
20.3 Perl Value Types
In this section, we'll study the functions and macros for manipulating the internal value types. We will also examine each object's internal makeup in sections entitled "Inside SV," "Inside AV," and so on. Although they will help you in making seasoned judgments about memory overhead and performance, you can skip these sections if the detail weighs you down.
20.3.1 Scalar Values
A scalar value (SV) contains the value of the scalar, a reference count, and a bitmask to describe the state of the scalar. The scalar may be an integer value ("IV"), a double ("NV"), a string ("PV" for pointer value), a reference ("RV"), or a special-purpose object ("magical"). We'll discuss magical variables separately.
Table 20.1 shows the functions and macros to create, delete, and modify SVs. They are listed in sv.h and implemented in sv.c . Macros, by convention, have their first letter capitalized. All the tables in this chapter make use of two important typedefs, I32 and U32, which represent signed and unsigned integral quantities that are at least 32 bits wide and big enough to hold a pointer (it will be 64 bits on a 64-bit machine).
|
Function/Macro |
Description |
|---|---|
SV* newSViv(I32);
SV* newSVnv(double);
SV* newSVpv(char* str,
int len);
|
Create a new SV from an integer, double, or string respectively. newSVpv calculates the length of the string if len is 0. |
SV* newSVsv(SV *); |
Create a clone of an existing SV. To create an empty SV, use the global scalar sv_undef , instead of NULL, like this: newSVsv(&sv_undef); This is true of all functions that expect an SV as an argument. |
SV* newSVrv
(SV* rv,
char *pkgname);
|
Creates a new SV and points |
SV *newRV (SV* other) SV* newRV_inc (SV* other) SV* newRV_noinc(SV *) |
Create a reference pointing to any type of value, not just SVs. You can cast other values to an SV*, as will be evident when we examine AVs, HVs, and CVs. newRV_inc increments the reference count of the entity referred to (and is an alias for newRV ). |
SvIOK(SV*), SvNOK(SV*), SvPOK(SV*), SvROK(SV*), SvOK (SV*), SvTRUE(SV*) |
These macros check whether the SV has a value of the corresponding type and, if so, return 1. They do not trigger a conversion. SvOK returns 1 if the value is not undef . SvTRUE returns 1 if the scalar is true. |
IV SvIV(SV*) double SvNV(SV*) char* SvPV(SV*,int len) SV* SvRV(SV*) |
These macros retrieve the values inside an SV and, except for
SvRV
, force an implicit conversion to the appropriate values if necessary.
SvIV
yields 0 if the scalar contains a nonnumeric string.
SvPV
returns a pointer to a string and updates
len
with its length. The scalar owns that string, so don't free it. Before invoking
SvRV
, make sure that it is indeed a reference, using |
sv_setiv (SV*, int)
sv_setnv (SV*, double)
sv_setsv (SV* dest,
SV* src)
|
Modifies an SV's values. The SV automatically gets rid of its old value and morphs to the new type.
sv_setsv
copies the |
sv_setpv (SV*, char *)
sv_setpvn(SV*, char *,
int len
sv_catpv (SV*, char*);
sv_catpvn(SV*, char*,
int);
sv_catsv (SV*, SV*);
|
String functions, which force the scalar to be a string if necessary. sv_setpv assumes a null-terminated string, while sv_setpvn takes the length. Both functions make a copy of the given string. The cat series of functions does string concatenation. |
SVTYPE(SV*) |
Returns an enum value, and is equivalent to the ref function. These are the common values listed in sv.h:
|
sv_setref_iv(
SV* rv,
char* classname,
int i)
(and similarly for nv and pv)
|
Creates a new SV, sets it to the value Note that sv_setref_pv stores the pointer; it does not make a copy of the string.
If |
svREFCNT_dec(SV *) |
Decrements the reference count and calls sv_free if this count is 0. You should never call sv_free yourself. |
SV* sv_bless ( SV *rv, HV* stash); int sv_isa( SV *, char *pkgname); int sv_isobject(SV*); |
sv_bless
blesses |
SV* sv_newmortal() SV* sv_2mortal(SV*) SV* sv_mortalcopy(SV*) |
By default, if you create an SV, you are responsible for deleting it. If you create a mortal or temporary variable, Perl automatically deletes it the end of the current scope (unless someone else holds a reference to it). sv_2mortal tags an existing SV as a mortal, and sv_2mortalcopy creates a mortal clone. |
SV* perl_get_sv(
char* varname,
int create)
|
To get a scalar variable as you are used to seeing in script space, you have to explicitly bind an SV to a name.
SV *s = perl_get_av("Foo::a", 1);
|
sv_dump(SV*) |
The name is a misnomer, since it is capable of pretty-printing the contents of all Perl value types (casting them to SV* if necessary). This is extremely useful if you have Perl under a debugger: for example, inside gdb , use
call sv_dump(sv)
|
The mortal series of calls in Table 20.1 create a temporary SV or tag an existing value as temporary. These calls essentially tell Perl to shove the SV onto a stack called tmps_stack and call svREFCNT_dec on the SV at the end of the current scope. (More on this in the section "Inside Other Stacks .") Typically, all parameters passed between functions are tagged mortal, because neither the caller nor the called function wants to worry about the appropriate time to delete the SV and its contents; Perl automatically takes care of the memory management.
