
7.2 Text Processing
The enormous popularity of Perl is due in large part to its sophisticated text processing capabilities. A single Perl command can replace dozens of PL/SQL INSTR and SUBSTR operations. Additionally, Perl's pattern matching capabilities are well suited for processing and validating the text entered into HTML forms.
The PL/SQL toolkit has two packages that bring a subset of these capabilities to PL/SQL. The first, OWA_TEXT, manipulates large chunks of text. The second, OWA_PATTERN, allows developers to use sophisticated search patterns to perform many of the text operations found in Perl.
Beyond their mere utility, these two packages are interesting examples of good package design. OWA_TEXT is similar to the abstract datatypes described in Chapter 6, PL/SQL . OWA_PATTERN builds on OWA_TEXT to create dozens of variations of the search and replace procedure, each useful in particular circumstances.
7.2.1 OWA_TEXT: Representing Text
The largest PL/SQL string can contain 32,767 characters. Unfortunately, there are many cases where we might like to process larger chunks of text. A document indexing system, for example, must almost certainly process files much larger than 32K.[ 1 ] The OWA_TEXT package overcomes the 32K limitation by breaking text streams into smaller pieces that are stored as elements in a PL/SQL array.
[1] The human resources dress code guidelines at some companies probably exceed a megabyte.
Additionally, it is often useful to treat the components of a string as a single entity (e.g., a sentence as an array of words). OWA_TEXT is ideal for this type of application. In practice, though, you'll probably not use OWA_TEXT directly; instead, it's used to provide more flexibility to the OWA_PATTERN package discussed later in this chapter.
7.2.1.1 Data structures
OWA_TEXT's specification declares four data structures. The first two, vc_arr and int_arr, are PL/SQL arrays that are the building blocks of the more complex types. vc_arr is a 32K string array; int_arr holds indexes to the interesting rows of vc_arr. The declarations for these two datatypes are:
TYPE vc_arr IS TABLE OF VARCHAR2(32767) INDEX BY BINARY_INTEGER; TYPE int_arr IS TABLE OF INTEGER INDEX BY BINARY_INTEGER;
The third data structure, called multi_line, is used to store information about an entire text stream. multi_line contains three fields: a vc_arr array to hold the individual rows of the stream, an integer to hold the number of rows in the vc_arr array, and a Boolean flag to indicate the presence of a partial row. Its declaration is:
TYPE multi_line IS RECORD ( rows vc_arr, num_rows INTEGER, partial_row BOOLEAN );
The fourth data structure, row_list, is used to represent pointers into the rows in a multi_line structure. This structure is generally used by other toolkit packages, such as OWA_PATTERN, discussed later in this chapter. The declaration for the row_list structure is:
TYPE row_list IS RECORD ( rows int_arr, num_rows INTEGER );
7.2.1.2 Procedures
The procedures in OWA_TEXT define a limited set of operations similar to those of a classic linked list. There are procedures to create a new multi_line structure, to add a new row onto the end of an existing structure, and even to print its contents. Table 7.4 summarizes these procedures:
|
Parameters |
Description |
|
|---|---|---|
|
ADD2MULTI |
stream IN VARCHAR2 mline OUT multi_line continue IN BOOLEAN DEFAULT TRUE |
Appends the passed stream to the multi_line structure. If the continue flag is TRUE, the stream is appended to the last line of the multi_line array. If FALSE, the stream is appended as the last row. |
|
mline OUT multi_line |
Creates a new, blank multi_line. There is also a functionalized version that returns an empty structure. |
|
|
rlist IN row_list |
Creates a new row_list structure. The command can be used as either a procedure or a function. |
|
|
mline IN multi_line |
Prints the content of the multi_line data structure using HTP.PRINT. |
|
|
rlist IN row_list |
Prints the row_list using HTP.PRINT. |
|
|
stream IN VARCHAR2 mline OUT multi_line |
Converts a VARCHAR2 into a multi_line. |
7.2.1.3 Example
Let's look at a quick example that illustrates OWA_TEXT in action. The following procedure, TOKENIZE, uses OWA_TEXT to break apart and print the individual words in a sentence:
CREATE OR REPLACE PROCEDURE tokenize (
sentence IN VARCHAR2 DEFAULT NULL
)
IS
mline OWA_TEXT.multi_line;
i NUMBER;
n NUMBER := LENGTH (sentence);
c VARCHAR2(1);
BEGIN
OWA_TEXT.new_multi (mline); -- Initialize the structure
FOR i IN 1 .. n
LOOP
c := SUBSTR (sentence, i, 1); -- Fetch current character
IF c = ' '
THEN
-- Add a new row if the character is a space
OWA_TEXT.add2multi (c, mline, FALSE);
ELSE
-- Otherwise, append the character to the string
OWA_TEXT.add2multi (c, mline);
END IF;
END LOOP;
/*
|| Print individual words in sentence
*/
FOR i IN 1 .. mline.num_rows
LOOP
HTP.print ('Word ' || i || ' is ');
HTP.print (mline.rows (i) || '<br>');
END LOOP;
END;
The following HTML form is used to test the procedure; note how the
<textarea>
tag is used to supply the value for the sentence parameter.
