
15.3 The Anonymous PL/SQL Block
When someone wishes to remain anonymous, that person goes unnamed. So it is with the anonymous PL/SQL block. Unlike the other two types of PL/SQL blocks (the procedure and the function), the anonymous block has no name associated with it. In fact, the anonymous block is missing the header section altogether. Instead it simply uses the DECLARE reserved word to mark the beginning of its optional declaration section.
Figure 15.4: An anonymous block without declaration and exception sections
Figure 15.5: An anonymous block defined inside a procedure

Without a name, the anonymous block cannot be called by any other block -- it doesn't have a handle for reference. Instead, anonymous blocks serve as scripts that execute PL/SQL statements, including calls to procedures and functions. Anonymous blocks can also serve as nested blocks inside procedures, functions, and other anonymous blocks, as shown in Figure 15.5 .
Because an anonymous block can have its own declaration and exception sections, developers use anonymous blocks to provide a scope for identifiers and exception handling within a larger program.
15.3.1 The Structure of an Anonymous Block
The general format of an anonymous PL/SQL block is as follows:
[ DECLARE ... optional declaration statements ... ] BEGIN ... executable statements ... [ EXCEPTION ... optional exception handler statements ... ] END;
The square brackets indicate an optional part of the syntax. As you can see, just about everything in an anonymous block is optional. You must have BEGIN and END statements and you must have at least one executable statement.
15.3.2 Examples of Anonymous Blocks
The following examples show the different combinations of block sections, all of which comprise valid PL/SQL blocks:
-
A block with BEGIN-END terminators, but no declaration or exception sections:
BEGIN hiredate := SYSDATE; END
-
An anonymous block with a declaration section, but no exception section:
DECLARE right_now DATE := SYSDATE; BEGIN hiredate := right_now; END
-
An anonymous block containing declaration, execution, and exception sections:
DECLARE right_now DATE := SYSDATE; too_late EXCEPTION; BEGIN IF :employee.hiredate < ADD_MONTHS (right_now, 6) THEN RAISE too_late; ELSE :employee.hiredate := right_now; END IF; EXCEPTION WHEN too_late THEN DBMS_OUTPUT.PUT_LINE ('You no longer qualify for free air.'); WHEN OTHERS THEN DBMS_OUTPUT.PUT_LINE ('Error encountered: ' || SQLCODE); END;
Anonymous blocks execute a series of statements and then terminate, thus acting like procedures. In fact, all anonymous blocks are anonymous block procedures.
15.3.3 Anonymous Blocks in the Oracle Tools
Anonymous blocks are used in Oracle tools where PL/SQL code is either executed immediately (SQL*Plus) or attached directly to objects in that tool environment (see Table 15.1 ). That object then provides the context or name for the PL/SQL code, making the anonymous block both the most appropriate and the most efficient way to attach programmatic functionality to the object.
|
Object Type |
Environment |
Description |
|---|---|---|
|
Trigger |
Oracle Developer/2000 |
Place PL/SQL code directly in the Oracle Forms or Oracle Reports trigger, which is then packaged as an anonymous block by the tool and sent to the PL/SQL engine. |
|
Database trigger |
Record or column of table |
The body of the trigger is coded in PL/SQL. While the trigger has a name, the PL/SQL code itself is unnamed, hence anonymous. |
|
Script |
SQL*Plus and SQL*DBA |
Ad hoc programs and batch processing scripts written in SQL*Plus are always anonymous blocks (which may then call procedures or functions). |
|
Embedded PL/SQL programs |
Pro* embedded languages |
Embed PL/SQL blocks to execute statements inside the database server. |
Whenever you attach PL/SQL code to a trigger or field in a tool, that code forms an anonymous PL/SQL block. When you write this code you can enter a fully specified PL/SQL block (declaration, execution, and exception sections), or you can enter only the executable section.
15.3.4 Nested Blocks
PL/SQL allows you to nest or embed anonymous blocks within another PL/SQL block. You can also nest anonymous blocks within anonymous blocks for more than one level, as shown in Figure 15.6 .
