
9.4. Disk Space Problems
The downside to having programs that can provide useful or verbose logging output is the amount of disk space this output can consume. This is a concern for all three operating systems covered in this book: Unix, MacOS, and Windows NT/2000. Of the three, NT/2000 is probably the least troublesome of the lot because its central logging facility has built-in autotrimming support. MacOS does not have a central logging facility, but it too can run servers that will happily produce enough logging output to fill your disks if given the chance.
Usually, the task of keeping the log files down to a reasonable size is handed off to the system administrator. Most Unix vendors provide some sort of automated log size management mechanism with the OS, but it often only handles the select set of log files shipped with the machine. As soon as you add another service to a machine that creates a separate log file, it becomes necessary to tweak (or even toss) the vendor-supplied solution.
9.4.1. Log Rotation
The usual solution to the space problem is to rotate your log files. (We'll see an unusual solution later in this section.) After a specific duration has passed or a file size has been reached, the current log file is moved to another name, e.g., logfile.0. The logging process is then continued into an empty file. At the next interval or limit, we repeat the process, first moving the backup file (logfile.0 ) to another name (like logfile.1). This process is repeated until a set number backup files have been created. The oldest backup file at that point is deleted. Figure 9-3 shows a picture of this process.
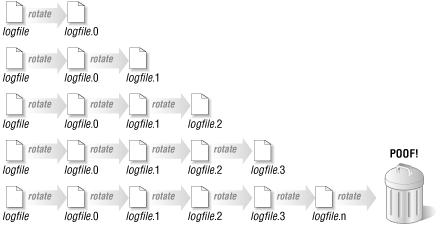
Figure 9.3. A pictorial representation of log rotation
This method allows us to keep a reasonable, finite amount of log data around. Table 9-2 provides one recipe for log rotation and the Perl functions needed to perform each step.
Table 9.2. A Recipe for Log Rotation in Perl
|
Process |
Perl |
|---|---|
|
Move the older backup logs out of the way (i.e., move each one to a new name in the sequence). |
rename( ) or &File::Copy::move( ) if moving files cross-filesystem. |
|
If necessary, signal the process creating this particular log file to close the current file and cease logging to disk until told otherwise. |
kill( ) for programs that take signals, system( ) or `` (backticks) if another administrative program has to be called for this purpose. |
|
Copy or move the log file that was just in use to another file. |
&File::Copy to copy, rename( ) to rename (or &File::Copy::move( ) if moving files cross-filesystem). |
|
If necessary, truncate the current log file. |
truncate( ) or open(FILE,">filename"). |
|
If necessary, signal the logging process to resume logging. |
See step 2 of this table. |
|
If desired, compress or post-process the copied file. |
system( ) or backticks to run a compression program or other code for post-processing. |
|
Delete other, older log file copies. |
stat( ) to examine file sizes and dates, unlink( ) to delete files. |
There are many variations on this theme. Everyone and their aunt's vendor have written their own script to do log rotation. It should come as no surprise that there is a Perl module to handle log rotation. Let's take a quick look at Logfile::Rotate by Paul Gampe.
Logfile::Rotate uses the object-oriented programming convention of first creating a new log file object instance and then running a method of that instance. First, we create a new instance with the parameters found in Table 9-3.
Table 9.3. Logfile::Rotate Parameters
|
Parameter |
Purpose |
|---|---|
|
File |
Name of log file to rotate |
|
Count (optional, default: 7) |
Number of backup files to keep around |
|
Gzip (optional, default: Perl's default as found during the Perl build) |
Full path to gzip compression program executable |
|
Signal |
Code to be executed after the rotation has been completed, as in step 5 of Table 9-2 |
Here's some example code that uses these parameters:
use Logfile::Rotate;
$logfile = new Logfile::Rotate(
File => "/var/adm/log/syslog",
Count => 5,
Gzip => "/usr/local/bin/gzip",
Signal =>
sub {
open PID, "/etc/syslog.pid" or
die "Unable to open pid file:$!\n";
chomp($pid = <PID>);
close PID;
# should check validity first
kill 'HUP', $pid;
}
);
This locks the log file you've specified and prepares the module for rotating it. Once you've created this object, actually rotating the log is trivial:
$logfile->rotate( ); undef $logfile;
The undef line is there to be sure that the log file is unlocked after rotation (it stays locked while the logfile object is still in existence).