<html>
<title>Test tokenizer procedure</title>
<body>
Enter the text to tokenize:
<form action="http://gandalf/agent_webtest/plsql/tokenize">
<textarea name=sentence>Enter sentence here</textarea>
<p>
<input type=submit>
</form>
</body>
</html>
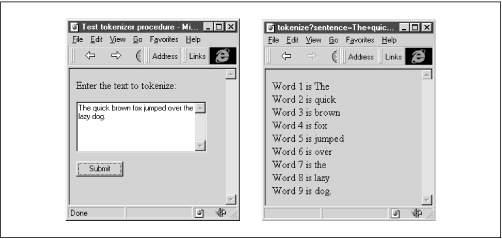
Figure 7.2 shows the results of the TOKENIZE procedure. The image on the left shows the form used to submit the sentence; the image on the right shows the corresponding output generated by TOKENIZE.
Figure 7.2: Results of the TOKENIZE procedure
7.2.1.4 Design note
In a classic ADT, such as the stack presented in Chapter 6 , the datatypes would be hidden within the package body and would be accessible only through a programmatic interface. While this information hiding approach gives the developer strict control over how the package is used, it also makes it difficult to extend the package.
Although it seems like an obscure issue, the placement of the declaration has a profound impact on the life of the package. Declaring everything in the specification can make the package unwieldy and hard to maintain. The other extreme, declaring everything in the body and making nothing accessible, results in a package that is rigid and difficult to use in new circumstances.
OWA_TEXT resolves this tension admirably. By placing the declarations in the specification, the developers are consciously creating a general-purpose object that other packages can use. However, the package also contains a well-defined, private set of procedures that limit the operations that can be performed against its structures. In the next section, we'll see how the package is used to extend the toolkit's pattern searching capabilities.
7.2.2 OWA_PATTERN: Searching and Replacing Text
The OWA_PATTERN package is the second component of our text processing unit. As its name implies, OWA_PATTERN performs more complex text manipulation than is possible with PL/SQL's INSTR and SUBSTR functions. Regular expressions make this sophistication possible.
7.2.2.1 Regular expressions
A
regular expression
, or RegExp, is a compact description for a pattern of characters used to find matches within another string. Chances are you have used a simple RegExp to perform wildcard file searches using commands such as
dir
*.sql
or
ls
*.sql
. In these searches, instead of looking for a specific file, you are looking for any file that matches the
.sql
extension. In this case, the RegExp translates to the sentence "Any string of characters that ends in
.sql
."
You can use regular expressions to create more sophisticated patterns. For example, suppose you want to take some action if any date appears within a string; you are only interested in its presence and do not know its value ahead of time. Clearly, the following INSTR test is not very effective:
IF INSTR (some_string, '07/13/71') OR INSTR (some_string, '07/14/71') OR INSTR (some_string, '07/15/71') OR INSTR (some_string, '07/16/71') ...
What you are really after is a pattern consisting of three sets of two digits separated by slashes (for clarity, assume the date is always DD-MM-YY). A regular expression is a mini-language that uses a compact vocabulary to describe these patterns.
The first part of the RegExp vocabulary defines the different types of characters that can be matched, such as digits, letters, or tabs. These characters are sometimes called atoms because they form the basic building blocks on which the expressions are based. The atoms that can be used in OWA_PATTERN are shown in Table 7.5 .
|
Atom |
Description |
|---|---|
|
. |
Any character except newline (\n) |
|
\n |
Newline |
|
\t |
Tab |
|
\d |
Any digit (0 . . . 9) |
|
\D |
Any non-digit |
|
\w |
Any alphanumeric character (0 . . . 9, a . . . z, A . . . Z) |
|
\W |
Any nonalphanumeric character |
|
\s |
Any whitespace character (space, tab, or newline) |
|
\S |
Non-whitespace character |
|
\b |
Word boundary |
|
\x nn |
Character having the hexadecimal value nn (i.e., \x20 is a space) |
|
\ nnn |
Character having the octal value nnn (i.e., \040 is a space) |
|
\ c |
Any character matching c |
The next part of the vocabulary defines how many characters must appear to constitute a match. For example, we may want to return a match only if there are exactly two consecutive digits. The characters in this set are called the quantifiers ; the possibilities for them are shown in Table 7.6 .