Figure 15.6: Anonymous blocks nested three levels deep
15.3.4.1 Nested block terminology
A PL/SQL block nested within another PL/SQL block may be called by any of the following: nested block, enclosed block, child block or sub-block.
A PL/SQL block that calls another PL/SQL block (anonymous or named) may be referred to as either the enclosing block or the parent block.
15.3.4.2 Nested blocks provide scope
The general advantage of a nested block is that you create a scope for all the declared objects and executable statements in that block. You can use this scope to improve your control over activity in your program. For a discussion, see Section 15.3.5, "Scope and Visibility" later in this chapter.
Consider the following procedure, in which the president and vice-president of the specified company request their salaries be cut in half if their current salaries are more than ten times the average salary in the company. It's the sort of incentive plan that would encourage executives to "share the wealth."
PROCEDURE update_management
(company_id_in IN NUMBER, avgsal_in IN NUMBER)
IS
BEGIN
-- The vice-president shows his generosity...
BEGIN
SELECT salary INTO v_sal
FROM employee
WHERE company_id = company_id_in
AND title = 'VICE-PRESIDENT';
IF v_sal > avgsal_in * 10
THEN
UPDATE employee SET salary := salary * .50
WHERE company_id = company_id_in
AND title = 'VICE-PRESIDENT';
ELSE
DBMS_OUTPUT.PUT_LINE ('The VP is OK!');
END IF;
EXCEPTION
WHEN NO_DATA_FOUND THEN NULL;
END;
-- The president shows her generosity...
BEGIN
SELECT salary INTO v_sal
FROM employee
WHERE company_id = company_id_in
AND title = 'PRESIDENT';
IF v_sal > avgsal_in * 10
THEN
UPDATE employee SET salary := salary * .50
WHERE company_id = company_id_in
AND title = `PRESIDENT';
ELSE
DBMS_OUTPUT.PUT_LINE ('The Prez is a pal!');
END IF;
EXCEPTION
WHEN NO_DATA_FOUND THEN NULL;
END;
END;
Each of the two SELECT-UPDATE combinations is embedded in its own anonymous PL/SQL block. Each block has its own exception section. Why go to all this trouble? Why couldn't the programmer just create a little script that will update the salary for a specified title? The following statement, saved to the updemp.sql file, would "do the trick" (&N is the syntax used to supply arguments to a SQL*Plus script):
UPDATE employee SET salary := salary * .50 WHERE company_id = &1 AND title = '&2' AND salary > &3 * 10;
and then execute the SQL script in SQL*Plus using the START command:
SQL> start updemp 1100 VICE-PRESIDENT SQL> start updemp 1100 PRESIDENT
The programmer who was assigned this task took several things into account:
-
The executives might decide they will want to take such actions repeatedly in the coming years; better to package the steps into a reusable chunk of code like a procedure than simply execute a series of SELECT-UPDATEs in SQL*Plus.
-
Executives come and go frequently at the company. There is no guarantee that there will be a person in the employee table with a title of `PRESIDENT' or `VICE-PRESIDENT' at any given time. The first assumption argues for the encapsulation of these two SELECT-UPDATE steps into a procedure. This second assumption results in the need for embedded PL/SQL blocks around each UPDATE statement. Suppose that the procedure update_management did not make use of the embedded blocks. The code would then look like this:
PROCEDURE update_management (company_id_in IN NUMBER, avgsal_in IN NUMBER) IS BEGIN SELECT salary INTO v_sal FROM employee WHERE company_id = company_id_in AND title = 'VICE-PRESIDENT'; IF v_sal > avgsal_in * 10 THEN UPDATE employee SET salary := salary * .50 WHERE company_id = company_id_in AND title = 'VICE-PRESIDENT'; ELSE DBMS_OUTPUT.PUT_LINE ('The VP is OK!'); END IF; SELECT salary INTO v_sal FROM employee WHERE company_id = company_id_in AND title = 'PRESIDENT'; IF v_sal > avgsal_in * 10 THEN UPDATE employee SET salary := salary * .50 WHERE company_id = company_id_in AND title = 'PRESIDENT'; ELSE DBMS_OUTPUT.PUT_LINE ('The Prez is a pal!'); END IF; END;
If there is a record in the employee table with the title of "VICE-PRESIDENT" (for the appropriate company_id) and if there is a record in the employee table with the title of "PRESIDENT," then this procedure works just fine. But what if there is no record with a title of "VICE-PRESIDENT"? What if the Vice-President did not want to take a 50% cut in pay and instead quit in disgust?
