
29.2. Perl Functions in Alphabetical Order
Many of the following function names are annotated with, um, annotations. Here are their meanings:
-
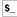
-
Uses $_ ($ARG) as a default variable.
-
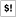
-
Sets $! ($OS_ERROR) on syscall errors.
-
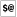
-
Raises exceptions; use eval to trap $@ ($EVAL_ERROR).
-
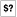
-
Sets $? ($CHILD_ERROR) when child process exits.
-

-
Taints returned data.
-

-
Taints returned data under some system, locale, or handle settings.
-
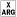
-
Raises an exception if given an argument of inappropriate type.
-
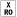
-
Raises an exception if modifying a read-only target.
-
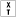
-
Raises an exception if fed tainted data.
-
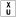
-
Raises an exception if unimplemented on current platform.
Functions that return tainted data when fed tainted data are not marked, since that's most of them. In particular, if you use any function on %ENV or @ARGV, you'll get tainted data.
Functions marked with raise an exception when they require, but do not receive,
an argument of a particular type (such as filehandles for I/O
operations, references for blessing, etc.).
Functions marked with sometimes need to alter their arguments.
If they can't modify the argument because it's marked read-only,
they'll raise an exception. Examples of read-only variables are
the special variables containing data captured during a pattern
match and variables that are really aliases to constants.
Functions marked with may not be implemented on all platforms.
Although many of these are named after functions in the Unix C
library, don't assume that just because you aren't running Unix,
you can't call any of them. Many are emulated, even
those you might never expect to see--such as fork on Win32
systems, which works as of the 5.6 release of Perl. For more
information about the portability and behavior of system-specific
functions, see the perlport manpage, plus any platform-specific documentation that came with
your Perl port.
Functions that raise other miscellaneous exceptions are marked with ,
including math functions that throw range errors, such as sqrt(-1).
29.2.1. abs
This function returns the absolute value of its argument.abs VALUE abs
Note: here and in subsequent examples, good style (and the use strict pragma) would dictate that you add a my modifier to declare a new lexically scoped variable, like this:$diff = abs($first - $second);
However, we've omitted my from most of our examples for clarity. Just assume that any such variable was declared earlier, if that cranks your rotor.my $diff = abs($first - $second);
29.2.2. accept
This function is used by server processes that wish to listen for socket connections from clients. PROTOSOCKET must be a filehandle already opened via the socket operator and bound to one of the server's network addresses or to INADDR_ANY. Execution is suspended until a connection is made, at which point the SOCKET filehandle is opened and attached to the newly made connection. The original PROTOSOCKET remains unchanged; its only purpose is to be cloned into a real socket. The function returns the connected address if the call succeeds, false otherwise. For example:accept SOCKET, PROTOSOCKET
unless ($peer = accept(SOCK, PROTOSOCK)) {
die "Can't accept a connection: $!\n";
}
On systems that support it, the close-on-exec flag will be set for the
newly opened file descriptor, as determined by the value of
$^F ($SYSTEM_FD_MAX).
See accept(2). See also the example in the section "Sockets" in Chapter 16, "Interprocess Communication".
29.2.3. alarm
This function sends a SIGALRM signal to the current process after EXPR seconds.alarm EXPR alarm
Only one timer may be active at once. Each call disables the previous timer, and an EXPR of 0 may be supplied to cancel the previous timer without starting a new one. The return value is the amount of time remaining on the previous timer.
It is usually a mistake to intermix alarm and sleep calls, because many systems use the alarm(2) syscall mechanism to implement sleep(3). On older machines, the elapsed time may be up to one second less than you specified because of how seconds are counted. Additionally, a busy system may not get around to running your process immediately. See Chapter 16, "Interprocess Communication" for information on signal handling.print "Answer me within one minute, or die: "; alarm(60); # kill program in one minute $answer = <STDIN>; $timeleft = alarm(0); # clear alarm print "You had $timeleft seconds remaining\n";
For alarms of finer granularity than one second, you might be able to use the syscall function to access setitimer(2) if your system supports it. The CPAN module, Timer::HiRes, also provides functions for this purpose.
29.2.4. atan2
This function returns the principal value of the arc tangent of Y/X in the range -atan2 Y, X
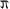 to . A quick way to get an
approximate value of is to say:
to . A quick way to get an
approximate value of is to say:
For the tangent operation, you may use the tan function from either the Math::Trig or the POSIX modules, or just use the familiar relation:$pi = atan2(1,1) * 4;
sub tan { sin($_[0]) / cos($_[0]) }
29.2.5. bind
This function attaches an address (a name) to an already opened socket specified by the SOCKET filehandle. The function returns true if it succeeded, false otherwise. NAME should be a packed address of the proper type for the socket.bind SOCKET, NAME
See bind(2). See also the examples in the section "Sockets" in Chapter 16, "Interprocess Communication".use Socket; $port_number = 80; # pretend we want to be a web server $sockaddr = sockaddr_in($port_number, INADDR_ANY); bind SOCK, $sockaddr or die "Can't bind $port_number: $!\n";
29.2.6. binmode
This function arranges for the FILEHANDLE to have the semantics specified by the DISCIPLINES argument. If DISCIPLINES is omitted, binary (or "raw") semantics are applied to the filehandle. If FILEHANDLE is an expression, the value is taken as the name of the filehandle or a reference to a filehandle, as appropriate.binmode FILEHANDLE, DISCIPLINES binmode FILEHANDLE
The binmode function should be called after the open but before any I/O is done on the filehandle. The only way to reset the mode on a filehandle is to reopen the file, since the various disciplines may have treasured up various bits and pieces of data in various buffers. This restriction may be relaxed in the future.
In the olden days, binmode was used primarily on operating systems whose run-time libraries distinguished text from binary files. On those systems, the purpose of binmode was to turn off the default text semantics. However, with the advent of Unicode, all programs on all systems must take some cognizance of the distinction, even on Unix and Mac systems. These days there is only one kind of binary file (as far as Perl is concerned), but there are many kinds of text files, which Perl would also like to treat in a single way. So Perl has a single internal format for Unicode text, UTF-8. Since there are many kinds of text files, text files often need to be translated upon input into UTF-8, and upon output back into some legacy character set, or some other representation of Unicode. You can use disciplines to tell Perl how exactly (or inexactly) to do these translations.[2]
[2]More precisely, you will be able to use disciplines for this, but we're still implementing them as of this writing.
For example, a discipline of ":text" will tell Perl to do generic text processing without telling Perl which kind of text processing to do. But disciplines like ":utf8" and ":latin1" tell Perl which text format to read and write. On the other hand, the ":raw" discipline tells Perl to keep its cotton-pickin' hands off the data. For more on how disciplines work (or will work), see the open function. The rest of this discussion describes what binmode does without the DISCIPLINES argument, that is, the historical meaning of binmode, which is equivalent to:
Unless instructed otherwise, Perl will assume your freshly opened file should be read or written in text mode. Text mode means that \n (newline) will be your internal line terminator. All systems use \n as the internal line terminator, but what that really represents varies from system to system, device to device, and even file to file, depending on how you access the file. In such legacy systems (including MS-DOS and VMS), what your program sees as a \n may not be what's physically stored on disk. The operating system might, for example, store text files with \cM\cJ sequences that are translated on input to appear as \n to your program, and have \n from your program translated back to \cM\cJ on output to a file. The binmode function disables this automatic translation on such systems.binmode FILEHANDLE, ":raw";
In the absence of a DISCIPLINES argument, binmode has no effect under Unix or Mac OS, both of which use \n to end each line and represent that as a single character. (It may, however, be a different character: Unix uses \cJ and older Macs use \cM. Doesn't matter.)
The following example shows how a Perl script might read a GIF image from a file and print it to the standard output. On systems that would otherwise alter the literal data into something other than its exact physical representation, you must prepare both handles. While you could use a ":raw" discipline directly in the GIF open, you can't do that so easily with pre-opened filehandles like STDOUT:
binmode STDOUT;
open(GIF, "vim-power.gif") or die "Can't open vim-power.gif: $!\n";
binmode GIF;
while (read(GIF, $buf, 1024)) {
print STDOUT $buf;
}
29.2.7. bless
This function tells the referent pointed to by reference REF that it is now an object in the CLASSNAME package--or the current package if no CLASSNAME is specified. If REF is not a valid reference, an exception is raised. For convenience, bless returns the reference, since it's often the last function in a constructor subroutine. For example:bless REF, CLASSNAME bless REF
$pet = Beast->new(TYPE => "cougar", NAME => "Clyde");
# then in Beast.pm:
sub new {
my $class = shift;
my %attrs = @_;
my $self = { %attrs };
return bless($self, $class);
}
You should generally bless objects into CLASSNAMEs that are mixed
case.
Namespaces with all lowercase names are reserved for internal
use as Perl pragmata (compiler directives). Built-in types (such as
"SCALAR", "ARRAY", "HASH", etc., not to mention the base class
of all classes, "UNIVERSAL") all have uppercase names, so you may wish
to avoid such package names as well.
Make sure that CLASSNAME is not false; blessing into false packages is not supported and may result in unpredictable behavior.
It is not a bug that there is no corresponding curse operator. (But there is a sin operator.) See also Chapter 12, "Objects", for more about the blessing (and blessings) of objects.
29.2.8. caller
This function returns information about the stack of current subroutine calls and such. Without an argument, it returns the package name, filename, and line number that the currently executing subroutine was called from:caller EXPR caller
Here's an example of an exceedingly picky function, making use of the special tokens __PACKAGE__ and __FILE__ described in Chapter 2, "Bits and Pieces":($package, $filename, $line) = caller;
sub careful {
my ($package, $filename) = caller;
unless ($package eq __PACKAGE__ && $filename eq __FILE__) {
die "You weren't supposed to call me, $package!\n";
}
print "called me safely\n";
}
sub safecall {
careful();
}
When called with an argument, caller evaluates EXPR as the
number of stack frames to go back before the current one. For
example, an argument of 0 means the current stack frame, 1 means
the caller, 2 means the caller's caller, and so on. The function
also reports additional information as shown here:
$i = 0;
while (($package, $filename, $line, $subroutine,
$hasargs, $wantarray, $evaltext, $is_require,
$hints, $bitmask) = caller($i++) )
{
...
}
If the frame is a subroutine call, $hasargs is true
if it has its own @_ array (not one borrowed from
its caller). Otherwise, $subroutine may be
"(eval)" if the frame is not a subroutine call, but
an eval. If so, additional elements
$evaltext and $is_require are
set: $is_require is true if the frame is created by
a require or use statement, and
$evaltext contains the text of the
evalEXPR statement. In
particular, for a evalBLOCK statement,
$filename is "(eval)", but
$evaltext is undefined. (Note also that each
use statement creates a require
frame inside an evalEXPR frame.) The $hints
and $bitmask are internal values; please ignore
them unless you're a member of the thaumatocracy.
In a fit of even deeper magic, caller also sets the array @DB::args to the arguments passed in the given stack frame--but only when called from within the DB package. See Chapter 20, "The Perl Debugger".
29.2.9. chdir
This function changes the current process's working directory to EXPR, if possible. If EXPR is omitted, the caller's home directory is used. The function returns true upon success, false otherwise.chdir EXPR chdir
See also the Cwd module, described in Chapter 32, "Standard Modules", which lets you keep track of your current directory automatically.chdir "$prefix/lib" or die "Can't cd to $prefix/lib: $!\n";
29.2.10. chmod
This function changes the permissions of a list of files. The first element of the list must be the numerical mode, as in the chmod(2) syscall. The function returns the number of files successfully changed. For example:chmod LIST
will set $cnt to 0, 1, or 2, depending on how many files were changed. Success is measured by lack of error, not by an actual change, because a file may have had the same mode before the operation. An error probably means you lacked sufficient privileges to change its mode because you were neither the file's owner nor the superuser. Check $! to find the actual reason for failure.$cnt = chmod 0755, 'file1', 'file2';
Here's a more typical usage:
chmod(0755, @executables) == @executables
or die "couldn't chmod some of @executables: $!";
If you need to know which files didn't allow the change, use something
like this:
@cannot = grep {not chmod 0755, $_} 'file1', 'file2', 'file3';
die "$0: could not chmod @cannot\n" if @cannot;
This idiom makes use of the grep function to select
only those elements of the list for which the chmod
function failed.
When using nonliteral mode data, you may need to convert an octal string to a number using the oct function. That's because Perl doesn't automatically assume a string contains an octal number just because it happens to have a leading "0".
$DEF_MODE = 0644; # Can't use quotes here!
PROMPT: {
print "New mode? ";
$strmode = <STDIN>;
exit unless defined $strmode; # test for eof
if ($strmode =~ /^\s*$/) { # test for blank line
$mode = $DEF_MODE;
}
elsif ($strmode !~ /^\d+$/) {
print "Want numeric mode, not $strmode\n";
redo PROMPT;
}
else {
$mode = oct($strmode); # converts "755" to 0755
}
chmod $mode, @files;
}
This function works with numeric modes much like the Unix chmod(2)
syscall. If you want a symbolic interface like the one the
chmod(1) command provides, see the File::chmod module on CPAN.
You can also import the symbolic S_I* constants from the Fcntl module:
Some people consider that more readable than 0755. Go figure.use Fcntl ':mode'; chmod S_IRWXU|S_IRGRP|S_IXGRP|S_IROTH|S_IXOTH, @executables;
29.2.11. chomp
This function (normally) deletes a trailing newline from the end of a string contained in a variable. This is a slightly safer version of chop (described next) in that it has no effect upon a string that doesn't end in a newline. More specifically, it deletes the terminating string corresponding to the current value of $/, and not just any last character.chomp VARIABLE chomp LIST chomp
Unlike chop, chomp returns the number of characters deleted. If $/ is "" (in paragraph mode), chomp removes all trailing newlines from the selected string (or strings, if chomping a LIST). You cannot chomp a literal, only a variable.
For example:
while (<PASSWD>) {
chomp; # avoid \n on last field
@array = split /:/;
...
}
With version 5.6, the meaning of chomp changes
slightly in that input disciplines are allowed to override the value
of the $/ variable and mark strings as to how they
should be chomped. This has the advantage that an input discipline
can recognize more than one variety of line terminator (such as
Unicode paragraph and line separators), but still safely
chomp whatever terminates the current line.
29.2.12. chop
This function chops off the last character of a string variable and returns the character chopped. The chop operator is used primarily to remove the newline from the end of an input record, and is more efficient than using a substitution. If that's all you're doing, then it would be safer to use chomp, since chop always shortens the string no matter what's there, and chomp is more selective.chop VARIABLE chop LIST chop
You cannot chop a literal, only a variable.
If you chop a LIST of variables, each string in the list is chopped:
You can chop anything that is an lvalue, including an assignment:@lines = `cat myfile`; chop @lines;
This is different from:chop($cwd = `pwd`); chop($answer = <STDIN>);
which puts a newline into $answer because chop returns the character chopped, not the remaining string (which is in $tmp). One way to get the result intended here is with substr:$answer = chop($tmp = <STDIN>); # WRONG
But this is more commonly written as:$answer = substr <STDIN>, 0, -1;
In the most general case, chop can be expressed in terms of substr:chop($answer = <STDIN>);
Once you understand this equivalence, you can use it to do bigger chops. To chop more than one character, use substr as an lvalue, assigning a null string. The following removes the last five characters of $caravan:$last_char = chop($var); $last_char = substr($var, -1, 1, ""); # same thing
The negative subscript causes substr to count from the end of the string instead of the beginning. If you wanted to save the characters so removed, you could use the four-argument form of substr, creating something of a quintuple chop:substr($caravan, -5) = "";
$tail = substr($caravan, -5, 5, "");
29.2.13. chown
This function changes the owner and group of a list of files. The first two elements of the list must be the numeric UID and GID, in that order. A value of -1 in either position is interpreted by most systems to leave that value unchanged. The function returns the number of files successfully changed. For example:chown LIST
chown($uidnum, $gidnum, 'file1', 'file2') == 2
or die "can't chown file1 or file2: $!";
will set $cnt to 0, 1, or 2, depending on how many files got
changed (in the sense that the operation succeeded, not in the sense
that the owner was different afterward). Here's a more typical usage:
chown($uidnum, $gidnum, @filenames) == @filenames
or die "can't chown @filenames: $!";
Here's a subroutine that accepts a username, looks up the user and
group IDs for you, and does the chown:
sub chown_by_name {
my($user, @files) = @_;
chown((getpwnam($user))[2,3], @files) == @files
or die "can't chown @files: $!";
}
chown_by_name("fred", glob("*.c"));
However, you may not want the group changed as the previous function
does, because the /etc/passwd file associates
each user with a single group even though that user may be a member of
many secondary groups according to /etc/group.
An alternative is to pass a -1 for the GID, which
leaves the group of the file unchanged. If you pass a
-1 as the UID and a valid GID, you can set the
group without altering the owner.
On most systems, you are not allowed to change the ownership of the file unless you're the superuser, although you should be able to change the group to any of your secondary groups. On insecure systems, these restrictions may be relaxed, but this is not a portable assumption. On POSIX systems, you can detect which rule applies like this:
use POSIX qw(sysconf _PC_CHOWN_RESTRICTED);
# only try if we're the superuser or on a permissive system
if ($> == 0 || !sysconf(_PC_CHOWN_RESTRICTED) ) {
chown($uidnum, -1, $filename)
or die "can't chown $filename to $uidnum: $!";
}
29.2.14. chr
chr NUMBER chr
This function returns the character represented by that NUMBER in the character set. For example, chr(65) is "A" in either ASCII or Unicode, and chr(0x263a) is a Unicode smiley face. For the reverse of chr, use ord.
If you'd rather specify your characters by name than by number (for example, "\N{WHITE SMILING FACE}" for a Unicode smiley), see charnames in Chapter 31, "Pragmatic Modules".
29.2.15. chroot
If successful, FILENAME becomes the new root directory for the current process--the starting point for pathnames beginning with "/". This directory is inherited across exec calls and by all subprocesses forked after the chroot call. There is no way to undo a chroot. For security reasons, only the superuser can use this function. Here's some code that approximates what many FTP servers do:chroot FILENAME chroot
chroot((getpwnam('ftp'))[7])
or die "Can't do anonymous ftp: $!\n";
This function is unlikely to work on non-Unix systems. See chroot(2).
29.2.16. close
This function closes the file, socket, or pipe associated with FILEHANDLE. (It closes the currently selected filehandle if the argument is omitted.) It returns true if the close is successful, false otherwise. You don't have to close FILEHANDLE if you are immediately going to do another open on it, since the next open will close it for you. (See open.) However, an explicit close on an input file resets the line counter ($.), while the implicit close done by open does not.close FILEHANDLE close
FILEHANDLE may be an expression whose value can be used as an indirect filehandle (either the real filehandle name or a reference to anything that can be interpreted as a filehandle object).
If the filehandle came from a piped open, close will return false if any underlying syscall fails or if the program at the other end of the pipe exited with nonzero status. In the latter case, the close forces $! ($OS_ERROR) to zero. So if a close on a pipe returns a nonzero status, check $! to determine whether the problem was with the pipe itself (nonzero value) or with the program at the other end (zero value). In either event, $? ($CHILD_ERROR) contains the wait status value (see its interpretation under system) of the command associated with the other end of the pipe. For example:
open(OUTPUT, '| sort -rn | lpr -p') # pipe to sort and lpr
or die "Can't start sortlpr pipe: $!";
print OUTPUT @lines; # print stuff to output
close OUTPUT # wait for sort to finish
or warn $! ? "Syserr closing sortlpr pipe: $!"
: "Wait status $? from sortlpr pipe";
A filehandle produced by dup(2)ing a pipe is treated as an ordinary
filehandle, so close will not wait for the child on that filehandle.
You have to wait for the child by closing the original filehandle.
For example:
open(NETSTAT, "netstat -rn |")
or die "can't run netstat: $!";
open(STDIN, "<&NETSTAT")
or die "can't dup to stdin: $!";
If you close STDIN above, there is no wait, but if you
close NETSTAT, there is.
If you somehow manage to reap an exited pipe child on your own, the close will fail. This could happen if you had a $SIG{CHLD} handler of your own that got triggered when the pipe child exited, or if you intentionally called waitpid on the process ID returned from the open call.
29.2.17. closedir
This function closes a directory opened by opendir and returns the success of that operation. See the examples under readdir. DIRHANDLE may be an expression whose value can be used as an indirect dirhandle, usually the real dirhandle name.closedir DIRHANDLE
29.2.18. connect
This function initiates a connection with another process that is waiting at an accept. The function returns true if it succeeded, false otherwise. NAME should be a packed network address of the proper type for the socket. For example, assuming SOCK is a previously created socket:connect SOCKET, NAME
use Socket;
my ($remote, $port) = ("www.perl.com", 80);
my $destaddr = sockaddr_in($port, inet_aton($remote));
connect SOCK, $destaddr
or die "Can't connect to $remote at port $port: $!";
To disconnect a socket, use either close or shutdown. See also the
examples in the section "Sockets" in Chapter 16, "Interprocess Communication". See connect(2).
29.2.19. cos
This function returns the cosine of EXPR (expressed in radians). For example, the following script will print a cosine table of angles measured in degrees:cos EXPR cos
# Here's the lazy way of getting degrees-to-radians.
$pi = atan2(1,1) * 4;
$piover180 = $pi/180;
# Print table.
for ($deg = 0; $deg <= 90; $deg++) {
printf "%3d %7.5f\n", $deg, cos($deg * $piover180);
}
For the inverse cosine operation, you may use the acos() function
from the Math::Trig or POSIX modules, or use this relation:
sub acos { atan2( sqrt(1 - $_[0] * $_[0]), $_[0] ) }
29.2.20. crypt
This function computes a one-way hash of a string exactly in the manner of crypt(3). This is somewhat useful for checking the password file for lousy passwords,[3] although what you really want to do is prevent people from adding the bad passwords in the first place.crypt PLAINTEXT, SALT
[3] Only people with honorable intentions are allowed to do this.
crypt is intended to be a one-way function, much like breaking eggs to make an omelette. There is no (known) way to decrypt an encrypted password apart from exhaustive, brute-force guessing.
When verifying an existing encrypted string, you should use the encrypted text as the SALT (like crypt($plain, $crypted) eq $crypted). This allows your code to work with the standard crypt, and with more exotic implementations, too.
When choosing a new SALT, you minimally need to create a random two character string whose characters come from the set [./0-9A-Za-z] (like join '', ('.', '/', 0..9, 'A'..'Z', 'a'..'z')[rand 64, rand 64]). Older implementations of crypt only needed the first two characters of the SALT, but code that only gives the first two characters is now considered nonportable. See your local crypt(3) manpage for interesting details.
Here's an example that makes sure that whoever runs this program knows their own password:
$pwd = (getpwuid ($<))[1]; # Assumes we're on Unix.
system "stty -echo"; # or look into Term::ReadKey on CPAN
print "Password: ";
chomp($word = <STDIN>);
print "\n";
system "stty echo";
if (crypt($word, $pwd) ne $pwd) {
die "Sorry...\n";
} else {
print "ok\n";
}
Of course, typing in your own password to whoever asks for it is
unwise.
Shadow password files are slightly more secure than traditional password files, and you might have to be a superuser to access them. Because few programs should run under such powerful privileges, you might have the program maintain its own independent authentication system by storing the crypt strings in a different file than /etc/passwd or /etc/shadow.
The crypt function is unsuitable for encrypting large quantities of data, not least of all because you can't get the information back. Look at the by-module/Crypt and by-module/PGP directories on your favorite CPAN mirror for a slew of potentially useful modules.
29.2.21. dbmclose
This function breaks the binding between a DBM (database management) file and a hash. dbmclose is really just a call to untie with the proper arguments, but is provided for backward compatibility with ancient versions of Perl.dbmclose HASH
29.2.22. dbmopen
This binds a DBM file to a hash (that is, an associative array). (DBM stands for database management, and consists of a set of C library routines that allow random access to records via a hashing algorithm.) HASH is the name of the hash (including the %). DBNAME is the name of the database (without any .dir or .pag extension). If the database does not exist and a valid MODE is specified, the database is created with the protection specified by MODE, as modified by the umask. To prevent creation of the database if it doesn't exist, you may specify a MODE of undef, and the function will return false if it can't find an existing database. Values assigned to the hash prior to the dbmopen are not accessible.dbmopen HASH, DBNAME, MODE
The dbmopen function is really just a call to tie with the proper arguments, but is provided for backward compatibility with ancient versions of Perl. You can control which DBM library you use by using the tie interface directly or by loading the appropriate module before you call dbmopen. Here's an example that works on some systems for versions of DB_File similar to the version in your Netscape browser:
use DB_File;
dbmopen(%NS_Hist, "$ENV{HOME}/.netscape/history.dat", undef)
or die "Can't open netscape history file: $!";
while (($url, $when) = each %NS_Hist) {
next unless defined($when);
chop ($url, $when); # kill trailing null bytes
printf "Visited %s at %s.\n", $url,
scalar(localtime(unpack("V",$when)));
}
If you don't have write access to the DBM file, you can only read
the hash variables, not set them. If you want to test whether you
can write, either use a file test like -w $file, or try setting a
dummy hash entry inside an eval {}, which will trap the exception.
Functions such as keys and values may return huge list values when used on large DBM files. You may prefer to use the each function to iterate over large DBM files so that you don't load the whole thing in memory at once.
Hashes bound to DBM files have the same limitations as the type of DBM package you're using, including restrictions on how much data you can put into a bucket. If you stick to short keys and values, it's rarely a problem. See also the DB_File module in Chapter 32, "Standard Modules".
Another thing you should bear in mind is that many existing DBM databases contain null-terminated keys and values because they were set up with C programs in mind. The Netscape history file and the old sendmail aliases file are examples. Just use "$key\0" when pulling out a value, and remove the null from the value.
$alias = $aliases{"postmaster\0"};
chop $alias; # kill the null
There is currently no built-in way to lock a generic DBM file. Some
would consider this a bug. The GDBM_File module does attempt to provide
locking at the granularity of the entire file. When in doubt,
your best bet is to use a separate lock file.
29.2.23. defined
This function returns a Boolean value saying whether EXPR has a defined value or not. Most of the data you deal with is defined, but a scalar that contains no valid string, numeric, or reference value is said to contain the undefined value, or undef for short. Initializing a scalar variable to a particular value will define it, and it will stay defined until you assign an undefined value to it or explicitly call the undef function on that variable.defined EXPR defined
Many operations return undef under exceptional conditions, such as at end-of-file, when using an uninitialized variable's value, an operating system error, etc. Since undef is just one kind of false value, a simple Boolean test does not distinguish between undef, numeric zero, the null string, and the one-character string, "0"--all of which are equally false. The defined function allows you to distinguish between an undefined null string and a defined null string when you're using operators that might return a real null string.
Here is a fragment that tests a scalar value from a hash:
print if defined $switch{D};
When used on a hash element like this, defined only tells you
whether the value is defined, not whether the key has an entry in
the hash. It's possible to have a key whose value is undefined;
the key itself however still exists. Use exists to determine
whether the hash key exists.
In the next example we exploit the convention that some operations return the undefined value when you run out of data:
And in this one, we do the same thing with the getpwent function for retrieving information about the system's users.print "$val\n" while defined($val = pop(@ary));
setpwent();
while (defined($name = getpwent())) {
print "<<$name>>\n";
}
endpwent();
The same thing goes for error returns from syscalls that could validly return a false value:
die "Can't readlink $sym: $!"
unless defined($value = readlink $sym);
You may also use defined to see whether a subroutine has been
defined yet. This makes it possible to avoid blowing up on nonexistent
subroutines (or subroutines that have been declared but never given a
definition):
indir("funcname", @arglist);
sub indir {
my $subname = shift;
no strict 'refs'; # so we can use subname indirectly
if (defined &$subname) {
&$subname(@_); # or $subname->(@_);
}
else {
warn "Ignoring call to invalid function $subname";
}
}
Use of defined on aggregates (hashes and arrays) is deprecated.
(It used to report whether memory for that aggregate had ever been
allocated.) Instead, use a simple Boolean test
to see whether the array or hash has any elements:
if (@an_array) { print "has array elements\n" }
if (%a_hash) { print "has hash members\n" }
See also undef and exists.
29.2.24. delete
This function deletes an element (or a slice of elements) from the specified hash or array. (See unlink if you want to delete a file.) The deleted elements are returned in the order specified, though this behavior is not guaranteed for tied variables such as DBM files. After the delete operation, the exists function will return false on any deleted key or index. (In contrast, after the undef function, the exists function continues to return true, because the undef function only undefines the value of the element, but doesn't delete the element itself.)delete EXPR
Deleting from the %ENV hash modifies the environment. Deleting from a hash that is bound to a (writable) DBM file deletes the entry from that DBM file.
Historically, you could only delete from a hash, but with Perl version 5.6 you may also delete from an array. Deleting from an array causes the element at the specified position to revert to a completely uninitialized state, but it doesn't close up the gap, since that would change the positions of all the subsequent entries. Use a splice for that. (However, if you delete the final element in an array, the array size will shrink by one (or more, depending on the position of the next largest existing element (if any))).
EXPR can be arbitrarily complicated, provided that the final operation is a hash or array lookup:
# set up array of array of hash
$dungeon[$x][$y] = \%properties;
# delete one property from hash
delete $dungeon[$x][$y]{"OCCUPIED"};
# delete three properties all at once from hash
delete @{ $dungeon[$x][$y] }{ "OCCUPIED", "DAMP", "LIGHTED" };
# delete reference to %properties from array
delete $dungeon[$x][$y];
The following naïve example inefficiently deletes all the values of
a %hash:
foreach $key (keys %hash) {
delete $hash{$key};
}
And so does this:
delete @hash{keys %hash};
But both of these are slower than just assigning the empty list
or undefining it:
Likewise for arrays:%hash = (); # completely empty %hash undef %hash; # forget %hash ever existed
foreach $index (0 .. $#array) {
delete $array[$index];
}
and:
are less efficient than either of:delete @array[0 .. $#array];
@array = (); # completely empty @array undef @array; # forget @array ever existed
29.2.25. die
Outside an eval, this function prints the concatenated value of LIST to STDERR and exits with the current value of $! (the C-library errno variable). If $! is 0, it exits with the value of $? >> 8 (which is the status of the last reaped child from a system, wait, close on a pipe, or `command`). If $? >> 8 is 0, it exits with 255.die LIST die
Within an eval, the function sets the $@ variable to the error message that would have otherwise been produced, then aborts the eval, which returns undef. The die function can thus be used to raise named exceptions that can be caught at a higher level in the program. See eval later in this chapter.
If LIST is a single object reference, that object is assumed to be an exception object and is returned unmodified as the exception in $@.
If LIST is empty and $@ already contains a string value (typically from a previous eval) that value is reused after appending "\t...propagated". This is useful for propagating (reraising) exceptions:
eval { ... };
die unless $@ =~ /Expected exception/;
If LIST is empty and $@ already contains an exception object, the
$@->PROPAGATE method is called to determine how the exception should
be propagated.