As mentioned in the documentation, if this module is run by a privileged user (like root) there are a few concerns. First, Logfile::Rotate makes a system call to run the gzip program, potentially a security hole. Second, the Signal subroutine must be coded in a defensive manner. In the previous example, we don't check to see that the process ID retrieved from /etc/syslog.pid is actually the correct PID for syslog. It would be better to use one of the process table listing strategies we discussed in Chapter 4, "User Activity", before sending the signal via kill( ). See Chapter 1, "Introduction", for more tips on coding defensively.
9.4.2. Circular Buffering
We've just discussed the traditional log rotation method for dealing with storage of ever-growing logs. Let me show you a more unusual approach that you can add to your toolkit.
Here's a common scenario: you're trying to debug a server daemon that provides a torrent of log output. You're only interested in a small part of the total output, perhaps just the lines the server produces after you run some sort of test with a special client. Saving all of the log output to disk as per usual would fill your disk quickly. Rotating the logs as often as needed with this volume of output would slow down the server. What do you do?
I wrote a program called bigbuffy to deal with this conundrum. The approach is pretty straightforward. bigbuffy reads from its usual "standard" or "console" input one line at a time. These lines are stored in a circular buffer of a set size. When the buffer is full, it starts filling from the top again. This read-store process continues forever until bigbuffy receives a signal from the user. Upon receiving this signal, it dumps the current contents of the buffer to a file and returns to its normal cycle. What's left behind on disk is essentially a window into the log stream, showing just the data you need.
bigbuffy can be paired with a service-monitoring program like those found in Chapter 5, "TCP/IP Name Services". As soon as the monitor detects a problem, it can signal bigbuffy to dump its log buffer. Now you've got a snapshot of the log localized to the failure instance (assuming your buffer is large enough and your monitor noticed the problem in time).
Here's a simplified version of bigbuffy. The code is longer than the examples we've seen so far in this chapter, but it is not very complex. We'll use it in a moment as a springboard for addressing some important issues like input blocking and security:
$buffsize = 200; # default circular buffer size (in lines)
use Getopt::Long;
# parse the options
GetOptions("buffsize=i" => \$buffsize,
"dumpfile=s" => \$dumpfile);
# set up the signal handler and initialize a counter
&setup;
# and away we go! (with just a simple
# read line--store line loop)
while (<>){
# insert line into data structure
# note, we do this first, even if we've caught a signal.
# Better to dump an extra line than lose a line of data if
# something goes wrong in the dumping process
$buffer[$whatline] = $_;
# where should the next line go?
($what_line %= $buff_size)++;
# if we receive a signal, dump the current buffer
if ($dumpnow) {
&dodump( );
}
}
sub setup {
die "USAGE: $0 [--buffsize=<lines>] --dumpfile=<filename>"
unless (length($dumpfile));
$SIG{'USR1'} = \&dumpnow; # set a signal handler for dump
$whatline = 1; # start line in circular buffer
}
# simple signal handler that just sets an exception flag,
# see perlipc(1)
sub dumpnow {
$dumpnow = 1;
}
# dump the circular buffer out to a file, appending to file if
# it exists
sub dodump{
my($line); # counter for line dump
my($exists); # flag, does the output file exist already?