When the WHERE clause of an implict SELECT statement does not identify any records, PL/SQL raises the NO_DATA_FOUND exception (for more details on this phenomenon see Chapter 6, Database Interaction and Cursors , and pay particular attention to the sections concerning implicit cursors). There is no exception handler section in this procedure. As a result, when there is no Vice-President in sight, the procedure will immediately complete (well, abort, actually) and transfer control to the calling block's exception section to see if the NO_DATA_FOUND exception is handled there. The SELECT-UPDATE for the President's salary is therefore not executed at all.
NOTE: You don't actually need a BEGIN-END block around the second SELECT-UPDATE. This is the last statement, and if it fails nothing will be skipped. It is good practice, however, to include an exception statement for the procedure as a whole to trap errors and handle them gracefully.
Our programmer would hate to see an executive's wish go unfulfilled, so we need a mechanism to trap the failure of the first SELECT and allow PL/SQL procedure execution to continue on to the next SELECT-UPDATE. The embedded anonymous block offers this protection. By placing the first SELECT within a BEGIN-END envelope, you can also define an exception section just for the SELECT. Then, when the SELECT fails, control is passed to the exception handler for that specific block, not to the exception handler for the procedure as a whole (see Figure 15.7 ). If you then code an exception to handle NO_DATA_FOUND which allows for continued processing, the next SELECT-UPDATE will be executed.
Figure 15.7: An anonymous block "catches" the exception

15.3.4.3 Named modules offer scoping effect of nested block
You can also restructure the update_management procedure to avoid the problems addressed in the previous section, and also the redundancy in the code for that procedure. The following version of update_management uses an explicit cursor to avoid the problem of the NO_DATA_FOUND exception being raised. It also encapsulates the repetitive logic into a local or nested procedure.
PROCEDURE update_management
(company_id_in IN NUMBER, avgsal_in IN NUMBER, decr_in IN NUMBER)
IS
CURSOR salcur (title_in IN VARCHAR2)
IS
SELECT salary
FROM employee
WHERE company_id = company_id_in
AND title = title_in
AND salary > avgsal_in * 10;
PROCEDURE update_exec (title_in IN VARCHAR2)
IS
salrec salcur%ROWTYPE;
BEGIN
OPEN salcur (title_in);
FETCH salcur INTO salrec;
IF salcur%NOTFOUND
THEN
DBMS_OUTPUT.PUT_LINE ('The ' || title_in || ' is OK!');
ELSE
UPDATE employee SET salary := salary * decr_in
WHERE company_id = company_id_in
AND title = title_in;
END IF;
CLOSE salcur;
END;
BEGIN
update_exec ('VICE-PRESIDENT');
update_exec ('PRESIDENT');
END;
This final version also offers the advantage of consolidating the two SELECTs into a single explicit cursor, and the two UPDATEs into a single statement, thereby reducing the amount of code one would have to test and maintain. Whether you go with named or anonymous blocks, the basic concept of program (and therefore exception) scope remains the same. Use the scoping and visibility rules to your advantage by isolating areas of code and cleaning up the program flow.
15.3.5 Scope and Visibility
Two of the most important concepts related to a PL/SQL block are those of the scope and visibility of identifiers. An identifier is the name of a PL/SQL object, which could be anything from a variable to a program name. In order to manipulate a PL/SQL identifier (assign a value to it, pass it as a parameter, or call it in a module), you have to be able to reference that identifier in such a way that the code will compile.
The scope of an identifier is the part of a program in which you can make a reference to the identifier and have that reference resolved by the compiler. An identifier is visible in a program when it can be referenced using an unqualified name.
15.3.5.1 Qualified identifiers
A qualifier for an identifier can be a package name, module name (procedure or function), or loop label. You qualify the name of an identifer with dot notation, the same way you would qualify a column name with the name of its table.
