
10.9 Working with PL/SQL Tables
The remainder of this chapter provides you with lots of examples of ways to use PL/SQL tables in your applications.
10.9.1 Transferring Database Information to PL/SQL Tables
You cannot use a SQL SELECT statement to transfer data directly from a database table to a PL/SQL table. You need to take a programmatic approach. A cursor FOR loop usually makes the most sense for this process, which requires the following steps:
-
Define a PL/SQL table TYPE for each datatype found in the columns of the database table.
-
Declare PL/SQL tables which will each receive the contents of a single column.
-
Declare the cursor against the database table.
-
Execute the FOR loop. The body of the loop will contain a distinct assignment of one column into one PL/SQL table.
In PL/SQL Release 2.3, this process would be much simpler. You could define a PL/SQL table with the same structure as the database table by creating a table-based record. Prior to that release, unfortunately, you need a separate PL/SQL table for each column. You do not, on the other hand, need a separate table TYPE for each column. If you have two date columns, for example, you can declare two separate PL/SQL tables both based on the same TYPE.
In the following example I load the company ID, incorporation date, and filing date from the database table to three different PL/SQL tables. Notice that there are only two types of PL/SQL tables declared:
/* Filename on companion disk: db2tab1.sql (see db2tab2.sql for the PL/SQL Release 2.3 version of same transfer) */
DECLARE
/* The cursor against the database table. */
CURSOR company_cur
IS
SELECT company_id, incorp_date, filing_date FROM company;
/* The PL/SQL table TYPE and declaration for the primary key. */
TYPE company_keys_tabtype IS
TABLE OF company.company_id%TYPE NOT NULL
INDEX BY BINARY_INTEGER;
company_keys_table primary_keys_tabtype;
/* Sincle PL/SQL table TYPE for two different PL/SQL tables. */
TYPE date_tabtype IS
TABLE OF DATE
INDEX BY BINARY_INTEGER;
incorp_date_table date_tabtype;
filing_date_table date_tabtype;
/* Variable to keep track of number of rows loaded. */
num_company_rows BINARY_INTEGER := 0;
BEGIN
/* The cursor FOR loop */
FOR company_rec IN company_cur
LOOP
/* Increment to the next row in the two, coordinated tables. */
num_company_rows := num_company_rows + 1;
/* Set the row values for ID and dates. */
company_keys_table (num_company_rows) := company_rec.company_id;
incorp_date_table (num_company_rows) := company_rec.incorp_date;
filing_date_table (num_company_rows) := company_rec.filing_date;
END LOOP;
END;
10.9.2 Data-Smart Row Numbers in PL/SQL Tables
As I've mentioned, one of the most interesting and unusual aspects of the PL/SQL table is its sparseness. I can have a value in the first row and in the 157th row of the table, with nothing in between. This feature is directly related to the fact that a PL/SQL table is unconstrained. Because there is no limit on the number of rows in a table, PL/SQL does not set aside the memory for that table at the time of creation, as would normally occur with an array.
When you use the PL/SQL table to store and retrieve information sequentially, this sparse quality doesn't have any real significance. The ability to store data nonsequentially can, however, come in very handy. Because the row number does not have to be sequentially generated and used, it can represent data in your application. In other words, it can be "data-smart."
Suppose you want to use a PL/SQL table to store the text of messages associated with numeric error codes. These error codes are patterned after Oracle error codes, with ranges of values set aside for different aspects of the application: 1000-1999 for employee-related errors, 5000-5999 for company-related errors, etc. When a user action generates an error, the error number is passed to a procedure which then looks up and displays the message. By storing this information in PL/SQL tables, you avoid a lookup against the remote database.
Let's take a look at sequential and indexed access to implement this functionality.
10.9.2.1 Sequential, parallel storage
One possible way to implement this procedure is to create two tables: one that holds the error codes (stored sequentially in the table) and another that holds the messages (also stored sequentially). When an error is encountered, the procedure scans sequentially through the PL/SQL table of codes until it finds a match. The row in which the code is found is also the row in the PL/SQL message table; it uses the row to find the message and then displays it. Figure 10.2 shows the correlation between these two tables.
