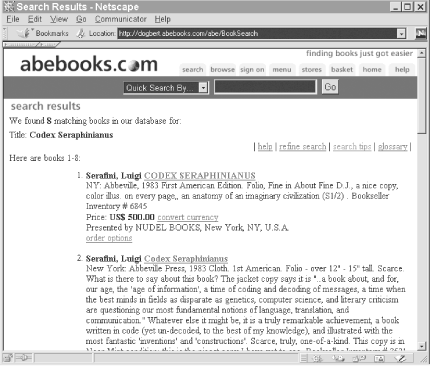
Figure 5-4. ABEBooks results page
5.6.1. The Form
In the previous section, the form's source was simple enough that we could tell at a glance what form pairs it would produce, and our use of formpairs.pl merely confirmed that we understood it. However, this ABEBooks form is obviously much more complex, so let's start with using formpairs.pl and look to the details of the form source only as necessary. Save a local copy of the form and change its form action attribute from this:
<FORM ACTION="BookSearch" METHOD=post>
to this:
<FORM ACTION="http://someserver.int/cgi-bin/formpairs.pl" METHOD=post>
or to whatever URL you've put a copy of formpairs.pl at. If you then open that newly altered HTML file in a browser, fill in "Codex Seraphinianus" in the "Title" blank, set "Order results by" to "Newest," set "Results per page" to "100," and hit "Start Search," our formpairs.pl program shows the form pairs that the browser sends:
POST data: ( "ph" => "2", "an" => "", "tn" => "Codex Seraphinianus", "pn" => "", "sn" => "", "gpnm" => "ALL", "cty" => "", "bi" => "", "prl" => "", "prh" => "", "sortby" => "0", "ds" => "30", "bu" => "Start Search", )
5.6.2. Translating This into LWP
These form pairs can be pasted into a simple program for saving the result of that search, using a call to $browser->post(url, pairs_arrayref) such as you'll recognize from the previous section. Example 5-4 demonstrates.
Example 5-4. seraph.pl
#!/usr/bin/perl -w
# seraph.pl - search for Codex Seraphinianus on abebooks
use strict;
my $out_file = "result_seraph.html"; # where to save it
use LWP;
my $browser = LWP::UserAgent->new;
my $response = $browser->post(
'http://dogbert.abebooks.com/abe/BookSearch',
# That's the URL that the real form submits to.
[
"ph" => "2",
"an" => "",
"tn" => "Codex Seraphinianus",
"pn" => "",
"sn" => "",
"gpnm" => "All Book Stores",
"cty" => "All Countries",
"bi" => "Any Binding",
"prl" => "",
"prh" => "",
"sortby" => "0",
"ds" => "100",
"bu" => "Start Search",
]
);
die "Error: ", $response->status_line, "\n"
unless $response->is_success;
open(OUT, ">$out_file") || die "Can't write-open $out_file: $!";
binmode(OUT);
print OUT $response->content;
close(OUT);
print "Bytes saved: ", -s $out_file, " in $out_file\n";When run, this program successfully saves to result_seraph.html all the HTML that results from running a 100-newest-items search on the title "Codex Seraphinianus".
5.6.3. Adding Features
A little more experimentation with the form would show that a search on an author's name, instead of the title name, shows up in the an=author_name form pair, instead of the tn=title_name form pair. That is what we see if we go sifting through the HTML source to the search form:
... <TR><TH ALIGN=LEFT>Author</TH> <TD><INPUT TYPE=text NAME=an VALUE="" SIZE=35 MAXLENGTH=254></TD></TR> <TR><TH ALIGN=LEFT>Title</TH> <TD><INPUT TYPE=text NAME=tn VALUE="" SIZE=35 MAXLENGTH=254></TD></TR> ...
We could alter our program to set the form pairs with something like this:
... "an" => $author || "", "tn" => $title || "", ...
Moreover, if we wanted to allow the search to specify that only first editions should be shown, some experimentation with formpairs.pl and our local copy of the form shows that checking the "First Edition" checkbox produces a new form pair fe=on, between the bi= and prl= pairs, where previously there was nothing. This jibes with the HTML source code:
<INPUT TYPE=CHECKBOX NAME=fe><B>First Edition</B>
This could be modeled in our program with a variable $first_edition, which, if set to a true value, produces that form pair; otherwise, it produces nothing:
...