If LIST is empty and $@ is empty, then the string "Died" is used.
If the final value of LIST does not end in a newline (and you're not passing an exception object), the current script filename, line number, and input line number (if any) are appended to the message, as well as a newline. Hint: sometimes appending ", stopped" to your message will cause it to make better sense when the string "at scriptname line 123" is appended. Suppose you are running script canasta; consider the difference between the following two ways of dying:
which produce, respectively:die "/usr/games is no good"; die "/usr/games is no good, stopped";
If you want your own error messages reporting the filename and line number, use the __FILE__ and __LINE__ special tokens:/usr/games is no good at canasta line 123. /usr/games is no good, stopped at canasta line 123.
This produces output like:die '"', __FILE__, '", line ', __LINE__, ", phooey on you!\n";
One other style issue--consider the following equivalent examples:"canasta", line 38, phooey on you!
Because the important part is the chdir, the second form is generally preferred.die "Can't cd to spool: $!\n" unless chdir '/usr/spool/news'; chdir '/usr/spool/news' or die "Can't cd to spool: $!\n"
See also exit, warn, %SIG, and the Carp module.
29.2.26. do (block)
The doBLOCK form executes the sequence of statements in the BLOCK and returns the value of the last expression evaluated in the block. When modified by a while or until statement modifier, Perl executes the BLOCK once before testing the loop condition. (On other statements the loop modifiers test the conditional first.) The doBLOCK itself does not count as a loop, so the loop control statements next, last, or redo cannot be used to leave or restart the block. See the section "Bare Blocks" in Chapter 4, "Statements and Declarations", for workarounds.do BLOCK
29.2.27. do (file)
The doFILE form uses the value of FILE as a filename and executes the contents of the file as a Perl script. Its primary use is (or rather was) to include subroutines from a Perl subroutine library, so that:do FILE
is rather like:do 'stat.pl';
except that do is more efficient, more concise, keeps track of the current filename for error messages, searches all the directories listed in the @INC array, and updates %INC if the file is found. (See Chapter 28, "Special Names".) It also differs in that code evaluated with doFILE cannot see lexicals in the enclosing scope, whereas code in evalFILE does. It's the same, however, in that it reparses the file every time you call it--so you might not want to do this inside a loop unless the filename itself changes at each loop iteration.scalar eval `cat stat.pl`; # `type stat.pl` on Windows
If do can't read the file, it returns undef and sets $! to the error. If do can read the file but can't compile it, it returns undef and sets an error message in $@. If the file is successfully compiled, do returns the value of the last expression evaluated.
Inclusion of library modules (which have a mandatory .pm suffix) is better done with the use and require operators, which also do error checking and raise an exception if there's a problem. They also offer other benefits: they avoid duplicate loading, help with object-oriented programming, and provide hints to the compiler on function prototypes.
But doFILE is still useful for such things as reading program configuration files. Manual error checking can be done this way:
# read in config files: system first, then user
for $file ("/usr/share/proggie/defaults.rc",
"$ENV{HOME}/.someprogrc")
{
unless ($return = do $file) {
warn "couldn't parse $file: $@" if $@;
warn "couldn't do $file: $!" unless defined $return;
warn "couldn't run $file" unless $return;
}
}
A long-running daemon could periodically examine the timestamp on
its configuration file, and if the file has changed since it was
last read in, the daemon could use do to reload that file. This
is more tidily accomplished with do than with require or use.
29.2.28. do (subroutine)
The doSUBROUTINE(LIST) is a deprecated form of a subroutine call. An exception is raised if the SUBROUTINE is undefined. See Chapter 6, "Subroutines".do SUBROUTINE(LIST)
29.2.29. dump
This function causes an immediate core dump. Primarily this is so that you can use the undump program (not supplied) to turn your core dump into an executable binary after having initialized all your variables at the beginning of the program. When the new binary is executed it will begin by executing a gotoLABEL (with all the restrictions that goto suffers). Think of it as a goto with an intervening core dump and reincarnation. If LABEL is omitted, the program is restarted from the top. Warning: any files opened at the time of the dump will not be open any more when the program is reincarnated, with possible resulting confusion on the part of Perl. See also the -u command-line option in Chapter 19, "The Command-Line Interface".dump LABEL dump
This function is now largely obsolete, partly because it's difficult in the extreme to convert a core file into an executable in the general case, and because various compiler backends for generating portable bytecode and compilable C code have superseded it.
If you're looking to use dump to speed up your program, check out the discussion of efficiency matters in Chapter 24, "Common Practices", as well the Perl native-code generator in Chapter 18, "Compiling". You might also consider autoloading or selfloading, which at least make your program appear to run faster.
29.2.30. each
This function steps through a hash one key/value pair at a time. When called in list context, each returns a two-element list consisting of the key and value for the next element of a hash, so that you can iterate over it. When called in scalar context, each returns just the key for the next element in the hash. When the hash is entirely read, the empty list is returned, which when assigned produces a false value in scalar context, such as a loop test. The next call to each after that will start iterating again. The typical use is as follows, using predefined %ENV hash:each HASH
while (($key,$value) = each %ENV) {
print "$key=$value\n";
}
Internally, a hash maintains its own entries in an apparently random
order. The each function iterates through this sequence because
every hash remembers which entry was last returned. The actual
ordering of this sequence is subject to change in future versions
of Perl, but is guaranteed to be in the same order as the
keys (or values) function would produce on the same (unmodified)
hash.
There is a single iterator for each hash, shared by all each, keys, and values function calls in the program; it can be reset by reading all the elements from the hash, or by evaluating keys %hash or values %hash. If you add or delete elements of a hash while you're iterating over it, the resulting behavior is not well-defined: entries might get skipped or duplicated.
See also keys, values, and sort.
29.2.31. eof
This function returns true if the next read on FILEHANDLE would return end-of-file, or if FILEHANDLE is not open. FILEHANDLE may be an expression whose value gives the real filehandle, or a reference to a filehandle object of some sort. An eof without an argument returns the end-of-file status for the last file read. An eof() with empty parentheses () tests the ARGV filehandle (most commonly seen as the null filehandle in <>). Therefore, inside a while (<>) loop, an eof() with parentheses will detect the end of only the last of a group of files. Use eof (without the parentheses) to test each file in a while (<>) loop. For example, the following code inserts dashes just before the last line of the last file:eof FILEHANDLE eof() eof
while (<>) {
if (eof()) {
print "-" x 30, "\n";
}
print;
}
On the other hand, this script resets line numbering on each input
file:
# reset line numbering on each input file
while (<>) {
next if /^\s*#/; # skip comments
print "$.\t$_";
} continue {
close ARGV if eof; # Not eof()!
}
Like "$" in a sed program, eof tends to show up in line number
ranges. Here's a script that prints lines from /pattern/ to end of
each input file:
while (<>) {
print if /pattern/ .. eof;
}
Here, the flip-flop operator (..) evaluates the pattern match for each line. Until the pattern matches, the
operator returns false. When it finally matches, the operator
starts returning true, causing the lines to be printed. When the
eof operator finally returns true (at the end of the file being
examined), the flip-flop operator resets, and starts returning false
again for the next file in @ARGV.
Warning: The eof function reads a byte and then pushes it back on the input stream with ungetc(3), so it is not useful in an interactive context. In fact, experienced Perl programmers rarely use eof, since the various input operators already behave politely in while-loop conditionals. See the example in the description of foreach in Chapter 4, "Statements and Declarations".
29.2.32. eval
The eval keyword serves two distinct but related purposes in Perl. These purposes are represented by two forms of syntax, evalBLOCK and evalEXPR. The first form traps run-time exceptions (errors) that would otherwise prove fatal, similar to the "try block" construct in C++ or Java. The second form compiles and executes little bits of code on the fly at run time, and also (conveniently) traps any exceptions just like the first form. But the second form runs much slower than the first form, since it must parse the string every time. On the other hand, it is also more general. Whichever form you use, eval is the preferred way to do all exception handling in Perl.eval BLOCK eval EXPR eval
For either form of eval, the value returned from an eval is the value of the last expression evaluated, just as with subroutines. Similarly, you may use the return operator to return a value from the middle of the eval. The expression providing the return value is evaluated in void, scalar, or list context, depending on the context of the eval itself. See wantarray for more on how the evaluation context can be determined.
If there is a trappable error (including any produced by the die operator), eval returns undef and puts the error message (or object) in $@. If there is no error, $@ is guaranteed to be set to the null string, so you can test it reliably afterward for errors. A simple Boolean test suffices:
eval { ... }; # trap run-time errors
if ($@) { ... } # handle error
The evalBLOCK form is
syntax-checked at compile time, so it is quite efficient. (People
familiar with the slow evalEXPR form are occasionally confused on this
issue.) Since the code in the BLOCK is
compiled at the same time as the surrounding code, this form of
eval cannot trap syntax errors.
The evalEXPR form can trap syntax errors because it parses the code at run time. (If the parse is unsuccessful, it places the parse error in $@, as usual.) Otherwise, it executes the value of EXPR as though it were a little Perl program. The code is executed in the context of the current Perl program, which means that it can see any enclosing lexicals from a surrounding scope, and that any non-local variable settings remain in effect after the eval is complete, as do any subroutine or format definitions. The code of the eval is treated as a block, so any locally scoped variables declared within the eval last only until the eval is done. (See my and local.) As with any code in a block, a final semicolon is not required.
Here is a simple Perl shell. It prompts the user to enter a string of arbitrary Perl code, compiles and executes that string, and prints whatever error occurred:
print "\nEnter some Perl code: ";
while (<STDIN>) {
eval;
print $@;
print "\nEnter some more Perl code: ";
}
Here is a rename program to do a mass renaming of
files using a Perl expression:
#!/usr/bin/perl
# rename - change filenames
$op = shift;
for (@ARGV) {
$was = $_;
eval $op;
die if $@;
# next line calls the built-in function, not the script by the same name
rename($was,$_) unless $was eq $_;
}
You'd use that program like this:
Since eval traps errors that would otherwise prove fatal, it is useful for determining whether particular features (such as fork or symlink) are implemented.$ rename 's/\.orig$//' *.orig $ rename 'y/A-Z/a-z/ unless /^Make/' * $ rename '$_ .= ".bad"' *.f
Because evalBLOCK is syntax-checked at compile time, any syntax error is reported earlier. Therefore, if your code is invariant and both evalEXPR and evalBLOCK will suit your purposes equally well, the BLOCK form is preferred. For example:
# make divide-by-zero nonfatal
eval { $answer = $a / $b; }; warn $@ if $@;
# same thing, but less efficient if run multiple times
eval '$answer = $a / $b'; warn $@ if $@;
# a compile-time syntax error (not trapped)
eval { $answer = }; # WRONG
# a run-time syntax error
eval '$answer ='; # sets $@
Here, the code in the BLOCK has to be valid Perl code to make it past
the compile phase. The code in the EXPR doesn't get examined
until run time, so it doesn't cause an error until run time.
The block of evalBLOCK does not count as a loop, so the loop control statements next, last, or redo cannot be used to leave or restart the block.
29.2.33. exec
The exec function terminates the current program and executes an external command and never returns!!! Use system instead of exec if you want to recover control after the commands exits. The exec function fails and returns false only if the command does not exist and if it is executed directly instead of via your system's command shell (discussed below).exec PATHNAME LIST exec LIST
If there is only one scalar argument, the argument is checked for shell metacharacters. If metacharacters are found, the entire argument is passed to the system's standard command interpreter (/bin/sh under Unix). If there are no metacharacters, the argument is split into words and executed directly, since in the interests of efficiency this bypasses all the overhead of shell processing. It also gives you more control of error recovery should the program not exist.
If there is more than one argument in LIST, or if LIST is an array with more than one value, the system shell will never be used. This also bypasses any shell processing of the command. The presence or absence of metacharacters in the arguments doesn't affect this list-triggered behavior, which makes it the preferred form in security-conscious programs that do not wish to expose themselves to potential shell escapes.
This example causes the currently running Perl program to replace itself with the echo program, which then prints out the current argument list:
This example shows that you can exec a pipeline, not just a single program.exec 'echo', 'Your arguments are: ', @ARGV;
exec "sort $outfile | uniq"
or die "Can't do sort/uniq: $!\n";
Ordinarily, exec never returns--if it does return,
it always returns false, and you should check $! to
find out what went wrong. Be aware that in older releases of Perl,
exec (and system) did not flush
your output buffer, so you needed to enable command buffering by
setting $| on one or more filehandles to avoid lost
output in the case of exec, or misordered output in
the case of system. This situation was largely
remedied in the 5.6 release of Perl.
When you ask the operating system to execute a new program within an existing process (as Perl's exec function does), you tell the system the location of the program to execute, but you also tell the new program (through its first argument) the name under which the program was invoked. Customarily, the name you tell it is just a copy of the location of the program, but it doesn't necessarily have to be, since there are two separate arguments at the level of the C language. When it is not a copy, you have the odd result that the new program thinks it's running under a name that may be totally different from the actual pathname where the program resides. Often this doesn't matter to the program in question, but some programs do care and adopt a different persona depending on what they think their name is. For example, the vi editor looks to see whether it was called as "vi" or as "view". If invoked as "view", it automatically enables read-only mode, just as though it was called with the -R command-line option.
This is where exec's optional PATHNAME parameter comes into play. Syntactically, it goes in the indirect-object slot like the filehandle for print or printf. Therefore, it doesn't take a comma after it, because it's not exactly part of the argument list. (In a sense, Perl takes the opposite approach from the operating system in that it assumes the first argument is the important one, and lets you modify the pathname if it differs.) For example:
$editor = "/usr/bin/vi";
exec $editor "view", @files # trigger read-only mode
or die "Couldn't execute $editor: $!\n";
As with any other indirect object, you can also replace the simple scalar holding the program name with a
block containing arbitrary code, which simplifies the previous example to:
exec { "/usr/bin/vi" } "view" @files # trigger read-only mode
or die "Couldn't execute $editor: $!\n";
As we mentioned earlier, exec treats a discrete list of arguments as an indication that it should bypass shell processing. However, there is one place where you might still get
tripped up. The exec call (and system, too) will not distinguish
between a single scalar argument and an array containing only one
element.
@args = ("echo surprise"); # just one element in list
exec @args # still subject to shell escapes
or die "exec: $!"; # because @args == 1
To avoid this, you can use the PATHNAME syntax, explicitly
duplicating the first argument as the pathname, which forces the rest
of the arguments to be interpreted as a list, even if there is only one
of them:
exec { $args[0] } @args # safe even with one-argument list
or die "can't exec @args: $!";
The first version, the one without the curlies, runs the echo
program, passing it "surprise" as an argument. The second version
doesn't--it tries to run a program literally called echo surprise,
doesn't find it (we hope), and sets $! to a nonzero value indicating failure.
Because the exec function is most often used shortly after a fork, it is assumed that anything that normally happens when a Perl process terminates should be skipped. Upon an exec, Perl will not call your END blocks, nor will it call any DESTROY methods associated with any objects. Otherwise, your child process would end up doing the cleanup you expected the parent process to do. (We wish that were the case in real life.)
Because it's such a common mistake to use exec instead of system, Perl warns you if there is a following statement that isn't die, warn, or exit when run with the popular -w command-line option, or if you've used the use warnings qw(exec syntax) pragma. If you really want to follow an exec with some other statement, you can use either of these styles to avoid the warning:
exec ('foo') or print STDERR "couldn't exec foo: $!";
{ exec ('foo') }; print STDERR "couldn't exec foo: $!";
As the second line above shows, a call to exec that
is the last statement in a block is exempt from this warning.
See also system.
29.2.34. exists
This function returns true if the specified hash key or array index exists in its hash or array. It doesn't matter whether the corresponding value is true or false, or whether the value is even defined.exists EXPR
print "True\n" if $hash{$key};
print "Defined\n" if defined $hash{$key};
print "Exists\n" if exists $hash{$key};
print "True\n" if $array[$index];
print "Defined\n" if defined $array[$index];
print "Exists\n" if exists $array[$index];
An element can be true only if it's defined, and can be defined
only if it exists, but the reverse doesn't necessarily hold.
EXPR can be arbitrarily complicated, provided that the final operation is a hash key or array index lookup:
if (exists $hash{A}{B}{$key}) { ... }
Although the last element will not spring into existence just because
its existence was tested, intervening ones will. Thus
$$hash{"A"} and
$hash{"A"}->{"B"} will both spring into
existence. This is not a function of exists,
per se; it happens anywhere the arrow
operator is used (explicitly or implicitly):
undef $ref;
if (exists $ref->{"Some key"}) { }
print $ref; # prints HASH(0x80d3d5c)
Even though the "Some key" element didn't spring into existence, the
previously undefined $ref variable did suddenly come to hold an
anonymous hash. This is a surprising instance of autovivification
in what does not at first--or even second--glance appear to be an
lvalue context. This behavior is likely to be fixed in a future
release. As a workaround, you can nest your calls:
if ($ref and
exists $ref->[$x] and
exists $ref->[$x][$y] and
exists $ref->[$x][$y]{$key} and
exists $ref->[$x][$y]{$key}[2] ) { ... }
If EXPR is the name of a subroutine, the exists function will return
true if that subroutine has been declared, even if it has not yet been
defined. The following will just print "Exists":
Using exists on a subroutine name can be useful for an AUTOLOAD subroutine that needs to know whether a particular package wants a particular subroutine to be defined. The package can indicate this by declaring a stub sub like flub.sub flub; print "Exists\n" if exists &flub; print "Defined\n" if defined &flub;
29.2.35. exit
This function evaluates EXPR as an integer and exits immediately with that value as the final error status of the program. If EXPR is omitted, the function exits with 0 status (meaning "no error"). Here's a fragment that lets a user exit the program by typing x or X:exit EXPR exit
You shouldn't use exit to abort a subroutine if there's any chance that someone might want to trap whatever error happened. Use die instead, which can be trapped by an eval. Or use one of die's wrappers from the Carp module, like croak or confess.$ans = <STDIN>; exit if $ans =~ /^[Xx]/;
We said that the exit function exits immediately, but that was a bald-faced lie. It exits as soon as possible, but first it calls any defined END routines for at-exit handling. These routines cannot abort the exit, although they can change the eventual exit value by setting the $? variable. Likewise, any class that defines a DESTROY method will invoke that method on behalf of all its objects before the real program exits. If you really need to bypass exit processing, you can call the POSIX module's _exit function to avoid all END and destructor processing. And if POSIX isn't available, you can exec "/bin/false" or some such.
29.2.36. exp
This function returns e to the power of EXPR. To get the value of e, just use exp(1). For general exponentiation of different bases, use the ** operator we stole from FORTRAN:exp EXPR exp
use Math::Complex; print -exp(1) ** (i * pi); # prints 1
29.2.37. fcntl
This function calls your operating system's file control functions, as documented in the fcntl(2) manpage. Before you call fcntl, you'll probably first have to say:fcntl FILEHANDLE, FUNCTION, SCALAR
to load the correct constant definitions.use Fcntl;
SCALAR will be read or written (or both) depending on the FUNCTION. A pointer to the string value of SCALAR will be passed as the third argument of the actual fcntl call. (If SCALAR has no string value but does have a numeric value, that value will be passed directly rather than passing a pointer to the string value.) See the Fcntl module for a description of the more common permissible values for FUNCTION.
The fcntl function will raise an exception if used on a system that doesn't implement fcntl(2). On systems that do implement it, you can do such things as modify the close-on-exec flags (if you don't want to play with the $^F ($SYSTEM_FD_MAX) variable), modify the nonblocking I/O flags, emulate the lockf(3) function, and arrange to receive the SIGIO signal when I/O is pending.
Here's an example of setting a filehandle named REMOTE to be nonblocking at the system level. This makes any input operation return immediately if nothing is available when reading from a pipe, socket, or serial line that would otherwise block. It also works to cause output operations that normally would block to return a failure status instead. (For those, you'll likely have to negotiate $| as well.)
use Fcntl qw(F_GETFL F_SETFL O_NONBLOCK);
$flags = fcntl(REMOTE, F_GETFL, 0)
or die "Can't get flags for the socket: $!\n";
$flags = fcntl(REMOTE, F_SETFL, $flags | O_NONBLOCK)
or die "Can't set flags for the socket: $!\n";
The return value of fcntl (and ioctl) is as follows:
| Syscall Returns | Perl Returns |
|---|---|
| -1 | undef |
| 0 | String "0 but true" |
| anything else | That number |
Thus Perl returns true on success and false on failure, yet you can still easily determine the actual value returned by the operating system:
Here, even the string "0 but true" prints as 0, thanks to the %d format. This string is true in Boolean context and 0 in numeric context. (It is also happily exempt from the normal warnings on improper numeric conversions.)$retval = fcntl(...) || -1; printf "fcntl actually returned %d\n", $retval;
29.2.38. fileno
This function returns the file descriptor underlying a filehandle. If the filehandle is not open, fileno returns undef. A file descriptor is a small, non-negative integer like 0 or 1, in contrast to filehandles like STDIN and STDOUT, which are symbols. Unfortunately, the operating system doesn't know about your cool symbols. It only thinks of open files in terms of these small file numbers, and although Perl will usually do the translations for you automatically, occasionally you have to know the actual file descriptor.fileno FILEHANDLE
So, for example, the fileno function is useful for constructing bitmaps for select and for passing to certain obscure system calls if syscall(2) is implemented. It's also useful for double-checking that the open function gave you the file descriptor you wanted and for determining whether two filehandles use the same system file descriptor.
if (fileno(THIS) == fileno(THAT)) {
print "THIS and THAT are dups\n";
}
If FILEHANDLE is an expression, the value is taken as an indirect
filehandle, generally its name or a reference to something resembling
a filehandle object.
One caution: don't count on the association of a Perl filehandle and a numeric file descriptor throughout the life of the program. If a file has been closed and reopened, the file descriptor may change. Perl takes a bit of trouble to try to ensure that certain file descriptors won't be lost if an open on them fails, but it only does this for file descriptors that don't exceed the current value of the special $^F ($SYSTEM_FD_MAX) variable (by default, 2). Although filehandles STDIN, STDOUT, and STDERR start out with file descriptors of 0, 1, and 2 (the Unix standard convention), even they can change if you start closing and opening them with wild abandon. You can't get into trouble with 0, 1, and 2 as long as you always reopen immediately after closing. The basic rule on Unix systems is to pick the lowest available descriptor, and that'll be the one you just closed.
29.2.39. flock
The flock function is Perl's portable file-locking interface, although it locks only entire files, not records. The function manages locks on the file associated with FILEHANDLE, returning true for success and false otherwise. To avoid the possibility of lost data, Perl flushes your FILEHANDLE before locking or unlocking it. Perl might implement its flock in terms of flock(2), fcntl(2), lockf(3), or some other platform-specific lock mechanism, but if none of these is available, calling flock raises an exception. See the section "File Locking" in Chapter 16, "Interprocess Communication".flock FILEHANDLE, OPERATION
OPERATION is one of LOCK_SH, LOCK_EX, or LOCK_UN, possibly ORed with LOCK_NB. These constants are traditionally valued 1, 2, 8, and 4, but you can use the symbolic names if you import them from the Fcntl module, either individually or as a group using the :flock tag.
LOCK_SH requests a shared lock, so it's typically used for reading. LOCK_EX requests an exclusive lock, so it's typically used for writing. LOCK_UN releases a previously requested lock; closing the file also releases any locks. If the LOCK_NB bit is used with LOCK_SH or LOCK_EX, flock returns immediately rather than waiting for an unavailable lock. Check the return status to see whether you got the lock you asked for. If you don't use LOCK_NB, you might wait indefinitely for the lock to be granted.
Another nonobvious but traditional aspect of flock is that its locks are merely advisory. Discretionary locks are more flexible but offer fewer guarantees than mandatory ones. This means that files locked with flock may be modified by programs that do not also use flock. Cars that stop for red lights get on well with each other, but not with cars that don't stop for red lights. Drive defensively.
Some implementations of flock cannot lock things over the network. While you could in theory use the more system-specific fcntl for that, the jury (having sequestered itself on the case for a decade or so) is still out on whether this is (or even can be) reliable.
Here's a mailbox appender for Unix systems that use flock(2) to lock mailboxes:
use Fcntl qw/:flock/; # import LOCK_* constants
sub mylock {
flock(MBOX, LOCK_EX)
or die "can't lock mailbox: $!";
# in case someone appended while we were waiting
# and our stdio buffer is out of sync
seek(MBOX, 0, 2)
or die "can't seek to the end of mailbox: $!";
}
open(MBOX, ">>/usr/spool/mail/$ENV{'USER'}")
or die "can't open mailbox: $!";
mylock();
print MBOX $msg, "\n\n";
close MBOX
or die "can't close mailbox: $!";
On systems that support a real flock(2)
syscall, locks are inherited across fork calls.
Other implementations are not so lucky, and are likely to lose the
locks across forks. See also the DB_File module in
Chapter 32, "Standard Modules" for other
flock examples.
29.2.40. fork
This function creates two processes out of one by invoking the fork(2) syscall. If it succeeds, the function returns the new child process's ID to the parent process and 0 to the child process. If the system doesn't have sufficient resources to allocate a new process, the call fails and returns undef. File descriptors (and sometimes locks on those descriptors) are shared, while everything else is copied--or at least made to look that way.fork
In versions of Perl prior to 5.6, unflushed buffers remain unflushed in both processes, which means you may need to set $| on one or more filehandles earlier in the program to avoid duplicate output.
A nearly bulletproof way to launch a child process while checking for "cannot fork" errors would be:
use Errno qw(EAGAIN);
FORK: {
if ($pid = fork) {
# parent here
# child process pid is available in $pid
}
elsif (defined $pid) { # $pid is zero here if defined
# child here
# parent process pid is available with getppid
}
elsif ($! == EAGAIN) {
# EAGAIN is the supposedly recoverable fork error
sleep 5;
redo FORK;
}
else {
# weird fork error
die "Can't fork: $!\n";
}
}
These precautions are not necessary on operations that do an implicit
fork(2), such as
system, backticks, or opening a process as a
filehandle, because Perl automatically retries a fork on a temporary
failure when it's doing the fork for you. Be
careful to end the child code with an exit, or else
your child will inadvertently leave the conditional block and start
executing code intended only for the parent process.
If you fork without ever waiting on your children, you will accumulate zombies (exited processes whose parents haven't waited on them yet). On some systems, you can avoid this by setting $SIG{CHLD} to "IGNORE"; on most, you must wait for your moribund children. See the wait function for examples of doing this, or see the "Signals" section of Chapter 16, "Interprocess Communication" for more on SIGCHLD.
If a forked child inherits system file descriptors like STDIN and STDOUT that are connected to a remote pipe or socket, you may have to reopen these in the child to /dev/null. That's because even when the parent process exits, the child will live on with its copies of those filehandles. The remote server (such as, say, a CGI script or a background job launched from a remote shell) will appear to hang because it's still waiting for all copies to be closed. Reopening the system filehandles to something else fixes this.
On most systems supporting fork(2), great care has gone into making it extremely efficient (for example, using copy-on-write technology on data pages), making it the dominant paradigm for multitasking over the last few decades. The fork function is unlikely to be implemented efficiently, or perhaps at all, on systems that don't resemble Unix. For example, Perl 5.6 emulates a proper fork even on Microsoft systems, but no assurances can be made on performance at this point. You might have more luck there with the Win32::Process module.
29.2.41. format
format NAME =
picture line
value list
...
.
This function declares a named sequence of picture lines (with
associated values) for use by the write function.
If NAME is omitted, the name defaults to
STDOUT, which happens to be the default format name
for the STDOUT filehandle. Since, like a
sub declaration, this is a package-global
declaration that happens at compile time, any variables used in the
value list need to be visible at the point of the format's
declaration. That is, lexically scoped variables must be declared
earlier in the file, while dynamically scoped variables merely need to
be set at the time write is called. Here's an
example (which assumes we've already calculated
$cost and $quantity):
my $str = "widget"; # Lexically scoped variable.
format Nice_Output =
Test: @<<<<<<<< @||||| @>>>>>
$str, $%, '$' . int($num)
.
local $~ = "Nice_Output"; # Select our format.
local $num = $cost * $quantity; # Dynamically scoped variable.
write;
Like filehandles, format names are identifiers that exist in a symbol
table (package) and may be fully qualified by package name. Within
the typeglobs of a symbol table's entries, formats reside in their own
namespace, which is distinct from filehandles, directory handles,
scalars, arrays, hashes, and subroutines. Like those other six types,
however, a format named Whatever would also be
affected by a local on the
*Whatever typeglob. In other words, a format is
just another gadget contained in a typeglob, independent of the other
gadgets.
The "Format Variables" section in Chapter 7, "Formats" contains numerous details and examples of their use. Chapter 28, "Special Names" describes the internal format-specific variables, and the English and IO::Handle modules provide easier access to them.
29.2.42. formline
This is an internal function used by formats, although you may also call it yourself. It always returns true. It formats a list of values according to the contents of PICTURE, placing the output into the format output accumulator, $^A (or $ACCUMULATOR if you use the English module). Eventually, when a write is done, the contents of $^A are written to some filehandle, but you could also read $^A yourself and then set $^A back to "". A format typically does one formline per line of form, but the formline function itself doesn't care how many newlines are embedded in the PICTURE. This means that the ~ and ~~ tokens will treat the entire PICTURE as a single line. You may therefore need to use multiple formlines to implement a single record-format, just as the format compiler does internally.formline PICTURE, LIST
Be careful if you put double quotes around the picture, since an @ character may be taken to mean the beginning of an array name. See "Formats" in Chapter 6, "Subroutines" for example uses.
29.2.43. getc
This function returns the next byte from the input file attached to FILEHANDLE. It returns undef at end-of-file, or if an I/O error was encountered. If FILEHANDLE is omitted, the function reads from STDIN.getc FILEHANDLE getc
This function is somewhat slow, but occasionally useful for single-character (byte, really) input from the keyboard--provided you manage to get your keyboard input unbuffered. This function requests unbuffered input from the standard I/O library. Unfortunately, the standard I/O library is not so standard as to provide a portable way to tell the underlying operating system to supply unbuffered keyboard input to the standard I/O system. To do that, you have to be slightly more clever, and in an operating-system-dependent fashion. Under Unix you might say this:
if ($BSD_STYLE) {
system "stty cbreak </dev/tty >/dev/tty 2>&1";
} else {
system "stty", "-icanon", "eol", "\001";
}
$key = getc;
if ($BSD_STYLE) {
system "stty -cbreak </dev/tty >/dev/tty 2>&1";
} else {
system "stty", "icanon", "eol", "^@"; # ASCII NUL
}
print "\n";
This code puts the next character (byte) typed on the terminal in the
string $key. If your stty
program has options like cbreak, you'll need to use
the code where $BSD_STYLE is true. Otherwise,
you'll need to use the code where it is false. Determining the
options for stty(1) is left as an exercise
to the reader.
The POSIX module provides a more portable version of this using the POSIX::getattr function. See also the Term::ReadKey module from your nearest CPAN site for a more portable and flexible approach.