my(@firststat,@secondstat); # to hold output of lstats
$dumpnow = 0; # reset the flag and signal handler
$SIG{'USR1'} = \&dumpnow;
if (-e $dumpfile and (! -f $dumpfile or -l $dumpfile)) {
warn "ALERT: dumpfile exists and is not a plain file,
skipping dump.\n";
return undef;
}
# we have to take special precautions when we're doing an
# append. The next set of "if" statements perform a set of
# security checks while opening the file for append
if (-e $dumpfile) {
$exists = 1;
unless(@firststat = lstat $dumpfile){
warn "Unable to lstat $dumpfile,
skipping dump.\n";
return undef;
}
if ($firststat[3] != 1) {
warn "$dumpfile is a hard link, skipping dump.\n";
return undef;
}
}
unless (open(DUMPFILE,">>$dumpfile")){
warn "Unable to open $dumpfile for append,
skipping dump.\n";
return undef;
}
if ($exists) {
unless (@secondstat = lstat DUMPFILE){
warn "Unable to lstat opened $dumpfile,
skipping dump.\n";
return undef;
}
if ($firststat[0] != $secondstat[0] or # check dev num
$firststat[1] != $secondstat[1] or # check inode
$firststat[7] != $secondstat[7]) # check sizes
{
warn "SECURITY PROBLEM: lstats don't match,
skipping dump.\n";
return undef;
}
}
$line = $whatline;
print DUMPFILE "-".scalar(localtime).("-"x50)."\n";
do {
# in case buffer was not full
last unless (defined $buffer[$line]);
print DUMPFILE $buffer[$line];
$line = ($line == $buffsize) ? 1 : $line+1;
} while ($line != $whatline);
close(DUMPFILE);
# zorch the active buffer to avoid leftovers
# in future dumps
$whatline = 1;
$buffer = ( );
return 1;
}
A program like this can stir up a few interesting implementation issues.
9.4.2.1. Input blocking in log processing programs
I mentioned earlier that this is a simplified version of bigbuffy. For ease of implementation, especially cross-platform, this version has an unsavory characteristic: while dumping data to disk, it can't continue reading input. During a buffer dump, the program sending output to bigbuffy may be told by the OS to pause operation pending the drain of its output buffer. Luckily, the dump is fast, so the window where this could happen is very small, but this is still less passive than we'd like.
Two possible solutions to this problem include:
-
Rewriting bigbuffy to use a double-buffered, multitasking approach. Instead of using a single storage buffer, two would be employed. Upon receiving the signal, the program would begin to log to a second buffer while a child process or another thread handled the dumping of the first buffer. At the next signal, buffers are swapped again.
-
Rewriting bigbuffy to interleave reading and writing while it is dumping. The simplest version of this approach would involve writing some number of lines to the output file each time a new line is read. This gets a bit tricky if the log output being read is "bursty" instead of arriving as constant flow. You wouldn't want to wait for a new line of output before you could receive the requested log buffer dump. You'd have to use some sort of timeout or internal clock mechanism to get around this problem.
Both approaches are hard to pull off portably in a cross-platform environment, hence the simplified version shown in this book.
9.4.2.2. Security in log processing programs
You may have noticed that bigbuffy troubles itself more than usual with the opening and writing of its output file. This is an example of the defensive coding style mentioned earlier in Section 9.4.1, "Log Rotation". If this program is to be used to debug server daemons, it is likely to be run by privileged users on a system. It is important to think about unpleasant situations that might allow this program to be abused.
For example, take the case where the output file we've specified is maliciously swapped with a link to another file. If we naively opened and wrote to the file, we might find ourselves inadvertently stomping on an important file like /etc/passwd instead. Even if we checked the output file before opening it, a nasty person may have switched it on us before we began to write to it. To avoid this scenario:
-
We check if the output file exists already. If it does, we lstat( ) it to get filesystem information.
-
We open the file in append mode.
-
Before we actually write to this file, we lstat( ) the open filehandle and check that it is still the same file we expect it to be and it hasn't been switched since we initially checked it. If it is not the same file (e.g., someone swapped the file with a link right before the open), we do not write to the file and complain loudly. This last step avoids a race condition as mentioned in Chapter 1, "Introduction".
If we didn't have to append, we could have opened a temporary file with a randomized name (so it couldn't be guessed ahead of time) and renamed the temporary file into place.
These sorts of gyrations are necessary on most Unix systems because Unix was not originally designed with security as a high priority. Symbolic-link security breaches are not a problem under NT4 since they are a little-used part of the POSIX subsystem, and MacOS, which doesn't have the notion of "privileged user."[3]
[3]In fairness, both NT and MacOS have their own unique security weaknesses. Also, there is considerable time and effort these days being spent to "harden" various Unix distributions (e.g., OpenBSD).
 |  |  |
| 9.3. Stateful and Stateless Data |  | 9.5. Log Analysis |

Copyright © 2001 O'Reilly & Associates. All rights reserved.