|
|
11.2 IP: The Internet ProtocolThe Internet Protocol is the glue that holds together modern computer networks. IP specifies the way that messages are sent from computer to computer; it essentially defines a common "language" that is spoken by every computer stationed on the Internet. This section describes IPv4, the fourth version of the Internet Protocol, which has been used on the Internet since 1982. IPv4 is universally used today, and will likely see continued use for many years to come. IPv5 was an experimental protocol that was never widely used. IPv6 is the newest version of the Internet Protocol. IPv6 provides for a dramatically expanded address space, built-in encryption, and plug-and-play Internet connectivity. As this book goes to press, IPv6 is largely being used on an experimental basis, although use of this new Internet Protocol is increasing. Nevertheless, we expect IPv4 to be the dominant protocol version for many years to come. As we said earlier, at a very abstract level the Internet is similar to the phone network. However, looking more closely at the underlying protocols, we find that it is actually quite different. On the telephone network, each conversation is assigned a circuit (either a pair of wires or a channel on a multiplexed connection) that used for the duration of the telephone call. Whether you talk or not, the channel remains open until you hang up the phone. On the Internet, the connections between computers are shared by all of the conversations. Data is sent in blocks of characters called datagrams, or more colloquially, packets. Each packet has a small block of bytes called the header, which identifies the sender and intended destination on each computer. The header is followed by another, usually larger, block of characters of data called the packet's contents (see Figure 11-3). After the packets reach their destination, they are often reassembled into a continuous stream of data; this fragmentation and reassembly process is usually invisible to the user. As there are often many different routes from one system to another, each packet may take a slightly different path from source to destination. Because the Internet switches packets, instead of circuits, it is called a packet-switching network. Figure 11-3. IP header and packet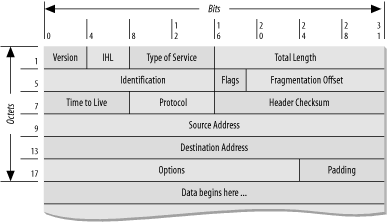 We'll borrow an analogy from Vint Cerf, one of the original architects of the ARPANET. Think of the IP protocol as sending a novel a page at a time, numbered and glued to the backs of postcards. All the postcards from every user are thrown together and carried by the same trucks to their destinations, where they are sorted. Sometimes, the postcards are delivered out of order. Sometimes, a postcard may not be delivered at all, but you can use the page numbers to request another copy. And, a key point for those concerned with security, anyone in the postal service who handles the post cards can read the contents without the recipient or sender knowing about it. There are four distinct ways to directly connect two computers using IP:
Figure 11-4. Connecting one computer to another with a telephone line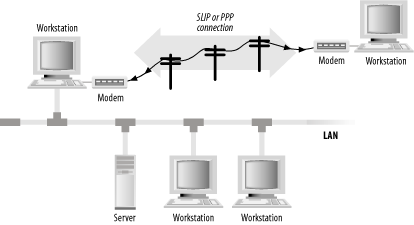 Figure 11-5. Connecting two local area networks with a pair of routers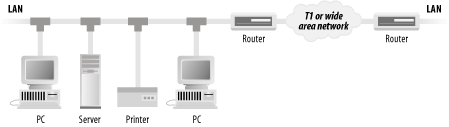 IP is a scalable network protocol: it works as well with a small office network of 10 workstations as it does with a university-sized network supporting a few thousand workstations, or with the national (and international) networks that support millions of computers.[6] IP scales because it views these large networks merely as collections of smaller ones. Computers connected to a network are called hosts. Computers that are connected to two or more networks can be programmed to forward packets automatically from one network to another; today, these computers are called routers (originally, they were called gateways). Routers use routing tables to determine where to send packets next.