The names of the following identifiers are qualified:
- :GLOBAL.company_id
-
A global variable in Oracle Forms
- std_types.dollar_amount
-
A subtype declared in a package
The scope of an identifier is generally the block in which that identifier is declared. The following anonymous block declares and then references two local variables:
DECLARE first_day DATE; last_day DATE; BEGIN first_day := SYSDATE; last_day := ADD_MONTHS (first_day, 6); END;
Both the first_day and last_day variables are visible in this block. When I reference the variables in the assignment statements, I do not need to qualify their names. Also, the scope of the two variables is precisely this anonymous block.
I cannot make reference to either of those variables in a second anonymous block or in a procedure. Any attempt to do so will result in a compile failure, because the reference to those variables cannot be resolved.
If an identifier is declared or defined outside of the current PL/SQL block, it is visible (can be referenced without a qualifier) only under the following conditions:
-
The identifier is the name of a standalone procedure or function on which you have EXECUTE privilege. You can then include a call to this module in your block.
-
The identifier is declared in a block which encloses the current block.
15.3.5.2 Scope and nested blocks
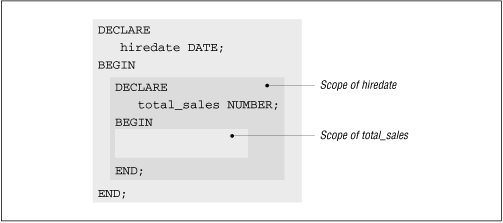
Let's take a closer look at nested blocks and the impact on scope and visibility. When you declare a variable in a PL/SQL block, then that variable is local to that block, but is visible in or global to any blocks defined within the first, enclosing block. For example, in the following anonymous block, the variable last_date can be referenced anywhere inside the block:
/* The enclosing or outer anonymous block. */
DECLARE
last_date DATE;
BEGIN
last_date := LAST_DAY (SYSDATE);
/* The inner anonymous block. */
BEGIN
IF last_date > :employee.hire_date
THEN
...
END IF;
END;
...
END;
Even though last_date is not defined in the inner block, it can still be referenced there without qualification because the inner block is defined inside the outer block. The last_date variable is therefore considered a global variable in the inner block.
Figure 15.8 shows additional examples illustrating the concept of scope in PL/SQL blocks.
Figure 15.8: Scope of identifiers in PL/SQL blocks
15.3.5.3 Qualifying identifier names with module names
When necessary, PL/SQL offers many ways to qualify an identifier so that a reference to the identifier can be resolved. Suppose I create a package called company_pkg and declare a variable named last_company_id in that package's specification, as follows:
PACKAGE company_pkg IS last_company_id NUMBER; ... END company_pkg;
Then, when I reference that variable outside of the package, I must preface the identifer name with the package name:
IF new_company_id = company_pkg.last_company_id THEN ...
Because a variable declared in a package specification is global in your session, the last_company_id variable can be referenced in any program, but it is not visible unless it is qualified.
I can also qualify the name of an identifier with the module in which it is defined:
PROCEDURE calc_totals
IS
salary NUMBER;
BEGIN
...
DECLARE
salary NUMBER;
BEGIN
salary := calc_totals.salary;
END;
...
END;
The first declaration of salary creates an identifier whose scope is the entire procedure. Inside the inner anonymous block, however, I declare another identifer with the same name. So when I reference the variable "salary" inside the inner block, it will always be resolved first against the declaration in the inner block, where that variable is visible without any qualification. If I wish to make reference to the procedure-wide salary variable inside the inner block, I must qualify that variable name with the name of the procedure.
PL/SQL goes to a lot of trouble and has established many rules for determining how to resolve such naming conflicts. While it is good to be aware of such issues, you would be much better off never having to rely on these guidelines. Use unique names for your identifiers in different blocks so that you can avoid naming conflicts altogether.
15.3.5.4 Cursor scope
To use a cursor, you must declare it. But you cannot refer to that cursor -- whether to OPEN, CLOSE, or FETCH from it -- unless that cursor is accessible in your current PL/SQL block. The scope of a cursor is that part of a PL/SQL program in which you can refer to the cursor.
