

|
Chapter 3 |

|
3. Typeglobs and Symbol Tables
Contents:
Perl Variables, Symbol Table, and Scoping
Typeglobs
Typeglobs and References
Filehandles, Directory Handles, and Formats
We are symbols, and inhabit symbols.
- Ralph Waldo Emerson
This chapter discusses typeglobs, the symbol table, filehandles, formats, and the differences between dynamic and lexical scoping. At first sight, these topics may seem to lack a common theme, but as it happens, they are intimately tied to typeglobs and symbol tables.
Typeglobs are immensely useful. They allow us to efficiently create aliases of symbols, which is the basis for a very important module called Exporter that is used in a large number of freely available modules. Typeglobs can also be aliased to ordinary references in such a way that you don't have to use the dereferencing syntax; this is not only easier on the eye, it is faster too. At the same time, using typeglobs without understanding how they work can lead to a particularly painful problem called variable suicide . This might explain why most Perl literature gives typeglobs very little attention.
Closely related to typeglobs and symbol tables is the subject of dynamic versus lexical scoping (using local versus my ). There are a couple of useful idioms that arise from these differences.
This is the only chapter that starts off by giving a picture of what is going on inside, rather than first presenting examples that you can use directly. The hope is that you will find the subsequent discussions really easy to follow.
3.1 Perl Variables, Symbol Table, and Scoping
Variables are either global or lexical (those tagged with my ). In this section we briefly study how these two are represented internally. Let us start with global variables.
Perl has a curious feature that is typically not seen in other languages: you can use the same name for both data and nondata types. For example, the scalar $spud , the array @spud , the hash %spud , the subroutine &spud , the filehandle spud , and the format name spud are all simultaneously valid and completely independent of each other. In other words, Perl provides distinct namespaces for each type of entity. I do not have an explanation for why this feature is present. In fact, I consider it a rather dubious facility and recommend that you use a distinct name for each logical entity in your program; you owe it to the poor fellow who's going to maintain your code (which might be you!).
Perl uses a symbol table (implemented internally as a hash table)[ 1 ] to map identifier names (the string "spud" without the prefix) to the appropriate values. But you know that a hash table does not tolerate duplicate keys, so you can't really have two entries in the hash table with the same name pointing to two different values. For this reason, Perl interposes a structure called a typeglob between the symbol table entry and the other data types, as shown in Figure 3.1 ; it is just a bunch of pointers to values that can be accessed by the same name, with one pointer for each value type. In the typical case, in which you have unique identifier names, all but one of these pointers are null.
[1] Actually, it is one symbol table per package, where each package is a distinct namespace. For now, this distinction does not matter. We'll revisit this issue in Chapter 6, Modules .
Figure 3.1: Symbol table and typeglobs
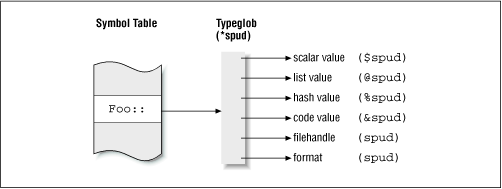
A typeglob is a real data type accessible from script space and has the prefix " * "; while you can think of it as a wildcard representing all values sharing the identifier name, there's no pattern matching going on. You can assign typeglobs, store them in arrays, create local versions of them, or print them out, just as you can for any fundamental type. More on this in a moment.
3.1.1 Lexical Variables
Lexical variables (those tagged with my ) aren't listed in the symbol table at all. Every block and subroutine gets a list of one or more arrays of variables called scratchpads (typically one, but more if the subroutine recurses). Each lexical variable is assigned one slot from a scratchpad; in fact, different types of variables with the same name - $spud and %spud , say - occupy different slots. Since a subroutine's lexical variables are independent of any other's, we get truly local variables. We will have more to say on this subject in Chapter 20, Perl Internals .
3.1.2 Lexical Versus Dynamic Scoping
There are two ways of getting private values inside a subroutine or block. One is to use the local operator, which operates on global variables only; it saves their values and arranges to have them restored at the end of the block. The other option is to use my , which not only creates a new variable, it marks it as private to the block.