20.3.1.1 Using this API
Perhaps your eyes are somewhat glazed and your mind is numbed, so we will relieve the tedium by writing a custom interpreter using the API we have seen so far. (For now, this is our idea of fun!) Example 20.2 shows a function called create_envt_vars that creates a scalar variable for every environment variable.
Example 20.2: Creating Scalars for Environment Variables - the Hard Way!
#include <EXTERN.h>
#include <perl.h>
void create_envt_vars (char **environ)
{
/*
* Each element in environ is in the form <envt. var name>=<value>"
*/
SV * sv = NULL;
char **env = environ; /* for iterating through environ */
char buf[1000]; /* will contain a copy of an envt variable */
char *envt_var_name; /* Name of the envt. variable, like PATH */
char *envt_var_value; /* Its corresponding value */
char var_name[100]; /* Fully qualified name of environment var */
while (*env) {
strcpy (buf, *env);
/* Search for "=", replace it with '\0', thus splitting it into
* logical parts - envt variable name and the value
*/
envt_var_name = buf; envt_var_value = buf;
while (*envt_var_value != '=') envt_var_value++;
*envt_var_value++ = '\0';
/* Qualify the environment var with the package name.
* PATH becomes $main::PATH
*/
strcpy (var_name, "main::"); strcat(var_name, envt_var_name);
sv = perl_get_sv (var_name, TRUE); /* TRUE => Force Create */
/* Set the string value for the sv);
sv_setpv(sv, envt_var_value);
env++; /* On to the next environ variable */
}
}
static PerlInterpreter *my_perl;
main(int argc, char **argv, char **env) {
my_perl = perl_alloc();
perl_construct(my_perl);
perl_parse(my_perl, NULL, argc, argv, env);
create_envt_vars();
perl_run(my_perl);
perl_destruct(my_perl);
perl_free(my_perl);
}
On a DEC Alpha box, you might compile and link it as follows:
% cc -o ex -I/usr/local/lib/perl5/alpha-dec_osf/5.004/CORE \
-L/usr/local/lib/perl5/alpha-dec_osf/5.004/CORE \
ex.c -lperl -lsocket -lm
Now for the big test:
% ./ex -e 'print $USER' sriram
Amazing, it works - try doing that with your regular Perl! Okay, so it's not a big deal, but you are definitely on your way to dirtying your hands more than you thought you could. Or would!
20.3.1.2 Inside SVs
An SV has the potential of being large, to accommodate the worst case of it morphing to any one of its subtypes. To avoid this, Perl keeps track of the information in two parts, as illustrated in Figure 20.3 : a generic structure called " sv ", which contains a bitmask flag, a reference count, and a pointer, sv_any , which refers to a "specific part."
Figure 20.3: An inside view of scalars. Each shaded box represents one SV.
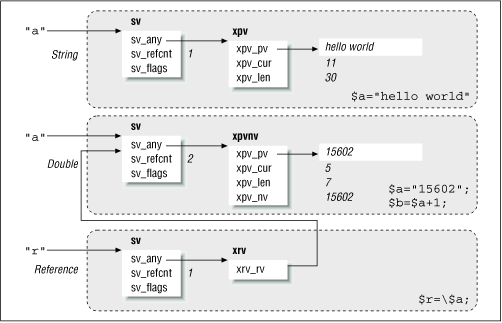
The specific part is a structure of the appropriate type and is one of several structures called xpv , xpviv , xpvnv , and so on, depending on what the bitmask flag says is contained by the scalar. A scalar may start life as a number, but the moment it is used in a string context, it morphs to a structure containing both the number and a string. Figure 20.3 shows an example of the SV (the middle one) containing a double and a string at the same time. If you modify its value with, say, sv_setnv , it sets a bit flag in sv_flags to indicate that the string part of it is not valid any more. Perl doesn't morph a structure unless absolutely necessary.
The Devel::Peek module gives you script-level access to the internal information discussed previously:
use Devel::Peek 'Dump'; # Import the Dump subroutine $a = 15602; Dump ($a);
This outputs
SV = IV(0x663f1c) REFCNT = 1 FLAGS = (IOK,pIOK) IV = 15602
Modify $a to a string and see what happens to it:
use Devel::Peek 'Dump'; $a = 10; # Start off with an integer value $a .= " Ten"; # Convert to a string Dump ($a);
Its output is as follows:
SV = PVIV(0x7b2ef0) REFCNT = 1 FLAGS = (POK,pPOK) IV = 10 PV = 0x7b2f00 "10 Ten" CUR = 6 LEN = 11
Note that the SV still contains the old integer value (10) but that field will be ignored because the
FLAGS
field indicates that only its string contents are valid.