You can refer to a cursor in the code block in which it was declared and in all blocks defined within that declaring block. You cannot refer to the cursor outside of the declaring block unless the cursor is declared in a package (see Chapter 16, Packages , for more information on global variables and cursors). For example, if a cursor is declared in the get_employees procedure (see below) and within get_employees a second PL/SQL block is defined to calculate total compensation for each employee, the cursor and its attributes may still be referenced in that calculation block:
PROCEDURE get_employees
IS
CURSOR emp_cur IS
SELECT employee_id, sal + bonus FROM employee;
BEGIN
OPEN emp_cur;
DECLARE
empid NUMBER;
total_comp NUMBER;
BEGIN
FETCH emp_cur INTO empid, total_comp;
IF total_comp < 5000
THEN
MESSAGE (' I need a raise!');
END IF;
END;
END;
If, on the other hand, the cursor is declared within an inner block, then that cursor cannot be referenced in an outer block. In the next procedure, the outer block declares the variables that receive the data fetched from the cursor. The inner block declares the cursor. While the inner block can open the cursor without error, the FETCH statement is outside the scope of the cursor-declaring block and will therefore fail:
PROCEDURE get_employees IS
empid NUMBER;
total_comp NUMBER;
BEGIN
DECLARE
CURSOR emp_cur IS
SELECT employee_id, sal + bonus FROM employee;
BEGIN
OPEN emp_cur;
END;
/* This fetch will not be able to identify the cursor. */
FETCH emp_cur INTO empid, total_comp; -- INVALID!
IF total_comp < 5000
THEN
MESSAGE (' I need a raise!');
END IF;
END;
The rules for cursor scope are, therefore, the same as those for all other identifiers.
15.3.6 Block Labels
Anonymous blocks don't have names under which they can be stored in the database. By using block labels, however, you can give a name to your block for the duration of its execution. A block label is a PL/SQL label which is placed directly in front of the first line of the block (either the DECLARE or the BEGIN keyword). You might use block labels for either of these reasons:
-
Improve the readability of your code. When you give something a name, you self-document that code. You also clarify your own thinking about what that code is supposed to do, sometimes ferreting out errors in the process.
-
Qualify the names of elements declared in the block to distinguish between references to elements with a different scope, but the same name.
A PL/SQL label has this format:
<<identifer>>
where identifier is a valid PL/SQL identifier (up to 30 characters in length, starting with a letter; see Section 2.2, "Identifiers" in Chapter 2 in Chapter 2, PL/SQL Language Fundamentals , for a complete list of rules).
Let's look at a couple of examples of applying block labels. In the first example, I place a label in front of my block simply to give it a name and document its purpose:
<<calc_dependencies>>
DECLARE
v_senator VARCHAR2(100) := 'THURMOND, JESSE';
BEGIN
IF total_contributions (v_senator, 'TOBACCO') > 25000
THEN
DBMS_OUTPUT.PUT_LINE ('We''re smokin''!');
END IF;
END;
In the next example, I use my block labels to allow me to reference all variables declared in my outer and inner blocks:
<<tobacco_dependency>>
DECLARE
v_senator VARCHAR2(100) := 'THURMOND, JESSE';
BEGIN
IF total_contributions (v_senator, 'TOBACCO') > 25000
THEN
<<alochol_dependency>>
DECLARE
v_senator VARCHAR2(100) := 'WHATEVERIT, TAKES';
BEGIN
IF tobacco_dependency.v_senator =
alcohol_dependency.v_senator
THEN
DBMS_OUTPUT.PUT_LINE
('Maximizing profits - the American way of life!');
END IF;
END;
END IF;
END;
I have used my block labels in this case to distinguish between the two different v_senator variables. Without the use of block labels, there would be no way for me to reference the v_senator of the outer block within the inner block. Of course, I could simply give these variables different names, the much-preferred approach.

|

|

|
| 15.2 Review of PL/SQL Block Structure |

|
15.4 Procedures |

Copyright (c) 2000 O'Reilly & Associates. All rights reserved.