
Chapter 7. SQL Database Administration
Contents:
Interacting with an SQL Server from Perl
Using the DBI Framework
Using the ODBC Framework
Server Documentation
Database Logins
Monitoring Server Health
Module Information for This Chapter
References for More Information
What's a chapter on database administration doing in a system administration book? There are three strong reasons for people with interests in Perl and system administration to become database-savvy:
-
A not-so-subtle thread running through several chapters of this book is the increasing importance of databases to modern-day system administration. We've used (albeit simple) databases to keep track of user and machine information; that's just the tip of the iceberg. Mailing lists, password files, and even the Windows NT/2000 registry are all examples of databases you probably see every day. All large-scale system administration packages (e.g., offerings from CA, Tivoli, HP, and Microsoft) are dependent on database backends. If you are planning to do any serious system administration, you are bound to bump into a database eventually.
-
Database administration is a play-within-a-play for system administrators. Database Administrators (DBAs) have to contend with, among other things:
Logins/users
Log files
Storage management (disk space, etc.)
Process management
Connectivity issues
Backup
Security
Sound familiar? We can and should learn from both knowledge domains.
-
Perl is a glue language, arguably one of the best. Much work has gone into Perl/database integration, thanks mostly to the tremendous energy surrounding Web development. We can put this effort to work for us. Though Perl can integrate with several different database formats like Unix DBM, Berkeley DB, etc., we're going to pay attention in this chapter to the Perl's interface with large-scale database products. Other formats are addressed elsewhere in this book.
In order to be a database-literate system administrator, you have to speak a little Structured Query Language (SQL), the lingua franca of most commercial and several noncommercial databases. Writing scripts in Perl for database administration requires some SQL knowledge because these scripts will contain simple embedded SQL statements. See Appendix D, "The Fifteen-Minute SQL Tutorial", for enough SQL to get you started. The examples in this chapter use the same databases in previous chapters to keep us from straying from the system administration realm.
7.1. Interacting with an SQL Server from Perl
There are two standard frameworks for communication with an SQL server: DBI (DataBase Interface) and ODBC (Open DataBase Connectivity). Once upon a time, DBI was the Unix standard and ODBC the Win32 standard, but this distinction has started to blur now that ODBC has become available in the Unix world and DBI has been ported to Win32. Further blurring the lines is the DBD::ODBC package, a DBD module that speaks ODBC from within the DBI framework.[1]
[1]In addition to the standards we are going to discuss, there are some excellent server and OS-specific Perl mechanisms. Sybperl by Michael Peppler for Perl-Sybase communication is one example. Many of these nonstandard mechanisms are also available as DBI-ified modules. For instance, most Sybperl functionality is now available in DBD::Sybase. On Win32 platforms the ActiveX Data Objects (ADO) framework mentioned in the previous chapter is starting to see wider use.
DBI and ODBC are very similar in intent and execution, so we'll show you how to use both simultaneously. Both DBI and ODBC can be thought of as "middleware." They form a layer of abstraction that allows the programmer to write code using generic DBI/ODBC calls, without having to know the specific API of any particular database. It is then up to the DBI/ODBC software to hand these calls off to a database-specific layer. The DBI module calls a DBD driver for this; the ODBC Manager calls the data source-specific ODBC driver. This database-specific driver takes care of the nitty-gritty details necessary for communicating with the server in question. Figure 7-1 shows the DBI and ODBC architectures. In both cases, there is a (at least) three-tiered model:
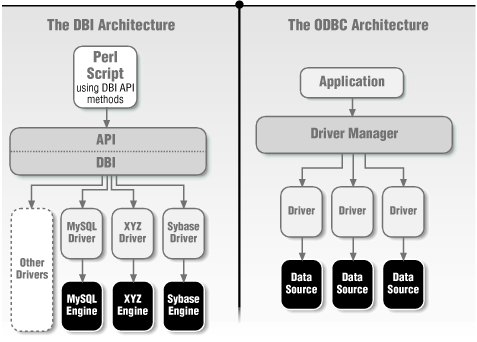
Figure 7.1. DBI and ODBC architectures
-
An underlying database (Oracle, MySQL, Sybase, Microsoft SQL Server, etc.).
-
A database-specific layer that makes the actual server-specific requests to the server on behalf of the programmer. Programmers don't directly communicate with this layer; they use the third tier. In DBI, a specific DBD module handles this layer. When talking with an Oracle database, the DBD::Oracle module would be invoked. DBD modules are usually linked during the building process to a server-specific client library provided by the server vendor. With ODBC, a data-source-specific ODBC driver provided by the vendor handles this layer.
-
A database-independent Application Programming Interface (API) layer. Soon, we'll be writing Perl scripts that will communicate with this layer. In DBI, this is known as the DBI layer (i.e., we'll be making DBI calls). In ODBC, one typically communicates with the ODBC Driver Manager via ODBC API calls.
The beauty of this system is that code written for DBI or ODBC is extremely portable between different servers from different vendors. The API calls made are the same, independent of the underlying database. That's the idea at least, and it holds true for most database programming. Unfortunately, the sort of code we're most likely to write (i.e., database administration) is bound to be server-specific, since virtually no two servers are administered in even a remotely similar fashion.[2] Experienced system administrators love portable solutions, but they don't expect them.
[2]MS-SQL was initially derived from Sybase source code, so it's one of the rare counter-examples.
That somber thought aside, let's look at how to use DBI and ODBC. Both technologies follow the same basic steps, so you may notice a little redundancy in the explanations, or at least in the headings.
The next sections assume you've installed a database server and the necessary Perl modules. For some of our DBI example code, we're going to use the MySQL server; for ODBC, we'll use Microsoft's SQL Server.
 |  |  |
| 6.7. References for More Information |  | 7.2. Using the DBI Framework |

Copyright © 2001 O'Reilly & Associates. All rights reserved.