29.2.44. getgrent
These routines iterate through your /etc/group file (or maybe someone else's /etc/group file, if it's coming from a server somewhere). The return value from getgrent in list context is:getgrent setgrent endgrent
where $members contains a space-separated list of the login names of the members of the group. To set up a hash for translating group names to GIDs, say this:($name, $passwd, $gid, $members)
while (($name, $passwd, $gid) = getgrent) {
$gid{$name} = $gid;
}
In scalar context, getgrent returns only the group
name. The standard User::grent module supports a
by-name interface to this function. See
getgrent(3).
29.2.45. getgrgid
This function looks up a group file entry by group number. The return value in list context is:getgrgid GID
where $members contains a space-separated list of the login names of the members of the group. If you want to do this repeatedly, consider caching the data in a hash using getgrent.($name, $passwd, $gid, $members)
In scalar context, getgrgid returns only the group name. The User::grent module supports a by-name interface to this function. See getgrgid(3).
29.2.46. getgrnam
This function looks up a group file entry by group name. The return value in list context is:getgrnam NAME
where $members contains a space-separated list of the login names of the members of the group. If you want to do this repeatedly, consider caching the data in a hash using getgrent.($name, $passwd, $gid, $members)
In scalar context, getgrnam returns only the numeric group ID. The User::grent module supports a by-name interface to this function. See getgrnam(3).
29.2.47. gethostbyaddr
This function translates addresses into names (and alternate addresses). ADDR should be a packed binary network address, and ADDRTYPE should in practice usually be AF_INET (from the Socket module). The return value in list context is:gethostbyaddr ADDR, ADDRTYPE
($name, $aliases, $addrtype, $length, @addrs) =
gethostbyaddr($packed_binary_address, $addrtype);
where @addrs is a list of packed binary addresses.
In the Internet domain, each address is (historically) four bytes
long, and can be unpacked by saying something like:
($a, $b, $c, $d) = unpack('C4', $addrs[0]);
Alternatively, you can convert directly to dot vector notation with
the v modifier to sprintf:
The inet_ntoa function from the Socket module is useful for producing a printable version. This approach will become important if and when we all ever manage to switch over to IPv6.$dots = sprintf "%vd", $addrs[0];
In scalar context, gethostbyaddr returns only the host name.use Socket; $printable_address = inet_ntoa($addrs[0]);
To produce an ADDR from a dot vector, say this:
use Socket;
$ipaddr = inet_aton("127.0.0.1"); # localhost
$claimed_hostname = gethostbyaddr($ipaddr, AF_INET);
Interestingly, with version 5.6 of Perl you can skip the
inet_aton() and use the new v-string notation that
was invented for version numbers but happens to work for IP addresses
as well:
See the section "Sockets" in Chapter 16, "Interprocess Communication" for more examples. The Net::hostent module supports a by-name interface to this function. See gethostbyaddr(3).$ipaddr = v127.0.0.1;
29.2.48. gethostbyname
This function translates a network hostname to its corresponding addresses (and other names). The return value in list context is:gethostbyname NAME
($name, $aliases, $addrtype, $length, @addrs) =
gethostbyname($remote_hostname);
where @addrs is a list of raw addresses. In the
Internet domain, each address is (historically) four bytes long, and
can be unpacked by saying something like:
($a, $b, $c, $d) = unpack('C4', $addrs[0]);
You can convert directly to vector notation with the v
modifier to sprintf:
In scalar context, gethostbyname returns only the host address:$dots = sprintf "%vd", $addrs[0];
use Socket;
$ipaddr = gethostbyname($remote_host);
printf "%s has address %s\n",
$remote_host, inet_ntoa($ipaddr);
See "Sockets" in Chapter 16, "Interprocess Communication"
for another approach. The Net::hostent module
supports a by-name interface to this function. See also
gethostbyname(3).
29.2.49. gethostent
These functions iterate through your /etc/hosts file and return each entry one at a time. The return value from gethostent is:gethostent sethostent STAYOPEN endhostent
where @addrs is a list of raw addresses. In the Internet domain, each address is four bytes long, and can be unpacked by saying something like:($name, $aliases, $addrtype, $length, @addrs)
($a, $b, $c, $d) = unpack('C4', $addrs[0]);
Scripts that use gethostent should not be
considered portable. If a machine uses a name server, it would have to
interrogate most of the Internet to try to satisfy a request for all
the addresses of every machine on the planet. So
gethostent is unimplemented on such machines. See
gethostent(3) for other details.
The Net::hostent module supports a by-name interface to this function.
29.2.50. getlogin
This function returns the current login name if found. On Unix systems, this is read from the utmp(5) file. If it returns false, use getpwuid instead. For example:getlogin
$login = getlogin() || (getpwuid($<))[0] || "Intruder!!";
29.2.51. getnetbyaddr
This function translates a network address to the corresponding network name or names. The return value in list context is:getnetbyaddr ADDR, ADDRTYPE
In scalar context, getnetbyaddr returns only the network name. The Net::netent module supports a by-name interface to this function. See getnetbyaddr(3).use Socket; ($name, $aliases, $addrtype, $net) = getnetbyaddr(127, AF_INET);
29.2.52. getnetbyname
This function translates a network name to its corresponding network address. The return value in list context is:getnetbyname NAME
($name, $aliases, $addrtype, $net) = getnetbyname("loopback");
In scalar context, getnetbyname returns only the network address.
The Net::netent module supports a by-name interface to
this function. See getnetbyname(3).
29.2.53. getnetent
These functions iterate through your /etc/networks file. The return value in list context is:getnetent setnetent STAYOPEN endnetent
In scalar context, getnetent returns only the network name. The Net::netent module supports a by-name interface to this function. See getnetent(3).($name, $aliases, $addrtype, $net) = getnetent();
The concept of network names seems rather quaint these days; most IP addresses are on unnamed (and unnameable) subnets.
29.2.54. getpeername
This function returns the packed socket address of the other end of the SOCKET connection. For example:getpeername SOCKET
use Socket; $hersockaddr = getpeername SOCK; ($port, $heraddr) = sockaddr_in($hersockaddr); $herhostname = gethostbyaddr($heraddr, AF_INET); $herstraddr = inet_ntoa($heraddr);
29.2.55. getpgrp
This function returns the current process group for the specified PID (use a PID of 0 for the current process). Invoking getpgrp will raise an exception if used on a machine that doesn't implement getpgrp(2). If PID is omitted, the function returns the process group of the current process (the same as using a PID of 0). On systems implementing this operator with the POSIX getpgrp(2) syscall, PID must be omitted or, if supplied, must be 0.getpgrp PID
29.2.56. getppid
This function returns the process ID of the parent process. On the typical Unix system, if your parent process ID changes to 1, it means your parent process has died and you've been adopted by the init(8) program.getppid
29.2.57. getpriority
This function returns the current priority for a process, a process group, or a user. See getpriority(2). Invoking getpriority will raise an exception if used on a machine that doesn't implement getpriority(2).getpriority WHICH, WHO
The BSD::Resource module from CPAN provides a more convenient interface, including the PRIO_PROCESS, PRIO_PGRP, and PRIO_USER symbolic constants to supply for the WHICH argument. Although these are traditionally set to 0, 1, and 2 respectively, you really never know what may happen within the dark confines of C's #include files.
A value of 0 for WHO means the current process, process group, or user, so to get the priority of the current process, use:
$curprio = getpriority(0, 0);
29.2.58. getprotobyname
This function translates a protocol name to its corresponding number. The return value in list context is:getprotobyname NAME
($name, $aliases, $protocol_number) = getprotobyname("tcp");
When called in scalar context, getprotobyname
returns only the protocol number. The Net::proto
module supports a by-name interface to this function. See
getprotobyname(3).
29.2.59. getprotobynumber
This function translates a protocol number to its corresponding name. The return value in list context is:getprotobynumber NUMBER
When called in scalar context, getprotobynumber returns only the protocol name. The Net::proto module supports a by-name interface to this function. See getprotobynumber(3).($name, $aliases, $protocol_number) = getprotobynumber(6);
29.2.60. getprotoent
These functions iterate through the /etc/protocols file. In list context, the return value from getprotoent is:getprotoent setprotoent STAYOPEN endprotoent
When called in scalar context, getprotoent returns only the protocol name. The Net::proto module supports a by-name interface to this function. See getprotent(3).($name, $aliases, $protocol_number) = getprotoent();
29.2.61. getpwent
These functions conceptually iterate through your /etc/passwd file, though this may involve the /etc/shadow file if you're the superuser and are using shadow passwords, or NIS (née YP) or NIS+ if you're using either of those. The return value in list context is:getpwent setpwent endpwent
Some machines may use the quota and comment fields for other than their named purposes, but the remaining fields will always be the same. To set up a hash for translating login names to UIDs, say this:($name,$passwd,$uid,$gid,$quota,$comment,$gcos,$dir,$shell) = getpwent();
while (($name, $passwd, $uid) = getpwent()) {
$uid{$name} = $uid;
}
In scalar context, getpwent returns only the username. The
User::pwent module supports a by-name interface to this
function. See getpwent(3).
29.2.62. getpwnam
This function translates a username to the corresponding /etc/passwd file entry. The return value in list context is:getpwnam NAME
($name,$passwd,$uid,$gid,$quota,$comment,$gcos,$dir,$shell) = getpwnam("daemon");
On systems that support shadow passwords, you will have to be the
superuser to retrieve the actual password. Your C library should
notice that you're suitably empowered and open the /etc/shadow
file (or wherever it keeps the shadow file). At least, that's how it's supposed
to work. Perl will try to do this if your C library is too stupid to notice.
For repeated lookups, consider caching the data in a hash using getpwent.
In scalar context, getpwnam returns only the numeric user ID. The User::pwent module supports a by-name interface to this function. See getpwnam(3) and passwd(5).
29.2.63. getpwuid
This function translates a numeric user ID to the corresponding /etc/passwd file entry. The return value in list context is:getpwuid UID
For repeated lookups, consider caching the data in a hash using getpwent.($name,$passwd,$uid,$gid,$quota,$comment,$gcos,$dir,$shell) = getpwuid(2);
In scalar context, getpwuid returns the username. The User::pwent module supports a by-name interface to this function. See getpwnam(3) and passwd(5).
29.2.64. getservbyname
This function translates a service (port) name to its corresponding port number. PROTO is a protocol name such as "tcp". The return value in list context is:getservbyname NAME, PROTO
($name, $aliases, $port_number, $protocol_name) = getservbyname("www", "tcp");
In scalar context, getservbyname returns only the service port
number. The Net::servent module supports a by-name
interface to this function. See getservbyname(3).
29.2.65. getservbyport
This function translates a service (port) number to its corresponding names. PROTO is a protocol name such as "tcp". The return value in list context is:getservbyport PORT, PROTO
In scalar context, getservbyport returns only the service name. The Net::servent module supports a by-name interface to this function. See getservbyport(3).($name, $aliases, $port_number, $protocol_name) = getservbyport(80, "tcp");
29.2.66. getservent
This function iterates through the /etc/services file or its equivalent. The return value in list context is:getservent setservent STAYOPEN endservent
In scalar context, getservent returns only the service port name. The Net::servent module supports a by-name interface to this function. See getservent(3).($name, $aliases, $port_number, $protocol_name) = getservent();
29.2.67. getsockname
This function returns the packed socket address of this end of the SOCKET connection. (And why wouldn't you know your own address already? Maybe because you bound an address containing wildcards to the server socket before doing an accept and now you need to know what interface someone used to connect to you. Or you were passed a socket by your parent process--inetd, for example.)getsockname SOCKET
use Socket; $mysockaddr = getsockname(SOCK); ($port, $myaddr) = sockaddr_in($mysockaddr); $myname = gethostbyaddr($myaddr,AF_INET); printf "I am %s [%vd]\n", $myname, $myaddr;
29.2.68. getsockopt
This function returns the socket option requested, or undef if there is an error. See setsockopt for more information.getsockopt SOCKET, LEVEL, OPTNAME
29.2.69. glob
This function returns the value of EXPR with filename expansions such as a shell would do. This is the internal function implementing the <*> operator.glob EXPR glob
For historical reasons, the algorithm matches the csh(1)'s style of expansion, not the Bourne shell's. Versions of Perl before the 5.6 release used an external process, but 5.6 and later perform globs internally. Files whose first character is a dot (".") are ignored unless this character is explicitly matched. An asterisk ("*") matches any sequence of any character (including none). A question mark ("?") matches any one character. A square bracket sequence ("[...]") specifies a simple character class, like "[chy0-9]". Character classes may be negated with a circumflex, as in "*.[^oa]", which matches any non-dot files whose names contain a period followed by one character which is neither an "a" nor an "o" at the end of the name. A tilde ("~") expands to a home directory, as in "~/.*rc" for all the current user's "rc" files, or "~jane/Mail/*" for all of Jane's mail files. Braces may be used for alternation, as in "~/.{mail,ex,csh,twm,}rc" to get those particular rc files.
If you want to glob filenames that might contain whitespace, you'll need to use the File::Glob module directly, since glob grandfathers the use of whitespace to separate multiple patterns such as <*.c *.h>. For details, see File::Glob in Chapter 32, "Standard Modules". Calling glob (or the <*> operator) automatically uses that module, so if the module mysteriously vaporizes from your library, an exception is raised.
When you call open, Perl does not expand wildcards, including tildes. You need to glob the result first.
open(MAILRC, "~/.mailrc") # WRONG: tilde is a shell thing
or die "can't open ~/.mailrc: $!";
open(MAILRC, (glob("~/.mailrc"))[0]) # expand tilde first
or die "can't open ~/.mailrc: $!";
The glob function is not related to the Perl notion of typeglobs,
other than that they both use a * to represent multiple items.
See also the "Filename globbing operator" section of Chapter 2, "Bits and Pieces".
29.2.70. gmtime
This function converts a time as returned by the time function to a nine-element list with the time correct for the Greenwich time zone (a.k.a. GMT, or UTC, or even Zulu in certain cultures, not including the Zulu culture, oddly enough). It's typically used as follows:gmtime EXPR gmtime
If, as in this case, the EXPR is omitted, it does gmtime(time()). The Perl library module Time::Local contains a subroutine, timegm, that can convert the list back into a time value.# 0 1 2 3 4 5 6 7 8 ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = gmtime;
All list elements are numeric and come straight out of a struct tm (that's a C programming structure--don't sweat it). In particular this means that $mon has the range 0..11 with January as month 0, and $wday has the range 0..6 with Sunday as day 0. You can remember which ones are zero-based because those are the ones you're always using as subscripts into zero-based arrays containing month and day names.
For example, to get the current month in London, you might say:
$london_month = (qw(Jan Feb Mar Apr May Jun
Jul Aug Sep Oct Nov Dec))[(gmtime)[4]];
$year is the number of years since 1900; that is, in year 2023, $year is
123, not simply 23.
To
get the 4-digit year, just say $year + 1900. To get the 2-digit
year (for example "01" in 2001), use sprintf("%02d", $year % 100).
In scalar context, gmtime returns a ctime(3)-like string based on the GMT time value. The Time::gmtime module supports a by-name interface to this function. See also POSIX::strftime() for a more fine-grained approach to formatting times.
This scalar value is not locale dependent but is instead a Perl built-in. Also see the Time::Local module and the strftime(3) and mktime(3) functions available via the POSIX module. To get somewhat similar but locale-dependent date strings, set up your locale environment variables appropriately (please see the perllocale manpage), and try:
The %a and %b escapes, which represent the short forms of the day of the week and the month of the year, may not necessarily be three characters wide in all locales.use POSIX qw(strftime); $now_string = strftime "%a %b %e %H:%M:%S %Y", gmtime;
29.2.71. goto
gotoLABEL finds the statement labeled with LABEL and resumes execution there. If the LABEL cannot be found, an exception is raised. It cannot be used to go into any construct that requires initialization, such as a subroutine or a foreach loop. It also can't be used to go into a construct that is optimized away. It can be used to go almost anywhere else within the dynamic scope,[4] including out of subroutines, but for that purpose it's usually better to use some other construct such as last or die. The author of Perl has never felt the need to use this form of goto (in Perl, that is--C is another matter).goto LABEL goto EXPR goto &NAME
[4]This means that if it doesn't find the label in the current routine, it looks back through the routines that called the current routine for the label, thus making it nearly impossible to maintain your program.
Going to even greater heights of orthogonality (and depths of idiocy), Perl allows gotoEXPR, which expects EXPR to evaluate to a label name, whose location is guaranteed to be unresolvable until run time since the label is unknown when the statement is compiled. This allows for computed gotos per FORTRAN, but isn't necessarily recommended[5] if you're optimizing for maintainability:
goto +("FOO", "BAR", "GLARCH")[$i];
The unrelated goto&NAME is highly
magical, substituting a call to the named subroutine for the currently
running subroutine. This construct may be used without shame by
AUTOLOAD subroutines that wish to load another
subroutine and then pretend that this new subroutine--and not the
original one--had been called in the first place (except that any
modifications to @_ in the original subroutine are
propagated to the replacement subroutine). After the
goto, not even caller will be
able to tell that the original AUTOLOAD routine was
called first.
[5] Understatement is reputed to be funny, so we thought we'd try one here.
29.2.72. grep
This function evaluates EXPR or BLOCK in Boolean context for each element of LIST, temporarily setting $_ to each element in turn, much like the foreach construct. In list context, it returns a list of those elements for which the expression is true. (The operator is named after a beloved Unix program that extracts lines out of a file that match a particular pattern. In Perl, the expression is often a pattern, but doesn't have to be.) In scalar context, grep returns the number of times the expression was true.grep EXPR, LIST grep BLOCK LIST
If @all_lines contains lines of code, this example weeds out comment lines:
Because $_ is an implicit alias to each list value, altering $_ will modify the elements of the original list. While this is useful and supported, it can occasionally cause bizarre results if you aren't expecting it. For example:@code_lines = grep !/^\s*#/, @all_lines;
@list = qw(barney fred dino wilma);
@greplist = grep { s/^[bfd]// } @list;
@greplist is now "arney", "red", "ino", but @list is now
"arney", "red", "ino", "wilma"! Ergo, Caveat Programmor.
See also map. The following two statements are functionally equivalent:
@out = grep { EXPR } @in;
@out = map { EXPR ? $_ : () } @in
29.2.73. hex
This function interprets EXPR as a hexadecimal string and returns the equivalent decimal value. A leading "0x" is ignored, if present. To interpret strings that might start with any of 0, 0b, or 0x, see oct. The following code sets $number to 4,294,906,560:hex EXPR hex
$number = hex("ffff12c0");
To do the inverse function, use sprintf:
Hex strings may only represent integers. Strings that would cause integer overflow trigger a warning.sprintf "%lx", $number; # (That's an ell, not a one.)
29.2.74. import
There is no built-in import function. It is merely an ordinary class method defined (or inherited) by modules that wish to export names to another module through the use operator. See use for details.import CLASSNAME LIST import CLASSNAME
29.2.75. index
This function searches for one string within another. It returns the position of the first occurrence of SUBSTR in STR. The OFFSET, if specified, says how many characters from the start to skip before beginning to look. Positions are based at 0 (or whatever you've set the subscript base $[ variable to--but don't do that). If the substring is not found, the function returns one less than the base, ordinarily -1. To work your way through a string, you might say:index STR, SUBSTR, OFFSET index STR, SUBSTR
$pos = -1;
while (($pos = index($string, $lookfor, $pos)) > -1) {
print "Found at $pos\n";
$pos++;
}
29.2.76. int
This function returns the integer portion of EXPR. If you're a C programmer, you're apt to forget to use int in conjunction with division, which is a floating-point operation in Perl:int EXPR int
You should not use this function for generic rounding, because it truncates towards 0 and because machine representations of floating-point numbers can sometimes produce counterintuitive results. For example, int(-6.725/0.025) produces -268 rather than the correct -269; that's because the value is really more like -268.99999999999994315658. Usually, the sprintf, printf, or the POSIX::floor and POSIX::ceil functions will serve you better than will int.$average_age = 939/16; # yields 58.6875 (58 in C) $average_age = int 939/16; # yields 58
$n = sprintf("%.0f", $f); # round (not trunc) to nearest integer
29.2.77. ioctl
This function implements the ioctl(2) syscall which controls I/O. To get the correct function definitions, first you'll probably have to say:ioctl FILEHANDLE, FUNCTION, SCALAR
If sys/ioctl.ph doesn't exist or doesn't have the correct definitions, you'll have to roll your own based on your C header files such as sys/ioctl.h. (The Perl distribution includes a script called h2ph to help you do this, but running it is nontrivial.) SCALAR will be read or written (or both) depending on the FUNCTION--a pointer to the string value of SCALAR will be passed as the third argument of the actual ioctl(2) call. (If SCALAR has no string value but does have a numeric value, that value will be passed directly rather than a pointer to the string value.) The pack and unpack functions are useful for manipulating the values of structures used by ioctl. The following example determines how many bytes are available for reading using the FIONREADioctl:require "sys/ioctl.ph"; # perhaps /usr/local/lib/perl/sys/ioctl.ph
require 'sys/ioctl.ph';
$size = pack("L", 0);
ioctl(FH, FIONREAD(), $size)
or die "Couldn't call ioctl: $!\n";
$size = unpack("L", $size);
If h2ph wasn't installed or doesn't work for you, you can grep
the include files by hand or write a small C program to print out
the value.
The return value of ioctl (and fcntl) is as follows:
| Syscall Returns | Perl Returns |
|---|---|
| -1 | undef |
| 0 | String "0 but true" |
| Anything else | That number |
Thus Perl returns true on success and false on failure, yet you can still easily determine the actual value returned by the operating system:
The special string "0 but true" is exempt from -w complaints about improper numeric conversions.$retval = ioctl(...) || -1; printf "ioctl actually returned %d\n", $retval;
Calls to ioctl should not be considered portable. If, say, you're merely turning off echo once for the whole script, it's more portable to say:
Just because you can do something in Perl doesn't mean you ought to. To quote the Apostle Paul, "Everything is permissible--but not everything is beneficial."system "stty -echo"; # Works on most Unix boxen.
For still better portability, you might look at the Term::ReadKey module from CPAN.
29.2.78. join
This function joins the separate strings of LIST into a single string with fields separated by the value of EXPR, and returns the string. For example:join EXPR, LIST
To do the opposite, see split. To join things together into fixed-position fields, see pack. The most efficient way to concatenate many strings together is to join them with a null string:$rec = join ':', $login,$passwd,$uid,$gid,$gcos,$home,$shell;
Unlike split, join doesn't take a pattern as its first argument, and will produce a warning if you try.$string = join "", @array;
29.2.79. keys
This function returns a list consisting of all the keys of the indicated HASH. The keys are returned in an apparently random order, but it is the same order produced by either the values or each function (assuming the hash has not been modified between calls). As a side effect, it resets HASH's iterator. Here is a (rather cork-brained) way to print your environment:keys HASH
@keys = keys %ENV; # keys are in the same order as
@values = values %ENV; # values, as this demonstrates
while (@keys) {
print pop(@keys), '=', pop(@values), "\n";
}
You're more likely to want to see the environment sorted by keys:
foreach $key (sort keys %ENV) {
print $key, '=', $ENV{$key}, "\n";
}
You can sort the values of a hash directly, but that's somewhat useless
in the absence of any way to map the values back to the keys.
To sort a hash by value, you generally need to sort the keys by
providing a comparison function that accesses the values based on the
keys. Here's a descending numeric sort of a hash by its values:
foreach $key (sort { $hash{$b} <=> $hash{$a} } keys %hash) {
printf "%4d %s\n", $hash{$key}, $key;
}
Using keys on a hash bound to a largish DBM file will
produce a largish list, causing you to have a largish process. You
might prefer to use the each function here, which will
iterate over the hash entries one by one without slurping them all into
a single gargantuan list.
In scalar context, keys returns the number of elements of the hash (and resets the each iterator). However, to get this information for tied hashes, including DBM files, Perl must walk the entire hash, so it's not efficient then. Calling keys in a void context helps with that.
Used as an lvalue, keys increases the number of hash buckets allocated for the given hash. (This is similar to pre-extending an array by assigning a larger number to $#array.) Pre-extending your hash can gain a measure of efficiency if you happen to know the hash is going to get big, and how big it's going to get. If you say:
then %hash will have at least 1000 buckets allocated for it (you get 1024 buckets, in fact, since it rounds up to the next power of two). You can't shrink the number of buckets allocated for the hash using keys in this way (but you needn't worry about doing this by accident, as trying has no effect). The buckets will be retained even if you do %hash = (). Use undef %hash if you want to free the storage while %hash is still in scope.keys %hash = 1000;
See also each, values, and sort.
29.2.80. kill
This function sends a signal to a list of processes. For SIGNAL, you may use either an integer or a quoted signal name (without a "SIG" on the front). Trying to use an unrecognized SIGNAL name raises an exception. The function returns the number of processes successfully signalled. If SIGNAL is negative, the function kills process groups instead of processes. (On SysV, a negative process number will also kill process groups, but that's not portable.) A PID of zero sends the signal to all processes of the same group ID as the sender. For example:kill SIGNAL, LIST
$cnt = kill 1, $child1, $child2;
kill 9, @goners;
kill 'STOP', getppid # Can *so* suspend my login shell...
unless getppid == 1; # (But don't taunt init(8).)
A SIGNAL of 0 tests whether a process is still alive and that
you still have permission to signal it. No signal is sent.
This way you can check whether the process is still alive and hasn't
changed its UID.
use Errno qw(ESRCH EPERM);
if (kill 0 => $minion) {
print "$minion is alive!\n";
} elsif ($! == EPERM) { # changed UID
print "$minion has escaped my control!\n";
} elsif ($! == ESRCH) {
print "$minion is deceased.\n"; # or zombied
} else {
warn "Odd; I couldn't check on the status of $minion: $!\n";
}
See the section "Signals" in Chapter 16, "Interprocess Communication".
29.2.81. last
The last operator immediately exits the loop in question, just like the break statement in C or Java (as used in loops). If the LABEL is omitted, the operator refers to the innermost enclosing loop. The continue block, if any, is not executed.last LABEL last
LINE: while (<MAILMSG>) {
last LINE if /^$/; # exit when done with header
# rest of loop here
}
last cannot be used to exit a block which returns a
value, such as eval {}, sub {},
or do {}, and should not be used to exit a
grep or map operation. With
warnings enabled, Perl will warn you if you last
out of a loop that's not in your current lexical scope, such as a loop
in a calling subroutine.
A block by itself is semantically identical to a loop that executes once. Thus last can be used to effect an early exit out of such a block.
See also Chapter 4, "Statements and Declarations" for illustrations of how last, next, redo, and continue work.
29.2.82. lc
This function returns a lowercased version of EXPR. This is the internal function implementing the \L escape in double-quoted strings. Your current LC_CTYPE locale is respected if use locale is in effect, though how locales interact with Unicode is still a topic of ongoing research, as they say. See the perllocale manpage for the most recent results.lc EXPR lc
29.2.83. lcfirst
This function returns a version of EXPR with the first character lowercased. This is the internal function implementing the \l escape in double-quoted strings. Your current LC_CTYPE locale is respected if you use locale and if we figure out how that relates to Unicode.lcfirst EXPR lcfirst
29.2.84. length
This function returns the length in characters of the scalar value EXPR. If EXPR is omitted, it returns the length of $_. (But be careful that the next thing doesn't look like the start of an EXPR, or Perl's lexer will get confused. For example, length < 10 won't compile. When in doubt, use parentheses.)length EXPR length
Do not try to use length to find the size of an array or hash. Use scalar @array for the size of an array, and scalar keys %hash for the number of key/value pairs in a hash. (The scalar is typically omitted when redundant.)
To find the length of a string in bytes rather than characters, say:
$blen = do { use bytes; length $string; };
or:
$blen = bytes::length($string); # must use bytes first
29.2.85. link
This function creates a new filename linked to the old filename. The function returns true for success, false otherwise. See also symlink later in this chapter. This function is unlikely to be implemented on non-Unix-style filesystems.link OLDFILE, NEWFILE
29.2.86. listen
This function tells the system that you're going to be accepting connections on this SOCKET and that the system can queue the number of waiting connections specified by QUEUESIZE. Imagine having call-waiting on your phone, with up to 17 callers queued. (Gives me the willies!) The function returns true if it succeeded, false otherwise.listen SOCKET, QUEUESIZE
use Socket;
listen(PROTOSOCK, SOMAXCONN)
or die "cannot set listen queue on PROTOSOCK: $!";
See accept. See also the section "Sockets" in Chapter 16, "Interprocess Communication". See listen(2).
29.2.87. local
This operator does not create a local variable; use my for that. Instead, it localizes existing variables; that is, it causes one or more global variables to have locally scoped values within the innermost enclosing block, eval, or file. If more than one variable is listed, the list must be placed in parentheses because the operator binds more tightly than commas. All listed variables must be legal lvalues, that is, something you could assign to; this can include individual elements of arrays or hashes.local EXPR
This operator works by saving the current values of the specified variables on a hidden stack and restoring them upon exiting the block, subroutine, eval, or file. After the local is executed, but before the scope is exited, any subroutines and executed formats will see the local, inner value, instead of the previous, outer value because the variable is still a global variable, despite having a localized value. The technical term for this is "dynamic scoping". See the section "Scoped Declarations" in Chapter 4, "Statements and Declarations".
The EXPR may be assigned to if desired, which allows you to initialize your variables as you localize them. If no initializer is given, all scalars are initialized to undef, and all arrays and hashes to (). As with ordinary assignment, if you use parentheses around the variables on the left (or if the variable is an array or hash), the expression on the right is evaluated in list context. Otherwise, the expression on the right is evaluated in scalar context.
In any event, the expression on the right is evaluated before the localization, but the initialization happens after localization, so you can initialize a localized variable with its nonlocalized value. For instance, this code demonstrates how to make a temporary modification to a global array:
if ($sw eq '-v') {
# init local array with global array
local @ARGV = @ARGV;
unshift @ARGV, 'echo';
system @ARGV;
}
# @ARGV restored
You can also temporarily modify global hashes:
# temporarily add a couple of entries to the %digits hash
if ($base12) {
# (NOTE: We're not claiming this is efficient!)
local(%digits) = (%digits, T => 10, E => 11);
parse_num();
}
You can use local to give temporary values to individual
elements of arrays and hashes, even lexically scoped ones:
if ($protected) {
local $SIG{INT} = 'IGNORE';
precious(); # no interrupts during this function
} # previous handler (if any) restored
You can also use local on typeglobs to create local filehandles without loading any bulky object modules:
local *MOTD; # protect any global MOTD handle
my $fh = do { local *FH }; # create new indirect filehandle
(As of the 5.6 release of Perl, a plain my $fh; is good enough,
because if you give an undefined variable where a real filehandle is expected,
like the first argument to open or socket, Perl now autovivifies
a brand new filehandle for you.)
But in general, you usually want to use my instead of local, because local isn't really what most people think of as "local", or even "lo-cal". See my.