"bi" => "",
$first_edition ? ("fe" => "on") : ( ),
"prl" => "",
...This can all be bundled up in a single routine that runs a search based on three given parameters: author, title, and whether only first editions should be shown:
sub run_search {
my($author, $title, $first_edition) = @_;
my $response = $browser->post(
'http://dogbert.abebooks.com/abe/BookSearch',
[
"ph" => "2",
"an" => $author || "",
"tn" => $title || "",
"pn" => "",
"sn" => "",
"gpnm" => "All Book Stores",
"cty" => "All Countries",
"bi" => "Any Binding",
$first_edition ? ("fe" => "on") : ( ),
"prl" => "",
"prh" => "",
"sortby" => "0",
"ds" => "100",
"bu" => "Start Search",
]
);
return $response;
}That run_search( ) routine takes all we know about how any new-books query to ABEBooks needs to be performed and puts it all in a single place. From here, we need only apply initialization code and code to call the run_search routine, and do whatever needs doing with it:
use strict;
use LWP;
my $browser = LWP::UserAgent->new;
do_stuff( );
sub do_stuff {
my $response = run_search( # author, title, first edition
'', 'Codex Seraphinianus', ''
);
process_search($response, 'result_seraph.html');
}
sub process_search {
my($response, $out_file) = @_;
die "Error: ", $response->status_line, "\n"
unless $response->is_success;
open(OUT, ">$out_file") || die "Can't write-open $out_file: $!";
binmode(OUT);
print OUT $response->content;
close(OUT);
print "Bytes saved: ", -s $out_file, " in $out_file\n";
return;
}5.6.4. Generalizing the Program
This program still just runs an ABEBooks search for books with the title "Codex Seraphinianus", and saves the results to result_seraph.html. But the benefit of reshuffling the code as we did is that now, by just changing do_stuff slightly, we change our program from being dedicated to running one search, to being a generic tool for running any number of searches:
my @searches = ( # outfile, author, title, first_edition
['result_seraph.html', '', 'Codex Seraphinianus', ''],
['result_vidal_1green.html', 'Gore Vidal', 'Dark Green Bright Red', 1],
['result_marchand.html', 'Hans Marchand', 'Categories', ''],
['result_origins.html', 'Eric Partridge', 'Origins', ''],
['result_navajo.html', '', 'Navajo', ''],
['result_navaho.html', '', 'Navaho', ''],
['result_iroq.html', '', 'Iroquois', ''],
['result_tibetan.html', '', 'Tibetan', ''],
);
do_stuff( );
sub do_stuff {
foreach my $search (@searches) {
my $out_file = shift @$search;
my $resp = run_search(@$search);
sleep 3; # Don't rudely query the ABEbooks server too fast!
process_search($resp, $out_file);
}
}Running this program saves each of those searches in turn:
% perl -w abesearch03.pl Bytes saved: 15452 in result_seraph.html Bytes saved: 57693 in result_vidal_1green.html Bytes saved: 8009 in result_marchand.html Bytes saved: 25322 in result_origins.html Bytes saved: 125337 in result_navajo.html Bytes saved: 128665 in result_navaho.html Bytes saved: 127475 in result_iroq.html Bytes saved: 130941 in result_tibetan.html
The user can then open each file and skim it for interesting new titles. Each book listed there comes with a working absolute URL to a book detail page on the ABEBooks server, which can be used for buying the book. For some of the queries that generate large numbers of results, it would be particularly convenient to have do_stuff( ) actually track which books it has seen before (using the book-detail URL of each) and report only on new ones:
my $is_first_time;
my (%seen_last_time, %seen_this_time, @new_urls);
sub do_stuff {
if (-e 'seen_last_time.dat') {
# Get URLs seen last time.
open(LAST_TIME, "<seen_last_time.dat") || die $!;
while (<LAST_TIME>) { chomp; $seen_last_time{$_} = 1 };
close(LAST_TIME);
} else {
$is_first_time = 1;
}
foreach my $search (@searches) {
my $out_file = shift @$search;
my $resp = run_search(@$search);
process_search($resp, $out_file);
foreach my $url ($resp->content =~
# Extract URLs of book-detail pages:
m{"(http://dogbert.abebooks.com/abe/BookDetails\?bi=[^\s\"]+)"}g
){
push @new_urls, $url unless $seen_last_time{$url}
or $seen_this_time{$url};
$seen_this_time{$url} = 1;
}
}
# Save URLs for comparison next time.
open(LAST_TIME, ">seen_last_time.dat") || die $!;
for (keys %seen_this_time) { print LAST_TIME $_, "\n" }
close(LAST_TIME);
if($is_first_time) {
print "(This was the first time this program was run.)\n";
} elsif (@new_urls) {
print "\nURLs of new books:\n";
for (@new_urls) { print $_, "\n" }
} else {
print "No new books to report.\n";
}
}A typical run of this will produce output as above, but with this addendum:
URLs of new books: http://dogbert.abebooks.com/abe/BookDetails?bi=24017010 http://dogbert.abebooks.com/abe/BookDetails?bi=4766571 http://dogbert.abebooks.com/abe/BookDetails?bi=110543730 http://dogbert.abebooks.com/abe/BookDetails?bi=58703369 http://dogbert.abebooks.com/abe/BookDetails?bi=93298753 http://dogbert.abebooks.com/abe/BookDetails?bi=93204427 http://dogbert.abebooks.com/abe/BookDetails?bi=24086008
|  | |
| 5.5. POST Example: License Plates |  | 5.7. File Uploads |

Copyright © 2002 O'Reilly & Associates. All rights reserved.