A basic integer value costs you at least 28 bytes on a typical workstation ( sizeof(SV) + sizeof(XPVIV) + malloc overhead). Strings and arrays are more expensive than what you might infer from the length or count alone. The dump above shows that Perl allocated 11 bytes for the string (the xpv_len field) instead of the minimum 6 bytes (the length of the string, as stored in the xpv_cur field); this means that you can append 5 more bytes to the string without triggering a reallocation. Because it is geared for performance and convenience (being able to treat numbers and strings as one entity), it is not frugal with space at all. In fact, Perl applies this strategy of trading off space for performance for practically all data structures.[ 6 ]
[6] One notable exception being hashes, which share their key strings in one string table, thus minimizing space requirements but taking a small hit in performance.
There are no simple xiv or xnv structures that contain just an integer or a floating-point number. I do not know the reason for this, and idly speculate that it's so because a typical script requires numbers to morph into strings (while doing a print , for example) or vice versa (reading from files).
Figure 20.3 also shows the reference counts of the three scalars. The reference count of the middle scalar is 2 because of two arrows pointing to it; the arrows coming from the left imply a symbol table entry (for global and local variables) or a scratchpad for lexical variables, as we saw in Chapter 3 . Note that all pointers to an SV (to any Perl value, actually) refer to the outer structure, never to the "specific" part.
20.3.1.3 SVs and object pointers
As an extension writer, you are often interested in storing a pointer to a C or C++ object returned from an XSUB. Recall that the integer (IV) slot of a scalar is guaranteed to be big enough to hold a pointer. We use this facility as follows:
Matrix *m = new_matrix(); sv_setiv(sv, (IV) m); # Cast pointer to an IV. Ugh!
Crufty, to say the least, but that's the way it is.
In practice, C/C++ objects are always associated with blessed references because it allows the Perl programmer to use the arrow notation ( $matrix->transpose() ). Consider
RV *rv = newRV(); sv_setref_iv(rv, "Matrix", (IV) m);
This creates a new integer SV internally, sets it to the "integer" m , and makes rv point to this freshly allocated SV. It also blesses rv under the module Matrix. This is exactly as if you had said, in Perl space,
my $m = 0xfffa34a; # Some pointer value, converted to an int bless \$m, "Matrix"; # Return a blessed reference to $m.
We will use this snippet when discussing typemaps for objects, in the section "Object Interface Using XS Typemaps ."
20.3.2 Array Values (AV)
An AV is a dynamic, contiguous array of pointers to SVs, and as we are used to seeing in script space, storing a value at an index beyond its current capacity triggers an automatic expansion of the array. Table 20.2 shows the API for manipulating an AV as a whole and for accessing its elements individually. Take note that unless you clear or undef an AV, it does not touch the reference counts of its constituent SVs.
|
Function/Macro |
Description |
|---|---|
AV * newAV()
AV * av_make(int num,
SV **ptr)
|
Creates an empty AV or a clone of another array of SV*. |
I32 av_len(AV*); |
Returns the highest index of the array (such as $#array ). |
SV** av_fetch (AV*,
I32 index,
I32 lval)
|
Retrieves the SV* from the given index. If |
SV** av_store(AV*,
I32 index,
SV* val)
|
Stores an SV* at that index and returns an SV** just like av_fetch . Neither function updates the reference counts of the indexed element. |
void av_clear (AV*) |
Decrements the reference counts of its constituent scalars and replaces those positions with undef . It leaves the array intact. |
void av_undef (AV*) |
Decrements ref counts of all its scalars as well as of the array itself. In the typical case, this function deallocates the array. This is different from SVs in that they are deleted implicitly by decrementing the ref count ( SvREFCNT_dec ). |
void av_extend(AV*,
int num)
|
Extends the array to |
void av_push (AV*, SV*) |
Pushes one SV at the end of an AV. You have to write more code if you want to append an entire list. This and the following functions do not touch the SV's reference count. |
SV* av_pop (AV* ) |
Pops an SV from the end but doesn't touch its reference count, so you must call SvREFCNT_dec or tag it as a temporary variable with sv_2mortal , in which case Perl deletes it at the end of the scope. |
SV* av_shift(AV*) |
Like av_pop but pops an SV from the front of the AV. |
void av_unshift(AV*,
I32 num)
|
Creates |
AV *perl_get_av (
char* varname,
int create)
|
Gets the AV corresponding to |
20.3.2.1 Inside AVs
AVs, like SVs, are split into a generic part and a specific part. As it happens, this is true for the other value types also.
As shown in Figure 20.4 , the xav_alloc field points to a dynamically allocated array of SV*s, the real meat of the AV. av_fill contains the last valid (or filled) index in this array, and av_max contains the total number of SV*s allocated for the array. Perl always strives to make sure it allocates memory in some "reasonable" quantities so that it doesn't have to realloc every time you push an element into this array. xav_array points to the first valid element. It starts off by pointing to xav_alloc[0] , and gets incremented on an unshift to avoid having to move the rest of the elements to the left. In other words, the real contents of the AV are bounded by xav_array and av_fill .
Figure 20.4: AV internal structure. The shaded squares contain real data.