On the surface, both local and my behave identically:
$a = 20; # global variable
{
local ($a); # save $a's old value;
# new value is undef
my (@b); # Lexical variable
$a = 10; # Modify $a's new value
@b = ("wallace", "grommit");
print $a; # prints "10"
print "@b"; # prints "wallace grommit"
}
# Block ended. Back to global scope where only $a is valid
print $a; # prints "20", the old value
print @b; # prints a warning, because no global @b
A global variable created because of a local statement gets deallocated at the end of the block.
While their usage is identical, there's one important difference between local and my . The my declaration creates truly local variables, such as auto variables in C. This is called lexical binding. The variable is private to the block in which it is declared and is available only to that block (what you can see lexically defines the bounds). It is not available to subroutines that are called from the block.
In contrast, the local operator does not create new variable. When applied to global variables, it squirrels their values away and restores them at the end of the block. Because the variables themselves are global, their new value is available not only to the block in which the local operator is used, but also to all called subroutines . Consider
$x = 10;
first();
sub first {
local ($x) = "zen"; # $x is still global, and has a new value
second();
}
sub second {
print $x; # Prints "zen", the current value of the global $x
}
From global scope, we call first , which localizes the global $x , sets it to a new value (the string "zen"), and calls second . second sees the last value of $x , as set by first . This process is called dynamic scoping , because the value of $x seen by second depends on the particular call stack. This feature can be quite confusing in practice, because if you wrote another subroutine that declared a local $x and called second , it would pick up that version of $x .
In other words, local makes a global variable's new value temporary; it does not change the essential nature of the variable itself (it still remains global). my creates a truly local variable. Which is why you can say
local $x{foo}; # Squirrel away $x{foo}'s value.
but not
my $x{foo}; # Error. $x{foo} is not a variable
It is recommended that you use my wherever possible, because you almost always want lexical scoping. In addition, as we shall see in Chapter 20 , lexically scoped variables are faster than dynamically scoped variables.
3.1.2.1 When would you ever need to use local?
The fact that local saves a variable's value and arranges to have that value restored at the end of the block results in a very neat idiom: localizing built-in variables. Consider a local version of the built-in array representing the program's arguments, @ARGV :
{ # Start of a new block
local(@ARGV) = ("/home/alone", "/vassily/kandinski");
while (<>) {
# Iterate through each file and process each line
print; # print, for example
}
} # Block ends. The original @ARGV restored after this.
The diamond operator ( <> ) needs a globally defined @ARGV to work, so it looks at the typeglob corresponding to the ARGV entry in the symbol table.[ 2 ] What it doesn't know, however, is that local has temporarily replaced @ARGV 's value with a different array. The diamond operator treats each element of this array as a filename, opens it, reads a line in every iteration, and moves on to the first line of the next file when necessary. When the block is over, the original @ARGV is restored. This example does not work with my , because this operator creates a wholly new variable.
[2] For efficiency, Perl doesn't do a symbol table lookup at run-time. The compilation phase ensures that the corresponding opcodes know which typeglob to pick up. More on this in Chapter 20 .
This technique works for other built-in variables too. Consider the variable $/ , which contains the input record separator ("\n" by default). The diamond input operator uses this separator to return the next chunk (by default, the next line). If you undef it, the whole file is slurped in, in one fell swoop. To avoid having to save the original value of $/ and restore it later, you can use local instead, like this:
{
local $/ = undef; # Saves previous value of $/, and substitutes
# it with undef
$a = <STDIN>; # Slurp all of STDIN into $a
}
local is also used for localizing typeglobs, which, as it turns out, is the only way of getting local filehandles, formats, and directory handles.
|
|

|
|
| 2.6 Resources |

|
3.2 Typeglobs |