29.2.88. localtime
This function converts the value returned by time to a nine-element list with the time corrected for the local time zone. It's typically used as follows:localtime EXPR localtime
If, as in this case, EXPR is omitted, it does localtime(time()).# 0 1 2 3 4 5 6 7 8 ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime;
All list elements are numeric and come straight out of a struct tm. (That's a bit of C programming lingo--don't worry about it.) In particular, this means that $mon has the range 0..11 with January as month 0, and $wday has the range 0..6 with Sunday as day 0. You can remember which ones are zero-based because those are the ones you're always using as subscripts into zero-based arrays containing month and day names.
For example, to get the name of the current day of the week:
$year is the number of years since 1900, that is, in year 2023, $year is 123, not simply 23. To get the 4-digit year, just say $year + 1900. To get the 2-digit year (for example "01" in 2001), use sprintf("%02d", $year % 100).$thisday = (Sun,Mon,Tue,Wed,Thu,Fri,Sat)[(localtime)[6]];
The Perl library module Time::Local contains a subroutine, timelocal, that can convert in the opposite direction.
In scalar context, localtime returns a ctime(3)-like string. For example, the date(1) command can be (almost)[6] emulated with:
See also the standard POSIX module's strftime function for a more fine-grained approach to formatting times. The Time::localtime module supports a by-name interface to this function.perl -le 'print scalar localtime'
[6]date(1) prints the timezone, whereas scalar localtime does not.
29.2.89. lock
The lock function places a lock on a variable, subroutine, or object referenced by THING until the lock goes out of scope. For backward compatibility, this function is a built-in only if your version of Perl was compiled with threading enabled, and if you've said use Threads. Otherwise, Perl will assume this is a user-defined function. See Chapter 17, "Threads".lock THING
29.2.90. log
This function returns the natural logarithm (that is, base e) of EXPR. If EXPR is negative, it raises an exception. To get the log of another base, use basic algebra: the base-N log of a number is equal to the natural log of that number divided by the natural log of N. For example:log EXPR log
sub log10 {
my $n = shift;
return log($n)/log(10);
}
For the inverse of log, see exp.
29.2.91. lstat
This function does the same thing as Perl's stat function (including setting the special _ filehandle), but if the last component of the filename is a symbolic link, it stats the symbolic link itself instead of the file that the symbolic link points to. (If symbolic links are unimplemented on your system, a normal stat is done instead.)lstat EXPR lstat
29.2.92. m//
This is the match operator, which interprets PATTERN as a regular expression. The operator is parsed as a double-quoted string rather than as a function. See Chapter 5, "Pattern Matching"./PATTERN/ m/PATTERN/
29.2.93. map
This function evaluates the BLOCK or EXPR for each element of LIST (locally setting $_ to each element) and returns the list comprising the results of each such evaluation. It evaluates BLOCK or EXPR in list context, so each element of LIST may map to zero, one, or more elements in the returned value. These are all flattened into one list. For instance:map BLOCK LIST map EXPR, LIST
@words = map { split ' ' } @lines;
splits a list of lines into a list of words. But often there is a
one-to-one mapping between input values and output values:
translates a list of numbers to the corresponding characters. And here's an example of a one-to-two mapping:@chars = map chr, @nums;
%hash = map { genkey($_) => $_ } @array;
which is just a funny functional way to write this:
%hash = ();
foreach $_ (@array) {
$hash{genkey($_)} = $_;
}
Because $_ is an alias (implicit reference) into the list's
values, this variable can be used to modify the elements of the
array. This is useful and supported, although it can cause bizarre
results if the LIST is not a named array. Using a regular
foreach loop for this purpose may be clearer. See also grep;
map differs from grep in that map returns a list consisting
of the results of each successive evaluation of EXPR, whereas
grep returns a list consisting of each value of LIST for which
EXPR evaluates to true.
29.2.94. mkdir
This function creates the directory specified by FILENAME, giving it permissions specified by the numeric MASK as modified by the current umask. If the operation succeeds, it returns true; otherwise, it returns false.mkdir FILENAME, MASK mkdir FILENAME
If MASK is omitted, a mask of 0777 is assumed, which is almost always what you want anyway. In general, creating directories with permissive MASKs (like 0777) and letting the user modify that with their umask is better than supplying a restrictive MASK and giving the user no way to be more permissive. The exception to this rule is when the file or directory should be kept private (mail files, for instance). See umask.
If the mkdir(2) syscall is not built into your C library, Perl emulates it by calling the mkdir(1) program for each directory. If you are creating a long list of directories on such a system, it'll be more efficient to call the mkdir program yourself with the list of directories than it is to start zillions of subprocesses.
29.2.95. msgctl
This function calls the System V IPC msgctl(2) syscall; see msgctl(2) for more details. You may have to useIPC::SysV first to get the correct constant definitions. If CMD is IPC_STAT, then ARG must be a variable that will hold the returned msqid_ds C structure. Return values are like ioctl and fcntl: undef for error, "0 but true" for zero, or the actual return value otherwise.msgctl ID, CMD, ARG
This function is available only on machines supporting System V IPC, which turns out to be far fewer than those supporting sockets.
29.2.96. msgget
This function calls the System V IPC msgget(2) syscall. See msgget(2) for details. The function returns the message queue ID, or undef if there is an error. Before calling, you should useIPC::SysV.msgget KEY, FLAGS
This function is available only on machines supporting System V IPC.
29.2.97. msgrcv
This function calls the msgrcv(2) syscall to receive a message from message queue ID into variable VAR with a maximum message size of SIZE. See msgrcv(2) for details. When a message is received, the message type will be the first thing in VAR, and the maximum length of VAR is SIZE plus the size of the message type. The function returns true if successful, or false if there is an error. Before calling, you should useIPC::SysV.msgrcv ID, VAR, SIZE, TYPE, FLAGS
This function is available only on machines supporting System V IPC.
29.2.98. msgsnd
This function calls the msgsnd(2) syscall to send the message MSG to the message queue ID. See msgsnd(2) for details. MSG must begin with the long integer message type. You can create a message like this:msgsnd ID, MSG, FLAGS
The function returns true if successful, or false if there is an error. Before calling, useIPC::SysV.$msg = pack "L a*", $type, $text_of_message;
This function is available only on machines supporting System V IPC.
29.2.99. my
This operator declares one or more private variables to exist only within the innermost enclosing block, subroutine, eval, or file. If more than one variable is listed, the list must be placed in parentheses because the operator binds more tightly than commas. Only simple scalars or complete arrays and hashes may be declared this way.my TYPE EXPR : ATTRIBUTES my EXPR : ATTRIBUTES my TYPE EXPR my EXPR
The variable name cannot be package qualified, because package variables are all globally accessible through their corresponding symbol table, and lexical variables are unrelated to any symbol table. Unlike local, then, this operator has nothing to do with global variables, other than hiding any other variable of the same name from view within its scope (that is, where the private variable exists). A global variable can always be accessed through its package-qualified form, however, or through a symbolic reference.
A private variable's scope does not start until the statement after its declaration. The variable's scope extends into any enclosed blocks thereafter, up to the end of the scope of the variable itself.
However, this means that any subroutines you call from within the scope of a private variable cannot see the private variable unless the block that defines the subroutine itself is also textually enclosed within the scope of that variable. That sounds complicated, but it's not once you get the hang of it. The technical term for this is lexical scoping, so we often call these lexical variables. In C culture, they're sometimes called "auto" variables, since they're automatically allocated and deallocated at scope entry and exit.
The EXPR may be assigned to if desired, which allows you to initialize your lexical variables. (If no initializer is given, all scalars are initialized to the undefined value and all arrays and hashes to the empty list.) As with ordinary assignment, if you use parentheses around the variables on the left (or if the variable is an array or hash), the expression on the right is evaluated in list context. Otherwise, the expression on the right is evaluated in scalar context. For example, you can name your formal subroutine parameters with a list assignment, like this:
But be careful not to omit the parentheses indicating list assignment, like this:my ($friends, $romans, $countrymen) = @_;
This assigns the length of the array (that is, the number of the subroutine's arguments) to the variable, since the array is being evaluated in scalar context. You can profitably use scalar assignment for a formal parameter though, as long as you use the shift operator. In fact, since object methods are passed the object as the first argument, many method subroutines start off by "stealing" the first argument:my $country = @_; # right or wrong?
sub simple_as {
my $self = shift; # scalar assignment
my ($a,$b,$c) = @_; # list assignment
...
}
If you attempt to declare a lexically scoped subroutine with
my sub, Perl will die with the message that this
feature has not been implemented yet. (Unless, of course, this
feature has been implemented yet.)
The TYPE and ATTRIBUTES are optional, which is just as well, since they're both considered experimental. Here's what a declaration that uses them might look like:
The TYPE, if specified, indicates what kind of scalar or scalars are declared in EXPR, either directly as one or more scalar variables, or indirectly through an array or hash. If TYPE is the name of the class, the scalars will be assumed to contain references to objects of that type, or to objects compatible with that type. In particular, derived classes are considered compatible. That is, assuming Collie is derived from Dog, you might declare:my Dog $spot :ears(short) :tail(long);
Your declaration claims that you will use the $lassie object consistently with its being a Dog object. The fact that it's actually a Collie object shouldn't matter as long as you only try to do Dog things. Through the magic of virtual methods, the implementation of those Dog methods might well be in the Collie class, but the declaration above is only talking about the interface, not the implementation. In theory.my Dog $lassie = new Collie;
Interestingly, up through version 5.6.0, the only time Perl pays attention to the TYPE declaration is when the corresponding class has declared fields with the use fields pragma. Together, these declarations allow the pseudohash implementation of a class to "show through" to code outside the class, so that hash lookups can be optimized by the compiler into array lookups. In a sense, the pseudohash is the interface to such a class, so our theory remains intact, if a bit battered. For more on pseudohashes, see the section "Pseudohashes" in Chapter 8, "References".
In the future, other types of classes may interpret the TYPE differently. The TYPE declaration should be considered a generic type interface that might someday be instantiated in various ways depending on the class. In fact, the TYPE might not even be an official class name. We're reserving the lowercase type names for Perl, because one of the ways we'd like to extend the type interface is to allow optional low-level type declarations such as int, num, str, and ref. These declarations will not be for the purpose of strong typing; rather, they'll be hints to the compiler telling it to optimize the storage of the variable with the assumption that the variable will be used mostly as declared. The semantics of scalars will stay pretty much the same--you'll still be able to add two str scalars, or print an int scalar, just as though they were the ordinary polymorphic scalars you're familiar with. But with an int declaration Perl might decide to store only the integer value and forget about caching the resulting string as it currently does. Loops with int loop variables might run faster, particularly in code compiled down to C. In particular, arrays of numbers could be stored much more compactly. As a limiting case, the built-in vec function might even become obsolete when we can write declarations such as:
my bit @bitstring;
The ATTRIBUTES declaration is even more experimental. We haven't done much more than reserve the syntax and prototype the internal interface; see the use attributes pragma in Chapter 31, "Pragmatic Modules" for more on that. The first attribute we'll implement is likely to be constant:
But there are many other possibilities, such as establishing default values for arrays and hashes, or letting variables be shared among cooperating interpreters. Like the type interface, the attribute interface should be considered a generic interface, a kind of workbench for inventing new syntax and semantics. We do not know how Perl will evolve in the next 10 years. We only know that we can make it easier on ourselves by planning for that in advance.my num $PI : constant = atan2(1,1) * 4;
See also local, our, and the section "Scoped Declarations" in Chapter 4, "Statements and Declarations".
29.2.100. new
There is no built-in new function. It is merely an ordinary constructor method (that is, a user-defined subroutine) that is defined or inherited by the CLASSNAME class (that is, package) to let you construct objects of type CLASSNAME. Many constructors are named "new", but only by convention, just to trick C++ programmers into thinking they know what's going on. Always read the documentation of the class in question so you know how to call its constructors; for example, the constructor that creates a list box in the Tk widget set is just called Listbox(). See Chapter 12, "Objects".new CLASSNAME LIST new CLASSNAME
29.2.101. next
The next operator is like the continue statement in C: it starts the next iteration of the loop designated by LABEL:next LABEL next
LINE: while (<STDIN>) {
next LINE if /^#/; # discard comments
...
}
If there were a continue block in this example, it would be
executed immediately following the invocation of next. When LABEL
is omitted, the operator refers to the innermost enclosing loop.
A block by itself is semantically identical to a loop that executes once. Thus, next will exit such a block early (via the continue block, if there is one).
next cannot be used to exit a block that returns a value, such as eval {}, sub {}, or do {}, and should not be used to exit a grep or map operation. With warnings enabled, Perl will warn you if you next out of a loop not in your current lexical scope, such as a loop in a calling subroutine. See the section "Loop Statements" in Chapter 4, "Statements and Declarations".
29.2.102. no
See the use operator, which is the opposite of no, kind of. Most standard modules do not unimport anything, making no a no-op, as it were. The pragmatic modules tend to be more obliging here. If the MODULE cannot be found, an exception is raised.no MODULE LIST
29.2.103. oct
This function interprets EXPR as an octal string and returns the equivalent decimal value. If EXPR happens to start with "0x", it is interpreted as a hexadecimal string instead. If EXPR starts off with "0b", it is interpreted as a string of binary digits. The following will properly convert to numbers any input strings in decimal, binary, octal, and hex bases written in standard C or C++ notation:oct EXPR oct
To perform the inverse function, use sprintf with an appropriate format:$val = oct $val if $val =~ /^0/;
$perms = (stat("filename"))[2] & 07777;
$oct_perms = sprintf "%lo", $perms;
The oct function is commonly used when a data string such as
"644" needs to be converted into a file mode, for example. Although
Perl will automatically convert strings into numbers as needed, this
automatic conversion assumes base 10.
29.2.104. open
The open function associates an internal FILEHANDLE with an external file specification given by EXPR or LIST. It may be called with one, two, or three arguments (or more if the third argument is a command, and you're running at least version 5.6.1 of Perl). If three or more arguments are present, the second argument specifies the access MODE in which the file should be opened, and the third argument (LIST) supplies the actual filename or the command to execute, depending on the mode. In the case of a command, additional arguments may be supplied if you wish to invoke the command directly without involving a shell, much like system or exec. Or the command may be supplied as a single argument (the third one), in which case the decision to invoke the shell depends on whether the command contains shell metacharacters. (Don't use more than three arguments if the arguments are ordinary filenames; it won't work.) If the MODE is not recognized, open raises an exception.open FILEHANDLE, MODE, LIST open FILEHANDLE, EXPR open FILEHANDLE
If only two arguments are present, the mode and filename/command are assumed to be combined in the second argument. (And if you don't specify a mode in the second argument, just a filename, then the file is opened read-only to be on the safe side.)
With only one argument, the package scalar variable of the same name as the FILEHANDLE must contain the filename and optional mode:
But don't do that. It's not stylin'. Forget we mentioned it.$LOG = ">logfile"; # $LOG must not be declared my! open LOG or die "Can't open logfile: $!";
The open function returns true when it succeeds and undef otherwise. If the open starts up a pipe to a child process, the return value will be the process ID of that new process. As with any syscall, always check the return value of open to make sure it worked. But this isn't C or Java, so don't use an if statement when the or operator will do. You can also use ||, but if you do, use parentheses on the open. If you choose to omit parentheses on the function call to turn it into a list operator, be careful to use "or die" after the list rather than "|| die", because the precedence of || is higher than list operators like open, and the || will bind to your last argument, not the whole open:
That looks rather intense, but typically you'd introduce some whitespace to tell your eye where the list operator ends:open LOG, ">logfile" || die "Can't create logfile: $!"; # WRONG open LOG, ">logfile" or die "Can't create logfile: $!"; # ok
open LOG, ">logfile"
or die "Can't create logfile: $!";
As that example shows, the FILEHANDLE
argument is often just a simple identifier (normally uppercase), but
it may also be an expression whose value provides a reference to the
actual filehandle. (The reference may be either a symbolic reference
to the filehandle name or a hard reference to any object that can be
interpreted as a filehandle.) This is called an indirect
filehandle, and any function that takes a
FILEHANDLE as its first argument can handle
indirect filehandles as well as direct ones. But
open is special in that if you supply it with an
undefined variable for the indirect filehandle, Perl will
automatically define that variable for you, that is, autovivifying it
to contain a proper filehandle reference. One advantage of this is
that the filehandle will be closed automatically when there are no
further references to it, typically when the variable goes out of
scope:
{
my $fh; # (uninitialized)
open($fh, ">logfile") # $fh is autovivified
or die "Can't create logfile: $!";
... # do stuff with $fh
} # $fh closed here
The my$fh declaration can be
readably incorporated into the open:
The > symbol you've been seeing in front of the filename is an example of a mode. Historically, the two-argument form of open came first. The recent addition of the three-argument form lets you separate the mode from the filename, which has the advantage of avoiding any possible confusion between the two. In the following example, we know that the user is not trying to open a filename that happens to start with ">". We can be sure that they're specifying a MODE of ">", which opens the file named in EXPR for writing, creating the file if it doesn't exist and truncating the file down to nothing if it already exists:open my $fh, ">logfile" or die ...
In the shorter forms, the filename and mode are in the same string. The string is parsed much as the typical shell processes file and pipe redirections. First, any leading and trailing whitespace is removed from the string. Then the string is examined, on either end if need be, for characters specifying how the file is to be opened. Whitespace is allowed between the mode and the filename.open(LOG, ">", "logfile") or die "Can't create logfile: $!";
The modes that indicate how to open a file are shell-like redirection symbols. A list of these symbols is provided in Table 29-1. (To access a file with combinations of open modes not covered by this table, see the low-level sysopen function.)
Table 29.1. Modes for open
| Read | Write | Append | Create | Clobber | |
|---|---|---|---|---|---|
| Mode | Access | Access | Only | Nonexisting | Existing |
| < PATH | Y | N | N | N | N |
| > PATH | N | Y | N | Y | Y |
| >> PATH | N | Y | Y | Y | N |
| +< PATH | Y | Y | N | N | N |
| +> PATH | Y | Y | N | Y | Y |
| +>> PATH | Y | Y | Y | Y | N |
| | COMMAND | N | Y | n/a | n/a | n/a |
| COMMAND | | Y | N | n/a | n/a | n/a |
If the mode is "<" or nothing, an existing file is opened for input. If the mode is ">", the file is opened for output, which truncates existing files and creates nonexistent ones. If the mode is ">>", the file is created if needed and opened for appending, and all output is automatically placed at the end of the file. If a new file is created because you used a mode of ">" or ">>" and the file did not previously exist, access permissions will depend on the process's current umask under the rules described for that function.
Here are common examples:
open(INFO, "datafile") || die("can't open datafile: $!");
open(INFO, "< datafile") || die("can't open datafile: $!");
open(RESULTS, "> runstats") || die("can't open runstats: $!");
open(LOG, ">> logfile ") || die("can't open logfile: $!");
If you prefer the low-punctuation version, you can write:
When opened for reading, the special filename "-" refers to STDIN. When opened for writing, the same special filename refers to STDOUT. Normally, these are specified as "<-" and ">-", respectively.open INFO, "datafile" or die "can't open datafile: $!"; open INFO, "< datafile" or die "can't open datafile: $!"; open RESULTS, "> runstats" or die "can't open runstats: $!"; open LOG, ">> logfile " or die "can't open logfile: $!";
This way the user can supply a program with a filename that will use the standard input or the standard output, but the author of the program doesn't have to write special code to know about this.open(INPUT, "-" ) or die; # re-open standard input for reading open(INPUT, "<-") or die; # same thing, but explicit open(OUTPUT, ">-") or die; # re-open standard output for writing
You may also place a "+" in front of any of these three modes to request simultaneous read and write. However, whether the file is clobbered or created and whether it must already exist is still governed by your choice of less-than or greater-than signs. This means that "+<" is almost always preferred for read/write updates, as the dubious "+>" mode would first clobber the file before you could ever read anything from it. (Use that mode only if you want to reread only what you just wrote.)
open(DBASE, "+< database")
or die "can't open existing database in update mode: $!";
You can treat a file opened for update as a random-access
database and use seek to move to a particular byte number, but the
variable-length records of regular text files usually make it
impractical to use read-write mode to update such files. See the
-i command-line option in Chapter 19, "The Command-Line Interface" for a different approach
to updating.
If the leading character in EXPR is a pipe symbol, open fires up a new process and connects a write-only filehandle to the command. This way you can write into that handle and what you write will show up on that command's standard input. For example:
If the trailing character in EXPR is a pipe symbol, open again launches a new process, but this time with a read-only filehandle connected to it. This allows whatever the command writes to its standard output to show up on your handle for reading. For example:open(PRINTER, "| lpr -Plp1") or die "can't fork: $!"; print PRINTER "stuff\n"; close(PRINTER) or die "lpr/close failed: $?/$!";
open(NET, "netstat -i -n |") or die "can't fork: $!";
while (<NET>) { ... }
close(NET) or die "can't close netstat: $!/$?";
Explicitly closing any piped filehandle causes the parent process to
wait for the child to finish and returns the status code in
$? ($CHILD_ERROR). It's also
possible for close to set
$! ($OS_ERROR). See the
examples under close and system
for how to interpret these error codes.
Any pipe command containing shell metacharacters such as wildcards or I/O redirections is passed to your system's canonical shell (/bin/sh on Unix), so those shell-specific constructs can be processed first. If no metacharacters are found, Perl launches the new process itself without calling the shell.
You may also use the three-argument form to start up pipes. Using that style, the equivalent of the previous pipe opens would be:
Here the minus in the second argument represents the command in the third argument. These commands don't happen to invoke the shell, but if you want to guarantee no shell processing occurs, new versions of Perl let you say:open(PRINTER, "|-", "lpr -Plp1") or die "can't fork: $!"; open(NET, "-|", "netstat -i -n") or die "can't fork: $!";
If you use the two-argument form to open a pipe to or from the special command "-",[7] an implicit fork is done first. (On systems that can't fork, this raises an exception. Microsoft systems did not support fork prior to the 5.6 release of Perl.) In this case, the minus represents your new child process, which is a copy of the parent. The return value from this forking open is the process ID of the child when examined from the parent process, 0 when examined from the child process, and the undefined value undef if the fork fails--in which case, there is no child. For example:open(PRINTER, "|-", "lpr", "-Plp1") or die "can't fork: $!"; open(NET, "-|", "netstat", "-i", "-n") or die "can't fork: $!";
defined($pid = open(FROM_CHILD, "-|"))
or die "can't fork: $!";
if ($pid) {
@parent_lines = <FROM_CHILD>; # parent code
}
else {
print STDOUT @child_lines; # child code
}
The filehandle behaves normally for the parent, but for the child
process, the parent's input (or output) is piped from (or to) the
child's STDOUT (or STDIN). The child process does not see the
parent's filehandle opened. (This is conveniently indicated by the 0 PID.)
Typically you'd use this construct instead of the normal piped open
when you want to exercise more control over just how the pipe command
gets executed (such as when you are running setuid) and don't want to
have to scan shell commands for metacharacters. The following piped opens
are roughly equivalent:
as are these:open FH, "| tr 'a-z' 'A-Z'"; # pipe to shell command open FH, "|-", 'tr', 'a-z', 'A-Z'; # pipe to bare command open FH, "|-" or exec 'tr', 'a-z', 'A-Z' or die; # pipe to child
For more elaborate uses of fork open, see the sections "Talking to Yourself" in Chapter 16, "Interprocess Communication" and "Cleaning Up Your Environment" in Chapter 23, "Security".open FH, "cat -n 'file' |"; # pipe from shell command open FH, "-|", 'cat', '-n', 'file'; # pipe from bare command open FH, "-|" or exec 'cat', '-n', 'file' or die; # pipe from child
[7]Or you can think of it as leaving the command off of the three-argument forms above.
When starting a command with open, you must choose either input or output: "cmd|" for reading or "|cmd" for writing. You may not use open to start a command that pipes both in and out, as the (currently) illegal notation, "|cmd|", might appear to indicate. However, the standard IPC::Open2 and IPC::Open3 library routines give you a close equivalent. For details on double-ended pipes, see the section "Bidirectional Communication" in Chapter 16, "Interprocess Communication".
You may also, in the Bourne shell tradition, specify an EXPR beginning with >&, in which case the rest of the string is interpreted as the name of a filehandle (or file descriptor, if numeric) to be duplicated using the dup2(2) syscall.[8] You may use & after >, >>, <, +>, +>>, and +<. (The specified mode should match the mode of the original filehandle.)
[8]This doesn't (currently) work with I/O objects on typeglob references by filehandle autovivification, but you can always use fileno to fetch the file descriptor and dup that.
One reason you might want to do this would be if you already had a filehandle open and wanted to make another handle that's really a duplicate of the first one.
That means that if a function is expecting a filename, but you don't want to give it a filename because you already have the file open, you can just pass the filehandle with a leading ampersand. It's best to use a fully qualified handle though, just in case the function happens to be in a different package:open(SAVEOUT, ">&SAVEERR") or die "couldn't dup SAVEERR: $!"; open(MHCONTEXT, "<&4") or die "couldn't dup fd4: $!";
somefunction("&main::LOGFILE");
Another reason to "dup" filehandles is to temporarily
redirect an existing filehandle without losing track
of the original destination. Here is a script that saves, redirects, and
restores STDOUT and STDERR:
#!/usr/bin/perl
open SAVEOUT, ">&STDOUT";
open SAVEERR, ">&STDERR";
open STDOUT, ">foo.out" or die "Can't redirect stdout";
open STDERR, ">&STDOUT" or die "Can't dup stdout";
select STDERR; $| = 1; # enable autoflush
select STDOUT; $| = 1; # enable autoflush
print STDOUT "stdout 1\n"; # these I/O streams propagate to
print STDERR "stderr 1\n"; # subprocesses too
system("some command"); # uses new stdout/stderr
close STDOUT;
close STDERR;
open STDOUT, ">&SAVEOUT";
open STDERR, ">&SAVEERR";
print STDOUT "stdout 2\n";
print STDERR "stderr 2\n";
If the filehandle or descriptor number is preceded by a
&= combination instead of a simple
&, then instead of
creating a completely new file descriptor, Perl makes the
FILEHANDLE an alias for the existing
descriptor using the fdopen(3) C library
call. This is slightly more parsimonious of systems resources,
although that's less of a concern these days.
$fd = $ENV{"MHCONTEXTFD"};
open(MHCONTEXT, "<&=$fdnum")
or die "couldn't fdopen descriptor $fdnum: $!";
Filehandles STDIN, STDOUT, and
STDERR always remain open across an
exec. Other filehandles, by default, do not. On
systems supporting the fcntl function, you may
modify the close-on-exec flag for a filehandle.
use Fcntl qw(F_GETFD F_SETFD);
$flags = fcntl(FH, F_SETFD, 0)
or die "Can't clear close-on-exec flag on FH: $!\n";
See also the special $^F
($SYSTEM_FD_MAX) variable in
Chapter 28, "Special Names".
With the one- or two-argument form of open, you have to be careful when you use a string variable as a filename, since the variable may contain arbitrarily weird characters (particularly when the filename has been supplied by arbitrarily weird characters on the Internet). If you're not careful, parts of the filename might get interpreted as a MODE string, ignorable whitespace, a dup specification, or a minus. Here's one historically interesting way to insulate yourself:
But that's still broken in several ways. Instead, just use the three-argument form of open to open any arbitrary filename cleanly and without any (extra) security risks:$path =~ s#^(\s)#./$1#; open (FH, "< $path\0") or die "can't open $path: $!";
On the other hand, if what you're looking for is a true, C-style open(2) syscall with all its attendant belfries and whistle-stops, then check out sysopen:open(FH, "<", $path) or die "can't open $path: $!";
If you're running on a system that distinguishes between text and binary files, you may need to put your filehandle into binary mode--or forgo doing so, as the case may be--to avoid mutilating your files. On such systems, if you use text mode on a binary file, or binary mode on a text file, you probably won't like the results.use Fcntl; sysopen(FH, $path, O_RDONLY) or die "can't open $path: $!";
Systems that need the binmode function are distinguished from those that don't by the format used for text files. Those that don't need it terminate each line with a single character that corresponds to what C thinks is a newline, \n. Unix and Mac OS fall into this category. VMS, MVS, MS-whatever, and S&M operating systems of other varieties treat I/O on text files and binary files differently, so they need binmode.
Or its equivalent. As of the 5.6 release of Perl, you can specify binary mode in the open function without a separate call to binmode. As part of the MODE argument (but only in the three-argument form), you may specify various input and output disciplines. To do the equivalent of a binmode, use the three argument form of open and stuff a discipline of :raw in after the other MODE characters:
Since this is a very new feature, there will certainly be more disciplines by the time you read this than there were when we wrote it. However, we can reasonably predict that there will in all likelihood be disciplines resembling some or all of the ones in Table 29-2.open(FH, "<:raw", $path) or die "can't open $path: $!";
Table 29.2. I/O Disciplines
| Discipline | Meaning |
|---|---|
| :raw | Binary mode; do no processing |
| :text | Default text processing |
| :def | Default declared by "use open" |
| :latin1 | File should be ISO-8859-1 |
| :ctype | File should be LC_CTYPE |
| :utf8 | File should be UTF-8 |
| :utf16 | File should be UTF-16 |
| :utf32 | File should be UTF-32 |
| :uni | Intuit Unicode (UTF-*) |
| :any | Intuit Unicode/Latin1/LC_CTYPE |
| :xml | Use encoding specified in file |
| :crlf | Intuit newlines |
| :para | Paragraph mode |
| :slurp | Slurp mode |
You'll be able to stack disciplines that make sense to stack, so, for instance, you could say:
open(FH, "<:para:crlf:uni", $path) or die "can't open $path: $!";
while ($para = <FH>) { ... }
That would set up disciplines to:
-
read in some form of Unicode and translate to Perl's internal UTF-8 format if the file isn't already in UTF-8,
-
look for variants of line-ending sequences, translating them all to \n, and
-
process the file into paragraph-sized chunks, much as $/ = "" does.