Figure 10.2: Using sequential access to correlate contents of two tables
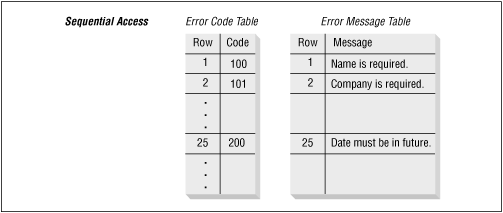
The code needed to implement this algorithm is shown in the following procedure. The procedure assumes that the two PL/SQL tables have already been loaded with data. The error_pkg.last_row variable is the last row containing an error code:
/* Filename on companion disk: seqretr.sp */
PROCEDURE display_error (errcode_in IN NUMBER)
IS
matching_row BINARY_INTEGER := 1;
keep_searching BOOLEAN := error_pkg.last_row > 0;
BEGIN
WHILE keep_searching
LOOP
/* Does the current row match the specified error code? */
IF error_pkg.error_codes_table (matching_row) = errcode_in
THEN
DBMS_OUTPUT.PUT_LINE
(error_pkg.error_messages_table (matching_row));
keep_searching := FALSE;
ELSE
/* Move to the next error code in the table */
matching_row := matching_row + 1;
keep_searching := matching_row <= error_pkg.last_row;
END IF;
END LOOP;
END;
A straightforward, sensible approach, right? Yes and no. Yes, it is straightforward. No, in the context of the PL/SQL table, it is not sensible. This module insists on performing a sequential scan when such a step is not necessary.
10.9.2.2 Using the index as an intelligent key
A much simpler way to accomplish this same task is to use the error code itself as the primary key value for the row in the error messages table. Then I need only one table -- to hold the error messages (see Figure 10.3 ).
Figure 10.3: Using indexed access to retrieve value with intelligent key row
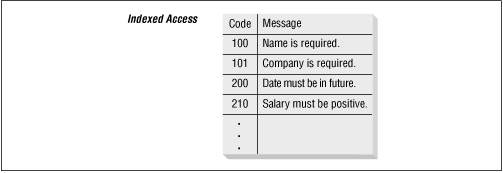
Instead of matching the error code and then using the primary key to locate the corresponding message, the error code is itself the index into the PL/SQL table. By using a single table and data-smart values for the primary key, the display_error procedure boils down to the code shown below:
/* Filename on companion disk: indretr.sp */
PROCEDURE display_error (errcode_in IN NUMBER) IS
BEGIN
/*
|| Deceptively simple: use the error code as the row, retrieve
|| the message, and display it. All in one statement!
*/
DBMS_OUTPUT.PUT_LINE
(error_pkg.error_messages_table (errcode_in));
EXCEPTION
/*
|| Just in case an undefined error code is passed to the
|| procedure, trap the failure in the exception section.
*/
WHEN NO_DATA_FOUND
THEN
DBMS_OUTPUT.PUT_LINE
('No match found for error code = ' || TO_CHAR (errcode_in));
END;
It has taken me a while to fully internalize the difference between a PL/SQL table and an array. I have had to go back and rewrite several packages and procedures once I realized that I had done it again, treating the PL/SQL table like a sequential access data structure.
So if you ever find yourself reading sequentially through a PL/SQL table, take a step back and consider what data you need to obtain and how it is being stored. Sometimes you do need to store data sequentially (when you use a PL/SQL table, for example, to implement a stack data structure). Frequently, however, you can simplify your life and your code by using data-smart values in your PL/SQL table.
10.9.3 Displaying a PL/SQL Table
When you work with PL/SQL tables, you often want to verify the contents of the table. The usual verification method is to display the contents of each row using DBMS_OUTPUT. This sounds like a simple enough task. In the most basic scenario where you have a sequentially filled table, the code is indeed straightforward.
The following procedures shows the small amount of code required to display a table which has rows 1 through n defined, where n is passed as a parameter to the procedure. The procedure displays a VARCHAR2 table; to display DATE or NUMBER tables, you simply need to use TO_CHAR to convert the value in the call to PUT_LINE:
/* Filename on companion disk: disptab1.sp */
PROCEDURE display_table
(table_in IN <the_table_type>, -- Placeholder for real table type.
number_of_rows_in IN INTEGER)
IS
BEGIN
/* For each row in the table ... */
FOR table_row IN 1 .. number_of_rows_in
LOOP
/* Display the message, including the row number */
DBMS_OUTPUT.PUT_LINE
('Value in row ' || TO_CHAR (table_row) || ': ' ||
table_in (table_row));
END LOOP;
END;
To put this display_table module to use, you will need to create a different version of this procedure for each different type of table, because the table is passed as a parameter. That table's type must be declared in the parameter list in place of the <the_table_type> text.
