

|
Chapter 2 |

|
2. Implementing Complex Data Structures
Contents:
User-Defined Structures
Example: Matrices
Professors, Students, Courses
Pass the Envelope
Pretty-Printing
Resources
Don't worry, spiders,
I keep house
casually.
- Kobayashi Issa
The success of Perl is a tribute to the fact that many problems can be solved by using just its fundamental data types. Jon Bentley's books Programming Pearls and More Programming Pearls are further testament to how much can be achieved if the basic data structures are dynamic and memory management is automatic. But as programs become more complex, moving from the domain of the script to that of the application, there is an increasing need for representing data in much more complex ways than can sometimes be achieved with the basic data types alone.
In this chapter, we will apply the syntax and concepts learned in Chapter 1, Data References and Anonymous Storage to a few "real" examples. We will write bits of code that build complex structures from file-based data and use sequences of $ 's and @ 's without batting an eyelid. For each problem, we will examine different ways of representing the same data and study the trade-offs in program versus programmer efficiency. In the interest of clarity, we will not worry too much about error handling.
Tom Christiansen has written an excellent series of tutorials called FMTEYEWTK (Far More Than Everything You've Ever Wanted to Know!) [ 3 ]. This series contains a motley collection of topics that crop up on the Perl Usenet groups. I admire them for their lucid, patient, and detailed explanations and recommend that you read them at some point. (Now is better!) Some of them are now packaged with the Perl distribution; in particular, the perldsc (data structures cookbook) document is a tutorial for building and manipulating complex structures.
Before we start the examples, we will study what it takes to create structures � la C or C++.
2.1 User-Defined Structures
The struct declaration in C provides a notion of user-defined types (though it doesn't quite have first-class status, like an int ), and a typedef statement is then used to alias it to a new type name. Java and C++ have the class declaration to compose new data types out of fundamental data types. These constructs allow you to combine a bunch of named attributes under a single banner but still provide access to each individual attribute.
Perl has no such built-in template feature.[ 1 ] One commonly used convention is to simulate structures using a hash table, as shown in Figure 2.1 .
[1] We'll discuss a module called ObjectTemplate in Chapter 7, Object-Oriented Programming , that provides this.
Figure 2.1: Simulating C structures with Perl hashes
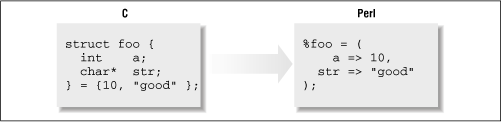
Perl's implementation of hash tables is actually quite efficient in terms of both performance and space. Since hash keys are immutable strings, Perl keeps only one systemwide copy of a hash key. This prevents a hundred foo structures from creating a hundred copies of the strings a and str .
Another way to create a user-defined collection of attributes is to use an array @foo instead, which is slightly more efficient, yet a tad more cumbersome:
$a = 0; $str = 1; # Indices $foo[$a] = 10; # Equivalent to foo.a = 10 in C. $foo[$str] = "hello"; # equivalent to foo.str = "hello" in C.
Remember, if a certain data structure is represented far more easily in C than in Perl and requires a considerable amount of manipulation, you could consider keeping it in C/C++ itself and not bother duplicating it in Perl. You will need to provide a set of C procedures that can manipulate this data. A very simple tool called SWIG (discussed in Chapter 18, Extending Perl:A First Course ) allows you to do this painlessly.
You can also use pack or sprintf to encode a set of values to get one composite entity, but accessing individual data elements is neither convenient nor efficient (in time). pack is a good option when you need to be frugal about space, because it converts a list of values into one scalar value without necessarily changing each individual item's machine representation; sprintf is less efficient in this regard, because it converts everything to a printable representation.
|
|

|
|
| 1.8 Resources |

|
2.2 Example: Matrices |