If you want to set the default open mode (:def) to something other than :text, you can declare that at the top of your file with the open pragma:
In fact, it would be really nice if that were the default :text discipline someday. It perfectly captures the spirit of "Be liberal in what you accept, and strict in what you produce."use open IN => ":any", OUT => ":utf8";
29.2.105. opendir
This function opens a directory named EXPR for processing by readdir, telldir, seekdir, rewinddir, and closedir. The function returns true if successful. Directory handles have their own namespace separate from filehandles.opendir DIRHANDLE, EXPR
29.2.106. ord
This function returns the numeric value (ASCII, Latin-1, or Unicode) of the first character of EXPR. The return value is always unsigned. If you want a signed value, use unpack('c',EXPR). If you want all the characters of the string converted to a list of numbers, use unpack('U*',EXPR) instead.ord EXPR ord
29.2.107. our
An our declares one or more variables to be valid globals within the enclosing block, file, or eval. That is, our has the same rules as a my declaration for determination of visibility, but does not create a new private variable; it merely allows unfettered access to the existing package global. If more than one value is listed, the list must be placed in parentheses.our TYPE EXPR : ATTRIBUTES our EXPR : ATTRIBUTES our TYPE EXPR our EXPR
The primary use of an our declaration is to hide the variable from the effects of a use strict "vars" declaration; since the variable is masquerading as a my variable, you are permitted to use the declared global variable without qualifying it with its package. However, just like the my variable, this only works within the lexical scope of the our declaration. In this respect, it differs from use vars, which affects the entire package and is not lexically scoped.
our is also like my in that you are allowed to declare variables with a TYPE and with ATTRIBUTES. Here is the syntax:
As of this writing, it's not entirely clear what that will mean. Attributes could affect either the global or the local interpretation of $spot. On the one hand, it would be most like my variables for attributes to warp the current local view of $spot without interfering with other views of the global in other places. On the other hand, if one module declares $spot to be a Dog, and another declares $spot to be a Cat, you could end up with meowing dogs or barking cats. This is a subject of ongoing research, which is a fancy way to say we don't know what we're talking about yet. (Except that we do know what to do with the TYPE declaration when the variable refers to a pseudohash--see "Managing Instance Data" in Chapter 12, "Objects".)our Dog $spot :ears(short) :tail(long);
Another way in which our is like my is in its visibility. An our declaration declares a global variable that will be visible across its entire lexical scope, even across package boundaries. The package in which the variable is located is determined at the point of the declaration, not at the point of use. This means the following behavior holds and is deemed to be a feature:
However, the distinction between my creating a new, private variable and our exposing an existing, global variable is important, especially in assignments. If you combine a run-time assignment with an our declaration, the value of the global variable does not disappear once the our goes out of scope. For that, you need local:package Foo; our $bar; # $bar is $Foo::bar for rest of lexical scope $bar = 582; package Bar; print $bar; # prints 582, just as if "our" had been "my"
($x, $y) = ("one", "two");
print "before block, x is $x, y is $y\n";
{
our $x = 10;
local our $y = 20;
print "in block, x is $x, y is $y\n";
}
print "past block, x is $x, y is $y\n";
That prints out:
Multiple our declarations in the same lexical scope are allowed if they are in different packages. If they happen to be in the same package, Perl will emit warnings if you ask it to.before block, x is one, y is two in block, x is 10, y is 20 past block, x is 10, y is two
See also local, my, and the section "Scoped Declarations" in Chapter 4, "Statements and Declarations".use warnings; package Foo; our $bar; # declares $Foo::bar for rest of lexical scope $bar = 20; package Bar; our $bar = 30; # declares $Bar::bar for rest of lexical scope print $bar; # prints 30 our $bar; # emits warning
29.2.108. pack
This function takes a LIST of ordinary Perl values and converts them into a string of bytes according to the TEMPLATE and returns this string. The argument list will be padded or truncated as necessary. That is, if you provide fewer arguments than the TEMPLATE requires, pack assumes additional null arguments. If you provide more arguments than the TEMPLATE requires, the extra arguments are ignored. Unrecognized format elements in TEMPLATE will raise an exception.pack TEMPLATE, LIST
The template describes the structure of the string as a sequence of fields. Each field is represented by a single character that describes the type of the value and its encoding. For instance, a format character of N specifies an unsigned four-byte integer in big-endian byte order.
Fields are packed in the order given in the template. For example, to pack an unsigned one-byte integer and a single-precision floating-point value into a string, you'd say:
$string = pack("Cf", 244, 3.14);
The first byte of the returned string has the value 244. The
remaining bytes are the encoding of 3.14 as a single-precision
float. The particular encoding of the floating point number depends
on your computer's hardware.
Some important things to consider when packing are:
-
the type of data (such as integer or float or string),
-
the range of values (such as whether your integers will fit into one, two, four, or maybe even eight bytes; or whether you're packing 8-bit or Unicode characters),
-
whether your integers are signed or unsigned, and
-
the encoding to use (such as native, little-endian, or big-endian packing of bits and bytes).
Table 29-3 lists the format characters and their meanings. (Other characters can occur in formats as well; these are described later.)
Table 29.3. Template Characters for pack/unpack
| Character | Meaning |
|---|---|
| a | A null-padded string of bytes |
| A | A space-padded string of bytes |
| b | A bit string, in ascending bit order inside each byte (like vec) |
| B | A bit string, in descending bit order inside each byte |
| c | A signed char (8-bit integer) value |
| C |
An unsigned char (8-bit integer) value; see U for Unicode |
| d | A double-precision floating-point number in native format |
| f | A single-precision floating-point number in native format |
| h | A hexadecimal string, low nybble first |
| H | A hexadecimal string, high nybble first |
| i | A signed integer value, native format |
| I | An unsigned integer value, native format |
| l | A signed long value, always 32 bits |
| L | An unsigned long value, always 32 bits |
| n | A 16-bit short in "network" (big-endian) order |
| N | A 32-bit long in "network" (big-endian) order |
| p | A pointer to a null-terminated string |
| P | A pointer to a fixed-length string |
| q | A signed quad (64-bit integer) value |
| Q | An unsigned quad (64-bit integer) value |
| s | A signed short value, always 16 bits |
| S | An unsigned short value, always 16 bits |
| u | A uuencoded string |
| U | A Unicode character number |
| v | A 16-bit short in "VAX" (little-endian) order |
| V | A 32-bit long in "VAX" (little-endian) order |
| w | A BER compressed integer |
| x | A null byte (skip forward a byte) |
| X | Back up a byte |
| Z | A null-terminated (and null-padded) string of bytes |
| @ | Null-fill to absolute position |
You may freely place whitespace and comments in your TEMPLATEs. Comments start with the customary # symbol and extend up through the first newline (if any) in the TEMPLATE.
Each letter may be followed by a number indicating the count, interpreted as a repeat count or length of some sort, depending on the format. With all formats except a, A, b, B, h, H, P, and Z, count is a repeat count, so pack gobbles up that many values from the LIST. A * for the count means however many items are left.
The a, A, and Z formats gobble just one value, but pack it as a byte string of length count, padding with nulls or spaces as necessary. When unpacking, A strips trailing spaces and nulls, Z strips everything after the first null, and a returns the literal data unmolested. When packing, a and Z are equivalent.
Similarly, the b and B formats pack a string count bits long. Each byte of the input field generates 1 bit of the result based on the least-significant bit of each input byte (that is, on ord($byte) % 2). Conveniently, that means bytes 0 and 1 generate bits 0 and 1. Starting from the beginning of the input string, each 8-tuple of bytes is converted to a single byte of output. If the length of the input string is not divisible by 8, the remainder is packed as if padded by 0's. Similarly, during unpacking any extra bits are ignored. If the input string is longer than needed, extra bytes are ignored. A * for the count means to use all bytes from the input field. On unpacking, the bits are converted to a string of 0s and 1s.
The h and H formats pack a string of count nybbles (4-bit groups often represented as hexadecimal digits).
The p format packs a pointer to a null-terminated string. You are responsible for ensuring the string is not a temporary value (which can potentially get deallocated before you get around to using the packed result). The P format packs a pointer to a structure of the size indicated by count. A null pointer is created if the corresponding value for p or P is undef.
The / character allows packing and unpacking of strings where the packed structure contains a byte count followed by the string itself. You write length-item/string-item. The length-item can be any pack template letter, and describes how the length value is packed. The ones likely to be of most use are integer-packing ones like n (for Java strings), w (for ASN.1 or SNMP) and N (for Sun XDR). The string-item must, at present, be A*, a*, or Z*. For unpack, the length of the string is obtained from the length-item, but if you put in the *, it will be ignored.
unpack 'C/a', "\04Gurusamy"; # gives 'Guru'
unpack 'a3/A* A*', '007 Bond J '; # gives (' Bond','J')
pack 'n/a* w/a*','hello,','world'; # gives "\000\006hello,\005world"
The length-item is not returned explicitly from unpack.
Adding a count to the length-item letter is unlikely to do anything
useful, unless that letter is A, a, or Z. Packing with a
length-item of a or Z may introduce null (\0) characters,
which Perl does not regard as legal in numeric strings.
The integer formats s, S, l, and L may be immediately followed by a ! to signify native shorts or longs instead of exactly 16 or 32 bits respectively. Today, this is an issue mainly in 64-bit platforms, where the native shorts and longs as seen by the local C compiler can be different than these values. (i! and I! also work but only because of completeness; they are identical to i and I.)
The actual sizes (in bytes) of native shorts, ints, longs, and long longs on the platform where Perl was built are also available via the Config module:
use Config;
print $Config{shortsize}, "\n";
print $Config{intsize}, "\n";
print $Config{longsize}, "\n";
print $Config{longlongsize}, "\n";
Just because Configure knows the size of a long long, doesn't
necessarily imply that you have q or Q formats available to
you. (Some systems do, but you're probably not running one. Yet.)
Integer formats of greater than one byte in length (s, S, i, I, l, and L) are inherently nonportable between processors because they obey the native byte order and endianness. If you want portable packed integers, use the formats n, N, v, and V; their byte endianness and size are known.
Floating-point numbers are in the native machine format only. Because of the variety of floating formats and lack of a standard "network" representation, no facility for interchange has been made. This means that packed floating-point data written on one machine may not be readable on another. This is a problem even when both machines use IEEE floating-point arithmetic, because the endian-ness of the memory representation is not part of the IEEE spec.
Perl uses doubles internally for all floating-point calculation, so converting from double into float, then back again to double will lose precision. This means that unpack("f", pack("f", $foo)) will not generally equal $foo.
You are responsible for any alignment or padding considerations expected by other programs, particularly those programs that were created by a C compiler with its own idiosyncratic notions of how to lay out a C struct on the particular architecture in question. You'll have to add enough x's while packing to make up for this. For example, a C declaration of:
struct foo {
unsigned char c;
float f;
};
might be written out in a "C x f" format, a "C x3 f" format,
or even a "f C" format--just to name a few. The pack and
unpack functions handle their input and output as flat sequences
of bytes because there is no way for them to know where the bytes
are going to or coming from.
Let's look at some examples. This first pair packs numeric values into bytes:
This one does the same thing with Unicode circled letters:$out = pack "CCCC", 65, 66, 67, 68; # $out eq "ABCD" $out = pack "C4", 65, 66, 67, 68; # same thing
$foo = pack("U4",0x24b6,0x24b7,0x24b8,0x24b9);
This does a similar thing, with a couple of nulls thrown in:
Packing your shorts doesn't imply that you're portable:$out = pack "CCxxCC", 65, 66, 67, 68; # $out eq "AB\0\0CD"
$out = pack "s2", 1, 2; # "\1\0\2\0" on little-endian
# "\0\1\0\2" on big-endian
On binary and hex packs, the count refers to the
number of bits or nybbles, not the number of bytes produced:
The length on an a field applies only to one string:$out = pack "B32", "01010000011001010111001001101100"; $out = pack "H8", "5065726c"; # both produce "Perl"
To get around that limitation, use multiple specifiers:$out = pack "a4", "abcd", "x", "y", "z"; # "abcd"
The a format does null filling:$out = pack "aaaa", "abcd", "x", "y", "z"; # "axyz" $out = pack "a" x 4, "abcd", "x", "y", "z"; # "axyz"
This template packs a C struct tm record (at least on some systems):$out = pack "a14", "abcdefg"; # "abcdefg\0\0\0\0\0\0\0"
Generally, the same template may also be used in the unpack function, although some formats act differently, notably a, A, and Z.$out = pack "i9pl", gmtime(), $tz, $toff;
If you want to join fixed-width text fields together, use pack with a TEMPLATE of several A or a formats:
$string = pack("A10" x 10, @data);
If you want to join variable-width text fields with a separator, use the
join function instead:
$string = join(" and ", @data);
$string = join("", @data); # null separator
Although all of our examples used literal strings as templates,
there is no reason you couldn't pull in your templates from a disk
file. You could build an entire relational database system around
this function. (What that would prove about you we won't get into.)
29.2.109. package
This is not really a function, but a declaration that says that the rest of the innermost enclosing scope belongs to the indicated symbol table or namespace. (The scope of a package declaration is thus the same as the scope of a my or our declaration.) Within its scope, the declaration causes the compiler to resolve all unqualified global identifiers by looking them up in the declared package's symbol table.package NAMESPACE package
A package declaration affects only global variables--including those on which you've used local--not lexical variables created with my. It only affects unqualified global variables; global variables that are qualified with a package name of their own ignore the current declared package. Global variables declared with our are unqualified and therefore respect the current package, but only at the point of declaration, after which they behave like my variables. That is, for the rest of their lexical scope, our variables are "nailed" to the package in use at the point of declaration, even if a subsequent package declaration intervenes.
Typically, you would put a package declaration as the first thing in a file that is to be included by the require or use operator, but you can put one anywhere a statement would be legal. When creating a traditional or objected-oriented module file, it is customary to name the package the same name as the file to avoid confusion. (It's also customary to name such packages beginning with a capital letter because lowercase modules are by convention interpreted as pragmatic modules.)
You can switch into a given package in more than one place; it merely influences which symbol table is used by the compiler for the rest of that block. (If the compiler sees another package declaration at the same level, the new declaration overrides the previous one.) Your main program is assumed to start with an invisible package main declaration.
You can refer to variables, subroutines, handles, and formats in other packages by qualifying the identifier with the package name and a double colon: $Package::Variable. If the package name is null, the main package is assumed. That is, $::sail is equivalent to $main::sail, as well as to $main'sail, which is still occasionally seen in older code.
Here's an example:
This prints:package main; $sail = "hale and hearty"; package Mizzen; $sail = "tattered"; package Whatever; print "My main sail is $main::sail.\n"; print "My mizzen sail is $Mizzen::sail.\n";
The symbol table for a package is stored in a hash with a name ending in a double colon. The main package's symbol table is named %main:: for example. So the existing package symbol *main::sail can also be accessed as $main::{"sail"}.My main sail is hale and hearty. My mizzen sail is tattered.
If NAMESPACE is omitted, then there is no current package, and all identifiers must be fully qualified or declared as lexicals. This is stricter than use strict since it also extends to function names.
See Chapter 10, "Packages", for more information about packages. See my earlier in this chapter for other scoping issues.
29.2.110. pipe
Like the corresponding syscall, this function opens a pair of connected pipes--see pipe(2). This call is usually used right before a fork, after which the pipe's reader should close WRITEHANDLE, and the writer close READHANDLE. (Otherwise the pipe won't indicate EOF to the reader when the writer closes it.) If you set up a loop of piped processes, deadlock can occur unless you are remarkably careful. In addition, note that Perl's pipes use standard I/O buffering, so you may need to set $| ($OUTPUT_AUTOFLUSH) on your WRITEHANDLE to flush after each output operation, depending on the application--see select (output filehandle).pipe READHANDLE, WRITEHANDLE
(As with open, if either filehandle is undefined, it will be autovivfied.)
Here's a small example:
pipe(README, WRITEME);
unless ($pid = fork) { # child
defined $pid or die "can't fork: $!";
close(README);
for $i (1..5) { print WRITEME "line $i\n" }
exit;
}
$SIG{CHLD} = sub { waitpid($pid, 0) };
close(WRITEME);
@strings = <README>;
close(README);
print "Got:\n", @strings;
Notice how the writer closes the read end and the reader closes the
write end. You can't use one pipe for two-way communication. Either
use two different pipes or the socketpair syscall
for that. See the section "Pipes" in Chapter 16, "Interprocess Communication".
29.2.111. pop
This function treats an array like a stack--it pops (removes) and returns the last value of the array, shortening the array by one element. If ARRAY is omitted, the function pops @_ within the lexical scope of subroutines and formats; it pops @ARGV at file scopes (typically the main program) or within the lexical scopes established by the evalSTRING, BEGIN {}, CHECK {}, INIT {}, and END {} constructs. It has the same effect as:pop ARRAY pop
or:$tmp = $ARRAY[$#ARRAY--];
If there are no elements in the array, pop returns undef. (But don't depend on that to tell you when the array is empty if your array contains undef values!) See also push and shift. If you want to pop more than one element, use splice.$tmp = splice @ARRAY, -1;
The pop requires its first argument to be an array, not a list. If you just want the last element of a list, use this:
( LIST )[-1]
29.2.112. pos
This function returns the location in SCALAR where the last m//g search over SCALAR left off. It returns the offset of the character after the last one matched. (That is, it's equivalent to length($`) + length($&).) This is the offset where the next m//g search on that string will start. Remember that the offset of the beginning of the string is 0. For example:pos SCALAR pos
$graffito = "fee fie foe foo";
while ($graffito =~ m/e/g) {
print pos $graffito, "\n";
}
prints 2, 3, 7, and 11, the offsets of each of the
characters following an "e". The pos function may be assigned a value
to tell the next m//g where to start:
$graffito = "fee fie foe foo";
pos $graffito = 4; # Skip the fee, start at fie
while ($graffito =~ m/e/g) {
print pos $graffito, "\n";
}
This prints only 7 and 11. The regular expression assertion
\G matches only at the location currently specified by pos
for the string being searched. See the section "Positions" in Chapter 5, "Pattern Matching".
29.2.113. print
This function prints a string or a comma-separated list of strings. If set, the contents of the $\ ($OUTPUT_RECORD_SEPARATOR) variable will be implicitly printed at the end of the list. The function returns true if successful, false otherwise. FILEHANDLE may be a scalar variable name (unsubscripted), in which case the variable contains either the name of the actual filehandle or a reference to a filehandle object of some sort. As with any other indirect object, FILEHANDLE may also be a block that returns such a value:print FILEHANDLE LIST print LIST print
print { $OK ? "STDOUT" : "STDERR" } "stuff\n";
print { $iohandle[$i] } "stuff\n";
If FILEHANDLE is a variable and the next token is a term,
it may be misinterpreted as an operator unless you interpose a + or
put parentheses around the arguments. For example:
If FILEHANDLE is omitted, the function prints to the currently selected output filehandle, initially STDOUT. To set the default output filehandle to something other than STDOUT, use the selectFILEHANDLE operation.[9] If LIST is also omitted, the function prints $_. Because print takes a LIST, anything in the LIST is evaluated in list context. Thus, when you say:print $a - 2; # prints $a - 2 to default filehandle (usually STDOUT) print $a (- 2); # prints -2 to filehandle specified in $a print $a -2; # also prints -2 (weird parsing rules :-)
it is not going to print the next line from standard input, but all the rest of the lines from standard input up to end-of-file, since that's what <STDIN> returns in list context. If you want the other thing, say:print OUT <STDIN>;
Also, remembering the if-it-looks-like-a-function-it-is-a-function rule, be careful not to follow the print keyword with a left parenthesis unless you want the corresponding right parenthesis to terminate the arguments to the print--interpose a + or put parens around all the arguments:print OUT scalar <STDIN>;
print (1+2)*3, "\n"; # WRONG print +(1+2)*3, "\n"; # ok print ((1+2)*3, "\n"); # ok
[9] Thus, STDOUT isn't really the default filehandle for print. It's merely the default default filehandle.
29.2.114. printf
This function prints a formatted string to FILEHANDLE or, if omitted, the currently selected output filehandle, initially STDOUT. The first item in the LIST must be a string that says how to format the rest of the items. This is similar to the C library's printf(3) and fprintf(3) functions. The function is equivalent to:printf FILEHANDLE FORMAT, LIST printf FORMAT, LIST
except that $\ ($OUTPUT_RECORD_SEPARATOR) is not appended. If use locale is in effect, the character used for the decimal point in formatted floating-point numbers is affected by the LC_NUMERIC locale.print FILEHANDLE sprintf FORMAT, LIST
An exception is raised only if an invalid reference type is used as the FILEHANDLE argument. Unrecognized formats are passed through intact. Both situations trigger warnings if they're enabled.
See the print and sprintf functions elsewhere in this chapter. The description of sprintf includes the list of format specifications. We'd duplicate them here, but this book is already an ecological disaster.
If you omit both the FORMAT and the LIST, $_ is used--but in that case, you should have been using print. Don't fall into the trap of using a printf when a simple print would do. The print function is more efficient and less error prone.
29.2.115. prototype
Returns the prototype of a function as a string (or undef if the function has no prototype). FUNCTION is a reference to, or the name of, the function whose prototype you want to retrieve.prototype FUNCTION
If FUNCTION is a string starting with CORE::, the rest is taken as a name for Perl built-in, and an exception is raised if there is no such built-in. If the built-in is not overridable (such as qw//) or its arguments cannot be expressed by a prototype (such as system), the function returns undef because the built-in does not really behave like a Perl function. Otherwise, the string describing the equivalent prototype is returned.
29.2.116. push
This function treats ARRAY as a stack and pushes the values of LIST onto the end of ARRAY. The length of ARRAY increases by the length of LIST. The function returns this new length. The push function has the same effect as:push ARRAY, LIST
foreach $value (listfunc()) {
$array[++$#array] = $value;
}
or:
but it is more efficient (for both you and your computer). You can use push in combination with shift to make a fairly time-efficient shift register or queue:splice @array, @array, 0, listfunc();
for (;;) {
push @array, shift @array;
...
}
See also pop and unshift.
29.2.117. q/STRING/
Generalized quotes. See the "Pick your own quotes" section Chapter 2, "Bits and Pieces". For status annotations on qx//, see readpipe. For status annotations on qr//, see m//. See also "Staying in Control" in Chapter 5, "Pattern Matching".q/STRING/ qq/STRING/ qr/STRING/ qw/STRING/ qx/STRING/
29.2.118. quotemeta
This function returns the value of EXPR with all nonalphanumeric characters backslashed. (That is, all characters not matching /[A-Za-z_0-9]/ will be preceded by a backslash in the returned string, regardless of locale settings.) This is the internal function implementing the \Q escape in interpolative contexts (including double-quoted strings, backticks, and patterns).quotemeta EXPR quotemeta
29.2.119. rand
This function returns a pseudorandom floating-point number greater than or equal to 0 and less than the value of EXPR. (EXPR should be positive.) If EXPR is omitted, the function returns a floating-point number between 0 and 1 (including 0, but excluding 1). rand automatically calls srand unless srand has already been called. See also srand.rand EXPR rand
To get an integral value, such as for a die roll, combine this with int, as in:
Because Perl uses your own C library's pseudorandom number function, like random(3) or drand48(3), the quality of the distribution is not guaranteed. If you need stronger randomness, such as for cryptographic purposes, you might consult instead the documentation on random(4) (if your system has a /dev/random or /dev/urandom device), the CPAN module Math::TrulyRandom, or a good textbook on computational generation of pseudorandom numbers, such as the second volume of Knuth.[10]$roll = int(rand 6) + 1; # $roll now a number between 1 and 6
[10] Knuth, D.E. The Art of Computer Programming, Seminumerical Algorithms, vol. 2, 3d ed. (Reading, Mass.: Addison-Wesley, 1997). ISBN 0-201-89684-2.
29.2.120. read [taintgray]
This function attempts to read LENGTH bytes of data into variable SCALAR from the specified FILEHANDLE. The function returns the number of bytes read or 0 at end-of-file. It returns undef on error. SCALAR will grow or shrink to the length actually read. The OFFSET, if specified, determines where in the variable to start putting bytes, so that you can read into the middle of a string.read FILEHANDLE, SCALAR, LENGTH, OFFSET read FILEHANDLE, SCALAR, LENGTH
To copy data from filehandle FROM into filehandle TO, you could say:
while (read(FROM, $buf, 16384)) {
print TO $buf;
}
The opposite of a read is simply a print, which already
knows the length of the string you want to write and can write a string
of any length. Don't make the mistake of using write, which is
solely used with formats.
Perl's read function is implemented in terms of standard I/O's fread(3) function, so the actual read(2) syscall may read more than LENGTH bytes to fill the input buffer, and fread(3) may do more than one read(2) syscall in order to fill the buffer. To gain greater control, specify the real syscall using sysread. Calls to read and sysread should not be intermixed unless you are into heavy wizardry (or pain). Whichever one you use, be aware that when reading from a file containing Unicode or any other multibyte encoding, the buffer boundary may fall in the middle of a character.
29.2.121. readdir
This function reads directory entries (which are simple filenames) from a directory handle opened by opendir. In scalar context, this function returns the next directory entry, if any; otherwise, it returns undef. In list context, it returns all the rest of the entries in the directory, which will be a null list if there are no entries. For example:readdir DIRHANDLE
That prints all the files in the current directory on one line. If you want to avoid the "." and ".." entries, incant one of these (whichever you think is least unreadable):opendir(THISDIR, ".") or die "serious dainbramage: $!"; @allfiles = readdir THISDIR; closedir THISDIR; print "@allfiles\n";
@allfiles = grep { $_ ne '.' and $_ ne '..' } readdir THISDIR;
@allfiles = grep { not /^[.][.]?\z/ } readdir THISDIR;
@allfiles = grep { not /^\.{1,2}\z/ } readdir THISDIR;
@allfiles = grep !/^\.\.?\z/, readdir THISDIR;
And to avoid all .* files (like the ls program):
To get just text files, say this:@allfiles = grep !/^\./, readdir THISDIR;
But watch out on that last one because the result of readdir needs to have the directory part glued back on if it's not the current directory--like this:@textfiles = grep -T, readdir THISDIR;
opendir(THATDIR, $path) or die "can't opendir $path: $!";
@dotfiles = grep { /^\./ && -f } map { "$path/$_" } readdir(THATDIR);
closedir THATDIR;
29.2.122. readline [taintgray]
This is the internal function implementing the <FILEHANDLE> operator, but you can use it directly. The function reads the next record from FILEHANDLE, which may be a filehandle name or an indirect filehandle expression that returns either the name of the actual filehandle or a reference to anything resembling a filehandle object, such as a typeglob. (Versions of Perl prior to 5.6 accept only a typeglob.) In scalar context, each call reads and returns the next record until end-of-file is reached, whereupon the subsequent call returns undef. In list context, readline reads records until end-of-file is reached and then returns a list of records. By "record", we normally mean a line of text, but changing the value of $/ ($INPUT_RECORD_SEPARATOR) from its default value causes this operator to "chunk" the text differently. Likewise, some input disciplines such as :para (paragraph mode) will return records in chunks other than lines. Setting the :slurp discipline (or undefining $/) makes the chunk size entire files.readline FILEHANDLE
When slurping files in scalar context, if you happen to slurp an empty file, readline returns "" the first time, and undef each subsequent time. When slurping from magical ARGV filehandle, each file returns one chunk (again, null files return as ""), followed by a single undef when the files are exhausted.
The <FILEHANDLE> operator is discussed in more detail in the section "Input Operators" in Chapter 2, "Bits and Pieces".
$line = <STDIN>; $line = readline(STDIN); # same thing $line = readline(*STDIN); # same thing $line = readline(\*STDIN); # same thing open my $fh, "<&=STDIN" or die; bless $fh => 'AnyOldClass'; $line = readline($fh); # same thing
29.2.123. readlink
This function returns the filename pointed to by a symbolic link. EXPR should evaluate to a filename, the last component of which is a symbolic link. If it is not a symbolic link, or if symbolic links are not implemented on the filesystem, or if some system error occurs, undef is returned, and you should check the error code in $!.readlink EXPR readlink
Be aware that the returned symlink may be relative to the location you specified. For instance, you may say:
and readlink might return:readlink "/usr/local/src/express/yourself.h"
which is not directly usable as a filename unless your current directory happens to be /usr/local/src/express.../express.1.23/includes/yourself.h
29.2.124. readpipe
This is the internal function implementing the qx// quote construct (also known as the backticks operator). It is occasionally handy when you need to specify your EXPR in a way that wouldn't be handy using the quoted form. Be aware that we may change this interface in the future to support a LIST argument in order to make it more like the exec function, so don't assume that it will continue to provide scalar context for EXPR. Supply the scalar yourself, or try the LIST form. Who knows, it might work by the time you read this.readpipe scalar EXPR readpipe LIST (proposed)
29.2.125. recv [taintgray]
This function receives a message on a socket. It attempts to receive LENGTH bytes of data into variable SCALAR from the specified SOCKET filehandle. The function returns the address of the sender, or undef if there's an error. SCALAR will grow or shrink to the length actually read. The function takes the same flags as recv(2). See the section "Sockets" in Chapter 16, "Interprocess Communication".recv SOCKET, SCALAR, LEN, FLAGS
29.2.126. redo
The redo operator restarts a loop block without reevaluating the conditional. The continue block, if any, is not executed. If the LABEL is omitted, the operator refers to the innermost enclosing loop. This operator is normally used by programs that wish to deceive themselves about what was just input:redo LABEL redo
# A loop that joins lines continued with a backslash.
while (<STDIN>) {
if (s/\\\n$// && defined($nextline = <STDIN>)) {
$_ .= $nextline;
redo;
}
print; # or whatever...
}
redo cannot be used to exit a block that returns a value such
as eval {}, sub {}, or do {}, and should not be used to
exit a grep or map operation. With warnings enabled, Perl will warn you if you redo a loop not in
your current lexical scope.
A block by itself is semantically identical to a loop that executes once. Thus redo inside such a block will effectively turn it into a looping construct. See the section "Loop Control" in Chapter 4, "Statements and Declarations".
29.2.127. ref
The ref operator returns a true value if EXPR is a reference, false otherwise. The value returned depends on the type of thing the reference refers to. Built-in types include:ref EXPR ref
If the referenced object has been blessed into a package, then that package name is returned instead. You can think of ref as a "typeof" operator.SCALAR ARRAY HASH CODE GLOB REF LVALUE IO::Handle
if (ref($r) eq "HASH") {
print "r is a reference to a hash.\n";
}
elsif (ref($r) eq "Hump") { # Naughty--see below.
print "r is a reference to a Hump object.\n";
}
elsif (not ref $r) {
print "r is not a reference at all.\n";
}
It's considered bad OO style to test your object's class for equality to
any particular class name, since a derived class will have a different
name, but should be allowed access to the base class's methods.
It's better to use the UNIVERSAL method isa as follows:
if ($r->isa("Hump") }
print "r is a reference to a Hump object, or subclass.\n";
}
It's usually best not to test at all, since the OO mechanism won't
send the object to your method unless it thinks it's appropriate in
the first place. See Chapter 8, "References" and Chapter 12, "Objects" for more details. See also the
reftype function under the use
attributes pragma in Chapter 31, "Pragmatic Modules".
29.2.128. rename
This function changes the name of a file. It returns true for success, false otherwise. It will not (usually) work across filesystem boundaries, although on a Unix system the mv command can sometimes be used to compensate for this. If a file named NEWNAME already exists, it will be destroyed. Non-Unix systems might have additional restrictions.rename OLDNAME, NEWNAME
See the standard File::Copy module for cross-filesystem renames.
29.2.129. require
This function asserts a dependency of some kind on its argument.require VERSION require EXPR require
If the argument is a string, require loads and executes the Perl code found in the separate file whose name is given by the string. This is similar to performing a do on a file, except that require checks to see whether the library file has been loaded already and raises an exception if any difficulties are encountered. (It can thus be used to express file dependencies without worrying about duplicate compilation.) Like its cousins do and use, require knows how to search the include path stored in the @INC array and to update %INC upon success. See Chapter 28, "Special Names".