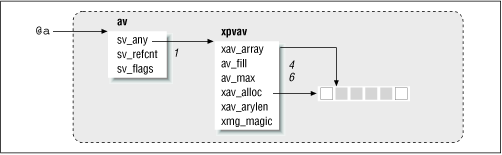
The xmg_magic pointer is typically NULL but refers to a "magic" structure if the array is special (such as @ISA) , represents a blessed object, or is tied to a package.[ 7 ] xav_arylen is an SV* that starts off being NULL but springs into existence as a magical scalar when you use the $# notation on the array (to get or set the array length).
[7] You don't have to understand this paragraph until we have covered magical variables.
Devel::Dump gives you script-level access to the internal details of an array and of all its constituent scalars. Dump expects nonscalar values to be passed by reference:
use Devel::Dump; @l = (1,2,3,4); Dump(\@l); # Pass @l by reference
20.3.3 Hash Values (HVs)
An HV is a table of hash entries (HEs), each representing a pair consisting of a string key and an SV*. No two hash entries in a hash table can have the same key. The API listed in Table 20.3 allows you to act on the HV as a whole, to fetch or store single elements, or to iterate through it one entry at a time.
|
Function/Macro |
Description |
|---|---|
HV * newHV() |
Creates a hash value. |
SV**
hv_store(
HV *hash,
char* key, U32 klen,
SV* val, U32 hash)
|
Stores the key-value pair. It doesn't assume the key is a
text
string, so you
have
to supply the key length,
Like AVs, these functions do not touch the reference count of the value |
SV** hv_fetch( HV *hash, char* key, U32 klen, I32 lval) |
As with AVs, an SV** is returned for efficiency, not for your convenience. When storing an entry, the interpreter has to call hv_fetch to see whether an entry corresponding to that key already exists. If so, it can simply replace the value part of the entry without having to traverse the structure all over again. Typically, you should dereference the result and dispose of the returned SV* (call SvREFCNT_dec ) or arrange to have it disposed of ( sv_2mortal ). |
SV* hv_delete( HV *hash, char* key, U32 klen, I32 flags) |
Deletes an entry and decrements the ref count of the value. If you don't want the deleted value, pass G_DISCARD for the flags; otherwise, it returns a mortal copy of that value. Since the entry is removed from the hash's data structures, it needs to return only an SV*, instead of SV**. |
void hv_clear(HV *hash) |
Equal to %h=() . Like av_clear() , it retains the outer array but gets rid of the hash entries, keys, and values. It also decrements the reference count of each value (not the hash itself). |
void hv_undef(HV *hash) |
Clears the HV and decrements its reference count. |
I32 hv_iterinit(HV *hash) |
Prepares to iterate through its list of entries and returns the number of elements in the HV. hv_iterinit and hv_iternextsv are used by the operators each , keys , and values . |
SV*
hv_iternextsv(
HV *hash,
char** key,
I32* pkeylen)
|
Get the next key and value. The key is returned by reference (along with its length). Unlike hv_fetch() , this function returns only an SV*. This is similar to calling each() . |
HV *
perl_get_hv (
char * varname,
int create)
|
Gets the HV corresponding to varname. Creates the variable if |
The iterating functions (
hv_iter*
) are safe for deletion but not for insertion. That is, you can invoke
hv_delete
on the current entry while iterating on a hash value using
hv_iternextsv
, but you should not call
hv_store
, because that might trigger a complete reorganization of the hash table.
20.3.3.1 Inside HVs
The HV is a straightforward implementation of a hashing technique called collision chaining . The basic idea is to reduce a string key to an integer and use this number as an index into an ordinary dynamic array. Clearly, we cannot expect to reduce all possible string keys to unique array indices, so each element of this dynamic array points instead to a linked list of all hash entries that reduced to that index. Figure 20.5 shows this arrangement.
Figure 20.5: Hash value, containing hash entries
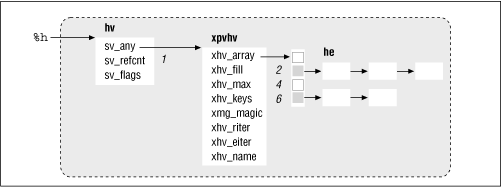
xhv_array is the dynamic array we mentioned above, xhv_fill indicates the number of elements that have linked lists hanging off them, and xhv_keys contains the total number of hash entries. Given a string, hv_fetch() computes the appropriate index and traverses the corresponding linked list, comparing the key to each hash entry's key value.
The translation of a string to an array index is a two-step process (for reasons to be discussed soon). First the string is run through an algorithm called a hash function , which computes an integer from a string without worrying about whether or not that number is practical to use as an array index. Perl's hash function is implemented as follows:
int i = klen;
unsigned int hash = 0;
char *s = key;
while (i--)
hash = hash * 33 + *s++;
The resulting number is known as a hash . There is no guarantee that different strings hash to different hash values. Note that if you have a different hash algorithm, you can compute the hash yourself and supply it to hv_store (refer to Table 20.3 ).