|
Quantifier |
Description |
|---|---|
|
? |
Exactly zero or one occurrence of an atom |
|
* |
Zero or more occurrences of an atom |
|
+ |
One or more occurrences of an atom |
|
{ n } |
Exactly n occurrences of an atom |
|
{ n ,} |
At least n occurrences of an atom |
|
{ n,m } |
At least n , but not more than m , occurrences of an atom |
There are two possible assertions , or sets of characters used to fix the position of a match, as shown in Table 7.7 .
|
Description |
|
|---|---|
|
^ |
Match must come at the start of the string. |
|
$ |
Match must come at the end of the string. |
Finally, the vocabulary of the regular expression contains a set of flags that are used to control the behavior of the search. Unlike the atoms, quantifiers, and assertions, these flags are not included as part of the RegExp itself. Instead, they are passed as a separate parameter to control how the various OWA_TEXT procedures behave. The two available flags are shown in Table 7.8 .
|
Description |
|
|---|---|
|
I |
The search is not case sensitive. |
|
g |
Used in the change procedure to specify a global search and replace. |
There are additional special characters that remember the portions of the original string that was matched. The first special character, the ampersand (&), can be used during the replace phase of a search and replace operation. The & represents the original pattern found in a match; including it in a replace string recreates the original string of characters that matched the pattern. The second special character is a pair of parentheses. When a portion of a match sequence is enclosed in parentheses, the subsequent replace operation can remember each parenthesized match. These remembered strings are called back references (backrefs) and are stored in an array.
7.2.2.2 Data structures
You must supply a regular expression to each function in OWA_PATTERN. Initially, the pattern is stored as a simple VARCHAR2 string. In order to use the expression, however, OWA_PATTERN transforms it into a more useful format. This relatively time-consuming process converts the regular expression from a VARCHAR2 into a PL/SQL array, using the following declaration:
TYPE pattern IS TABLE OF VARCHAR2(4) INDEX BY BINARY_INTEGER;
Like many of the other data structures we've seen, pattern datatypes are initialized by calling a procedure. In this case, the procedure is called GET_PAT. There are two parameters to this procedure. The first is a VARCHAR2 string called arg that holds the regular expression to be parsed. The second is a pattern datatype (declared as an IN OUT mode parameter) to hold the resultant parsed pattern.
In the next section, we'll see once again how the toolkit's developers intentionally placed the declaration in the specification and not the body, even though it's a purely internal representation. This time, however, the intent is to improve the package's performance as well as its usability.
7.2.2.3 Procedures and functions
In addition to GET_PAT, the OWA_PATTERN package contains three other basic functions: MATCH, AMATCH, and CHANGE. In an attempt to match the enormous flexibility of Perl, each function has several overloaded versions that derive from the data structures found in OWA_TEXT. For example, the MATCH function can search either a simple VARCHAR2 string or the more complex multi_line data structure. This is a great example of the power and flexibility a good package can provide.
However, with 14 variations of just three functions, OWA_PATTERN reveals an API that just might be too complex. The next three sections describe the functions for this package, shown in Table 7.9 . Keep in mind that some of these functions are like the finches on the Galapagos Islands: very specialized.
|
Procedure/Function |
Parameters |
Description |
|---|---|---|
|
AMATCH |
See Table 7.11 for details on overloaded versions. |
Returns the position of the end of the first RegExp found within text |
|
CHANGE |
See Table 7.12 for details on overloaded versions. |
Replaces matched pattern with a new string |
|
GET_PAT |
arg IN VARCHAR2 pat IN OUT pattern |
Initializes a datatype |
|
MATCH |
See Table 7.10 for details on overloaded versions. |
Returns a Boolean value indicating whether a RegExp was found inside text |
7.2.2.3.1 The MATCH function.
This function returns a Boolean value indicating whether a regular expression was found inside a chunk of text. There are six overloaded versions. The parameters for this function are:
- line/mline
-
The text that is being searched, either a VARCHAR2 or an OWA_TEXT.MULTI_LINE (in the latter case, the parameter is renamed mline).