11.2.1 Internet AddressesEvery interface that a computer has on an IPv4 network is assigned a unique 32-bit address. These addresses are often expressed as a set of four 8-bit numbers called octets. A sample address is 18.70.0.224. Think of an IP address as if it were a telephone number: if you know a computer's IP address, you can connect to it and exchange information.[7]
Theoretically, the 32-bit IP address allows a maximum of 232 = 4,294,967,296 computers to be attached to the Internet at a given time. In practice, the total number of computers that can be connected is much more than 232 because it is possible for many computers to share a single IP address through the use of technologies such as proxies and Network Address Translation. These multiple systems behind the single IP address can be configured with a variety of policies to govern connectivity between machines, allowing no access, restricted access, or unlimited access in either or both directions. Here are some sample Internet addresses:
IP addresses are typically abbreviated ii.jj.kk.ll, in which the numbers ii, jj, kk, and ll are between 0 and 255. This notation is sometimes called a dotted quad. Each decimal number represents an 8-bit octet. Together, they represent the 32-bit IP address. IP addresses can also be written as a single decimal number, although this notation is typically used only by people such as spammers who are attempting to obscure their Internet addresses. 11.2.1.1 IP networksThe Internet is a network of networks. Although many people think of these networks as being major networks, such as those belonging to companies like AT&T, WorldCom, and Sprint, most of the networks that make up the Internet are actually local area networks, such as the network in an office building or the network in a small research laboratory. Each of these small networks is given its own network number. There are two methods of looking at network numbers. The "classical" network numbers were distinguished by a unique prefix of bits in the address of each host in the network. This approach partitioned the address space into a well-defined set of differently sized networks. However, several of these networks had large "holes," which are sets of host addresses that were never used. With the explosion of sites on the Internet, a somewhat different interpretation of network addresses has been proposed, which allows more granularity in the assignment of network addresses and less waste. This approach is the Classless InterDomain Routing (CIDR) scheme. We briefly describe both schemes in the following sections. 11.2.1.2 Classical network addressesThere are five primary kinds of IP addresses in the "classical" address scheme; the first few bits of the address (the most significant bits) define the class of network to which the address belongs. The remaining bits are divided into a network part and a host part:
11.2.1.3 CIDR addressesIn recent years, a new form of address assignment has superseded traditional network address classes. This assignment is the CIDR method. As the name implies, there are no "classes" of addresses as in the classical scheme. Instead, networks are defined as being the most significant k bits of each address, with the remaining 32-k bits being used for the host part of the address. Thus, a service provider could be given a range of addresses whereby the first 14 bits of the address are fixed at a particular value (the network address), and the remaining 18 bits represent the portion of the address available to allocate to hosts. This method allows the service provider to allocate up to 218 distinct addresses to customers. CIDR networks are often abbreviated as the lowest IP address in the range, followed by a slash and the size, in bits, of the network portion. For example, the network 128.200.0.0/14 represents all of the IP addresses from 128.200.0.0 to 128.203.255.255. Another way that this network is often abbreviated is with the lowest IP address in the range, followed by a slash and the netmask, which is the dotted octet in which the k most significant bits are 1s and all others are 0s. In our example, this abbreviation would be 128.200.0.0/255.252.0.0. In reality, the host portion of an address is often further divided into subnets. This subdivision is done by fixing the first j bits of the host portion of the address to some set value, and using the remaining bits for host addresses. And those can be further divided into subnets, and so on. A CIDR-format address is of the form k.j.l.(m...n), in which each of the fields is of variable length. Thus, the fictional service-provider network address described above could be subdivided into 1,024 subnets, one for each customer. Each customer would have 28 bits of host address, which they could further subdivide into local subnets. The CIDR scheme is compatible with the classical address format, with Class A addresses using an 8-bit network field (e.g., 10.0.0.0/8), Class B networks using a 16-bit network address (e.g., 192.168.0.0/16), and so on. 11.2.2 RoutingDespite the complexity of the Internet and IP addressing, computers can easily send each other messages across the global network. To send a packet, most computers simply set the packet's destination address and then send the packet to a computer on their local network called a gateway. If the gateway makes a determination of where to send the packet next, the gateway is a router.[8] The router takes care of sending the packet to its final destination by forwarding the packet to a directly connected gateway that is (supposed to be) one step closer to the destination host.
Many organizations configure their internal networks as a large tree. At the root of the tree is the organization's connection to the Internet. When a gateway receives a packet, it decides whether to send it to one of its own subnetworks or direct it towards the root. Out on the Internet, major IP providers have far more complicated networks with sophisticated routing algorithms and specialized routing protocols. Many of these providers have redundant networks so that if one link malfunctions, other links can take over. Nevertheless, from the point of view of any computer on the Internet, routing is transparent, regardless of whether packets are being sent across the room or across the world. The only information that you need to know to make a connection to another computer on the Internet is the computer's 32-bit IPv4 address—you do not need to know the route to the host, or on what type of network the host resides. You do not even need to know if the host is connected by a high-speed local area network, or if it is at the other end of a modem-based PPP connection. All you need to know is the address of the destination, and your packets are on their way. Of course, if you are the site administrator and are configuring the routing on your system, you do need to be concerned with a little more than the IP number of a destination machine. You must know at least the addresses of the gateway or gateways out of your network and possibly set up a system for automatically choosing which gateway to use if there is more than one. We'll assume you know how to do that.[9]
11.2.3 HostnamesA hostname is the name of a computer on the Internet. Hostnames make life easier for users: they are easier to remember than IP addresses. You can change a computer's IP address but keep its hostname the same. If you think of an IP address as a computer's phone number, think of its hostname as the name under which it is listed in the telephone book. Some hosts can also have more than one address on more than one network. Rather than needing to remember each one, you can remember a single hostname and let the underlying network mechanisms pick the most appropriate addresses to use—or try all of them in sequence. This is so important that it needs to be repeated: a single hostname can have more than one IP address, and a single IP address can be associated with more than one hostname. Both of these facts have profound implications for people who are attempting to write secure network programs. 11.2.3.1 Format of the hostnameHostnames must begin with a letter or number and may contain letters, numbers, and a few symbols, such as the hyphen (-).[10] Case is ignored. A sample hostname is tock.cerias.purdue.edu. For more information on host names, see RFC 1122 and RFC 1123.
