|
|
This section explains the basis of branching strategies and the two main philosophies of branching. It also provides some answers to the question of when and why you should branch on a project.
The general rule of thumb for branching is: keep the main line of development on the trunk; everything else can be branched. The problem is determining the main line of development. Should the trunk contain stable code or unstable code? Should each release be branched when it goes to be tested? Should new features be developed on the trunk or on a branch?
These decisions all stem from two distinct definitions of "the main line of development." These two definitions result in two different branching philosophies, which can be termed basically stable and basically unstable.
The basically stable branching philosophy states that the trunk should contain project data that is always close to being ready for release. Branches are used for development, bug fixes, prerelease QA (quality assurance), and refactoring. Branches are also used for experimental code.
The strictest variation of this philosophy states that nothing should be merged to the trunk until it has been through QA. This ensures that at any time a release candidate can be taken from the trunk, put through a small amount of QA, and then published or sold.
More lenient variations of this philosophy allow anything that passes developer unit-testing to be merged into the trunk. Such a relaxed approach requires a release candidate to be branched off and put through a full QA analysis before publication.
Advantages of the basically stable method include the following:
You can take a release off the trunk at any time, run it through QA, and publish it.
Because the trunk contains stable code that changes slowly, you can perform experimental work on a branch with little likelihood of causing errors in someone else's work when the branch is merged back into the trunk.
The greatest disadvantage of the basically stable philosophy is that merging usually gets done by a QA tester rather than by a person who understands the semantics of the code being merged. Also, the trunk may change significantly between the original time a branch was split off from it and the time the branch is merged back. Both of these problems can be reduced by having the developer merge the trunk to the branch periodically, or by using a less strict variation.
The basically unstable philosophy states that the trunk should contain the latest code, regardless of its stability, and that release candidates should be branched off for QA.
The strictest variation states that all development takes place on the trunk and branches are used only for release candidates, bugfix branches, and releases.
More lenient variations also allow branching for experimental code, refactoring, and other special-case code. Merging of a branch back into the trunk is done by the managers of the branch.
The advantage of this philosophy is that merging doesn't happen often and is easier to do because it is usually done by people familiar with the code.
The disadvantage of this philosophy, especially when applied in its strictest form, is that the main trunk often contains buggy code, experimental work, and sometimes code that doesn't compile at all. Frequent tagging can reduce this disadvantage, so tag every time there's good code or whenever someone starts to experiment or refactor. The more lenient variations keep the buggiest code and the code most likely to cause significant breakage off the trunk, reducing the time it takes to prepare a release for publication.
CVS includes code to create and use branches, but it doesn't enforce any particular technique for using them. This section explains several styles for using branches.
In this section, the term long branch is used to mean either ongoing branches or branches that merge several times and then are no longer used. A short branch is a branch that is merged back to the trunk once and never again used.
CVS permits a branch to be activated again at any time; it has no way of saying a branch is no longer valid. Ending a branch is done simply by telling all developers that it will never again be used for active development.
An ongoing branch for which the trunk merges repeatedly to the branch is useful for situations in which the trunk should not be affected by changes in the branch, but the branch needs changes from the trunk. Mirror web sites may use this method. See Figure 4-6 for an illustration of how this method works.

An ongoing branch that merges repeatedly to the trunk is useful in situations in which the branch should not be affected by ongoing trunk development, but the trunk needs changes made in the branch. Any situation in which a branch is being tested and prepared for publication can use this branch style. Projects that are in testing can use this method, putting the content that is being tested on the branch and merging corrections back to the trunk. See Figure 4-7.

A long branch that merges in both directions ensures that changes from the branch are integrated to the trunk and that changes in the trunk are integrated into the branch. If the developers working on the branch are doing ongoing development of unstable code, the branch can be merged back to the trunk when each stage is completed, and the branch can be synchronized with changes from the trunk whenever the branch developers are prepared to merge those changes. This method can be useful when mature code is being rewritten one section at a time, while new features are being added on the trunk. See Figure 4-8.

A short branch can be a standalone branch used for a simple change. If you want to add a single feature, write experimental code, or prepare for a release, a short, single-purpose branch may be ideal.
You can also use a series of short branches to simulate a long branch merged to and from the trunk. By using a series of short branches, you avoid having to merge branch changes to the trunk and then trunk changes to the branch. Instead, you merge changes from a branch to the trunk, and then start a new branch from the trunk. This method may be useful when both the trunk and the branch have significant changes. See Figure 4-9.
CVS permits you to create branches off of branches. You then treat the root branch as a trunk and manage the subbranch using any of the branch styles discussed in the preceding sections. Nested branches are most useful when using CVS for configuration management. Minimize the nesting complexity to reduce confusion.
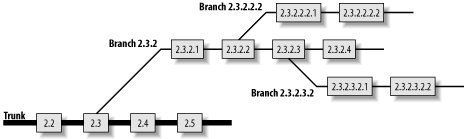
If you are writing a new set of features on a branch and need to give a feature to a tester while you continue to work on the branch, you can create a test branch off your feature branch. Figure 4-10 shows a set of nested branches off a trunk.
Consistent policies can help ensure that branching assists your project. Without consistent rules, you may end up with a mess of branches that are difficult to keep track of.
Having and using consistent policies can also help you keep merging as simple as possible. Minimizing the amount of merging requires communication between the developers working on the branch and those working on the trunk.
Develop policies that work for your projects and your team. The following policies are ones that my coworkers and I have found useful:
Have an overall design for the project.
Ensure that each branch has a definite purpose and minimize the number of currently active branches.
Minimize the complexity of your branching scheme. CVS permits nested branches, but there are few situations where multiple layers of nesting help a project.
Use a consistent branch-naming scheme that expresses the purpose of each branch.
Be aware of semantic differences between a branch and the trunk; good design and good communication can reduce these differences.
An example of semantic difference is when a developer has changed the number (or worse, the order) of parameters in a function and other developers call the function with the old parameters.
Avoid binary files where possible, to allow CVS to merge files automatically.
Merge back frequently; the fewer changes there are to the trunk, the easier they are to merge.
Tag the branch at every merge point, so you can avoid merging the same changes twice.
Tag the trunk at every branch point and just before and after every merge, in case you need to retrieve the trunk state at that time.
Use consistent tag-naming schemes for the tags associated with the branches.
|
|
| Top |