The file must return true as the last value to indicate successful execution of any initialization code, so it's customary to end such a file with 1; unless you're sure it'll return true otherwise.
If require's argument is a version number of the form 5.6.2, require demands that the currently executing version of Perl be at least that version. (Perl also accepts a floating point number such as 5.005_03 for compatibility with older versions of Perl, but that form is now discouraged because folks from other cultures don't understand it.) Thus, a script that requires Perl version 5.6 can put as its first line:
and earlier versions of Perl will abort. Like all requires, however, this is done at run-time. You might prefer to say use 5.6.0 for a compile-time check. See also $PERL_VERSION in Chapter 28, "Special Names".require 5.6.0; # or require v5.6.0
If require's argument is a bare package name (see package), require assumes an automatic .pm suffix, making it easy to load standard modules. This behavior is like use, except that it happens at run time rather than compile time, and the import method is not called. For example, to pull in Socket.pm without introducing any symbols into the current package, say this:
However, you can get the same effect with the following, which has the advantage of giving a compile-time warning if Socket.pm can't be located:require Socket; # instead of "use Socket;"
Using require on a bare name also replaces any :: in the package name with your system's directory separator, traditionally /. In other words, if you try this:use Socket ();
The require function looks for the Foo/Bar.pm file in the directories specified in the @INC array. But if you try this:require Foo::Bar; # a splendid bare name
or this:$class = 'Foo::Bar'; require $class; # $class is not a bare name
the require function will look for the Foo::Bar file in the @INC array and will complain about not finding Foo::Bar there. If so, you can do this:require "Foo::Bar"; # quoted literal not a bare name
See also doFILE, the use command, the use lib pragma, and the standard FindBin module.eval "require $class";
29.2.130. reset
This function is generally used (or abused) at the top of a loop or in a continue block at the end of a loop, to clear global variables or reset ?? searches so that they work again. The expression is interpreted as a list of single characters (hyphens are allowed for ranges). All scalar variables, arrays, and hashes beginning with one of those letters are reset to their pristine state. If the expression is omitted, one-match searches (?PATTERN?) are reset to match again. The function resets variables or searches for the current package only. It always returns true.reset EXPR reset
To reset all "X" variables, say this:
To reset all lowercase variables, say this:reset 'X';
Lastly, to just reset ?? searches, say:reset 'a-z';
Resetting "A-Z" in package main is not recommended since you'll wipe out your global ARGV, INC, ENV, and SIG arrays and hashes.reset;
Lexical variables (created by my) are not affected. Use of reset is vaguely deprecated because it easily clears out entire namespaces and because the ?? operator is itself vaguely deprecated.
See also the delete_package() function from the standard Symbol module, and the whole issue of Safe compartments documented in the section "Safe Compartments" in Chapter 23, "Security".
29.2.131. return
This operator causes the current subroutine (or eval or doFILE) to return immediately with the specified value. Attempting to use return outside these three places raises an exception. Note also that an eval cannot do a return on behalf of the subroutine that called the eval.return EXPR return
EXPR may be evaluated in list, scalar, or void context, depending on how the return value will be used, which may vary from one execution to the next. That is, the supplied expression will be evaluated in the context of the subroutine invocation. If the subroutine was called in a scalar context, EXPR is also evaluated in scalar context. If the subroutine was invoked in list context, then EXPR is also evaluated in list context and can return a list value. A return with no argument returns the scalar value undef in scalar context, an empty list () in list context, and (naturally) nothing at all in void context. The context of the subroutine call can be determined from within the subroutine by using the (misnamed) wantarray function.
29.2.132. reverse
In list context, this function returns a list value consisting of the elements of LIST in the opposite order. The function can be used to create descending sequences:reverse LIST
for (reverse 1 .. 10) { ... }
Because of the way hashes flatten into lists when passed as a LIST,
reverse can also be used to invert a hash, presuming the values are
unique:
In scalar context, the function concatenates all the elements of LIST and then returns the reverse of that resulting string, character by character.%barfoo = reverse %foobar;
A small hint: reversing a list sorted earlier by a user-defined function can often be achieved more easily by sorting the list in the opposite direction in the first place.
29.2.133. rewinddir
This function sets the current position to the beginning of the directory for the readdir routine on DIRHANDLE. The function may not be available on all machines that support readdir--rewinddir dies if unimplemented. It returns true on success, false otherwise.rewinddir DIRHANDLE
29.2.134. rindex
This function works just like index except that it returns the position of the last occurrence of SUBSTR in STR (a reverse index). The function returns $[-1 if not SUBSTR is found. Since $[ is virtually always 0 nowadays, the function virtually always returns -1. POSITION, if specified, is the rightmost position that may be returned. To work your way through a string backward, say:rindex STR, SUBSTR, POSITION rindex STR, SUBSTR
$pos = length $string;
while (($pos = rindex $string, $lookfor, $pos) >= 0) {
print "Found at $pos\n";
$pos--;
}
29.2.135. rmdir
This function deletes the directory specified by FILENAME if the directory is empty. If the function succeeds, it returns true; otherwise, it returns false. See also the File::Path module if you want to remove the contents of the directory first and don't care to shell out to call rm -r for some reason. (Such as not having a shell, or an rm command, because you haven't got PPT yet.)rmdir FILENAME rmdir
29.2.136. s/// [taintgray]
The substitution operator. See the section "Pattern-Matching Operators" in Chapter 5, "Pattern Matching".s///
29.2.137. scalar
This pseudofunction may be used within a LIST to force EXPR to be evaluated in scalar context when evaluation in the list context would produce a different result. For example:scalar EXPR
prevents <STDIN> from reading all the lines from standard input before doing the assignment, since assignment to a list (even a my list) provides a list context. (Without the scalar in this example, the first line from <STDIN> would still be assigned to $nextvar, but the subsequent lines would be read and thrown away, since the list we're assigning to is only able to receive a single scalar value.)my ($nextvar) = scalar <STDIN>;
Of course, a simpler, less-cluttered way would be to just leave the parentheses off, thereby changing the list context to a scalar one:
Since a print function is a LIST operator, you have to say:my $nextvar = <STDIN>;
if you want the length of @ARRAY to be printed out.print "Length is ", scalar(@ARRAY), "\n";
There's no "list" function corresponding to scalar since, in practice, one never needs to force evaluation in a list context. That's because any operation that wants LIST already provides a list context to its list arguments for free.
Because scalar is a unary operator, if you accidentally use a parenthesized list for the EXPR, this behaves as a scalar comma expression, evaluating all but the last element in void context and returning the final element evaluated in scalar context. This is seldom what you want. The following single statement:
is the (im)moral equivalent of these two:print uc(scalar(&foo,$bar)),$baz;
See Chapter 2, "Bits and Pieces" for more details on the comma operator. See "Prototypes" in Chapter 6, "Subroutines" for more on unary operators.&foo; print(uc($bar),$baz);
29.2.138. seek
This function positions the file pointer for FILEHANDLE, just like the fseek(3) call of standard I/O. The first position in a file is at offset 0, not offset 1. Also, offsets refer to byte positions, not line numbers. In general, since line lengths vary, it's not possible to access a particular line number without examining the whole file up to that point, unless all your lines are known to be of a particular length, or you've built an index that translates line numbers into byte offsets. (The same restrictions apply to character positions in files with variable-length character encodings: the operating system doesn't know what characters are, only bytes.)seek FILEHANDLE, OFFSET, WHENCE
FILEHANDLE can be an expression whose value gives either the name of the actual filehandle or a reference to anything resembling a filehandle object. The function returns true upon success, false otherwise. For handiness, the function can calculate offsets from various file positions for you. The value of WHENCE specifies which file position your OFFSET uses for its starting point: 0, the beginning of the file; 1, the current position in the file; or 2, the end of the file. The OFFSET can be negative for a WHENCE of 1 or 2. If you'd like to use symbolic values for WHENCE, you may use SEEK_SET, SEEK_CUR, and SEEK_END from either the IO::Seekable or the POSIX module, or as of the 5.6 release of Perl, the Fcntl module.
If you want to position the file for sysread or syswrite, don't use seek; standard I/O buffering makes its effect on the file's system position unpredictable and nonportable. Use sysseek instead.
Due to the rules and rigors of ANSI C, on some systems you have to do a seek whenever you switch between reading and writing. Amongst other things, this may have the effect of calling the standard I/O library's clearerr(3) function. A WHENCE of 1 (SEEK_CUR) with an OFFSET 0 is useful for not moving the file position:
One interesting use for this function is to allow you to follow growing files, like this:seek(TEST,0,1);
for (;;) {
while (<LOG>) {
grok($_); # Process current line.
}
sleep 15;
seek LOG,0,1; # Reset end-of-file error.
}
The final seek clears the end-of-file error without
moving the pointer. Depending on how standard your C library's
standard I/O implementation happens to be, you may need something more
like this:
for (;;) {
for ($curpos = tell FILE; <FILE>; $curpos = tell FILE) {
grok($_); # Process current line.
}
sleep $for_a_while;
seek FILE, $curpos, 0; # Reset end-of-file error.
}
Similar strategies can be used to remember the seek addresses of
each line in an array.
29.2.139. seekdir
This function sets the current position for the next call to readdir on DIRHANDLE. POS must be a value returned by telldir. This function has the same caveats about possible directory compaction as the corresponding system library routine. The function may not be implemented everywhere that readdir is. It's certainly not implemented where readdir isn't.seekdir DIRHANDLE, POS
29.2.140. select (output filehandle)
For historical reasons, there are two select operators that are totally unrelated to each other. See the next section for the other one. This version of the select operator returns the currently selected output filehandle and, if FILEHANDLE is supplied, sets the current default filehandle for output. This has two effects: first, a write or a print without a filehandle will default to this FILEHANDLE. Second, special variables related to output will refer to this output filehandle. For example, if you have to set the same top-of-form format for more than one output filehandle, you might do the following:select FILEHANDLE select
But note that this leaves REPORT2 as the currently selected filehandle. This could be construed as antisocial, since it could really foul up some other routine's print or write statements. Properly written library routines leave the currently selected filehandle the same on exit as it was upon entry. To support this, FILEHANDLE may be an expression whose value gives the name of the actual filehandle. Thus, you can save and restore the currently selected filehandle like this:select REPORT1; $^ = 'MyTop'; select REPORT2; $^ = 'MyTop';
or idiomatically but somewhat obscurely like this:my $oldfh = select STDERR; $| = 1; select $oldfh;
This example works by building a list consisting of the returned value from select(STDERR) (which selects STDERR as a side effect) and $| = 1 (which is always 1), but sets autoflushing on the now-selected STDERR as a side effect. The first element of that list (the previously selected filehandle) is now used as an argument to the outer select. Bizarre, right? That's what you get for knowing just enough Lisp to be dangerous.select((select(STDERR), $| = 1)[0])
You can also use the standard SelectSaver module to automatically restore the previous select upon scope exit.
However, now that we've explained all that, we should point out that you rarely need to use this form of select nowadays, because most of the special variables you would want to set have object-oriented wrapper methods to do it for you. So instead of setting $| directly, you might say:
And the earlier format example might be coded as:use IO::Handle; # Unfortunately, this is *not* a small module. STDOUT->autoflush(1);
use IO::Handle;
REPORT1->format_top_name("MyTop");
REPORT2->format_top_name("MyTop");
29.2.141. select (ready file descriptors)
The four-argument select operator is totally unrelated to the previously described select operator. This operator is used to discover which (if any) of your file descriptors are ready to do input or output, or to report an exceptional condition. (This helps you avoid having to do polling.) It calls the select(2) syscall with the bit masks you've specified, which you can construct using fileno and vec, like this:select RBITS, WBITS, EBITS, TIMEOUT
If you want to select on many filehandles, you might wish to write a subroutine:$rin = $win = $ein = ""; vec($rin, fileno(STDIN), 1) = 1; vec($win, fileno(STDOUT), 1) = 1; $ein = $rin | $win;
sub fhbits {
my @fhlist = @_;
my $bits;
for (@fhlist) {
vec($bits, fileno($_), 1) = 1;
}
return $bits;
}
$rin = fhbits(qw(STDIN TTY MYSOCK));
If you wish to use the same bit masks repeatedly (and it's more efficient
if you do), the usual idiom is:
($nfound, $timeleft) =
select($rout=$rin, $wout=$win, $eout=$ein, $timeout);
Or to block until any file descriptor becomes ready:
As you can see, calling select in scalar context just returns $nfound, the number of ready descriptors found.$nfound = select($rout=$rin, $wout=$win, $eout=$ein, undef);
The $wout=$win trick works because the value of an assignment is its left side, so $wout gets clobbered first by the assignment and then by the select, while $win remains unchanged.
Any of the arguments can also be undef, in which case they're ignored. The TIMEOUT, if not undef, is in seconds, which may be fractional. (A timeout of 0 effects a poll.) Not many implementations are capable of returning $timeleft. If not, they always return $timeleft equal to the supplied $timeout.
The standard IO::Select module provides a more user-friendly interface to select, mostly because it does all the bit mask work for you.
One use for select is to sleep with a finer resolution than sleep allows. To do this, specify undef for all the bitmasks. So, to sleep for (at least) 4.75 seconds, use:
(On some non-Unix systems the triple undef may not work, and you may need to fake up at least one bitmask for a valid descriptor that won't ever be ready.)select undef, undef, undef, 4.75;
One should probably not attempt to mix buffered I/O (like read or <HANDLE>) with select, except as permitted by POSIX, and even then only on truly POSIX systems. Use sysread instead.
29.2.142. semctl
This function calls the System V IPC function semctl(2). You'll probably have to say useIPC::SysV first to get the correct constant definitions. If CMD is IPC_STAT or GETALL, then ARG must be a variable that will hold the returned semid_ds structure or semaphore value array. As with ioctl and fcntl, return values are undef for error, "0 but true" for zero, and the actual return value otherwise.semctl ID, SEMNUM, CMD, ARG
See also the IPC::Semaphore module. This function is available only on machines supporting System V IPC.
29.2.143. semget
This function calls the System V IPC syscall semget(2). Before calling, you should useIPC::SysV to get the correct constant definitions. The function returns the semaphore ID, or undef if there is an error.semget KEY, NSEMS, SIZE, FLAGS
See also the IPC::Semaphore module. This function is available only on machines supporting System V IPC.
29.2.144. semop
This function calls the System V IPC syscall semop(2) to perform semaphore operations such as signalling and waiting. Before calling, you should useIPC::SysV to get the correct constant definitions.semop KEY, OPSTRING
OPSTRING must be a packed array of semop structures. You can make each semop structure by saying pack("s*", $semnum, $semop, $semflag). The number of semaphore operations is implied by the length of OPSTRING. The function returns true if successful, or false if there is an error.
The following code waits on semaphore $semnum of semaphore id $semid:
To signal the semaphore, simply replace -1 with 1.$semop = pack "s*", $semnum, -1, 0; semop $semid, $semop or die "Semaphore trouble: $!\n";
See the section "System V IPC" in Chapter 16, "Interprocess Communication". See also the IPC::Semaphore module. This function is available only on machines supporting System V IPC.
29.2.145. send
This function sends a message on a socket. It takes the same flags as the syscall of the same name--see send(2). On unconnected sockets, you must specify a destination to send TO, which then makes Perl's send work like sendto(2). The C syscall sendmsg(2) is currently unimplemented in standard Perl. The send function returns the number of bytes sent, or undef if there is an error.send SOCKET, MSG, FLAGS, TO send SOCKET, MSG, FLAGS
(Some non-Unix systems improperly treat sockets as different from ordinary file descriptors, with the result that you must always use send and recv on sockets rather than the handier standard I/O operators.)
One error that at least one of us makes frequently is to confuse Perl's send with C's send and write:
This will mysteriously fail depending on the relationship of the string length to the FLAGS bits expected by the system. See the section "Message Passing" in Chapter 16, "Interprocess Communication" for examples.send SOCK, $buffer, length $buffer # WRONG
29.2.146. setpgrp
This function sets the current process group (PGRP) for the specified PID (use a PID of 0 for the current process). Invoking setpgrp will raise an exception if used on a machine that doesn't implement setpgrp(2). Beware: some systems will ignore the arguments you provide and always do setpgrp(0, $$). Fortunately, those are the arguments one usually wants to provide. If the arguments are omitted, they default to 0,0. The BSD 4.2 version of setpgrp did not accept any arguments, but in BSD 4.4, it is a synonym for the setpgid function. For better portability (by some definition), use the setpgid function in the POSIX module directly. If what you're really trying to do is daemonize your script, consider the POSIX::setsid() function as well. Note that the POSIX version of setpgrp does not accept arguments, so only setpgrp(0,0) is truly portable.setpgrp PID, PGRP
29.2.147. setpriority
This function sets the current PRIORITY for a process, a process group, or a user, as specified by the WHICH and WHO. See setpriority(2). Invoking setpriority will raise an exception if used on a machine that doesn't implement setpriority(2). To "nice" your process down by four units (the same as executing your program with nice(1)), try:setpriority WHICH, WHO, PRIORITY
The interpretation of a given priority may vary from one operating system to the next. Some priorities may be unavailable to nonprivileged users.setpriority 0, 0, getpriority(0, 0) + 4;
See also the BSD::Resource module from CPAN.
29.2.148. setsockopt
This function sets the socket option requested. The function returns undef on error. LEVEL specifies which protocol layer you're aiming the call at, or SOL_SOCKET for the socket itself at the top of all the layers. OPTVAL may be specified as undef if you don't want to pass an argument. A common option to set on a socket is SO_REUSEADDR, to get around the problem of not being able to bind to a particular address while the previous TCP connection on that port is still making up its mind to shut down. That would look like this:setsockopt SOCKET, LEVEL, OPTNAME, OPTVAL
use Socket;
socket(SOCK, ...) or die "Can't make socket: $!\n";
setsockopt(SOCK, SOL_SOCKET, SO_REUSEADDR, 1)
or warn "Can't do setsockopt: $!\n";
See setsockopt(2) for other possible values.
29.2.149. shift
This function shifts the first value of the array off and returns it, shortening the array by one and moving everything down. (Or up, or left, depending on how you visualize the array list. We like left.) If there are no elements in the array, the function returns undef.shift ARRAY shift
If ARRAY is omitted, the function shifts @_ within the lexical scope of subroutines and formats; it shifts @ARGV at file scopes (typically the main program) or within the lexical scopes established by the evalSTRING, BEGIN {}, CHECK {}, INIT {}, and END {} constructs.
Subroutines often start by copying their arguments into lexical variables, and shift can be used for this:
sub marine {
my $fathoms = shift; # depth
my $fishies = shift; # number of fish
my $o2 = shift; # oxygen concentration
# ...
}
shift is also used to process arguments at the front of your program:
while (defined($_ = shift)) {
/^[^-]/ && do { unshift @ARGV, $_; last };
/^-w/ && do { $WARN = 1; next };
/^-r/ && do { $RECURSE = 1; next };
die "Unknown argument $_\n";
}
You might also consider the Getopt::Std and Getopt::Long
modules for processing program arguments.
See also unshift, push, pop, and splice. The shift and unshift functions do the same thing to the left end of an array that pop and push do to the right end.
29.2.150. shmctl
This function calls the System V IPC syscall, shmctl(2). Before calling, you should useIPC::SysV to get the correct constant definitions.shmctl ID, CMD, ARG
If CMD is IPC_STAT, then ARG must be a variable that will hold the returned shmid_ds structure. Like ioctl and fcntl, the function returns undef for error, "0 but true" for zero, and the actual return value otherwise.
This function is available only on machines supporting System V IPC.
29.2.151. shmget
This function calls the System V IPC syscall, shmget(2). The function returns the shared memory segment ID, or undef if there is an error. Before calling, useSysV::IPC.shmget KEY, SIZE, FLAGS
This function is available only on machines supporting System V IPC.
29.2.152. shmread
This function reads from the shared memory segment ID starting at position POS for size SIZE (by attaching to it, copying out, and detaching from it). VAR must be a variable that will hold the data read. The function returns true if successful, or false if there is an error.shmread ID, VAR, POS, SIZE
This function is available only on machines supporting System V IPC.
29.2.153. shmwrite
This function writes to the shared memory segment ID starting at position POS for size SIZE (by attaching to it, copying in, and detaching from it). If STRING is too long, only SIZE bytes are used; if STRING is too short, nulls are written to fill out SIZE bytes. The function returns true if successful, or false if there is an error.shmwrite ID, STRING, POS, SIZE
This function is available only on machines supporting System V IPC. (You're probably tired of reading that--we're getting tired of saying it.)
29.2.154. shutdown
This function shuts down a socket connection in the manner indicated by HOW. If HOW is 0, further receives are disallowed. If HOW is 1, further sends are disallowed. If HOW is 2, everything is disallowed.shutdown SOCKET, HOW
This is useful with sockets when you want to tell the other side you're done writing but not done reading, or vice versa. It's also a more insistent form of close because it also disables any copies of those file descriptors held in forked processes.shutdown(SOCK, 0); # no more reading shutdown(SOCK, 1); # no more writing shutdown(SOCK, 2); # no more I/O at all
Imagine a server that wants to read its client's request until end of file, then send an answer. If the client calls close, that socket is now invalid for I/O, so no answer would ever come back. Instead, the client should use shutdown to half-close the connection:
(If you came here trying to figure out how to shut down your system, you'll have to execute an external program to do that. See system.)print SERVER "my request\n"; # send some data shutdown(SERVER, 1); # send eof; no more writing $answer = <SERVER>; # but you can still read
29.2.155. sin
Sorry, there's nothing wicked about this operator. It merely returns the sine of EXPR (expressed in radians).sin EXPR sin
For the inverse sine operation, you may use Math::Trig or the POSIX module's asin function, or use this relation:
sub asin { atan2($_[0], sqrt(1 - $_[0] * $_[0])) }
29.2.156. sleep
This function causes the script to sleep for EXPR seconds, or forever if no EXPR, and returns the number of seconds slept. It may be interrupted by sending the process a SIGALRM. On some older systems, it may sleep up to a full second less than what you requested, depending on how it counts seconds. Most modern systems always sleep the full amount. They may appear to sleep longer than that, however, because your process might not be scheduled right away in a busy multitasking system. If available, the select (ready file descriptors) call can give you better resolution. You may also be able to use syscall to call the getitimer(2) and setitimer(2) routines that some Unix systems support. You probably cannot mix alarm and sleep calls, because sleep is often implemented using alarm.sleep EXPR sleep
See also the POSIX module's sigpause function.
29.2.157. socket
This function opens a socket of the specified kind and attaches it to filehandle SOCKET. DOMAIN, TYPE, and PROTOCOL are specified the same as for socket(2). If undefined, SOCKET will be autovivified. Before using this function, your program should contain the line:socket SOCKET, DOMAIN, TYPE, PROTOCOL
This gives you the proper constants. The function returns true if successful. See the examples in the section "Sockets" in Chapter 16, "Interprocess Communication".use Socket;
On systems that support a close-on-exec flag on files, the flag will be set for the newly opened file descriptor, as determined by the value of $^F. See the $^F ($SYSTEM_FD_MAX) variable in Chapter 28, "Special Names".
29.2.158. socketpair
This function creates an unnamed pair of sockets in the specified domain, of the specified type. DOMAIN, TYPE, and PROTOCOL are specified the same as for socketpair(2). If either socket argument is undefined, it will be autovivified. The function returns true if successful, false otherwise. On a system where socketpair(2) is unimplemented, calling this function raises an exception.socketpair SOCKET1, SOCKET2, DOMAIN, TYPE, PROTOCOL
This function is typically used just before a fork. One of the resulting processes should close SOCKET1, and the other should close SOCKET2. You can use these sockets bidirectionally, unlike the filehandles created by the pipe function. Some systems define pipe in terms of socketpair, in which a call to pipe(Rdr, Wtr) is essentially:
On systems that support a close-on-exec flag on files, the flag will be set for the newly opened file descriptors, as determined by the value of $^F. See the $^F ($SYSTEM_FD_MAX) variable in Chapter 28, "Special Names". See also the example at the end of the section "Bidirectional Communication" in Chapter 16, "Interprocess Communication".use Socket; socketpair(Rdr, Wtr, AF_UNIX, SOCK_STREAM, PF_UNSPEC); shutdown(Rdr, 1); # no more writing for reader shutdown(Wtr, 0); # no more reading for writer
29.2.159. sort
This function sorts the LIST and returns the sorted list value. By default, it sorts in standard string comparison order (undefined values sort before defined null strings, which sort before everything else). When the use locale pragma is in effect, sortLIST sorts LIST according to the current collation locale.sort USERSUB LIST sort BLOCK LIST sort LIST
USERSUB, if given, is the name of a subroutine that returns an integer less than, equal to, or greater than 0, depending on how the elements of the list are to be ordered. (The handy <=> and cmp operators can be used to perform three-way numeric and string comparisons.) If a USERSUB is given but that function is undefined, sort raises an exception.
In the interests of efficiency, the normal calling code for subroutines is bypassed, with the following effects: the subroutine may not be a recursive subroutine (nor may you exit the block or routine with a loop control operator), and the two elements to be compared are not passed into the subroutine via @_, but rather by temporarily setting the global variables $a and $b in the package in which the sort was compiled (see the examples that follow). The variables $a and $b are aliases to the real values, so don't modify them in the subroutine.
The comparison subroutine is required to behave. If it returns inconsistent results (sometimes saying $x[1] is less than $x[2] and sometimes saying the opposite, for example), the results are not well defined. (That's another reason you shouldn't modify $a and $b.)
USERSUB may be a scalar variable name (unsubscripted), in which case the value provides either a symbolic or a hard reference to the actual subroutine to use. (A symbolic name rather than a hard reference is allowed even when the use strict 'refs' pragma is in effect.) In place of a USERSUB, you can provide a BLOCK as an anonymous, inline sort subroutine.
To do an ordinary numeric sort, say this:
sub numerically { $a <=> $b }
@sortedbynumber = sort numerically 53,29,11,32,7;
To sort in descending order, you could simply apply
reverse after the sort, or you
could reverse the order of $a and
$b in the sort routine:
@descending = reverse sort numerically 53,29,11,32,7;
sub reverse_numerically { $b <=> $a }
@descending = sort reverse_numerically 53,29,11,32,7;
To sort strings without regard to case, run $a and $b
through lc before comparing:
@unsorted = qw/sparrow Ostrich LARK catbird blueJAY/;
@sorted = sort { lc($a) cmp lc($b) } @unsorted;
(Under Unicode, the use of lc for case canonicalization is vaguely
preferred to the use of uc, since some languages differentiate
titlecase from uppercase. But that doesn't matter for basic ASCII
sorting, and if you're going to do Unicode sorting right, your
canonicalization routines are going to be a lot fancier than lc.)
Sorting hashes by value is a common use of the sort function. For example, if a %sales_amount hash records department sales, doing a hash lookup in the sort routine allows the hash keys to be sorted according to their corresponding values:
# sort from highest to lowest department sales
sub bysales { $sales_amount{$b} <=> $sales_amount{$a} }
for $dept (sort bysales keys %sale_amount) {
print "$dept => $sales_amount{$dept}\n";
}
You can perform additional levels of sorting by cascading multiple
comparisons using the || or or
operators. This works nicely because the comparison operators
conveniently return 0 for equivalence, causing them
to fall through to the next comparison. Here, the hash keys are
sorted first by their associated sales amounts and then by the keys
themselves (in case two or more departments have the same sales
amount):
sub by_sales_then_dept {
$sales_amount{$b} <=> $sales_amount{$a}
||
$a cmp $b
}
for $dept (sort by_sales_then_dept keys %sale_amount) {
print "$dept => $sales_amount{$dept}\n";
}
Assume that @recs is an array of hash references, where each hash
contains fields such as FIRSTNAME, LASTNAME, AGE, HEIGHT, and
SALARY. The following routine sorts to the front of the list those records
for people who are first richer, then taller, then younger, then less
alphabetically challenged:
sub prospects {
$b->{SALARY} <=> $a->{SALARY}
||
$b->{HEIGHT} <=> $a->{HEIGHT}
||
$a->{AGE} <=> $b->{AGE}
||
$a->{LASTNAME} cmp $b->{LASTNAME}
||
$a->{FIRSTNAME} cmp $b->{FIRSTNAME}
}
@sorted = sort prospects @recs;
Any useful information that can be derived from $a and $b
can serve as the basis of a comparison in a sort routine. For
example, if lines of text are to be sorted according to
specific fields, split could be used within the sort routine
to derive the fields.
@sorted_lines = sort {
@a_fields = split /:/, $a; # colon-separated fields
@b_fields = split /:/, $b;
$a_fields[3] <=> $b_fields[3] # numeric sort on 4th field, then
||
$a_fields[0] cmp $b_fields[0] # string sort on 1st field, then
||
$b_fields[2] <=> $a_fields[2] # reverse numeric sort on 3rd field
||
... # etc.
} @lines;
However, because sort performs the sort routine many times using
different pairings of values for $a and $b, the previous
example will resplit each line more often than needed.
To avoid the expense of repeated derivations such as the splitting of lines in order to compare their fields, perform the derivation once per value prior to the sort and save the derived information. Here, anonymous arrays are created to encapsulate each line along with the results of splitting the line:
@temp = map { [$_, split /:/] } @lines;
Next, the array references are sorted:
@temp = sort {
@a_fields = @$a[1..$#$a];
@b_fields = @$b[1..$#$b];
$a_fields[3] <=> $b_fields[3] # numeric sort on 4th field, then
||
$a_fields[0] cmp $b_fields[0] # string sort on 1st field, then
||
$b_fields[2] <=> $a_fields[2] # reverse numeric sort on 3rd field
||
... # etc.
} @temp;
Now that the array references are sorted, the original lines
can be retrieved from the anonymous arrays:
@sorted_lines = map { $_->[0] } @temp;
Putting it all together, this map-sort-map technique, often
referred to as the Schwartzian Transform, can be performed in one statement:
@sorted_lines = map { $_->[0] }
sort {
@a_fields = @$a[1..$#$a];
@b_fields = @$b[1..$#$b];
$a_fields[3] <=> $b_fields[3]
||
$a_fields[0] cmp $b_fields[0]
||
$b_fields[2] <=> $a_fields[2]
||
...
}
map { [$_, split /:/] } @lines;
Do not declare $a and $b as lexical variables (with my). They
are package globals (though they're exempt from the usual restrictions
on globals when you're using use strict). You do need to make sure
your sort routine is in the same package though, or else qualify $a and
$b with the package name of the caller.
That being said, in version 5.6 you can write sort subroutines with the standard argument passing method (and, not coincidentally, use XS subroutines as sort subroutines), provided that you declare the sort subroutine with a prototype of ($$). And if you do that, then you can in fact declare $a and $b as lexicals:
sub numerically ($$) {
my ($a, $b) = @_;
$a <=> $b;
}
And someday, when full prototypes are implemented, you'll just say:
sub numerically ($a, $b) { $a <=> $b }
and then we'll be back where we started, more or less.