To convert the hash to a practical array index, Perl folds it into the array's maximum size:
index = hash & xhv_max;
Ideally, we want the entries to spread out evenly around the array to keep the linked lists short. Perl's hashing algorithm does this surprisingly well for typical ASCII strings, but as we mentioned earlier, there's no guarantee that a given set of strings disperses well. So if xhv_keys exceeds xhv_fill , Perl takes it as an indication that one or more linked lists are unnecessarily long and that hv_fetch is likely to spend a considerable amount of time traversing these lists. Therefore, when such a condition occurs, Perl immediately reorganizes the hash table: the dynamic array xhv_array is doubled in size, and the entries are reindexed. Each hash entry stores its hash value, so it doesn't have to be hashed again when the table is reorganized.
You can get an idea of the hash efficiency by printing an associative array in a scalar context, as follows:
# Create a hash
for (1 .. 1000) {$h{'foo' . $_} = 1;} # Create 1000 entries
print scalar(%h);
This prints "406/1024" on my machine, which is simply a ratio of xhv_fill and xhv_max . The lower the ratio, the faster the hash access, because, on average, the linked lists are short.
If you know you are going to be performing a large number of insert operations on a hash, you can improve its efficiency in script space by telling it to preallocate a certain-sized dynamic array, like this:
keys %h = 400; # set xhv_max
Perl rounds it up to the next higher power of two: 512.
The xhv_riter and xhv_eiter fields are used by the iterator functions, hv_iterinit and hv_iternextsv , and constitute a cursor over the hash entries. xhv_riter contains the current row index, and xhv_eiter contains the pointer to the current entry.
Most object-oriented Perl implementations use hash tables for storing object attributes, which means that all instances of a given class would typically have the same set of key strings. To prevent unnecessary duplication, the actual key strings are maintained in a systemwide shared string table ( strtab in strtab.h ). strtab is a simplified HV: each value here keeps a reference count of the number of uses of that string. When you say " $h{'foo'} ", the string foo is first entered into strtab if it is not already present. Then the hash entry for $h{foo} is created in the HV for %h . It turns out that performance suffers very little; if there are lots of duplicates, shared storage saves time because the key is malloc 'ed only once. Also, since the hash algorithm needs to be executed only once, the performance is pretty good even when there aren't too many duplicates.
The shared string table is used only for immutable strings (remember that hash key strings cannot be changed). User-defined SVs containing strings do not get to use this table.
20.3.4 Glob Values and Symbol Tables
We saw in Chapter 3 that typeglobs, also known as glob values, or GVs, connect other value types with a symbol table entry. An identifier name, such as "foo", is linked by the GV to $foo , @foo , %foo , &foo , a filehandle called foo , and a format called foo .
GVs and symbol tables work so much in cahoots that all symbol table manipulation code is also lumped into gv.c . Symbol tables are internally implemented as hash tables (HVs) and hence are referred to as stashes (short for symbol table hash). Each package has its own stash and contains pointers to nested packages' stashes. The main stash, available from a global variable[ 8 ] called defstash , contains pointers to other "top-level" packages' stashes. Table 20.4 shows the important functions for accessing GVs and the symbol table.
[8] Or per-interpreter variable if MULTIPLICITY is defined.
|
Function/Macro |
Description |
|---|---|
GvSV, GvAV, GvHV, GvIO, GvFORM |
Return the appropriate value pointers hanging off the GV. |
HV *gv_stashpv(
char *name,
int create)
|
Given a package name, get the corresponding HV. The names don't need the trailing "::", unlike in script space. |
HV *gv_stashsv(
SV *, int create)
|
Same as above. SV* contains the name of the package. |
HV *SvSTASH (SV* sv) |
Get the stash from a blessed object. If |
char* HvNAME(HV* stash) |
Given a stash, return the package name. |
Standard variables in script space such as $_ , $@ , $& , $` , and $' are available as global variables in C space: defgv , errgv , ampergv , leftgv , and rightgv , respectively. For example, if you know that $_ contains a number, you can extract it in C as follows:
int i = SvIV(GvSV(defgv)); /* $_ and @_ are represented by defgv */
20.3.4.1 Inside glob values and symbol tables
Figure 20.6 shows most of the interesting components of a GV.
Figure 20.6: Glob value structure
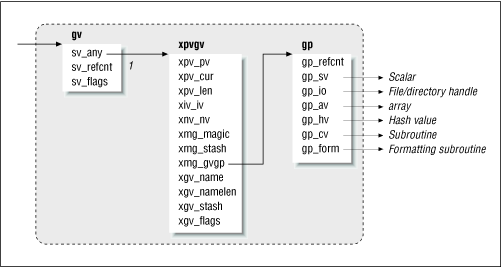
The xgv_name field stores the name of the variable (without the prefix). The pointers to the contained values ( $foo , @foo , and so on) are encapsulated in a separate structure called gp to enable fast aliasing. In the typical case in which you don't reuse the same name for different types of variables, all but one of the value pointers are NULL .
