
1.3 Nested Data Structures
Recall that arrays and hashes contain only scalars; they cannot directly contain another array or hash as such. But considering that references can refer to an array or a hash and that references are scalars, you can see how one or more elements in an array or hash can point to other arrays or hashes. In this section, we will study how to build nested, heterogeneous data structures.
Let us say we would like to track a person's details and that of their dependents. One approach is to create separate named hash tables for each person:
%sue = ( # Parent
'name' => 'Sue',
'age' => '45');
%john = ( # Child
'name' => 'John',
'age' => '20');
%peggy = ( # Child
'name' => 'Peggy',
'age' => '16');
The structures for John and Peggy can now be related to Sue like this:
@children = (\%john, \%peggy);
$sue{'children'} = \@children;
# Or
$sue{'children'} = [\%john, \%peggy];
Figure 1.2 shows this structure after it has been built.
Figure 1.2: Mixing scalars with arrays and hashes.
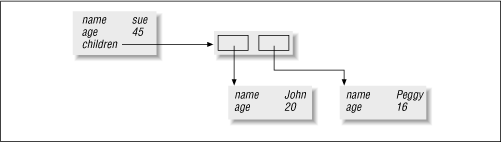
This is how you can print Peggy's age, given %sue :
print $sue{children}->[1]->{age};
1.3.1 Implicit Creation of Complex Structures
Suppose the first line in your program is this:
$sue{children}->[1]->{age} = 10;
Perl automatically creates the hash
%sue
, gives it a hash element indexed by the string
children
, points that entry to a newly allocated array, whose second element is made to refer to a freshly allocated hash, which gets an entry indexed by the string
age
. Talk about programmer efficiency.
1.3.2 Final Shortcut: Omit Arrows Between Subscripts
While on the subject of programmer efficiency, let us discuss one more optimization for typing. You can omit - > if (and only if) it is between subscripts. That is, the following expressions are identical:
print $sue{children}->[1]->{age};
print $sue{children}[1]{age};
This is similar to the way C implements multidimensional arrays, in which every index except the last one behaves like a pointer to the next level (or dimension) and the final index corresponds to the actual data. The difference - which doesn't really matter at a usage level - between C's and Perl's approaches is that C treats an n -dimensional array as a contiguous stream of bytes and does not allocate space for pointers to subarrays, whereas Perl allocates space for references to intermediate single-dimension arrays.
Continuing from where we left off, you will find that even such a simple example benefits from using anonymous arrays and hashes, rather than named ones, as shown in the following snippet:
%sue = ( # Parent
'name' => 'Sue',
'age' => '45',
'children' => [ # Anon array of two hashes
{ # Anon hash 1
'name' => 'John',
'age' => '20'
},
{ # Anon hash 2
'name' => 'Peggy',
'age' => '16'
}
]
);
This snippet of code contains only one named variable. The "children" attribute is a reference to an anonymous array, which itself contains references to anonymous hashes containing the children's details. This nesting can be as deep as you want; for example, you might represent John's educational qualifications as a reference to an anonymous array of hash records (each of which contain details of school attended, grade points, and so on). None of these arrays or hashes actually embed the next level hash or array; recall that the anonymous array and hash syntax yields references, which is what the containing structures see. In other words, such a nesting does not reflect a containment hierarchy. Try print values(%sue) to convince yourself.
It is comforting to know that Perl automatically deletes all nested structures as soon as the top-level structure ( %sue ) is deleted or reassigned to something else. Internal structures or elements that are are still referred to elsewhere aren't deleted.

|

|

|
| 1.2 Using References |

|
1.4 Querying a Reference |