29.2.160. splice
This function removes the elements designated by OFFSET and LENGTH from an ARRAY, and replaces them with the elements of LIST, if any. If OFFSET is negative, the function counts backward from the end of the array, but if that would land before the beginning of the array, an exception is raised. In list context, splice returns the elements removed from the array. In scalar context, it returns the last element removed, or undef if there was none. If the number of new elements doesn't equal the number of old elements, the array grows or shrinks as necessary, and elements after the splice change their position correspondingly. If LENGTH is omitted, the function removes everything from OFFSET onward. If OFFSET is omitted, the array is cleared as it is read. The following equivalences hold (assuming $[ is 0):splice ARRAY, OFFSET, LENGTH, LIST splice ARRAY, OFFSET, LENGTH splice ARRAY, OFFSET splice ARRAY
| Direct Method | Splice Equivalent |
|---|---|
| push(@a, $x, $y) | splice(@a, @a, 0, $x, $y) |
| pop(@a) | splice(@a, -1) |
| shift(@a) | splice(@a, 0, 1) |
| unshift(@a, $x, $y) | splice(@a, 0, 0, $x, $y) |
| $a[$x] = $y | splice(@a, $x, 1, $y) |
| (@a, @a = ()) | splice(@a) |
The splice function is also handy for carving up the argument list passed to a subroutine. For example, assuming list lengths are passed before lists:
sub list_eq { # compare two list values
my @a = splice(@_, 0, shift);
my @b = splice(@_, 0, shift);
return 0 unless @a == @b; # same length?
while (@a) {
return 0 if pop(@a) ne pop(@b);
}
return 1;
}
if (list_eq($len, @foo[1..$len], scalar(@bar), @bar)) { ... }
It would be cleaner to use array references for this, however.
29.2.161. split [taintgray]
This function scans a string given by EXPR for separators, and splits the string into a list of substrings, returning the resulting list value in list context or the count of substrings in scalar context.[11] The separators are determined by repeated pattern matching, using the regular expression given in PATTERN, so the separators may be of any size and need not be the same string on every match. (The separators are not ordinarily returned; exceptions are discussed later in this section.) If the PATTERN doesn't match the string at all, split returns the original string as a single substring. If it matches once, you get two substrings, and so on. You may supply regular expression modifiers to the PATTERN, like /PATTERN/i, /PATTERN/x, etc. The //m modifier is assumed when you split on the pattern /^/.split /PATTERN/, EXPR, LIMIT split /PATTERN/, EXPR split /PATTERN/ split
[11]Scalar context also causes split to write its result to @_, but this usage is deprecated.
If LIMIT is specified and positive, the function splits into no more than that many fields (though it may split into fewer if it runs out of separators). If LIMIT is negative, it is treated as if an arbitrarily large LIMIT has been specified. If LIMIT is omitted or zero, trailing null fields are stripped from the result (which potential users of pop would do well to remember). If EXPR is omitted, the function splits the $_ string. If PATTERN is also omitted or is the literal space, " ", the function splits on whitespace, /\s+/, after skipping any leading whitespace.
Strings of any length can be split:
A pattern capable of matching either the null string or something longer than the null string (for instance, a pattern consisting of any single character modified by a * or ?) will split the value of EXPR into separate characters wherever it matches the null string between characters; non-null matches will skip over the matched separator characters in the usual fashion. (In other words, a pattern won't match in one spot more than once, even if it matched with a zero width.) For example:@chars = split //, $word; @fields = split /:/, $line; @words = split " ", $paragraph; @lines = split /^/, $buffer;
produces the output "h:i:t:h:e:r:e". The space disappears because it matches as part of the separator. As a trivial case, the null pattern // simply splits into separate characters, and spaces do not disappear. (For normal pattern matches, a // pattern would repeat the last successfully matched pattern, but split's pattern is exempt from that wrinkle.)print join ':', split / */, 'hi there';
The LIMIT parameter splits only part of a string:
We encourage you to split to lists of names like this in order to make your code self-documenting. (For purposes of error checking, note that $remainder would be undefined if there were fewer than three fields.) When assigning to a list, if LIMIT is omitted, Perl supplies a LIMIT one larger than the number of variables in the list, to avoid unnecessary work. For the split above, LIMIT would have been 4 by default, and $remainder would have received only the third field, not all the rest of the fields. In time-critical applications, it behooves you not to split into more fields than you really need. (The trouble with powerful languages is that they let you be powerfully stupid at times.)($login, $passwd, $remainder) = split /:/, $_, 3;
We said earlier that the separators are not returned, but if the PATTERN contains parentheses, then the substring matched by each pair of parentheses is included in the resulting list, interspersed with the fields that are ordinarily returned. Here's a simple example:
produces the list value:split /([-,])/, "1-10,20";
With more parentheses, a field is returned for each pair, even if some pairs don't match, in which case undefined values are returned in those positions. So if you say:(1, '-', 10, ',', 20)
you get the value:split /(-)|(,)/, "1-10,20";
The /PATTERN/ argument may be replaced with an expression to specify patterns that vary at run time. As with ordinary patterns, to do run-time compilation only once, use /$variable/o.(1, '-', undef, 10, undef, ',', 20)
As a special case, if the expression is a single space (" "), the function splits on whitespace just as split with no arguments does. Thus, split(" ") can be used to emulate awk's default behavior. In contrast, split(/ /) will give you as many null initial fields as there are leading spaces. (Other than this special case, if you supply a string instead of a regular expression, it'll be interpreted as a regular expression anyway.) You can use this property to remove leading and trailing whitespace from a string and to collapse intervening stretches of whitespace into a single space:
$string = join(' ', split(' ', $string));
The following example splits an RFC 822 message header into a hash
containing $head{Date}, $head{Subject}, and so on. It uses the
trick of assigning a list of pairs to a hash, based on the fact that
separators alternate with separated fields. It makes use of parentheses
to return part of each separator as part of the returned list value.
Since the split pattern is guaranteed to return things in pairs by
virtue of containing one set of parentheses, the hash assignment is
guaranteed to receive a list consisting of key/value pairs, where each
key is the name of a header field. (Unfortunately, this technique loses
information for multiple lines with the same key field, such as
Received-By lines. Ah, well. . . .)
$header =~ s/\n\s+/ /g; # Merge continuation lines.
%head = ('FRONTSTUFF', split /^(\S*?):\s*/m, $header);
The following example processes the entries in a Unix passwd(5) file.
You could leave out the chomp, in which case $shell would have a
newline on the end of it.
open PASSWD, '/etc/passwd';
while (<PASSWD>) {
chomp; # remove trailing newline
($login, $passwd, $uid, $gid, $gcos, $home, $shell) =
split /:/;
...
}
Here's how to process each word of each line of each file
of input to create a word-frequency hash.
while (<>) {
foreach $word (split) {
$count{$word}++;
}
}
The inverse of split is performed by join (except that join can
only join with the same separator between all fields). To break apart a
string with fixed-position fields, use unpack.
29.2.162. sprintf
This function returns a string formatted by the usual printf conventions of the C library function sprintf. See sprintf(3) or printf(3) on your system for an explanation of the general principles. The FORMAT string contains text with embedded field specifiers into which the elements of LIST are substituted, one per field.sprintf FORMAT, LIST
Perl does its own sprintf formatting--it emulates the C function sprintf, but it doesn't use it.[12] As a result, any nonstandard extensions in your local sprintf(3) function are not available from Perl.
[12]Except for floating-point numbers, and even then only the standard modifiers are allowed.
Perl's sprintf permits the universally known conversions shown in Table 29-4.
Table 29.4. Formats for sprintf
| Field | Meaning |
|---|---|
| %% |
A percent sign |
| %c |
A character with the given number |
| %s |
A string |
| %d |
A signed integer, in decimal |
| %u |
An unsigned integer, in decimal |
| %o |
An unsigned integer, in octal |
| %x |
An unsigned integer, in hexadecimal |
| %e |
A floating-point number, in scientific notation |
| %f | A floating-point number, in fixed decimal notation |
| %g |
A floating-point number, in %e or %f notation |
In addition, Perl permits the following widely supported conversions:
| Field | Meaning |
|---|---|
| %X |
Like %x, but using uppercase letters |
| %E |
Like %e, but using an uppercase "E" |
| %G |
Like %g, but with an uppercase "E" (if applicable) |
| %b |
An unsigned integer, in binary |
| %p | A pointer (outputs the Perl value's address in hexadecimal) |
| %n |
Special: stores the number of characters output so far into the next variable in the argument list |
Finally, for backward (and we do mean "backward") compatibility, Perl permits these unnecessary but widely supported conversions:
| Field | Meaning |
|---|---|
| %i |
A synonym for %d |
| %D |
A synonym for %ld |
| %U |
A synonym for %lu |
| %O |
A synonym for %lo |
| %F |
A synonym for %f |
Perl permits the following universally known flags between the % and the conversion character:
There are also two Perl-specific flags:
If your Perl understands "quads" (64-bit integers) either because the platform natively supports them or because Perl has been specifically compiled with that ability, then the characters d u o x X b i D U O print quads, and they may optionally be preceded by ll, L, or q. For example, %lld %16LX %qo.
If Perl understands "long doubles" (this requires that the platform support long doubles), the flags e f g E F G may optionally be preceded by ll or L. For example, %llf %Lg.
Where a number would appear in the flags, an asterisk ("*") may be used instead, in which case Perl uses the next item in the argument list as the given number (that is, as the field width or precision). If a field width obtained through "*" is negative, it has the same effect as the "-" flag: left-justification.
The v flag is useful for displaying ordinal values of characters in arbitrary strings:
sprintf "version is v%vd\n", $^V; # Perl's version sprintf "address is %vd\n", $addr; # IPv4 address sprintf "address is %*vX\n", ":", $addr; # IPv6 address sprintf "bits are %*vb\n", " ", $bits; # random bit strings
29.2.163. sqrt
This function returns the square root of EXPR. For other roots such as cube roots, you can use the ** operator to raise something to a fractional power. Don't try either of these approaches with negative numbers, as that poses a slightly more complex problem (and raises an exception). But there's a standard module to take care of even that:sqrt EXPR sqrt
use Math::Complex; print sqrt(-2); # prints 1.4142135623731i
29.2.164. srand
This function sets the random number seed for the rand operator. If EXPR is omitted, it uses a semirandom value supplied by the kernel (if it supports the /dev/urandom device) or based on the current time and process ID, among other things. It's usually not necessary to call srand at all, because if it is not called explicitly, it is called implicitly at the first use of the rand operator. However, this was not true in versions of Perl prior to 5.004, so if your script needs to run under older Perl versions, it should call srand.srand EXPR srand
Frequently called programs (like CGI scripts) that simply use time ^ $$ for a seed can fall prey to the mathematical property that a^b == (a+1)^(b+1) one-third of the time. So don't do that. Use this instead:
You'll need something much more random than the default seed for cryptographic purposes. On some systems the /dev/random device is suitable. Otherwise, checksumming the compressed output of one or more rapidly changing operating system status programs is the usual method. For example:srand( time() ^ ($$ + ($$ << 15)) );
If you're particularly concerned with this, see the Math::TrulyRandom module in CPAN.srand (time ^ $$ ^ unpack "%32L*", `ps wwaxl | gzip`);
Do not call srand multiple times in your program unless you know exactly what you're doing and why you're doing it. The point of the function is to "seed" the rand function so that rand can produce a different sequence each time you run your program. Just do it once at the top of your program, or you won't get random numbers out of rand!
29.2.165. stat
In scalar context, this function returns a Boolean value that indicates whether the call succeeded. In list context, it returns a 13-element list giving the statistics for a file, either the file opened via FILEHANDLE, or named by EXPR. It's typically used as follows:stat FILEHANDLE stat EXPR stat
($dev,$ino,$mode,$nlink,$uid,$gid,$rdev,$size,
$atime,$mtime,$ctime,$blksize,$blocks)
= stat $filename;
Not all fields are supported on all filesystem types; unsupported
fields return 0. Table 29-5 lists the
meanings of the fields.
Table 29.5. Fields Returned by stat
| Index | Field | Meaning |
|---|---|---|
| 0 | $dev | Device number of filesystem |
| 1 | $ino | Inode number |
| 2 | $mode | File mode (type and permissions) |
| 3 | $nlink | Number of (hard) links to the file |
| 4 | $uid | Numeric user ID of file's owner |
| 5 | $gid | Numeric group ID of file's designated group |
| 6 | $rdev | The device identifier (special files only) |
| 7 | $size | Total size of file, in bytes |
| 8 | $atime | Last access time in seconds since the epoch |
| 9 | $mtime | Last modify time in seconds since the epoch |
| 10 | $ctime | Inode change time (not creation time!) in seconds since the epoch |
| 11 | $blksize | Preferred blocksize for file system I/O |
| 12 | $blocks | Actual number of blocks allocated |
$dev and $ino, taken together, uniquely identify a file on the same system. The $blksize and $blocks are likely defined only on BSD-derived filesystems. The $blocks field (if defined) is reported in 512-byte blocks. The value of $blocks*512 can differ greatly from $size for files containing unallocated blocks, or "holes", which aren't counted in $blocks.
If stat is passed the special filehandle consisting of an underline, no actual stat(2) is done, but the current contents of the stat structure from the last stat, lstat, or stat-based file test operator (such as -r, -w, and -x) are returned.
Because the mode contains both the file type and its permissions, you should mask off the file type portion and printf or sprintf using a "%o" if you want to see the real permissions:
The File::stat module provides a convenient, by-name access mechanism:$mode = (stat($filename))[2]; printf "Permissions are %04o\n", $mode & 07777;
You can also import symbolic definitions of the various mode bits from the Fcntl module. See the online documentation for more details.use File::stat; $sb = stat($filename); printf "File is %s, size is %s, perm %04o, mtime %s\n", $filename, $sb->size, $sb->mode & 07777, scalar localtime $sb->mtime;
Hint: if you need only the size of the file, check out the -s file test operator, which returns the size in bytes directly. There are also file tests that return the ages of files in days.
29.2.166. study
This function takes extra time in order to study SCALAR in anticipation of doing many pattern matches on the string before it is next modified. This may or may not save time, depending on the nature and number of patterns you are searching on, and on the distribution of character frequencies in the string to be searched--you probably want to compare run times with and without it to see which runs faster. Those loops that scan for many short constant strings (including the constant parts of more complex patterns) will benefit most from study. If all your pattern matches are constant strings anchored at the front, study won't help at all, because no scanning is done. You may have only one study active at a time--if you study a different scalar the first is "unstudied".study SCALAR study
The way study works is this: a linked list of every character in the string to be searched is made, so we know, for example, where all the "k" characters are. From each search string, the rarest character is selected, based on some static frequency tables constructed from some C programs and English text. Only those places that contain this rarest character are examined.
For example, here is a loop that inserts index-producing entries before any line containing a certain pattern:
while (<>) {
study;
print ".IX foo\n" if /\bfoo\b/;
print ".IX bar\n" if /\bbar\b/;
print ".IX blurfl\n" if /\bblurfl\b/;
...
print;
}
In searching for /\bfoo\b/, only those locations in $_ that
contain "f" will be looked at, because "f" is rarer than "o".
This is a big win except in pathological cases. The only
question is whether it saves you more time than it took to build the
linked list in the first place.
If you have to look for strings that you don't know until run time, you can build an entire loop as a string and eval that to avoid recompiling all your patterns all the time. Together with setting $/ to input entire files as one record, this can be very fast, often faster than specialized programs like fgrep(1). The following scans a list of files (@files) for a list of words (@words), and prints out the names of those files that contain a case-insensitive match:
$search = 'while (<>) { study;';
foreach $word (@words) {
$search .= "++\$seen{\$ARGV} if /\\b$word\\b/i;\n";
}
$search .= "}";
@ARGV = @files;
undef $/; # slurp each entire file
eval $search; # this screams
die $@ if $@; # in case eval failed
$/ = "\n"; # restore normal input terminator
foreach $file (sort keys(%seen)) {
print "$file\n";
}
Now that we have the qr// operator, complicated run-time evals
as seen above are less necessary. This does the same thing:
@pats = ();
foreach $word (@words) {
push @pats, qr/\b${word}\b/i;
}
@ARGV = @files;
undef $/; # slurp each entire file
while (<>) {
for $pat (@pats) {
$seen{$ARGV}++ if /$pat/;
}
}
$/ = "\n"; # restore normal input terminator
foreach $file (sort keys(%seen)) {
print "$file\n";
}
29.2.167. sub
Named declarations:
Named definitions:sub NAME PROTO ATTRS sub NAME ATTRS sub NAME PROTO sub NAME
Unnamed definitions:sub NAME PROTO ATTRS BLOCK sub NAME ATTRS BLOCK sub NAME PROTO BLOCK sub NAME BLOCK
The syntax of subroutine declarations and definitions looks complicated, but is actually pretty simple in practice. Everything is based on the syntax:sub PROTO ATTRS BLOCK sub ATTRS BLOCK sub PROTO BLOCK sub BLOCK
All four fields are optional; the only restrictions are that the fields that do occur must occur in that order, and that you must use at least one of NAME or BLOCK. For the moment, we'll ignore the PROTO and ATTRS; they're just modifiers on the basic syntax. The NAME and the BLOCK are the important parts to get straight:sub NAME PROTO ATTRS BLOCK
-
If you just have a NAME and no BLOCK, it's a declaration of that name (and if you ever want to call the subroutine, you'll have to supply a definition with both a NAME and a BLOCK later). Named declarations are useful because the parser treats a name specially if it knows it's a user-defined subroutine. You can call such a subroutine either as a function or as an operator, just like built-in functions. These are sometimes called forward declarations.
-
If you have both a NAME and a BLOCK, it's a standard named subroutine definition (and a declaration too, if you didn't declare the name previously). Named definitions are useful because the BLOCK associates an actual meaning (the body of the subroutine) with the declaration. That's all we mean when we say it defines the subroutine rather than just declaring it. The definition is like the declaration, however, in that the surrounding code doesn't see it, and it returns no inline value by which you could reference the subroutine.
-
If you have just have a BLOCK without a NAME, it's a nameless definition, that is, an anonymous subroutine. Since it doesn't have a name, it's not a declaration at all, but a real operator that returns a reference to the anonymous subroutine body at run time. This is extremely useful for treating code as data. It allows you to pass odd chunks of code around to be used as callbacks, and maybe even as closures if the sub definition operator refers to any lexical variables outside of itself. That means that different calls to the same sub operator will do the bookkeeping necessary to keep the correct "version" of each such lexical variable in sight for the life of the closure, even if the original scope of the lexical variable has been destroyed.
In any of these three cases, either one or both of the PROTO and ATTRS may occur after the NAME and/or before the BLOCK. A prototype is a list of characters in parentheses that tell the parser how to treat arguments to the function. Attributes are introduced by a colon and supply additional information to the parser about the function. Here's a typical definition that includes all four fields:
sub numstrcmp ($$) : locked {
my ($a, $b) = @_;
return $a <=> $b || $a cmp $b;
}
For details on attribute lists and their manipulation, see the
attributes pragma in Chapter 31, "Pragmatic Modules". See also
Chapter 6, "Subroutines" and "Anonymous Subroutines" in Chapter 8, "References".
29.2.168. substr
This function extracts a substring out of the string given by EXPR and returns it. The substring is extracted starting at OFFSET characters from the front of the string. (Note: if you've messed with $[, the beginning of the string isn't at 0, but since you haven't messed with it (have you?), it is.) If OFFSET is negative, the substring starts that far from the end of the string instead. If LENGTH is omitted, everything to the end of the string is returned. If LENGTH is negative, the length is calculated to leave that many characters off the end of the string. Otherwise, LENGTH indicates the length of the substring to extract, which is sort of what you'd expect.substr EXPR, OFFSET, LENGTH, REPLACEMENT substr EXPR, OFFSET, LENGTH substr EXPR, OFFSET
You may use substr as an lvalue (something to assign to), in which case EXPR must also be a legal lvalue. If you assign something shorter than the length of your substring, the string will shrink, and if you assign something longer than the length, the string will grow to accommodate it. To keep the string the same length, you may need to pad or chop your value using sprintf or the x operator. If you attempt to assign to an unallocated area past the end of the string, substr raises an exception.
To prepend the string "Larry" to the current value of $_, use:
To instead replace the first character of $_ with "Moe", use:substr($var, 0, 0) = "Larry";
And finally, to replace the last character of $var with "Curly", use:substr($var, 0, 1) = "Moe";
An alternative to using substr as an lvalue is to specify the REPLACEMENT string as the fourth argument. This allows you to replace parts of the EXPR and return what was there before in one operation, just as you can with splice. The next example also replaces the last character of $var with "Curly" and puts that replaced character into $oldstr:substr($var, -1) = "Curly";
You don't have to use lvalue substr only with assignment. This replaces any spaces with dots, but only in the last 10 characters in the string:$oldstr = substr($var, -1, 1, "Curly");
substr($var, -10) =~ s/ /./g;
29.2.169. symlink
This function creates a new filename symbolically linked to the old filename. The function returns true for success, false otherwise. On systems that don't support symbolic links, it raises an exception at run time. To check for that, use eval to trap the potential error:symlink OLDNAME, NEWNAME
$can_symlink = eval { symlink("",""); 1 };
Or use the Config module. Be careful if you supply a relative symbolic
link, since it'll be interpreted relative to the location of the
symbolic link itself, not to your current working directory.
See also link and readlink earlier in this chapter.
29.2.170. syscall
This function calls the system call (meaning a syscall, not a shell command) specified as the first element of the list passes the remaining elements as arguments to the system call. (Many of these calls are now more readily available through modules like POSIX.) The function raises an exception if syscall(2) is unimplemented.syscall LIST
The arguments are interpreted as follows: if a given argument is numeric, the argument is passed as a C integer. If not, a pointer to the string value is passed. You are responsible for making sure the string is long enough to receive any result that might be written into it; otherwise, you're looking at a core dump. You can't use a string literal (or other read-only string) as an argument to syscall because Perl has to assume that any string pointer might be written through. If your integer arguments are not literals and have never been interpreted in a numeric context, you may need to add 0 to them to force them to look like numbers.
syscall returns whatever value was returned by the system call invoked. By C coding conventions, if that system call fails, syscall returns -1 and sets $! (errno). Some system calls legitimately return -1 if successful. The proper way to handle such calls is to assign $!=0; before the call and check the value of $! if syscall returns -1.
Not all system calls can be accessed this way. For example, Perl supports passing up to 14 arguments to your system call, which in practice should usually suffice. However, there's a problem with syscalls that return multiple values. Consider syscall(&SYS_pipe): it returns the file number of the read end of the pipe it creates. There is no way to retrieve the file number of the other end. You can avoid this instance of the problem by using pipe instead. To solve the generic problem, write XSUBs (external subroutine modules, a dialect of C) to access the system calls directly. Then put your new module onto CPAN, and become wildly popular.
The following subroutine returns the current time as a floating-point number rather than as integer seconds as time returns. (It will only work on machines that support the gettimeofday(2) syscall.)
sub finetime() {
package main; # for next require
require 'syscall.ph';
# presize buffer to two 32-bit longs...
my $tv = pack("LL", ());
syscall(&SYS_gettimeofday, $tv, undef) >= 0
or die "gettimeofday: $!";
my($seconds, $microseconds) = unpack("LL", $tv);
return $seconds + ($microseconds / 1_000_000);
}
Suppose Perl didn't support the setgroups(2) syscall,[13] but your kernel did. You could
still get at it this way:
require 'syscall.ph';
syscall(&SYS_setgroups, scalar @newgids, pack("i*", @newgids))
or die "setgroups: $!";
You may have to run h2ph as indicated in the Perl installation
instructions for syscall.ph to exist. Some systems may require
a pack template of "II" instead. Even more disturbing,
syscall assumes the size equivalence of the C types int,
long, and char*. Try not to think of syscall as the epitome
of portability.
[13]Although through $(, it does.
See the Time::HiRes module from CPAN for a more rigorous approach to fine-grained timing issues.
29.2.171. sysopen
The sysopen function opens the file whose filename is given by FILENAME and associates it with FILEHANDLE. If FILEHANDLE is an expression, its value is used as the name of, or reference to, the filehandle. If FILEHANDLE is a variable whose value is undefined, a value will be created for you. The return value is true if the call succeeds, false otherwise.sysopen FILEHANDLE, FILENAME, MODE, MASK sysopen FILEHANDLE, FILENAME, MODE
This function is a direct interface to your operating system's open(2) syscall followed by an fdopen(3) library call. As such, you'll need to pretend you're a C programmer for a bit here. The possible values and flag bits of the MODE parameter are available through the Fcntl module. Because different systems support different flags, don't count on all of them being available on your system. Consult your open(2) manpage or its local equivalent for details. Nevertheless, the following flags should be present on any system with a reasonably standard C library:
| Flag | Meaning |
|---|---|
| O_RDONLY |
Read only. |
| O_WRONLY |
Write only. |
| O_RDWR |
Read and write. |
| O_CREAT | Create the file if it doesn't exist. |
| O_EXCL |
Fail if the file already exists. |
| O_APPEND |
Append to the file. |
| O_TRUNC |
Truncate the file. |
| O_NONBLOCK |
Nonblocking access. |
Many other options are possible, however. Here are some less common flags:
| Flag | Meaning |
|---|---|
| O_NDELAY |
Old synonym for O_NONBLOCK. |
| O_SYNC |
Writes block until data is physically written to the underlying hardware. O_ASYNC, O_DSYNC, and O_RSYNC may also be seen. |
| O_EXLOCK |
flock with LOCK_EX (advisory only). |
| O_SHLOCK |
flock with LOCK_SH (advisory only). |
| O_DIRECTORY |
Fail if the file is not a directory. |
| O_NOFOLLOW | Fail if the last path component is a symbolic link. |
| O_BINARY |
binmode the handle for Microsoft systems. An O_TEXT may also sometimes exist to get the opposite behavior. |
| O_LARGEFILE |
Some systems need this for files over 2 GB. |
| O_NOCTTY |
Opening a terminal file won't make that terminal become the process's controlling terminal if you don't have one yet. Usually no longer needed. |
The O_EXCL flag is not for locking: here, exclusiveness means that if the file already exists, sysopen fails.
If the file named by FILENAME does not exist and the MODE includes the O_CREAT flag, then sysopen creates the file with initial permissions determined by the MASK argument (or 0666 if omitted) as modified by your process's current umask. This default is reasonable: see the entry on umask for an explanation.
Filehandles opened with open and sysopen may be used interchangeably. You do not need to use sysread and friends just because you happened to open the file with sysopen, nor are you precluded from doing so if you opened it with open. Both can do things that the other can't. Regular open can open pipes, fork processes, set disciplines, duplicate file handles, and convert a file descriptor number into a filehandle. It also ignores leading and trailing whitespace in filenames and respects "-" as a special filename. But when it comes to opening actual files, sysopen can do anything that open can.
The following examples show equivalent calls to both functions. We omit the or die $! checks for clarity, but make sure to always check return values in your programs. We'll restrict ourselves to using only flags available on virtually all operating systems. It's just a matter of controlling the values that you OR together using the bitwise | operator to pass in MODE argument.
-
Open a file for reading:
open(FH, "<", $path); sysopen(FH, $path, O_RDONLY);
-
Open a file for writing, creating a new file if needed, or truncating an old file:
open(FH, ">", $path); sysopen(FH, $path, O_WRONLY | O_TRUNC | O_CREAT);
-
Open a file for appending, creating one if necessary:
open(FH, ">>", $path); sysopen(FH, $path, O_WRONLY | O_APPEND | O_CREAT);
-
Open a file for update, where the file must already exist:
open(FH, "+<", $path); sysopen(FH, $path, O_RDWR);
And here are things you can do with sysopen but not with regular open:
-
Open and create a file for writing, which must not previously exist:
sysopen(FH, $path, O_WRONLY | O_EXCL | O_CREAT);
-
Open a file for appending, which must already exist:
sysopen(FH, $path, O_WRONLY | O_APPEND);
-
Open a file for update, creating a new file if necessary:
sysopen(FH, $path, O_RDWR | O_CREAT);
-
Open a file for update, which must not already exist:
sysopen(FH, $path, O_RDWR | O_EXCL | O_CREAT);
-
Open a write-only file without blocking, but not creating it if it doesn't exist:
sysopen(FH, $path, O_WRONLY | O_NONBLOCK);
The FileHandle module described in Chapter 32, "Standard Modules" provides a set of object-oriented synonyms (plus a small bit of new functionality) for opening files. You are welcome to call the appropriate FileHandle methods[14] on any handle created with open, sysopen, pipe, socket, or accept, even if you didn't use the module to initialize those handles.
[14]Really IO::File or IO::Handle methods.
29.2.172. sysread [taintgray]
This function attempts to read LENGTH bytes of data into variable SCALAR from the specified FILEHANDLE using a low-level syscall, read(2). The function returns the number of bytes read, or 0 at EOF.[15] The sysread function returns undef on error. SCALAR will grow or shrink to the length actually read. The OFFSET, if specified, says where in the string to start putting the bytes, so that you can read into the middle of a string that's being used as a buffer. For an example of using OFFSET, see syswrite. An exception is raised if LENGTH is negative or if OFFSET points outside the string.sysread FILEHANDLE, SCALAR, LENGTH, OFFSET sysread FILEHANDLE, SCALAR, LENGTH
[15]There is no syseof function, which is okay, since eof doesn't work well on device files (like terminals) anyway. Use sysread and check for a return value for 0 to decide whether you're done.
You should be prepared to handle the problems (like interrupted syscalls) that standard I/O normally handles for you. Because it bypasses standard I/O, do not mix sysread with other kinds of reads, print, printf, write, seek, tell, or eof on the same filehandle unless you are into heavy wizardry (and/or pain). Also, please be aware that, when reading from a file containing Unicode or any other multibyte encoding, the buffer boundary may fall in the middle of a character.
29.2.173. sysseek
This function sets FILEHANDLE's system position using the syscall lseek(2). It bypasses standard I/O, so mixing this with reads (other than sysread), print, write, seek, tell, or eof may cause confusion. FILEHANDLE may be an expression whose value gives the name of the filehandle. The values for WHENCE are 0 to set the new position to POSITION, 1 to set the it to the current position plus POSITION, and 2 to set it to EOF plus POSITION (typically negative). For WHENCE, you may use the constants SEEK_SET, SEEK_CUR, and SEEK_END from the standard IO::Seekable and POSIX modules--or, as of the 5.6 release, from Fcntl, which is more portable and convenient.sysseek FILEHANDLE, POSITION, WHENCE
Returns the new position, or undef on failure. A position of zero is returned as the special string "0 but true", which can be used numerically without producing warnings.