Symbol tables are HVs that map variable names to GVs. But aren't HVs supposed to store SVs only? Well, you may have noticed that all value types have identical- looking wrapper structures that maintain the reference count, flags, and the pointer to an internal structure. Because they are identical, you can cast an AV* , HV* , CV* to an SV* and thus fool the HV into storing anything you want. If you were to do this yourself, be careful of the HV calls that decrement the reference count of a contained "SV" ( hv_delete , for example). This is because they will trigger an sv_free() if the reference count becomes 0, and if it is not an SV, you are in trouble.
20.3.5 Code Values
We have now finished studying all the fundamental data types used in Perl. Next we study code values, which represent subroutines, eval blocks, and format declarations. This explanation will enable you to call Perl subroutines efficiently from C and also give you a visceral understanding of how lexical variables and closures are implemented.
Table 20.5 shows the API for CVs; there's not much you can do with CVs except call them. Except for perl_call_sv , all the other API functions accept the name of a procedure rather than the CV itself.
|
Function/Macro |
Description |
|---|---|
CV*
perl_get_cv(char *name,
int create)
|
Get the CV for a given name. You should always set create to FALSE, because a TRUE value automatically creates a blank CV, which is useless to an application writer. |
int
perl_call_sv(SV* cv,
int flags)
|
Call a subroutine indicated by the |
perl_call_argv(
char *sub,
I32 flags,
char **argv);
|
Discussed in Table 19.1 . |
perl_call_va (
char *sub,
[char *type, arg],*
["OUT",]
[char *type, arg,]*
);
|
Discussed in Table 19.1 . We will implement this convenience function later in the section "Easy Embedding API ." |
int perl_call_pv (
char* sub_name,
int flags)
|
Call a subroutine by name. A thin wrapper over perl_call_sv . |
int perl_call_method(
char *method_name,
int flags)
|
Call a method of a class by name. The first parameter on the stack must be either an SV containing the name of the class or a blessed reference of the class. |
There are other ways of calling Perl subroutines, such as perl_call_argv and perl_call_va , which we saw in the last chapter. All these functions are wrappers around perl_call_sv and attempt to hide the messaging protocol details to some extent. The flags parameter is a combination of any of the following bitmasks defined in perl.h :
- G_DISCARD
-
Discards all return parameters from the function.
- G_SCALAR , G_ARRAY
-
Specifies a scalar or array context, scalar being the default. The called subroutine can use wantarray to find out the caller's intention. These flags can also be used in conjunction with G_DISCARD . This is useful when you want to affect the way a function invoking wantarray works, even if you are not interested in the results.
- G_EVAL , G_KEEPERR
-
Wraps an eval block around the call. perl_eval_sv() assumes this flag automatically. When an eval 'd block dies, Perl assigns die 's string argument to errgv ( $@ ) and clears all temporary variables created in that block. Perl checks to see whether any of these variables is a blessed object and, if so, calls its DESTROY routine. There's a chance that this routine might invoke die (after all, it is user-defined code). Here we have a situation in which errgv is already computed and an additional exception is thrown. Using G_KEEPERR , you instruct Perl to concatenate this new exception string to errgv instead of overwriting it.
20.3.5.1 Inside CV
A CV has the same overall structure as the other value types: a generic part and a specific part. Consider the following piece of code, which defines a function in another package (by fully qualifying the name) and examines the function using Devel::Peek:
package Foo;
sub main::bar { #Introduce a function in a different package
my $a = 10;
}
use Devel::Peek;
Dump(\&main::bar);
The dump looks like this:
SV = PVCV(0x774300) REFCNT = 2 FLAGS = () IV = 0 NV = 0 COMP_STASH = 0x6635f0 "Foo" START = 0x7744d0 ROOT = 0x774650 XSUB = 0x0 XSUBANY = 0 GVGV::GV = 0x66365c "main" :: "bar" FILEGV = 0x660418 "_<foo.pl" DEPTH = 0 PADLIST = 0x66362c
The COMP_STASH field indicates that the "Foo" stash would be active when bar() executes, although this subroutine is defined in package main . The ROOT field indicates the root opcode of the syntax subtree for the CV, and START is the address of the opcode to get control when the function starts. The XSUB field either is NULL or contains a pointer to a C subroutine. The DEPTH field indicates the depth of recursion, and PADLIST refers to a list of scratchpads for storing lexical variables defined inside that subroutine. More on this next.
20.3.5.2 How local and my work
Perl variables, as we are well aware, can be global, dynamic (tagged with local ), or lexical ( my ). Global variables are accessible via the stash and the corresponding typeglob. When Perl encounters the global variable $a , it produces the opcode gvsv , which places the corresponding GV's scalar value on the stack, at run-time.
When Perl parses " local $a ," it still outputs the same gvsv opcode, but this time it sets a special flag in that opcode to "localize" the scalar. At run-time, the corresponding opcode function pp_gvsv checks this flag and, if it is set, replaces the GV's scalar value with a new scalar value and pushes this new value onto the argument stack. Meanwhile, the old SV sits safely in something called a savestack (discussed later, in the section "Inside Other Stacks "). Subsequent accesses of $a within that scope (or a nested scope) lead you, via a 's GV, to the newly allocated scalar value.
my variables are stored and treated very differently. We mentioned earlier that each CV contains a padlist , a list of scratchpads, as illustrated in Figure 20.7 .