Of course, not all PL/SQL tables can be filled in ways which are displayed as easily as the one shown above. To start with, the display_table procedure makes many assumptions about its table profile (although very few tables actually fit this profile). These include the following:
-
The first defined row of the table is row one. The FOR loop always starts at one.
-
All rows between one and number_of_rows_in are defined. There is no exception handler for NO_DATA_FOUND.
-
The number_of_rows_in is a positive number. The loop does not even consider the possibility of negative row numbers.
Very few PL/SQL tables actually fit this profile. Even a traditional, sequentially filled table might start its rows at some arbitrary value; a PL/SQL table might be sparsely filled; you might know the starting row (lowest value) and the ending row (maximum value), but not really know which of the rows between those end points are defined. A table with the Oracle error codes would have all of these characteristics.
10.9.3.1 A flexible display_table procedure
It is possible to build a version of display_table which takes into account all of these variations in a PL/SQL table's structure. For example:
-
The program must be supplied with both a starting and an ending row for the scan through the table.
-
The program also needs to be told how many times it should encounter and handle an undefined row as it scans the table.
-
display_table needs a parameter which specifies the increment by which it loops through the table. This increment can be negative, which would allow you to scan in reverse through the rows of the table.
By incorporating all of this input, the header for display_table becomes:
PROCEDURE display_table
(table_in IN <the_table_type>,
end_row_in IN INTEGER ,
start_row_in IN INTEGER := 1,
failure_threshold_in IN INTEGER := 0,
increment_in IN INTEGER := +1)
where the parameters are defined as:
- table_in
-
The table to be displayed. Again, you would need a different version of this program for each different table type you want to display.
- end_row_in
-
The last row that is defined in the table. If sequentially filled from row 1, this value would simply be the maximum number of rows.
- start_row_in
-
The starting row defined in the table. The default is 1.
- failure_threshold_in
-
The number of times the procedure will raise the NO_DATA_FOUND exception before it stops scanning through the table. The default is zero, which means that the first time it tries to access an undefined row it will stop.
- increment_in
-
The amount by which the row counter is incremented as the procedure scans through the table. The default is +1. If you know that every 15th row is defined, you can pass 15 and avoid the NO_DATA_FOUND exceptions. If your rows are negative, as with Oracle error codes, specify -1 for the increment and the procedure will then scan backwards through the table.
This version of display_table shown in the following example displays both sequentially filled and sparsely filled PL/SQL tables. When I use the new display_table to view the contents of a sequentially filled table, the call to the procedure looks exactly the same as in the first version:
display_table (customer_tab, num_customers);
If I store the Oracle error codes in my table, then I can take advantage of all these different parameters to view only the errors dealing with the date functions (-01800 through -01899) with the following command:
display_table (ora_errors_tab, -1899, -1800, 100, -1);
My end row is -1899 and my start row is -1800. I allow the procedure to access up to 100 undefined rows, because not all of these values are currently defined. I know that this is enough because the full range is only 100. Finally, I tell display_table to read backwards through the table, as is appropriate given the negative values of the rows.
10.9.3.2 Examples of display_table output
To test the display_table procedure I created a package named dt which declared a VARCHAR2 table type named string_tabletype and defined the procedure. I then built the SQL*Plus script shown in the example below. Notice that I use three substitution variables (&1, &2, and &3):
DECLARE t dt.string_tabletype; BEGIN t(1) := 'hello'; t(2) := 'world!'; t(11) := 'I hope'; t(21) := 'we make it'; t(22) := 'to the year'; t(75) := '2000.'; dt.display_table (t, &1, &2, &3); END; /
Here are some of the results of my test scripts:
SQL> start disptab 100 1 100 Value in row 1: hello Value in row 2: world! Value in row 11: I hope Value in row 21: we make it Value in row 22: to the year Value in row 75: 2000. SQL> start disptab 100 1 50 Value in row 1: hello Value in row 2: world! Value in row 11: I hope Value in row 21: we make it Value in row 22: to the year Exceeded threshold on undefined rows in table. SQL> start disptab 2 1 0 Value in row 1: hello Value in row 2: world! SQL> start disptab 3 1 0 Value in row 1: hello Value in row 2: world! Exceeded threshold on undefined rows in table. SQL> start disptab 50 10 50 Value in row 11: I hope Value in row 21: we make it Value in row 22: to the year
10.9.3.3 Implementation of display_table
The first argument in display_table is a PL/SQL table. Because there is no such thing as a generic PL/SQL table structure, you will need to create a version of this procedure for each of your tables. Alternatively, you could create a generic program which handles all the logic in this program which does not rely on the specific table. Then each of your PL/SQL table-specific versions could simply call that generic version.