Each hostname has two parts: the computer's machine name and its domain. The computer's machine name is the name to the left of the first period; the domain name is everything to the right of the first period. In our example above, the machine name is tock, and the domain is cerias.purdue.edu. The domain name may represent further hierarchical domains if there is a period in the name. For instance, cerias.purdue.edu represents the CERIAS center domain, which is part of the Purdue University domain, which is, in turn, part of the Educational Institutions domain. Here are some other examples:
If you specify a machine name, but do not specify a domain, then your computer might append a default domain when it tries to resolve the name's IP address. Alternatively, your computer might simply return an "unknown host" error message. 11.2.3.2 The /etc/hosts fileEarly Unix systems used a single file named /etc/hosts to keep track of the network address for each host on the Internet. Many systems still use this file today to keep track of the IP addresses of computers on the organization's LAN. A sample /etc/hosts file for a small organization might look like this: # /etc/hosts # 192.42.0.1 server 192.42.0.2 art 192.42.0.3 science sci 192.42.0.4 engineering eng In this example, the computer named server has the network address 192.42.0.1. The computer named engineering has the address 192.42.0.4. The hostname sci following the computer named science means that sci can be used as a second name, or alias, for that computer. In the mid 1980s, the number of hosts on the Internet started to jump from thousands to tens of thousands and more. Maintaining a single file of hostnames and addresses soon proved to be impossible. Instead, the Internet adopted a distributed system for hostname resolution known as the Domain Name System (DNS). This is described in Section 11.2.6 later in this chapter. 11.2.4 Packets and ProtocolsToday there are four main kinds of IP packets that are sent on the Internet that will be seen by typical hosts. Each is associated with a particular protocol:[11]
11.2.4.1 ICMPThe Internet Control Message Protocol is used to send messages between gateways and hosts regarding the low-level operation of the Internet. For example, the ping command uses ICMP Echo packets to test for network connectivity; the response to an Echo packet is usually either an ICMP Echo Reply or an ICMP Destination Unreachable message type. Each ICMP packet contains a header that includes the following information:
Table 11-1 lists some typical ICMP packet types; some of these types are no longer used on the Internet, although many of them remain supported in most TCP/IP implementations. This has been an occasional source of security problems.
Although we have included all of these types for completeness, the most important types for our purposes are types 3, 4, and 5. An attacker can craft ICMP packets with these fields to redirect your network traffic, or perform a denial of service. Although the other packet types present less of an immediate risk, different versions of different operating systems often have subtly different responses to these ICMP packets, and attackers can use the pattern of responses to help "fingerprint" the operating system on your system to exploit known bugs. If you use a firewall, you should be sure that many ICMP packet types are blocked or monitored. You can generally safely block incoming ICMP packets of types 5, 13, 14, 17, and 18, and outgoing ICMP packets of types 5, 11, 12, 13, 14, 17, and 18. 11.2.4.2 TCPTCP provides a reliable, ordered, two-way transmission stream between two programs that are running on the same or different computers. "Reliable" means that every byte transmitted is guaranteed to reach its destination (or you are notified that the transmission failed), and that each byte arrives in the order in which it was sent. Of course, if the connection is physically broken, bytes that have not been transmitted will not reach their destination unless an alternate route can be found. In such an event, the computer's TCP implementation should send an error message to the process that is trying to send or receive characters, rather than give the impression that the link is still operational. Each TCP connection is attached at each end to a port. Ports are identified by 16-bit numbers. For most TCP protocols the server uses the port number assigned to the service it is providing, and the client's port number is randomly chosen by the client on a per-connection basis.[13] Some well-known port numbers are port 80 for HTTP servers and port 25 for SMTP servers.
