

|
Chapter 11 |

|
11. Implementing Object Persistence
God gave us our memories so that we might have roses in December.
- James Matthew Barrie
The Amazon is formed by the confluence of two rivers: the Solimőes, a yellowish, silt-laden river, and the dramatic Rio Negro, a river with jet-black water.[ 1 ] Twelve miles downstream of their meeting, the two rivers defiantly retain their separate identities while sharing the same bed. Somehow, this seems to bear a strange resemblance to the subject at hand: object persistence.
[1] The color comes from suspended minerals and decomposed organic matter from marginal swamps.
There are two important camps in the commercial computing world: purveyors of OO (language designers, object evangelists) and persistence vendors (database and TP[ 2 ] monitor implementors). Like the Solimőes and the Rio Negro, the two camps (and multiple camps within their ranks) have their own agendas, even as they strive to merge at some point in the future.
[2] Transaction-processing.
The OO folks would like nothing more than commercial-grade persistence (in terms of performance, stability, and scalability) and propose methods to retrofit various persistence stores onto an object model. Some of their prominent efforts include the CORBA Persistence Services specification from the Object Management Group, Sun's PJava (Persistent Java), and the OLE Persistence framework from Microsoft. Meanwhile, the database folks are grafting OO features onto their offerings: RDBMS vendors such as Informix and Oracle have announced object-relational databases (supporting abstract data types, not just plain scalar data), and the various TP monitor products from Tandem, IBM, Tuxedo, and Encina are sporting object-oriented interfaces. There is a tiny object persistence camp, the Object Database Management Group, comprising the OODB vendors, but their presence is quite negligible (commercially).
One of the hot topics in all these groups is the subject of " orthogonal" persistence - the ability to make an application or object persistent without embedding any, or much, persistence-specific code in the object. The idea is very seductive: Design your object model, implement it in memory, and then add persistence on the "side." This way, the objects don't have to be cluttered with the myriad details (and differences) of databases, nor do they have to deal with filesystem errors, data formatting, and other problems.[ 3 ] You can think of it this way: if you never embed user-interface-specific code inside an object, why would you do so for persistence?
There have traditionally been two approaches to achieving the transparency mentioned above.
The first is to take advantage of the systems side of things, such as the hardware, operating system, and compiler. For example, object-oriented databases such as Object Store and the Texas Persistent Store (a public-domain library) use the Unix system's
mmap
and
mprotect
calls to transparently move data from memory to disk and back. Another interesting systems-oriented approach comes from a group at Bell Labs, which has built a library that stores the state of an application by having it simply dump core in a controlled fashion, thus faithfully rendering all memory-based data structures onto disk.[
4
] They have augmented this facility with recovery and transactions and made this approach almost completely transparent to the application.
[4] Note that Perl's
dumpoperator does produce a core file, but it also aborts the application, a somewhat unpleasant feature.
The second approach for achieving transparent or orthogonal persistence is to supply application-level tools and libraries, an approach that is considerably more portable than the systems approach. CASE tools, for example, generate code to automate the task of sending objects to a persistent store (typically a relational database), while libraries such as Microsoft Foundation Classes ask the objects to stream themselves out to a file. In the latter case, the objects have to implement streaming methods. In either case, the code to be written by hand is fairly minimal, so it is still a reasonably transparent approach.
In this chapter, we will discuss a pilot project called Adaptor, a persistence framework for Perl objects (and written in Perl, of course). This is an application-level approach and doesn't expect the objects to implement persistence-specific methods. Unlike typical CASE tools, it does not generate any code files, because Perl is a dynamic language.
The primary objective of the Adaptor project was to study orthogonal persistence; this, I thought, could be done by "adapting" objects to specific types of persistent stores, using information completely outside the objects; the implementation described in this chapter depends on configuration files to describe which attributes map to which database columns, and how.
A secondary objective of this project was to study how you might code an application differently if you could always take queries and transaction atomicity for granted; that is, even if you didn't have a database at all, suppose you could ask some entity, "Give me all employees whose salary exceeds $100,000," and the application would be persistence-ready from the very beginning. I'm of the firm belief that you cannot simply drop persistence into an application; the object implementations look very different if they know that there is some kind of persistence up ahead (even if they don't quite have any specifics about the type of persistence). This is similar to the case of applications knowing that there may be a graphical user interface in the future and that it may be event-driven; for example, you may not write errors out to STDERR , and might make sure that no code gets indefinitely blocked on I/O. (We'll actually discuss these issues in Section 14.1, "Introduction to GUIs, Tk, and Perl/Tk" .)