- pat
-
The regular expression, either a VARCHAR2 or a pattern. If used as a pattern, the structure must be initialized with the GET_PAT procedure before it is passed as a parameter.
- flags
-
Controls the behavior of the search as described in Table 7.8 ; a VARCHAR2.
- backrefs
-
Optional parameter to hold back references when parentheses are used as part of the regular expression; an OWA_TEXT.VC_ARR.
- rlist
-
Identifies the rows in which a match was found; an OWA_TEXT.ROW_LIST (mandatory when the line parameter is an OWA_TEXT.MULTI_LINE).
Table 7.10 lists the formal parameters for each of the different versions of MATCH.
|
Version |
Parameters |
Description |
|---|---|---|
|
1 |
line IN VARCHAR2 pat IN VARCHAR2 flags IN VARCHAR2 DEFAULT NULL |
The simplest of the versions; all parameters are VARCHAR2. |
|
2 |
line IN VARCHAR2 pat IN OUT pattern flags IN VARCHAR2 DEFAULT NULL |
multiple searches that use the same RegExp. |
|
3 |
line IN VARCHAR2 pat IN VARCHAR2 backrefs OUT owa_text.vc_arr flags IN VARCHAR2 DEFAULT NULL |
Version 1 with the optional backrefs parameter. When the function completes, the backrefs array contains the portions of the original string that matched the parentheses. |
|
4 |
line IN VARCHAR2 pat IN VARCHAR2 backrefs OUT owa_text.vc_arr flags IN VARCHAR2 DEFAULT NULL |
Version 2 with the optional backrefs parameter. |
|
5 |
mline IN owa_text.multi_line pat IN VARCHAR2 rlist OUT owa_text.row_list flags IN VARCHAR2 DEFAULT NULL |
In this version, the text string is a multi_line datatype rather than a VARCHAR2. The mline parameter must be initialized using the procedures described in the OWA_TEXT section. |
|
6 |
mline IN owa_text.multi_line pat IN OUT pattern rlist OUT owa_text.row_list flags IN VARCHAR2 DEFAULT NULL |
Same as version 5, but the pat parameter is declared as a pattern structure. |
7.2.2.3.2 The AMATCH function.
This function is similar to MATCH, except that it returns the position of the end of the first match found within the string.[ 2 ] The function returns if no match is found. There are four overloaded versions; the parameters for each version are:
[2] INSTR, a similar function that's built into PL/SQL, returns the position of the first character of a match.
- line
-
The text that is being searched; unlike the MATCH function, it is always a VARCHAR2.
- from_loc
-
Starting position within the string for the search.
- pat
-
The regular expression, either a VARCHAR2 or a pattern. If used as a pattern, the structure must be initialized with the GET_PAT procedure before it is passed as a parameter.
- flags
-
Controls the behavior of the search as described in Table 7.8 ; a VARCHAR2.
- backrefs
-
Optional parameter to hold back references when parentheses are used as part of the regular expression; an OWA_TEXT.VC_ARR.
Table 7.11 lists the four versions of AMATCH.
|
Version |
Parameters |
Description |
|---|---|---|
|
1 |
line IN VARCHAR2 from_loc IN INTEGER pat IN VARCHAR2 flags IN VARCHAR2 DEFAULT NULL |
The simplest of the versions; all parameters are VARCHAR2. |
|
2 |
line IN VARCHAR2 from_loc IN INTEGER pat IN OUT pattern flags IN VARCHAR2 DEFAULT NULL |
In this version, the pat parameter is declared using the PATTERN datatype. |
|
3 |
line IN VARCHAR2 from_loc IN INTEGER pat IN VARCHAR2 backrefs OUT owa_text.vc_arr flags IN VARCHAR2 DEFAULT NULL |
Version 1 with the optional backrefs parameter. |
|
4 |
line IN VARCHAR2 from_loc IN INTEGER pat IN pattern backrefs OUT owa_text.vc_arr flags IN VARCHAR2 DEFAULT NULL |
Version 2 with the optional backrefs parameter. |
7.2.2.3.3 CHANGE.
The CHANGE function or procedure searches a chunk of text for a pattern. When it finds a match, it replaces the matched substring with a new string. When used as a procedure, CHANGE simply updates the text with the appropriate matches. When used as a function, it makes the changes and returns the number of substitutions.
This second usage is questionable. When a function changes the value of a parameter, it violates the most important rule about functions: that a function should return exactly one value. By updating the parameters, CHANGE is essentially returning two values: one for the number of updates and another for the actual results of that update. Including an OUT mode parameter to the procedural version would probably have been a better design.