On the wire, TCP packets are IP packets that include an additional TCP header. This header contains, among other things:
At any instant, every IPv4 connection on the Internet can be identified by a set of two 32-bit numbers and two 16-bit numbers:[14]
For example, Figure 11-6 shows three people on three separate workstations logged into a server using the ssh program. Each process's TCP connection starts on a different host and at a different originating port number, but each connection terminates on the same host (the server) and the same port (22). Figure 11-6. A few Internet connections with port numbers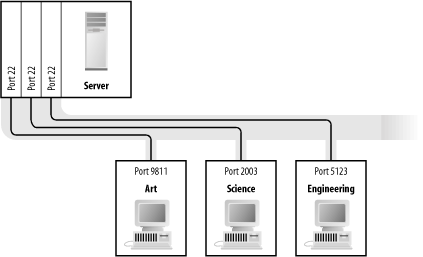 The idea that the workstations are all connecting to port number 22 can be confusing. Nevertheless, these are all distinct connections because each one is coming from a different originating host/port pair. The TCP protocol uses two special bits in the packet header, SYN and ACK, to negotiate the creation of new connections. To open a TCP connection, the requesting host sends a packet that has the SYN bit set but does not have the ACK bit set. The receiving host acknowledges the request by sending back a packet that has both the SYN and the ACK bits set. Finally, the originating host sends a third packet, again with the ACK bit set, but this time with the SYN bit unset. This process is called the TCP "three-way handshake," and is shown in Figure 11-7.[15] By looking for packets that have the ACK bit unset, one can distinguish packets requesting new connections from those that are sent in response to connections that have already been created. This distinction is useful when constructing packet filtering-firewalls.
Figure 11-7. The TCP/IP "three-way handshake"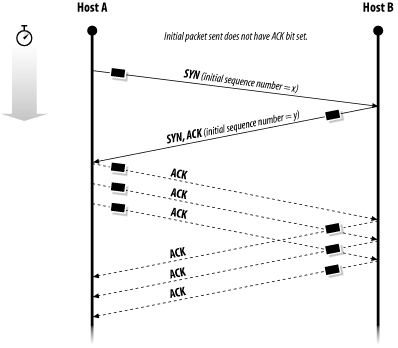 TCP is used for most Internet services that require the sustained synchronous transmission of a stream of data in one or two directions. For example, TCP is used for the hypertext transfer protocol (HTTP), remote terminal service, file transfer, and electronic mail. TCP is also used for sending commands to displays using the X Window system. Table 11-2 identifies some TCP services commonly enabled on Unix machines. These services and port numbers are usually found in the /etc/services file. (Note that non-Unix hosts can run all of these services as well as [or better than] a Unix host; protocols are independent of any underlying operating system or implementation.) Significant security problems of exploitable weaknesses have been found in the majority of them, as indicated in the notes and, in many cases, further detailed in Chapter 12.
11.2.4.3 UDPThe User Datagram Protocol provides a simple, unreliable system for sending packets of data between two or more programs running on the same or different computers. "Uunreliable" means that the operating system does not guarantee that every packet sent will be delivered, or that packets will be delivered in order. UDP does make a best effort to deliver the packets, however. On a LAN or uncrowded Internet path, UDP often approaches 100% reliability. UDP's advantage is that it has less overhead than TCP—less overhead lets UDP-based services transmit information with as much as 10 times the throughput. UDP is used primarily for Sun's Network Filesystem (NFS),[16] for NIS, for resolving hostnames, and for transmitting routing information. It is also used for services that aren't affected negatively if they miss an occasional packet because they will get another periodic update later, or because the information isn't really that important. For example, services such as rwho, talk, and some time services are in this category.
As with TCP, UDP packets are also sent from a port on the sending host to another port on the receiving host. Each UDP packet also contains user data. If a program is listening to the particular port and is ready for the packet, it will be received. If no program is listening, the packet will be ignored, and the receiving host will return an ICMP error message. If a program is listening but is not prepared to receive the packet, it may simply be queued and eventually received, or simply lost. In contrast to TCP packets, UDP packets can be broadcast, which causes them to be sent to the same port on every host that resides on the same local area network. Broadcast packets are used frequently for services such as time of day. Ports are identified by 16-bit numbers. Table 11-3 lists some common UDP ports.
11.2.5 Clients and ServersThe Internet Protocol is based on the client/server model. Programs called clients initiate connections over the network to other programs called servers, which wait for the connections to be made. One example of a client/server pair is the Network Time System. The client program is the program that asks the network server for the time. The server program is the program that listens for these requests and transmits the correct time. In Unix parlance, server programs that run in the background and wait for user requests are often known as daemons. Clients and servers are normally different programs. For example, if you wish to log onto another machine, you can use the ssh program: % ssh athens.com
password for simsong@athens.com:no34pass
Welcome to Athens.com.