/* Filename on companion disk: disptab2.sp */
PROCEDURE display_table
(table_in IN <the_table_type>,
end_row_in IN INTEGER ,
start_row_in IN INTEGER := 1,
failure_threshold_in IN INTEGER := 0,
increment_in IN INTEGER := +1)
IS
/* The current row displayed as I scan through the table */
current_row INTEGER := start_row_in;
/* Tracks number of misses, compared to threshold parameter. */
count_misses INTEGER := 0;
/* Used in WHILE loop to control scanning thru table. */
within_threshold BOOLEAN := TRUE;
/*----------------------- Local Module ------------------------*/
|| Determine if specified row is within range. I put this
|| into a function because I need to see which direction I
|| am scanning in order to determine whether I'm in range.
*/
FUNCTION in_range (row_in IN INTEGER) RETURN BOOLEAN IS
BEGIN
IF increment_in < 0
THEN
RETURN row_in >= end_row_in;
ELSE
RETURN row_in <= end_row_in;
END IF;
END;
BEGIN
/* The increment cannot be zero! */
IF increment_in = 0
THEN
DBMS_OUTPUT.PUT_LINE
('Increment for table display must be non-zero!');
ELSE
/*
|| Since I allow the user to pass in the amount of the increment
|| I will switch to a WHILE loop from the FOR loop. I keep
|| scanning if (1) have not reached last row and (2) if I have
|| not run into more undefined rows than allowed by the
|| threshold parameter.
*/
WHILE in_range (current_row) AND within_threshold
LOOP
/*
|| I place call to PUT_LINE within its own anonymous block.
|| This way I can trap a NO_DATA_FOUND exception and keep on
|| going (if desired) without interrupting the scan.
*/
BEGIN
/* Display the message, including the row number */
DBMS_OUTPUT.PUT_LINE
('Value in row ' || TO_CHAR (current_row) || ': ' ||
table_in (current_row));
/* Increment the counter as specified by the parameter */
current_row := current_row + increment_in;
EXCEPTION
WHEN NO_DATA_FOUND
THEN
/*
|| If at the threshold then shut down the WHILE loop by
|| setting the Boolean variable to FALSE. Otherwise,
|| increment the number of misses and current row.
*/
within_threshold := count_misses < failure_threshold_in;
IF within_threshold
THEN
count_misses := count_misses + 1;
current_row := current_row + increment_in;
END IF;
END;
END LOOP;
/*
|| If I stopped scanning because of undefined rows, let the
|| user know.
*/
IF NOT within_threshold
THEN
DBMS_OUTPUT.PUT_LINE
('Exceeded threshold on undefined rows in table.');
END IF;
END IF;
END;
By spending the time to think about the different ways a developer might want to display a table and the different kinds of tables to be displayed, and by adding the parameters necessary to handle these scenarios, I have transformed a very simple and limited procedure into a generic and useful program. While the more generic code is significantly more complex than that in the original display_table, I have to write it (and test it) only once. From then on, I simply substitute an actual table type.
10.9.4 Building Traditional Arrays with PL/SQL Tables
As I've mentioned, neither PL/SQL nor any other component of the Oracle product set supports true arrays. You cannot, for example, declare a two-dimensional array which is manipulated with statements such as the following:
company (2,3) := '100 Main St'; min_profits := financial_matrix (profit_row, min_column);
For years developers have complained about the lack of support for arrays. Although tables serve some of the same purposes as arrays, they are not equivalent. You can use a PL/SQL table as an array, but only one that is single-dimensional. If you need to make use of the more common two-dimensional array, such as a 10 � 10 array composed of 100 cells, then a PL/SQL table -- all on its own -- will not do the trick. You can, however, build a layer of code which will emulate a traditional n � m array based on the PL/SQL table data structure.