This chapter is probably more important for the issues it brings up than the specifics of the implementation; however, an implementation is necessary to clearly understand the problem.
11.1 Adaptor: An Introduction
Adaptor is intended to be a group of modules that translate a uniform persistence interface to specific types of persistent stores, as shown in Figure 11.1 . This chapter describes the two that have been implemented: Adaptor::File, capable of storing objects in plain files, and Adaptor::DBI, which can store them in relational databases. From here on, we will use the term "adaptor" to mean an object of any of these modules.
Figure 11.1: Adaptor modules
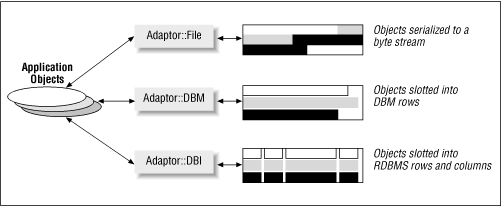
An adaptor represents a typical persistent store capable of accommodating a heterogeneous collection of objects; an Adaptor::File object is a wrapper over a file, and an Adaptor::DBI object is a wrapper over a database connection. All adaptors provide basic SQL queries[ 5 ] and transactions.[ 6 ]
[5] Only SQL
whereclauses, not the entire select clause; joins are not supported either.[6] Adaptor::File implements a fairly limited model, but it does support the interface.
Before we use these modules, let us create a few test application objects. We use the ObjectTemplate library discussed in Section 8.1, "Efficient Attribute Storage" , for this task:
use ObjectTemplate;
#----------------------------------------
package Employee;
@ISA = ('ObjectTemplate');
@ATTRIBUTES = qw(_id name age dept);
#----------------------------------------
package Department;
@ISA = ('ObjectTemplate');
@ATTRIBUTES = qw(_id name address);
#----------------------------------------
$dept = new Department (name => 'Materials Handling');
$emp1 = new Employee (name => 'John', age => 23, dept => $dept);
$emp2 = new Employee (name => 'Larry', age => 45, dept => $dept);
We now have three objects, free of database-specific code. To stow these objects into a persistent store, we start by creating an instance of a file or database adaptor as follows:
$db =
Adaptor::File->new
('test.dat', 'empfile.cfg');
The adaptor object, $db , is now associated with file test.dat and stores all objects given to it in this file. An object may have attributes that it doesn't wish to be made persistent: some attributes may be computed ( after_tax_salary ), while others may refer to filehandles, sockets, or GUI widgets. For this reason, the adaptor expects the developer to state, in a configuration file ( empfile.cfg , in this example), which attributes must be made persistent. empfile.cfg looks like this:
[Employee] attributes = _id, name, age [Department] attributes = _id, name, address
The adaptor can now be asked to store objects in its file, test.dat , as follows:
$db->store ($dept); $db->store($emp1); $db->store($emp2);
Our "database" now has a number of objects, and we can query this database using the retrieve_where method, like this:
@emps =
$db->retrieve_where
('Employee', "age < 40 && name != 'John'");
foreach $emp (@emps) {
$emp->print();
}
This method takes a class name and a query expression and returns object references of the specified class that match this criteria.
The flush method is used to ensure that the data in memory is flushed out to disk:
$db->flush ();
You can store objects under the purview of transactions:
$db->begin_transaction (); $db->store($emp1); $db->store($emp2); $db->commit_transaction (); # or rollback_transaction
The file adaptor keeps track of all objects given to its store method, and it flushes them to disk on commit_transaction . If, instead, you call rollback_transaction , it simply discards its internal structures and reloads the file, thus getting rid of all changes you may have made to the objects. This is by no means a real transaction (it doesn't protect the data from system failures), but it does support atomic updates, which can be used as an automatic undo facility.
To store these objects in a database instead of a file, all we need to do is make $db an instance of the Adaptor::DBI class. Everything else remains unchanged, except that you can feel a lot safer about your data because you get real transactions.
The Adaptor::DBI constructor's arguments are database-specific:
$db = Adaptor::DBI->new ($user, $password, 'Sybase', 'empdb.cfg');
This method calls DBI::new with the first three parameters. The last parameter is, as before, a configuration file, with some extra database-specific mapping information:
[Employee] table = emp attributes = _id, name, age columns = _id, name, age [Department] table = dept attributes = _id, name, address columns = _id, name, address
The attributes parameter specifies the list of attributes to be extracted out of an instance of a given module, and columns lists the corresponding column names in the database. Many adaptors can use the same configuration file.
|
|

|
|
| 10.5 Resources |

|
11.2 Design Notes |