Figure 20.7: Inside look at my variables
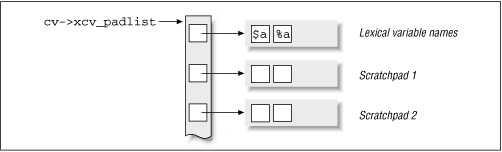
The padlist is an ordinary AV. Its 0th element points to an AV containing all lexical variable names used within that subroutine (not just declared within that subroutine). The names contain their prefix symbols, so $a and %a have their own unique entries. The padlist's first element points to a scratchpad array (also an AV), whose elements contain the values corresponding to the lexical variables named in the 0th row. As you can see, the padlist is an alternative symbol table because it contains a logical pairing of variable names and values.
When the subroutine recurses, a new scratchpad is allocated for that recursion level. You'll notice that a CV requires at least three AVs (one for xcv_padlist , one for storing the names, and one or more for storing values).
When multithreading is introduced into Perl (Version 5.005 onward), each thread will get its own scratchpad,[ 9 ] which means that lexical variables will continue to be completely private to a recursion level and thread. (Package global variables will continue to be global, of course.)
[9] This is according to Malcolm Beattie's current prototype patches for supporting POSIX threads.
my variables are a shade faster than local variables. The reason is that local allocates a new value at run-time to temporarily occlude the global value. In contrast, my variables are already unique to a CV, so they are typically allocated once, at parse time. The only reason to create a fresh my value is in case of recursion, which is not a typical occurrence. In future releases of Perl, multiple threads executing the same CV will also require run-time allocation of lexical variables.
When you access a lexical variable, Perl's code generator outputs an opcode called padsv , equivalent to gvsv (which is used for global or local variables). padsv remembers the offset of the variable inside the scratchpad (1 for %a in Figure 20.7 ). At run-time, Perl wastes no time at all fetching the corresponding value and pushing it on the stack.
20.3.5.3 Closures
This brief introduction to CVs and lexical variables leads us to the subject of closures. When a closure is created, Perl allocates a CV, points it to the starting opcode for the subroutine, and supplies it with its own private padlist. The padlist contains pointers to all lexical variables used by that closure, whether or not they were created within that block, as illustrated by Figure 20.8 .
Figure 20.8: Scratchpad picking up lexicals from containing CVs' scratchpads
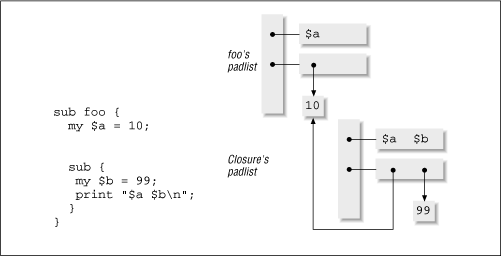
For those lexicals picked up from the CV containing the closure ( $a in Figure 20.8 ), the scratchpad contains direct pointers to the appropriate values, and the reference count of those values is incremented. Lexicals such as $b , created within the closure, are freshly allocated. Either way, the space allocated for a lexical variable is not deallocated as long as any subroutine using it can be called.
20.3.5.4 Objects versus closures
In Chapter 4, Subroutine References and Closures , we noted the similarity between objects and closures: both represent a binding between code and data. In other words, an object with three member functions can instead be represented as three closures acting on private variables borrowed from their containing environment.
Clearly, the closure approach is a lot more expensive in space; to represent 100 objects' worth of information, you require 300 unique closures, which works out to 900 AVs. In contrast, if you use a hash representation for storing object attributes, you need 100 hash tables and 9 AVs (three per subroutine).
On the other hand, calling a closure is faster than invoking an object's method. This is because a closure's variables are ready to be used as soon as the procedure is called, whereas an object's method has to dereference the object reference and then make a hash access for each attribute. The following benchmark compares the speed of an object accessor method to an equivalent closure - the latter approach is two to three times faster on my PC:
#--------------------------------------------------------------
package OBJECT; # Pkg for timing object accessors
sub new {
bless {'abc' => 10};
}
sub abc { # Fetch the abc attribute
$_[0]->{'abc'};
}
sub increment { # Increment the abc attribute
$_[0]->{'abc'}++;
}
#--------------------------------------------------------------
package CLOSURE; # Pkg for timing closures
sub new {
my $abc = 10; # member data.
$rs_increment = sub {$abc++}; # equivalent of OBJECT::increment
$rs_abc = sub {$abc} ; # equivalent of OBJECT::abc
($rs_increment, $rs_abc);
}
#--------------------------------------------------------------
package main;
use Benchmark;
$a = OBJECT->new(); # Create a new object
($inc, $fetch) = CLOSURE->new(); # Create two closures
timethese(1000000, {
Object => '$a->increment', # call an object method
Closure => '&$inc' # call a closure
});
On my PC, this prints
Benchmark: timing 1000000 iterations of Closure, Object...