NOTE: This implementation relies on the PL/SQL package structure, which is covered in Chapter 16, Packages . If you are not familiar yet with packages, you may want to read through that chapter before diving into this exploration of array emulation.
10.9.4.1 Obstacles to implementing arrays
The first time I tried to implement such an array structure with PL/SQL tables, I gave up, thinking that it simply wasn't possible. My strategy had been to create a table for each of the n columns in the array. A 2 � 3 array would, in other words, consist of three different tables of the same type, as shown in Figure 10.4 . The problem with this approach is that I could not dynamically generate the name of a PL/SQL table at runtime.
Suppose I supplied you with a function in which you specified the number of rows and columns in your array. You would expect to have a pointer to the array of that size returned to you. I can certainly return to you a pointer to a single PL/SQL table; it would simply be declared at the start of the function. If the array was made up of an arbitrary number of tables, however, I could not declare each of these as they were needed.
Figure 10.4: Three tables supporting a 2 � 3 array

I was about to give up when I realized that, oddly enough, the elements of the PL/SQL table which make it so different from an array -- that it is both unconstrained and sparse -- allow me to use a single PL/SQL table to implement the traditional n � m array, where n and m are virtually any positive integers. Because the PL/SQL table has no (practical) size limitation and I can use whichever rows in the table I desire, I can spread the m different columns of n rows across the expanse of the PL/SQL table. In other words, I can partition the single PL/SQL table so that it contains all the cells of a traditional array.
10.9.4.2 Partitioning a PL/SQL table to store an array
To understand how this partitioning works, consider a 3 � 4 array. This array contains a total of 12 cells. The cells would be spread among the rows of a PL/SQL table as shown in Figure 10.5 . Using the distribution in the figure, we can see that cell (3,3) would be stored in row 9 of the table, that cell (2,4) would be stored in row 11, and so on.
Figure 10.5: Distribution of 3 � 4 array cells in PL/SQL table
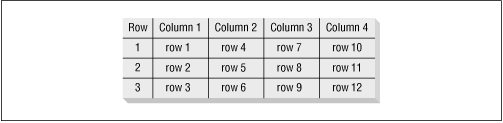
The general formula which converts the row and column of an array cell to the corresponding PL/SQL table row is this:
table_row := (cell_column - 1) * number_of_rows_in_array + cell_row;
where (cell_row, cell_column) is the cell in the array and number_of_rows_in_array is the total number of rows in the array.
10.9.4.3 Features of the array package
The array package I have developed (shown later in this section) implements traditional n � m arrays using PL/SQL tables. This package supports arrays of numeric values only. You would need to create an overloaded version of these same modules for character, date, and other values.
The following shows the modules and capabilities offered by the array package:
- array.make
-
Make or declare an array with specified numbers of rows and columns. You can optionally specify the default value you want placed in each cell.
- array.cell
-
Obtain the value of any cell in the array.
- array.change
-
Change the value of any cell in the array.
- array.erase
-
Erase the array from memory.
- array.display
-
Display the contents of the array. You can display the table contents in array style (matrix format) or inline style (one cell per line).
The package also provides two functions to return the number of rows and columns in the array (number_of_rows and number_of_columns, respectively). It does not, on the other hand, give programmers direct access to the variables which store these values. Instead, I hide the variables themselves in the package body and place the functions in the specification. There are two reasons for this layer of code:
-
You cannot access stored package variables and PL/SQL Version 2 data structures such as PL/SQL tables directly from PL/SQL Release 1.1. The Version 1.1 layer cannot parse such references (see Appendix B, Calling Stored Procedures from PL/SQL Version 1.1 ). You can, however, call stored package functions from within Oracle Developer/2000.
-
It is always better to hide the way you implement functionality, including variables names, data structures, and algorithms. By not exposing the details (in this case, the names of the variables which store this information), I can change the underlying implementation without affecting the way programmers use the data.
Most of the code needed to support arrays is straightforward. Oddly enough, the most complicated module in this package is the display procedure; its complexity is derived from the flexibility it offers. You can display the contents of an array in linestyle (one cell per line) or array style (all cells in each row on the same line, like a spreadsheet). You can also ask to display only selected columns and rows.