FreeBSD 4.7
%
When you type ssh, the client ssh program on your computer connects to the ssh server (in this case, named sshd) running on the computer athens.com. As stated, clients and servers normally reside in different programs. One exception to this rule is the sendmail program, which includes the code for both the server and a client bundled together in a single application.[17]
You can connect to an arbitrary TCP/IP port of a computer using the telnet program. (The telnet program was originally used for logging into remote systems. However, as this requires sending an unencrypted password over the network, such use of the telnet program is now strongly discouraged.) For instance, you might connect to port 25 (the SMTP port) to fake some mail without going through the normal mailer: % telnet control.mil 25 Trying 45.1.12.2 ... Connected to hq.control.mil. Escape character is '^]'. 220 hq.control.mil ESMTP Sendmail 8.11.6/8.11.6; Sun, 18 Aug 2002 21:21:03 -0500 HELO kaos.org 250 hq.control.mil Hello kaos.org, pleased to meet you MAIL FROM:<agent86@control.mil> 250 <agent86>... Sender ok RCPT TO:<agent99@control.mil> 550 <agent99>... Recipient ok DATA 354 Enter mail, end with "." on a line by itself To: agent99 From: Max <agent86> Subject: tonight 99, I know I was supposed to take you out to dinner tonight, but I have been captured by KAOS agents, and they won't let me out until they finish torturing me. I hope you understand. Love, Max . 250 UAA01441 Message accepted for delivery quit 221 hq.control.mil closing connection Connection closed by foreign host. % 11.2.6 Name ServiceAs we mentioned, in the early days of the Internet, a single /etc/hosts file contained the address and name of each computer on the Internet. But as the file grew to contain thousands of lines, and as changes to the list of names (or the namespace) started being made on a daily basis, a single /etc/hosts file soon became impossible to maintain. Instead, the Internet developed a distributed network-based naming service called the Domain Name Service (DNS). DNS implements a large-scale distributed database for translating hostnames into IP addresses and vice-versa, and performing related name functions. The software performs this function by using the network to resolve each part of the hostname distinctly. For example, if a computer is trying to resolve the name girigiri.gbrmpa.gov.au, it would first get the address of the root domain server (usually stored in a file) and ask that machine for the address of the au domain server. The computer would then ask the au domain server for the address of the gov.au domain server, and then would ask that machine for the address of the gbrmpa.gov.au domain server. Finally, the computer would then ask the gbrmpa.gov.au domain server for the address of the computer called girigiri.gbrmpa.gov.au. (Name resolution is shown in Figure 11-8.) A variety of caching techniques are employed to minimize overall network traffic. Figure 11-8. The DNS tree hierarchy for name resolution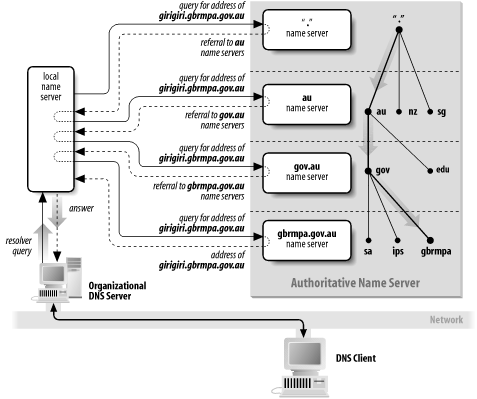 DNS hostname lookups are typically performed over UDP, but DNS also uses TCP for some operations. 11.2.6.1 DNS under UnixThe reference Unix implementation of DNS is named BIND.[18] It was originally written at the University of California at Berkeley and is now maintained by the Internet Software Consortium (ISC). This implementation is based on three parts: a library for the client side and two programs for the server:
More details about DNS and the BIND nameserver may be found in the book DNS and BIND by Paul Albitz and Cricket Liu (O'Reilly). 11.2.6.2 Other naming servicesIn addition to DNS, there are at least four vendor-specific systems for providing name service and other information to networked workstations. They are:
All of these systems are designed to distribute a variety of administrative information throughout a network. And all of them must use DNS to resolve hostnames outside the local organization. Another system used to provide information is the LDAP directory service. LDAP is intended as a lightweight (low overhead) and fast protocol. It is not secure by itself, but it can be run over an encrypted SSL tunnel. An LDAP server responds to database queries from other systems on the network. We describe LDAP in Chapter 14. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

|
|