
Chapter 5. Hashes
In this chapter, we will see one of Perl's features that makes Perl one of the world's truly great programming languages -- hashes.[121] Although hashes are a powerful and useful feature, you may have used other powerful languages for years without ever hearing of hashes. But you'll use hashes in nearly every Perl program you'll write from now on; they're that important.
[121]In the olden days, we called these "associative arrays." But the Perl community decided in about 1995 this was too many letters to type and too many syllables to say, so we changed the name to "hashes."
5.1. What Is a Hash?
A hash is a data structure, not unlike an array in that it can hold any number of values and retrieve them at will. But instead of indexing the values by number, as we did with arrays, we'll look up the values by name. That is, the indices (here, we'll call them keys ) aren't numbers, but instead they are arbitrary unique strings (see Figure 5-1).
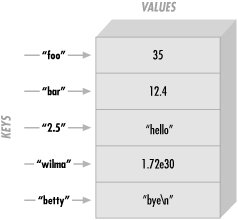
Figure 5-1. Hash keys and values
The keys are strings, first of all, so instead of getting element number 3 from an array, we'll be accessing the hash element named wilma.
These keys are arbitrary strings -- you can use any string expression for a hash key. And they are unique strings -- just as there's only one array element numbered 3, there's only one hash element named wilma.
Another way to think of a hash is that it's like a barrel of data, where each piece of data has a tag attached. You can reach into the barrel and pull out any tag and see what piece of data is attached. But there's no "first" item in the barrel; it's just a jumble. In an array, we'd start with element 0, then element 1, then element 2, and so on. But in a hash, there's no fixed order, no first element. It's just a collection of key-value pairs.
The keys and values are both arbitrary scalars, but the keys are always converted to strings. So, if you used the numeric expression 50/20 as the key,[122] it would be turned into the three-character string "2.5", which is one of the keys shown in the diagram above.
[122]That's a numeric expression, not the five-character string "50/20". If we used that five-character string as a hash key, it would stay the same five-character string, of course.
As usual, Perl's no-unnecessary-limits philosophy applies: a hash may be of any size, from an empty hash with zero key-value pairs, up to whatever fills up your memory.
Some implementations of hashes (such as in the original awk language, from where Larry borrowed the idea) slow down as the hashes get larger and larger. This is not the case in Perl -- it has a good, efficient, scalable algorithm.[123] So, if a hash has only three key-value pairs, it's very quick to "reach into the barrel" and pull out any one of those. If the hash has three million key-value pairs, it should be just about as quick to pull out any one of those. A big hash is nothing to fear.
[123]Technically, Perl rebuilds the hash table as needed for larger hashes. In fact, the term "hashes" comes from the fact that a hash table is used for implementing them.
It's worth mentioning again that the keys are always unique, although the values may be duplicated. The values of a hash may be all numbers, all strings, undef values, or a mixture.[124] But the keys are all arbitrary, unique strings.
[124]Or, in fact, any scalar values, including other scalar types than the ones we'll see in this book.
5.1.1. Why Use a Hash?
When you first hear about hashes, especially if you've lived a long and productive life as a programmer using other languages that don't have hashes, you may wonder why anyone would want one of these strange beasts. Well, the general idea is that you'll have one set of data "related to" another set of data. For example, here are some hashes you might find in typical applications of Perl:
- Given name, family name
- The given name (first name) is the key, and the family name is the value. This requires unique given names, of course; if there were two people named randal, this wouldn't work. With this hash, you can look up anyone's given name, and find the corresponding family name. If you use the key tom, you get the value phoenix.
- Host name, IP address
- You may know that each computer on the Internet has both a host name (like www.stonehenge.com) and an IP address number (like 123.45.67.89). That's because machines like working with the numbers, but we humans have an easier time remembering the names. The host names are unique strings, so they can be used to make this hash. With this hash, you could look up a host name and find the corresponding IP address number.
- IP address, host name
- Or you could go in the opposite direction. We generally think of the IP address as a number, but it can also be a unique string, so it's suitable for use as a hash key. In this hash, we can look up the IP address number to determine the corresponding host name. Note that this is not the same hash as the previous example: hashes are a one-way street, running from key to value; there's no way to look up a value in a hash and find the corresponding key! So these two are a pair of hashes, one for storing IP addresses, one for host names. It's easy enough to create one of these given the other, though, as we'll see below.
- Word, count of number of times that word appears[125]
- The idea here is that you want to know how often each word appears in a given document. Perhaps you're building an index to a number of documents, so that when a user searches for fred, you'll know that a certain document mentions fred five times, another mentions fred seven times, and yet another doesn't mention fred at all -- so you'll know which documents the user is likely to want. As the index-making program reads through a given document, each time it sees a mention of fred, it adds one to the value filed under the key of fred. That is, if we had seen fred twice already in this document, the value would be 2, but now we'll increment it to 3. If we had never seen fred before, we'd change the value from undef (the implicit, default value) to 1.
- Username, number of disk blocks they are using [wasting]
- System administrators like this one: the usernames on a given system are all unique strings, so they can be used as keys in a hash to look up information about that user.
- Driver's license number, name
- There may be many, many people named John Smith, but we hope that each one has a different driver's license number. That number makes for a unique key, and the person's name is the value.
So, yet another way to think of a hash is as a very simple database, in which just one piece of data may be filed under each key. In fact, if your task description includes phrases like "finding duplicates," "unique," "cross-reference," or "lookup table," it's likely that a hash will be useful in the implementation.
 |  |  |
| 4.12. Exercises |  | 5.2. Hash Element Access |

Copyright © 2002 O'Reilly & Associates. All rights reserved.