10.9.4.4 Examples using array package
The following four examples show how the array package is used.
-
Create a 10 � 10 array with values all set to 0:
array.make (10, 10, 0);
-
Set all the values in the first column of the array to 15:
FOR row_index IN 1 .. array.row_count LOOP array.change (row_index, 1, 15); END LOOP;
-
Set the values in the third row to the values in the fifth row:
FOR col_index IN 1 .. array.column_count LOOP array.change (3, col_index, array.cell (5, col_index)); END LOOP;
-
Create and display contents of arrays:
SQL> execute array.make (10,10,25); PL/SQL procedure successfully completed. SQL> execute array.display(4,6,2,4); Row Column 2 Column 3 Column 4 4 25 25 25 5 25 25 25 6 25 25 25 SQL> execute array.display(4,6,2,4,'line'); Cell (4,2): 25 Cell (4,3): 25 Cell (4,4): 25 Cell (5,2): 25 Cell (5,3): 25 Cell (5,4): 25 Cell (6,2): 25 Cell (6,3): 25 Cell (6,4): 25
There are many possibilities for expanding the capabilities of the array package. You could, for example, offer a module which performs scalar operations against the specified column(s) and row(s) of the array, such as multiplying all cells in the first column by a value. If you implement a version of the array package which supports more than one array at a time, you could build array-level, aggregate operations, such as "multiply two arrays together" or "subtract one array from another," and so on.
I hope that you can see from this section that even if the current version of PL/SQL does not offer every single feature you might want or need, there is often a way to emulate the desired feature. The array package is not nearly as convenient or efficient as true, native arrays would be, but if you have a need right now for an array in PL/SQL Version 2, the package implementation is hard to beat!
10.9.4.5 Limitations in array implementation
There is one major limitation to the implementation of arrays in this package. You can use only one array at a time from this package. The reason for this restriction is that I need to keep track of the number of rows and columns in the array. To make an association between the array (a PL/SQL table) and those values, I would need to ask you for a name for this array and then create named globals with the number of rows and columns. I avoid those complications by "burying" the structure of the array inside the package.
On the positive side, there are several advantages to hiding the table. One is that you have an array which is very easy to use. You never have to declare a table yourself. You simply ask to create or make the array and then you can access the cells.
Another advantage of hiding the table is that you don't have to pass it as a parameter when you call the modules. A PL/SQL table parameter could harm performance, because all the rows of the table are copied into and out of local memory structures for manipulation in that module. In the array package, the number_array table is declared at the package level so it is available to all modules in the package without having to be passed as a parameter.
One final advantage is that you can call this array package (stored in the database) from within the Oracle Developer/2000 tools. If the table were exposed, then the array could only be used in a PL/SQL Version 2 environment. Wow! When I decided to build it this way, I had no idea it would make this much sense.
10.9.4.6 The array package specification
The package specification lists the modules which programmers can call to create and manipulate an array with PL/SQL tables. Notice that the statements in the specification only show the header information: module name and parameters. The code behind these headers is found in the package body (next section):
/* Filename on companion disk: array.sps */
PACKAGE array
IS
/* Returns the number of rows in the array */
FUNCTION row_count RETURN INTEGER;
/* Returns the number of columns in the array */
FUNCTION column_count RETURN INTEGER;
/* Create an array */
PROCEDURE make
(num_rows_in IN INTEGER := 10,
num_columns_in IN INTEGER := 1,
initial_value_in IN NUMBER := NULL,
conflict_action_in IN VARCHAR2 := 'OVERWRITE');
/* Return the value in a cell */
FUNCTION cell (row_in IN INTEGER, col_in IN INTEGER)
RETURN NUMBER;
/* Change the value in a cell */
PROCEDURE change
(row_in IN INTEGER, col_in IN INTEGER, value_in IN NUMBER);
/* Erase the array */
PROCEDURE erase;
/* Display the array */
PROCEDURE display
(start_row_in IN INTEGER := 1,
end_row_in IN INTEGER := row_count,
start_col_in IN INTEGER := 1,
end_col_in IN INTEGER := column_count,
display_style_in IN VARCHAR2 := 'ARRAY');
END array;
10.9.4.7 The array package body
The package body provides the code which implements the modules listed in the array package specification. The longest module in this bunch is the display procedure. Because this code is basically the same as that shown in Section 10.9.3, "Displaying a PL/SQL Table" . I have not repeated it here. However, the full package body is found on the companion disk.