Closure: 13 secs (14.39 usr 0.00 sys = 14.39 cpu)
Object: 45 secs (45.14 usr 0.00 sys = 45.14 cpu)
20.3.6 Magic Variables[ 10 ]
[10] This section can be skipped on a first reading.
There are ordinary user-defined variables containing strings, numbers, and references; then there are magical variables, those that have one or more special properties. A tied variable, for example, is magical because it contains pointers to a tied object and invokes that object's FETCH and STORE methods when read from and written to, as we saw in Chapter 9, Tie . Built-in variables such as $! and %SIG are also special: when $! is read from, Perl implicitly reads the C variable errno ; when %SIG is written to, Perl resets the signal handler.
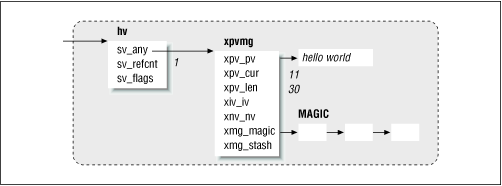
A magical scalar variable is shown in Figure 20.9 . It contains the normal scalar fields that you saw earlier and, in addition, points to a linked list of properties. A structure called MAGIC represents each property and provides a semblance of uniformity over the different types of properties, as we shall soon see. Let us look at this structure in some detail before we use this facility to our advantage.
Figure 20.9: Magical scalar
A property, as seen in Figure 20.10 , is an object containing a property type, a pointer to some data private to that property, and a pointer to a virtual table (or vtbl , a table of pointers to functions, in C++ parlance). When a variable is read from, written to, cleared, or destroyed, or if its length is accessed, Perl first updates the variable's value (the string, integer, or double fields) and then calls the accessor function responsible for the appropriate action (reading, writing, clearing, and so on; refer to Figure 20.10 ). If the variable has more than one property, the corresponding accessor function from each property is called, to give all of them a chance to affect the value of that variable as they please. An accessor can have side-effects too. For example, when you modify %SIG , each of its properties' svt_set function is invoked. One of these functions updates the signal handler.
Figure 20.10: MAGIC: Uniform interface for representing special properties

Perl comes with a set of prebuilt virtual tables associated with unique property types , which are simply unique characters. For example, the virtual table to handle tied arrays is indicated by the character "P." Please take a look at the perlguts document if you are interested in the other built-in types. A value can have at most one property of a given type in its list. There's one property type, identified by the character ~ , which is a hook for an extension writer to supply a custom virtual table. Let us see how to use this particular type.
To attach special properties to a scalar, use the sv_magic function, like this:
sv_magic(sv, obj, '~', "foo", 3);
This function upgrades the scalar value to an XPVMG structure internally and tells Perl not to attach any of its predefined virtual tables (because of ~ ). In addition, it creates one MAGIC structure and hangs it off the scalar. obj is an SV of your choice, containing user-defined data and meant for the accessor functions to distinguish between one magical variable and another. The last two parameters simply give a name to the property: an identifier string and length. Typically, you use the variable's name.
To access a certain property structure from a scalar, use the mg_find function:
MAGIC *m = mg_find(sv(,'~'));
Let us use these two functions to create a low-level tie mechanism: call a custom function when something happens to the variable. The procedure foo_tie in the following example shows how to associate a variable $foo in Perl space to a C variable my_foo :
int my_foo; /* to be tied to $foo at script level */
int foo_get (SV *sv, MAGIC *mg)
{
sv_setiv(sv, my_foo); /* return my_foo's value */
printf ("GET foo => %d\n", my_foo);
return 1; /* return value not used */
}
int foo_set (SV *sv, MAGIC *mg)
{
my_foo = SvIV(sv); /* set my_foo's value */
printf ("SET foo => %d\n", my_foo);
return 1; /* return value not used */
}
MGVTBL foo_accessors = { /* Custom virtual table */
foo_get, foo_set, NULL, NULL, NULL
};
void foo_tie ()
{
MAGIC *m;
/* Create a variable*/
char *var = "main::foo";
SV *sv = perl_get_sv(var,TRUE);
/* Upgrade the sv to a magical variable*/
sv_magic(sv, NULL, '~', var, strlen(var));
/* sv_magic adds a MAGIC structure (of type '~') to the SV.
Get it and set the virtual table pointer */
m = mg_find(sv, '~');
m->mg_virtual = &foo_accessors;
SvMAGICAL_on(sv);
}
Since foo_tie uses the ` ~ ' property type, Perl does not supply a prebuilt virtual table. foo_tie makes up for the omission by supplying its own custom virtual table, foo_accessors , which contains pointers to foo_get and foo_set . Note that these two functions access the integer slot of the scalar given to them.
The tie mechanism that is available at the scripting level is slightly more involved. It first asks the module to return an object (using TIESCALAR, TIEHASH, etc.) and uses that object as a parameter to sv_magic . Later, when the tied variable is read from, the sv_get accessor is called, which relays the call to the private object's FETCH method.

|

|

|
| 20.2 Architecture |
|
20.4 Stacks and Messaging Protocol |

Copyright © 2001 O'Reilly & Associates. All rights reserved.