29.2.174. system
This function executes any program on the system for you and returns that program's exit status--not its output. To capture the output from a command, use backticks or qx// instead. The system function works exactly like exec, except that system does a fork first and then, after the exec, waits for the executed program to complete. That is, it runs the program for you and returns when it's done, whereas execreplaces your running program with the new one, so it never returns if the replacement succeeds.system PATHNAME LIST system LIST
Argument processing varies depending on the number of arguments, as described under exec, including determining whether the shell will be called and whether you've lied to the program about its name by specifying a separate PATHNAME.
Because system and backticks block SIGINT and SIGQUIT, sending one of those signals (such as from a Control-C) to the program being run doesn't interrupt your main program. But the other program you're running does get the signal. Check the return value from system to see whether the program you were running exited properly or not.
@args = ("command", "arg1", "arg2");
system(@args) == 0
or die "system @args failed: $?"
The return value is the exit status of the program as returned through
the wait(2) syscall. Under traditional
semantics, to get the real exit value, divide by 256 or shift right by
8 bits. That's because the lower byte has something else in it. (Two
somethings, really.) The lowest seven bits indicate the signal number
that killed the process (if any), and the eighth bit indicates whether
the process dumped core. You can check all possible failure
possibilities, including signals and core dumps, by inspecting
$? ($CHILD_ERROR):
When the program has been run through the system shell[16] because you had only one argument and that argument had shell metacharacters in it, normal return codes are subject to that shell's additional quirks and capabilities. In other words, under those circumstances, you may be unable to recover the detailed information described earlier.$exit_value = $? >> 8; $signal_num = $? & 127; # or 0x7f, or 0177, or 0b0111_1111 $dumped_core = $? & 128; # or 0x80, or 0200, or 0b1000_0000
[16]That's /bin/sh by definition, or whatever makes sense on your platform, but not whatever shell the user just happens to be using at the time.
29.2.175. syswrite
This function attempts to write LENGTH bytes of data from variable SCALAR to the specified FILEHANDLE using the write(2) syscall. The function returns the number of bytes written, or undef on error. The OFFSET, if specified, says where in the string to start writing from. (You might do this if you were using the string as a buffer, for instance, or if you needed to recover from a partial write.) A negative OFFSET specifies that writing should start that many bytes backward from the end of the string. If SCALAR is empty, the only OFFSET permitted is 0. An exception is raised if LENGTH is negative or if OFFSET points outside the string.syswrite FILEHANDLE, SCALAR, LENGTH, OFFSET syswrite FILEHANDLE, SCALAR, LENGTH syswrite FILEHANDLE, SCALAR
To copy data from filehandle FROM into filehandle TO, you can use something like:
use Errno qw/EINTR/;
$blksize = (stat FROM)[11] || 16384; # preferred block size?
while ($len = sysread FROM, $buf, $blksize) {
if (!defined $len) {
next if $! == EINTR;
die "System read error: $!\n";
}
$offset = 0;
while ($len) { # Handle partial writes.
$written = syswrite TO, $buf, $len, $offset;
die "System write error: $!\n" unless defined $written;
$offset += $written;
$len -= $written;
}
}
You must be prepared to handle the problems that standard I/O
normally handles for you, such as partial writes. Because syswrite
bypasses the C standard I/O library, do not mix calls to it with
reads (other than sysread), writes (like print, printf,
or write), or other stdio functions like seek, tell, or
eof unless you are into heavy wizardry.[17]
[17]Or pain.
29.2.176. tell
This function returns the current file position (in bytes, zero-based) for FILEHANDLE. This value typically will be fed to the seek function at some future time to get back to the current position. FILEHANDLE may be an expression giving the name of the actual filehandle, or a reference to a filehandle object. If FILEHANDLE is omitted, the function returns the position of the file last read. File positions are only meaningful on regular files. Devices, pipes, and sockets have no file position.tell FILEHANDLE tell
There is no systell function. Use sysseek(FH, 0, 1) for that. Seek seek for an example telling how to use tell.
29.2.177. telldir
This function returns the current position of the readdir routines on DIRHANDLE. This value may be given to seekdir to access a particular location in a directory. The function has the same caveats about possible directory compaction as the corresponding system library routine. This function might not be implemented everywhere that readdir is. Even if it is, no calculation may be done with the return value. It's just an opaque value, meaningful only to seekdir.telldir DIRHANDLE
29.2.178. tie
This function binds a variable to a package class that will provide the implementation for the variable. VARIABLE is the variable (scalar, array, or hash) or typeglob (representing a filehandle) to be tied. CLASSNAME is the name of a class implementing objects of an appropriate type.tie VARIABLE, CLASSNAME, LIST
Any additional arguments are passed to the appropriate constructor method of the class, meaning one of TIESCALAR, TIEARRAY, TIEHASH, or TIEHANDLE. (If the appropriate method is not found, an exception is raised.) Typically, these are arguments such as might be passed to the dbm_open(3) function of C, but their meaning is package dependent. The object returned by the constructor is in turn returned by the tie function, which can be useful if you want to access other methods in CLASSNAME. (The object can also be accessed through the tied function.) So, a class for tying a hash to an ISAM implementation might provide an extra method to traverse a set of keys sequentially (the "S" of ISAM), since your typical DBM implementation can't do that.
Functions such as keys and values may return huge list values when used on large objects like DBM files. You may prefer to use the each function to iterate over such. For example:
use NDBM_File;
tie %ALIASES, "NDBM_File", "/etc/aliases", 1, 0
or die "Can't open aliases: $!\n";
while (($key,$val) = each %ALIASES) {
print $key, ' = ', $val, "\n";
}
untie %ALIASES;
A class implementing a hash should provide the following methods:
A class implementing an ordinary array should provide the following methods:TIEHASH CLASS, LIST FETCH SELF, KEY STORE SELF, KEY, VALUE DELETE SELF, KEY CLEAR SELF EXISTS SELF, KEY FIRSTKEY SELF NEXTKEY SELF, LASTKEY DESTROY SELF
A class implementing a scalar should provide the following methods:TIEARRAY CLASS, LIST FETCH SELF, SUBSCRIPT STORE SELF, SUBSCRIPT, VALUE FETCHSIZE SELF STORESIZE SELF, COUNT CLEAR SELF PUSH SELF, LIST POP SELF SHIFT SELF UNSHIFT SELF, LIST SPLICE SELF, OFFSET, LENGTH, LIST EXTEND SELF, COUNT DESTROY SELF
A class implementing a filehandle should have the following methods:TIESCALAR CLASS, LIST FETCH SELF, STORE SELF, VALUE DESTROY SELF
Not all methods indicated above need be implemented: the Tie::Hash, Tie::Array, Tie::Scalar, and Tie::Handle modules provide base classes that have reasonable defaults. See Chapter 14, "Tied Variables", for a detailed discussion of all these methods. Unlike dbmopen, the tie function will not use or require a module for you--you need to do that explicitly yourself. See the DB_File and Config modules for interesting tie implementations.TIEHANDLE CLASS, LIST READ SELF, SCALAR, LENGTH, OFFSET READLINE SELF GETC SELF WRITE SELF, SCALAR, LENGTH, OFFSET PRINT SELF, LIST PRINTF SELF, FORMAT, LIST CLOSE SELF DESTROY SELF
29.2.179. tied
This function returns a reference to the object underlying the scalar, array, hash, or typeglob contained in VARIABLE (the same value that was originally returned by the tie call that bound the variable to a package). It returns the undefined value if VARIABLE isn't tied to a package. So, for example, you can use:tied VARIABLE
to find out which package your hash is tied to. (Presuming you've forgotten.)ref tied %hash
29.2.180. time
This function returns the number of nonleap seconds since "the epoch", traditionally 00:00:00 on January 1st, 1970, UTC.[18] The returned value is suitable for feeding to gmtime and localtime, for comparison with file modification and access times returned by stat, and for feeding to utime.time
$start = time();
system("some slow command");
$end = time();
if ($end - $start > 1) {
print "Program started: ", scalar localtime($start), "\n";
print "Program ended: ", scalar localtime($end), "\n";
}
[18]Not to be confused with the "epic", which is about the making of Unix. (Other operating systems may have a different epoch, not to mention a different epic.)
29.2.181. times
In list context, this function returns a four-element list giving the user and system CPU times, in seconds (probably fractional), for this process and terminated children of this process.times
($user, $system, $cuser, $csystem) = times();
printf "This pid and its kids have consumed %.3f seconds\n",
$user + $system + $cuser + $csystem;
In scalar context, returns just the user time. For example, to
time the execution speed of a section of Perl code:
$start = times();
...
$end = times();
printf "that took %.2f CPU seconds of user time\n",
$end - $start;
29.2.182. tr///
This is the transliteration (also called translation) operator, which is like the y/// operator in the Unix sed program, only better, in everybody's humble opinion. See Chapter 5, "Pattern Matching".tr/// y///
29.2.183. truncate
This function truncates the file opened on FILEHANDLE, or named by EXPR, to the specified length. The function raises an exception if ftruncate(2) or an equivalent isn't implemented on your system. (You can always truncate a file by copying the front of it, if you have the disk space.) The function returns true on success, undef otherwise.truncate FILEHANDLE, LENGTH truncate EXPR, LENGTH
29.2.184. uc [taintgray]
This function returns an uppercased version of EXPR. This is the internal function implementing the \U escape in double-quoted strings. Perl will try to do the right thing with respect to your current locale settings, but we're still working out how that interacts with Unicode. See the perllocalle manpage for the latest guess. In any event, when Perl uses the Unicode tables, uc translates to uppercase rather than to titlecase. See ucfirst for titlecase translation.uc EXPR uc
29.2.185. ucfirst [taintgray]
This function returns a version of EXPR with the first character capitalized (titlecased in "Unicodese"), and other characters left alone. This is the internal function implementing the \u escape in double-quoted strings. Your current LC_CTYPE locale may be respected if you use locale and your data doesn't look like Unicode, but we make no guarantees at this time.ucfirst EXPR ucfirst
To force the initial character to titlecase and everything else to lowercase, use:
which is equivalent to "\u\L$word".ucfirst lc $word
29.2.186. umask
This function sets the umask for the process and returns the old one using the umask(2) syscall. Your umask tells the operating system which permission bits to disallow when creating a new file, including files that happen to be directories. If EXPR is omitted, the function merely returns the current umask. For example, to ensure that the "user" bits are allowed, and the "other" bits disallowed, try something like:umask EXPR umask
Remember that a umask is a number, usually given in octal; it is not a string of octal digits. See also oct, if all you have is a string. Remember also that the umask's bits are complemented compared to ordinary permissions.umask((umask() & 077) | 7); # don't change the group bits
The Unix permission rwxr-x--- is represented as three sets of three bits, or three octal digits: 0750 (the leading 0 indicates octal and doesn't count as one of the digits). Since the umask's bits are flipped, it represents disabled permissions bits. The permission (or "mode") values you supply to mkdir or sysopen are modified by your umask, so even if you tell sysopen to create a file with permissions 0777, if your umask is 0022, the file is created with permissions 0755. If your umask were 0027 (group can't write; others can't read, write, or execute), then passing sysopen a MASK of 0666 would create a file with mode 0640 (since 0666 & ~0027 is 0640).
Here's some advice: supply a creation mode of 0666 for regular files (in sysopen) and one of 0777 both for directories (in mkdir) and for executable files. This gives users the freedom of choice: if they want protected files, they choose process umasks of 022, 027, or even the particularly antisocial mask of 077. Programs should rarely if ever make policy decisions better left to the user. The exception to this rule is programs that write files that should be kept private: mail files, web browser cookies, .rhosts files, and so on.
If umask(2) is not implemented on your system and you are trying to restrict your own access (that is, if EXPR& 0700) > 0), you'll trigger a run-time exception. If umask(2) is not implemented and you are not trying to restrict your own access, the function simply returns undef.
29.2.187. undef
undef is the name by which we refer to the abstraction known as "the undefined value". It also conveniently happens to be the name of a function that always returns the undefined value. We happily confuse the two.undef EXPR undef
Coincidentally, the undef function can also explicitly undefine an entity if you supply its name as an argument. The EXPR argument, if specified, must be an lvalue. Hence you may only use this on a scalar value, an entire array or hash, a subroutine name (using the & prefix), or a typeglob. Any storage associated with the object will be recovered for reuse (though not returned to the system, for most operating systems). The undef function will probably not do what you expect on most special variables. Using it on a read-only variable like $1 raises an exception.
The undef function is a unary operator, not a list operator, so you can only undefine one thing at a time. Here are some uses of undef as a unary operator:
undef $foo;
undef $bar{'blurfl'}; # Different from delete $bar{'blurfl'};
undef @ary;
undef %hash;
undef &mysub;
undef *xyz; # destroys $xyz, @xyz, %xyz, &xyz, etc.
Without an argument, undef is just used for its value:
You may use undef as a placeholder on the left side of a list assignment, in which case the corresponding value from the right side is simply discarded. Apart from that, you may not use undef as an lvalue.select(undef, undef, undef, $naptime); return (wantarray ? () : undef) if $they_blew_it; return if $they_blew_it; # same thing
Also, do not try to compare anything to undef--it doesn't do what you think. All it does is compare against 0 or the null string. Use the defined function to determine if a value is defined.($a, $b, undef, $c) = &foo; # Ignore third value returned
29.2.188. unlink
This function deletes a list of files.[19] The function returns the number of filenames successfully deleted. Some sample examples:unlink LIST unlink
$count = unlink 'a', 'b', 'c';
unlink @goners;
unlink glob("*.orig");
The unlink function will not delete directories unless you are superuser
and the supply -U command-line option to Perl. Even if
these conditions are met, be warned that unlinking a directory can
inflict Serious Damage on your filesystem. Use rmdir instead.
[19] Actually, under a POSIX filesystem, it removes the directory entries (filenames) that refer to the real files. Since a file may be referenced (linked) from more than one directory, the file isn't removed until the last reference to it is removed.
Here's a simple rm command with very simple error checking:
#!/usr/bin/perl
@cannot = grep {not unlink} @ARGV;
die "$0: could not unlink @cannot\n" if @cannot;
29.2.189. unpack
This function does the reverse of pack: it expands a string (EXPR) representing a data structure into a list of values according to the TEMPLATE and returns those values. In scalar context, it can be used to unpack a single value. The TEMPLATE here has much the same format as it has in the pack function--it specifies the order and type of the values to be unpacked. See pack for a detailed description of TEMPLATE. An invalid element in the TEMPLATE, or an attempt to move outside the string with the x, X, or @ formats, raises an exception.unpack TEMPLATE, EXPR
The string is broken into chunks described by the TEMPLATE. Each chunk is converted separately to a value. Typically, the bytes of the string either are the result of a pack, or represent a C structure of some kind.
If the repeat count of a field is larger than the remainder of the input string allows, the repeat count is silently decreased. (Normally, you'd use a repeat count of * here, anyway.) If the input string is longer than what TEMPLATE describes, the rest of the string is ignored.
The unpack function is also useful for plain text data, too, not just binary data. Imagine that you had a data file that contained records that looked like this:
you can't use split to parse out the fields because they have no distinct separator. Instead, fields are determined by their byte-offset into the record. So even though this is a regular text record, because it's in a fixed format, you want to use unpack to pull it apart:1986 Ender's Game Orson Scott Card 1985 Neuromancer William Gibson 1984 Startide Rising David Brin 1983 Foundation's Edge Isaac Asimov 1982 Downbelow Station C. J. Cherryh 1981 The Snow Queen Joan D. Vinge
while (<>) {
($year, $title, $author) = unpack("A4 x A23 A*", $_);
print "$author won ${year}'s Hugo for $title.\n";
}
(The reason we wrote ${year}'s there is because Perl would have
treated $year's as meaning $year::s.)
Here's a complete uudecode program:
#!/usr/bin/perl
$_ = <> until ($mode,$file) = /^begin\s*(\d*)\s*(\S*)/;
open(OUT,"> $file") if $file ne "";
while (<>) {
last if /^end/;
next if /[a-z]/;
next unless int((((ord() - 32) & 077) + 2) / 3) ==
int(length() / 4);
print OUT unpack "u", $_;
}
chmod oct($mode), $file;
In addition to fields allowed in pack, you may prefix a field
with %number to produce a simple number-bit additive checksum
of the items instead of the items themselves. Default is a 16-bit
checksum. The checksum is calculated by summing numeric values of
expanded values (for string fields, the sum of ord($char) is
taken, and for bit fields, the sum of zeros and ones). For example,
the following computes the same number as the SysV sum(1) program:
undef $/;
$checksum = unpack ("%32C*", <>) % 65535;
The following efficiently counts the number of set bits in a bitstring:
Here's a simple BASE64 decoder:$setbits = unpack "%32b*", $selectmask;
while (<>) {
tr#A-Za-z0-9+/##cd; # remove non-base64 chars
tr#A-Za-z0-9+/# -_#; # convert to uuencoded format
$len = pack("c", 32 + 0.75*length); # compute length byte
print unpack("u", $len . $_); # uudecode and print
}
29.2.190. unshift
This function does the opposite of shift. (Or the opposite of push, depending on how you look at it.) It prepends LIST to the front of the array, and returns the new number of elements in the array:unshift ARRAY, LIST
Note the LIST is prepended whole, not one element at a time, so the prepended elements stay in the same order. Use reverse to do the reverse.unshift @ARGV, '-e', $cmd unless $ARGV[0] =~ /^-/;
29.2.191. untie
Breaks the binding between the variable or typeglob contained in VARIABLE and the package that it's tied to. See tie, and all of Chapter 14, "Tied Variables", but especially the section "A Subtle Untying Trap".untie VARIABLE
29.2.192. use
The use declaration loads in a module, if it hasn't been loaded before, and imports subroutines and variables into the current package from the named module. (Technically speaking, it imports some semantics into the current package from the named module, generally by aliasing certain subroutine or variable names into your package.) Most use declarations looks like this:use MODULE VERSION LIST use MODULE VERSION () use MODULE VERSION use MODULE LIST use MODULE () use MODULE use VERSION
That is exactly equivalent to saying:use MODULE LIST;
BEGIN { require MODULE; import MODULE LIST; }
The BEGIN forces the require and import to happen at compile
time. The require makes sure the module is loaded into memory
if it hasn't been yet. The import is not a built-in--it's just
an ordinary class method call into the package named by MODULE
to tell that module to pull the list of features back into the
current package. The module can implement its import method any
way it likes, though most modules just choose to derive their import
method via inheritance from the Exporter class that is defined in
the Exporter module. See Chapter 11, "Modules",
and the Exporter module for more information.
If no import method can be found, then the call is skipped without murmur.
If you don't want your namespace altered, explicitly supply an empty list:
That is exactly equivalent to the following:use MODULE ();
BEGIN { require MODULE; }
If the first argument to use is a version number like 5.6.2, the
currently executing version of Perl must be at least as modern as the
version specified. If the current version of Perl is less than
VERSION, an error message is printed and Perl exits immediately.
This is useful for checking the current Perl version before loading
library modules that depend on newer versions, since occasionally we
have to "break" the misfeatures of older versions of Perl. (We try not
to break things any more than we have to. In fact, we often try to
break things less than we have to.)
Speaking of not breaking things, Perl still accepts old version numbers of the form:
However, in order to align better with industry standards, Perl 5.6 now accepts, (and we prefer to see) the three-tuple form:use 5.005_03;
If the VERSION argument is present after MODULE, then the use will call the VERSION method in class MODULE with the given VERSION as an argument. Note that there is no comma after VERSION! The default VERSION method, which is inherited from the UNIVERSAL class, croaks if the given version is larger than the value of the variable $Module::VERSION.use 5.6.0; # That's version 5, subversion 6, patchlevel 0.
See Chapter 32, "Standard Modules" for a list of standard modules.
Because use provides a wide-open interface, pragmas (compiler directives) are also implemented via modules. Examples of currently implemented pragmas include:
Many of these pragmatic modules import semantics into the current lexical scope. (This is unlike ordinary modules, which only import symbols into the current package, which has little relation to the current lexical scope other than that the lexical scope is being compiled with that package in mind. That is to say...oh, never mind, see Chapter 11, "Modules".)use autouse 'Carp' => qw(carp croak); use bytes; use constant PI => 4 * atan2(1,1); use diagnostics; use integer; use lib '/opt/projects/spectre/lib'; use locale; use sigtrap qw(die INT QUIT); use strict qw(subs vars refs); use warnings "deprecated";
There's a corresponding declaration, no, that "unimports" any meanings originally imported by use that have since become, er, unimportant:
See Chapter 31, "Pragmatic Modules" for a list of standard pragmas.no integer; no strict 'refs'; no utf8; no warnings "unsafe";
29.2.193. utime
This function changes the access and modification times on each file of a list of files. The first two elements of the list must be the numerical access and modification times, in that order. The function returns the number of files successfully changed. The inode change time of each file is set to the current time. Here's an example of a touch command that sets the modification date of the file (assuming you're the owner) to about a month in the future:utime LIST
and here's a more sophisticated touch-like command with a smattering of error checking:#!/usr/bin/perl # montouch - post-date files now + 1 month $day = 24 * 60 * 60; # 24 hours of seconds $later = time() + 30 * $day; # 30 days is about a month utime $later, $later, @ARGV;
#!/usr/bin/perl
# montouch - post-date files now + 1 month
$later = time() + 30 * 24 * 60 * 60;
@cannot = grep {not utime $later, $later, $_} @ARGV;
die "$0: Could not touch @cannot.\n" if @cannot;
To read the times from existing files, use stat and then pass
the appropriate fields through localtime or gmtime for printing.
29.2.194. values
This function returns a list consisting of all the values in the indicated HASH. The values are returned in an apparently random order, but it is the same order as either the keys or each function would produce on the same hash. Oddly, to sort a hash by its values, you usually need to use the keys function, so see the example under keys for that.values HASH
You can modify the values of a hash using this function because the returned list contains aliases of the values, not just copies. (In earlier versions, you needed to use a hash slice for that.)
for (@hash{keys %hash}) { s/foo/bar/g } # old way
for (values %hash) { s/foo/bar/g } # now changes values
Using values on a hash that is bound to a humongous DBM file is
bound to produce a humongous list, causing you to have a humongous
process. You might prefer to use the each
function, which will iterate over the hash entries one by one without
slurping them all into a single gargantuan, er, humongous list.
29.2.195. vec
The vec function provides compact storage of lists of unsigned integers. These integers are packed as tightly as possible within an ordinary Perl string. The string in EXPR is treated as a bit string made up of some arbitrary number of elements depending on the length of the string.vec EXPR, OFFSET, BITS
OFFSET specifies the index of the particular element you're interested in. The syntaxes for reading and writing the element are the same, since vec stores or returns the value of the element depending on whether you use it in an lvalue or an rvalue context.
BITS specifies how wide each element is in bits, which must be a power of two: 1, 2, 4, 8, 16, or 32 (and also 64 on some platforms). (An exception is raised if any other value is used.) Each element can therefore contain an integer in the range 0..(2**BITS)-1. For the smaller sizes, as many elements as possible are packed into each byte. When BITS is 1, there are eight elements per byte. When BITS is 2, there are four elements per byte. When BITS is 4, there are two elements (traditionally called nybbles) per byte. And so on. Integers larger than a byte are stored in big-endian order.
A list of unsigned integers can be stored in a single scalar variable by assigning them individually to the vec function. (If EXPR is not a valid lvalue, an exception is raised.) In the following example, the elements are each 4 bits wide:
$bitstring = "";
$offset = 0;
foreach $num (0, 5, 5, 6, 2, 7, 12, 6) {
vec($bitstring, $offset++, 4) = $num;
}
If an element off the end of the string is written to,
Perl will first extend the string with sufficiently many zero bytes.
The vectors stored in the scalar variable can be subsequently retrieved by specifying the correct OFFSET.
$num_elements = length($bitstring)*2; # 2 elements per byte
foreach $offset (0 .. $num_elements-1) {
print vec($bitstring, $offset, 4), "\n";
}
If the selected element is off the end of the string, a value of 0 is
returned.
Strings created with vec can also be manipulated with the logical operators |, &, ^, and ~. These operators will assume that a bit string operation is desired when both operands are strings. See the examples of this in Chapter 3, "Unary and Binary Operators", in the section "Bitwise Operators".
If BITS == 1, a bitstring can be created to store a series of bits all in one scalar. The ordering is such that vec($bitstring,0,1) is guaranteed to go into the lowest bit of the first byte of the string.
@bits = (0,0,1,0, 1,0,1,0, 1,1,0,0, 0,0,1,0);
$bitstring = "";
$offset = 0;
foreach $bit (@bits) {
vec($bitstring, $offset++, 1) = $bit;
}
print "$bitstring\n"; # "TC", ie. '0x54', '0x43'
A bit string can be translated to or from a string of
1's and 0's by supplying a
"b*" template to pack or
unpack. Alternatively, pack can
be used with a "b*" template to create the bit
string from a string of 1's and
0's. The ordering is compatible with that expected
by vec.
$bitstring = pack "b*", join('', @bits);
print "$bitstring\n"; # "TC", same as before
unpack can be used to extract the list of 0's and 1's from
the bit string.
@bits = split(//, unpack("b*", $bitstring));
print "@bits\n"; # 0 0 1 0 1 0 1 0 1 1 0 0 0 0 1 0
If you know the exact length in bits, it can be used in place of the "*".
See select for additional examples of using bitmaps generated with vec. See pack and unpack for higher-level manipulation of binary data.
29.2.196. wait
This function waits for a child process to terminate and returns the PID of the deceased process, or -1 if there are no child processes (or on some systems, if child processes are being automatically reaped). The status is returned in $? as described under system. If you get zombie child processes, you should be calling this function, or waitpid.wait
If you expected a child and didn't find it with wait, you probably had a call to system, a close on a pipe, or backticks between the fork and the wait. These constructs also do a wait(2) and may have harvested your child process. Use waitpid to avoid this problem.
29.2.197. waitpid
This function waits for a particular child process to terminate and returns the PID when the process is dead, -1 if there are no child processes, or 0 if the FLAGS specify nonblocking and the process isn't dead yet. The status of the dead process is returned in $? as described under system. To get valid flag values, you'll need to import the ":sys_wait_h" import tag group from the POSIX module. Here's an example that does a nonblocking wait for all pending zombie processes.waitpid PID, FLAGS
use POSIX ":sys_wait_h";
do {
$kid = waitpid(-1,&WNOHANG);
} until $kid == -1;
On systems that implement neither the waitpid(2) nor wait4(2)
syscall, FLAGS may be specified only as 0. In other words, you
can wait for a specific PID there, but you can't do so in nonblocking
mode.
On some systems, a return value of -1 could mean that child processes are being automatically reaped because you set $SIG{CHLD} = 'IGNORE'.
29.2.198. wantarray
This function returns true if the context of the currently executing subroutine is looking for a list value, and false otherwise. The function returns a defined false value ("") if the calling context is looking for a scalar, and the undefined false value (undef) if the calling context isn't looking for anything; that is, if it's in void context.wantarray
Here's are examples of typical usage:
See also caller. This function should really have been named "wantlist", but we named it back when list contexts were still called array contexts.return unless defined wantarray; # don't bother doing more my @a = complex_calculation(); return wantarray ? @a : \@a;
29.2.199. warn
This function produces an error message, printing LIST to STDERR just like die, but doesn't try to exit or throw an exception. For example:warn LIST warn
If LIST is empty and $@ already contains a value (typically from a previous eval), the string "\t...caught" is appended following $@ on STDERR. (This is similar to the way die propagates errors, except that warn doesn't propagate (reraise) the exception.) If the message string supplied is empty, the message "Warning: Something's wrong" is used.warn "Debug enabled" if $debug;
As with die, if the strings supplied don't end in a newline, file and line number information is automatically appended. The warn function is unrelated to Perl's -w command-line option, but can be used in conjunction with it, such as when you wish to emulate built-ins:
No message is printed if there is a $SIG{__WARN__} handler installed. It is the handler's responsibility to deal with the message as it sees fit. One thing you might want to do is promote a mere warning into an exception:warn "Something wicked\n" if $^W;
local $SIG{__WARN__} = sub {
my $msg = shift;
die $msg if $msg =~ /isn't numeric/;
};
Most handlers must therefore make arrangements to display
the warnings that they are not prepared to deal with, by calling
warn again in the handler. This is perfectly safe; it won't produce
an endless loop because __WARN__ hooks are not called from inside
__WARN__ hooks. This behavior differs slightly from that of
$SIG{__DIE__} handlers (which don't suppress the error text, but
can instead call die again to change it).
Using a __WARN__ handler provides a powerful way to silence all warnings, even the so-called mandatory ones. Sometimes you need to wrap this in a BEGIN{} block so that it can happen at compile time:
# wipe out *all* compile-time warnings
BEGIN { $SIG{__WARN__} = sub { warn $_[0] if $DOWARN } }
my $foo = 10;
my $foo = 20; # no warning about duplicate my $foo,
# but hey, you asked for it!
# no compile-time or run-time warnings before here
$DOWARN = 1; # *not* a built-in variable
# run-time warnings enabled after here
warn "\$foo is alive and $foo!"; # does show up
See the use warnings pragma for lexically scoped
control of warnings. See the Carp module's
carp and cluck functions for
other ways to produce warning messages.
29.2.200. write
This function writes a formatted record (possibly multiline) to the specified filehandle, using the format associated with that filehandle--see the section "Format Variables" in Chapter 7, "Formats". By default the format associated with a filehandle is the one having the same name as the filehandle. However, the format for a filehandle may be changed by altering the $~ variable after you select that handle:write FILEHANDLE write
or by saying:$old_fh = select(HANDLE); $~ = "NEWNAME"; select($old_fh);
use IO::Handle;
HANDLE->format_name("NEWNAME");
Since formats are put into a package namespace, you may have
to fully qualify the format name if the format
was declared in a different package:
Top-of-form processing is handled automatically: if there is insufficient room on the current page for the formatted record, the page is advanced by writing a form feed, a special top-of-page format is used for the new page header, and then the record is written. The number of lines remaining on the current page is in the variable $-, which can be set to 0 to force a new page on the next write. (You may need to select the filehandle first.) By default, the name of the top-of-page format is the name of the filehandle with "_TOP" appended, but the format for a filehandle may be changed altering the $^ variable after selecting that handle, or by saying:$~ = "OtherPack::NEWNAME";
use IO::Handle;
HANDLE->format_top_name("NEWNAME_TOP");
If FILEHANDLE is unspecified, output goes to the current default
output filehandle, which starts out as STDOUT, but may be changed
by the single-argument form of the select operator. If the
FILEHANDLE is an expression, then the expression is evaluated
to determine the actual FILEHANDLE at run time.
If a specified format or the current top-of-page format does not exist, an exception is raised.
The write function is not the opposite of read. Unfortunately. Use print for simple string output. If you looked up this entry because you wanted to bypass standard I/O, see syswrite.
29.2.201. y//
The transliteration (historically, also called translation) operator, also known as tr///. See Chapter 5, "Pattern Matching".y///
 |  |  |
| 29.1. Perl Functions by Category |  | 30. The Standard Perl Library |

Copyright © 2001 O'Reilly & Associates. All rights reserved.