/* Filename on companion disk: array.spb */
PACKAGE BODY array
IS
/*------------------------Private Variables ----------------------*/
/* The number of rows in the array */
number_of_rows INTEGER := NULL;
/* The number of columns in the array */
number_of_columns INTEGER := NULL;
/* The generic table structure for a numeric table */
TYPE number_array_type IS TABLE OF NUMBER
INDEX BY BINARY_INTEGER;
/* The actual table which will hold the array */
number_array number_array_type;
/* An empty table used to erase the array */
empty_array number_array_type;
/*------------------------Private Modules ----------------------*/
FUNCTION row_for_cell (row_in IN INTEGER, col_in IN INTEGER)
RETURN INTEGER
/*
|| Returns the row in the table that stores the value for
|| the specified cell in the array.
*/
IS
BEGIN
RETURN (col_in - 1) * number_of_rows + row_in;
END;
/*------------------------Public Modules ----------------------*/
FUNCTION row_count RETURN INTEGER IS
BEGIN
RETURN number_of_rows;
END;
FUNCTION column_count RETURN INTEGER IS
BEGIN
RETURN number_of_columns;
END;
PROCEDURE make
(num_rows_in IN INTEGER := 10,
num_columns_in IN INTEGER := 1,
initial_value_in IN NUMBER := NULL,
conflict_action_in IN VARCHAR2 := 'OVERWRITE')
/*
|| Create an array of the specified size, with the initial
|| value. If the table is already in use, it will be erased
|| and then re-made only if the conflict action is the
|| default value above.
*/
IS
BEGIN
/*
|| If number_of_rows is NOT NULL, then the array is
|| already in use. If the conflict action is the
|| default or OVERWRITE, then erase the existing
|| array.
*/
IF number_of_rows IS NOT NULL AND
UPPER (conflict_action_in) = 'OVERWRITE'
THEN
erase;
END IF;
/*
|| Only continue now if my number of rows is NULL.
|| If it has a value, then table is in use and user
|| did NOT want to overwrite it.
*/
IF number_of_rows IS NULL
THEN
/* Set the global variables storing size of array */
number_of_rows := num_rows_in;
number_of_columns := num_columns_in;
/*
|| A PL/SQL table's row is defined only if a value
|| is assigned to that row, even if that is only a
|| NULL value. So to create the array, I will simply
|| make the needed assignments. Remember: I use a single
|| table, but segregate distinct areas of the table for each
|| column of data. I use the row_for_cell function to
|| "space out" the different cells of the array across
|| the table.
*/
FOR col_index IN 1 .. number_of_columns
LOOP
FOR row_index IN 1 .. number_of_rows
LOOP
number_array (row_for_cell (row_index, col_index))
:= initial_value_in;
END LOOP;
END LOOP;
END IF;
END;
FUNCTION cell (row_in IN INTEGER, col_in IN INTEGER)
RETURN NUMBER
/*
|| Retrieve the value in a cell using row_for_cell.
*/
IS
BEGIN
RETURN number_array (row_for_cell (row_in, col_in));
END;
PROCEDURE change
(row_in IN INTEGER, col_in IN INTEGER, value_in IN NUMBER)
/*
|| Change the value in a cell using row_for_cell.
*/
IS
BEGIN
number_array (row_for_cell (row_in, col_in)) := value_in;
END;
PROCEDURE erase
/*
|| Erase a table by assigning an empty table to a non-empty
|| array. Then set the size globals for the array to NULL.
*/
IS
BEGIN
number_array := empty_array;
number_of_rows := NULL;
number_of_columns := NULL;
END;
PROCEDURE display
(start_row_in IN INTEGER := 1,
end_row_in IN INTEGER := row_count,
start_col_in IN INTEGER := 1,
end_col_in IN INTEGER := column_count,
display_style_in IN VARCHAR2 := 'ARRAY')
IS
BEGIN
/*
|| See code on disk. This repeats, more or less, the code shown
|| above to display a table.