The parameters used in each version are:
- line/mline
-
The text that is being searched and replaced; either a VARCHAR2 or an OWA_TEXT.MULTI_LINE (in the latter case, the parameter is renamed mline).
- from_str
-
String to be replaced; always a VARCHAR2. Note that although the string represents a regular expression like the pat parameter in the MATCH and AMATCH functions, it cannot be used as a PATTERN datatype.
- to_str
-
The string that replaces from_str; always a VARCHAR2. An & character, when used anywhere in the string, is replaced by the original portion of the text line that matches the from_str pattern.
- flags
-
Controls the behavior of the search as described in Table 7.8 ; a VARCHAR2. If no value is specified (the default), only the first match is replaced. If the value "g" is used, it replaces all the matches.
Table 7.12 lists the four versions of CHANGE.
|
Version |
Parameters |
Description |
|---|---|---|
|
1 |
line IN OUT VARCHAR2 from_str IN VARCHAR2 to_str IN VARCHAR2 flags IN VARCHAR2 |
Function that returns the number of substitutions made. After the function exits, the line parameter is updated with the results of the search and replace. |
|
2 |
line IN OUT VARCHAR2 from_str IN VARCHAR2 to_str IN VARCHAR2 flags IN VARCHAR2 |
Procedural version of version 1. |
|
3 |
mline IN OUT owa_text.multi_line from_str IN VARCHAR2 to_str IN VARCHAR2 flags IN VARCHAR2 |
Function that returns the number of substitutions made; the target text is declared as a multi_line structure. |
|
4 |
mline IN OUT owa_text.multi_line from_str IN VARCHAR2 to_str IN VARCHAR2 flags IN VARCHAR2 |
Procedural version of version 4. |
7.2.2.4 Example
As you can imagine, there are a lot of possible examples for the OWA_PATTERN package. However, it's not necessary to detail every one. Instead, let's focus on a single example, based on the CHANGE procedure, that allows you to test the effect of various regular expressions in search and replace operations.
The example procedure, regexp_test, accepts the parameters of version 1 of CHANGE and builds an HTML table that breaks the final page into two columns. The first column contains a data entry form with the fields necessary to test the CHANGE procedure. The second column displays the results of the CHANGE procedure when it is executed with the regexp_test procedure's parameters.
The interesting thing about this procedure is that it preserves the values entered when the user submits the form. This is accomplished by setting the form
action
attribute back to the regexp_test procedure. When the form is submitted, the procedure reconstructs the form using the input from the previous screen:
CREATE OR REPLACE PROCEDURE regexp_test (
line IN OUT VARCHAR2 DEFAULT NULL,
from_str IN VARCHAR2 DEFAULT NULL,
to_str IN VARCHAR2 DEFAULT '<b>&</b>',
flags IN VARCHAR2 DEFAULT NULL
)
IS
BEGIN
HTP.print ('<html><title>Pattern Test</title><body>');
HTP.print ('<table border=1><tr><td>'); -- Used to format results
HTP.print ('<form action=regexp_test>');
HTP.print ('Line:<textarea name=line>' ||
line ||
'</textarea><br>');
HTP.print ('From:<input name=from_str value="' ||
from_str ||
'"><br>');
HTP.print ('To:<input name=to_str value="' ||
to_str ||
'"><br>');
HTP.print ('Flags:<input name=flags value="' ||
flags ||
'"><br>');
HTP.print ('<input type=submit>');
HTP.print ('</form></td><td>'); -- Results print in second column
-- Call the change procedure
OWA_PATTERN.change (line, from_str, to_str, flags);
HTP.print (line_copy);
HTP.print ('</td></tr></html>');
END;
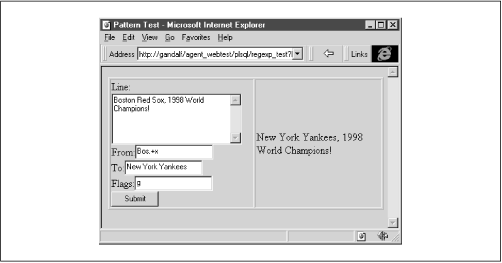
Figure 7.3 shows the output of the regexp_test procedure.
Figure 7.3: The results of the regexp_test procedure

|

|

|
| 7.1 Communicating with the Outside World |

|
7.3 Maintaining State |

Copyright (c) 2000 O'Reilly & Associates. All rights reserved.