*/
END display;
END array;
10.9.5 Optimizing Foreign Key Lookups with PL/SQL Tables
Something you'll do again and again in your client-server applications is look up the name or description of a foreign key from a database table that is resident on the server. This lookup often occurs, for example, in the Post-Query trigger of Oracle Forms applications. The base table block contains a database item for the company_id and a non-database item for company_name. What if you have to process a number of different records in your employee table? The SQL processing is very inefficient. When a record is queried from the database, the Post-Query trigger executes an additional SELECT statement to obtain the name of the company, as shown in the following example:
DECLARE
CURSOR company_cur IS
SELECT name FROM company
WHERE company_id = :employee.company_id;
BEGIN
OPEN company_cur;
FETCH company_cur INTO :employee.company_name;
IF company_cur%NOTFOUND
THEN
MESSAGE
(' Company with ID ' || TO_CHAR (:employee.company_id)
' not found in database.');
END IF;
CLOSE company_cur;
END;
This SELECT statement is executed for each record queried into the form. Even if the first twelve employees retrieved in a query all work for the same company, the trigger will open, fetch, and close the company_cur cursor a dozen times -- all to retrieve the same company name again and again. This is not desirable behavior in any application.
Is there a better way? Ideally, you'd want the company name to be already accessible in memory on the client side of the application -- "instantly" available in the form.
One way to achieve this noble objective is to read the contents of the lookup table into a local memory structure on the startup of the form. Unfortunately, this simple solution has a couple of drawbacks:
-
The data, such as the company name, might change during the user session. If you transfer all the names from an RDBMS table to memory and then another user changes the name in the database, your screen data is not updated.
-
You have to set aside sufficient memory to hold all reference values, even if only a few will ever be needed. You will also pay the CPU price necessary to transfer all of this data. This pre-load approach seems like overkill to me.
10.9.5.1 Blending database and PL/SQL table access
A reasonable middle ground between RDBMS-only data and totally local data would store values as they are queried from the database. Then, if that value is needed again in the current session, the application could use the local value instead of issuing another SELECT statement to the database. This would minimize both the memory and the CPU required by the application to return the names for foreign keys.
In this section I offer an implementation of a self-optimizing foreign key lookup process based on PL/SQL tables. I chose PL/SQL tables because I could then store the resulting function in the database and make it accessible to all of my Oracle-based applications, whether they are based on Oracle Forms, PowerBuilder, or Oracle Reports. Let's step through this implementation.
10.9.5.2 Top-down design of blended access
Suppose that I stored company names in a PL/SQL table as they are retrieved from the database and returned to the form. Then, if that same company name is needed a second (or third, or fourth) time, I get it from the memory-resident PL/SQL table rather than from the database. The following example shows the pseudocode which would implement this approach:
1 FUNCTION company_name 2 (id_in IN company.company_id%TYPE) 3 RETURN VARCHAR2 4 IS 5 BEGIN 6 get-data-from-table; 7 return-company-name; 8 EXCEPTION 9 WHEN NO_DATA_FOUND 10 THEN 11 get-data-from-database-table; 12 store-in-PL/SQL-table; 13 return-company-name; 14 END;
This function accepts a single parameter foreign key, id_in (line 2). It first attempts to retrieve the company name from the PL/SQL table (line 6). If that access fails -- if, in other words, I try to reference an undefined row in the PL/SQL table -- then PL/SQL raises the NO_DATA_FOUND exception and control is transferred to the exception section (line 9). The function then gets the name from the database table using a cursor (line 11), stores that information in the PL/SQL table (line 12), and finally returns the value (line 13).
As the user performs queries, additional company names are cached in the PL/SQL table. The next time that same company name is required, the function gets it from the PL/SQL table. In this way, database reads are kept to a minimum and the application automatically optimizes its own data access method. Figure 10.6 illustrates this process.
Figure 10.6: Blended method for lookup of foreign key descriptions
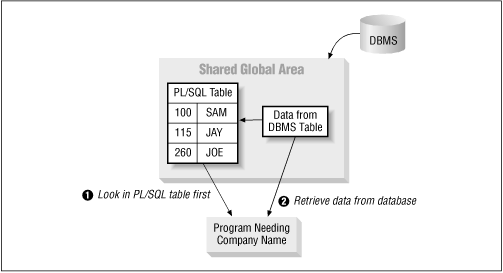
Let's see what it takes to actually write this pseudocode in PL/SQL. If I declare my PL/SQL table in a standalone function, then the scope of that PL/SQL table is restricted to the function. As soon as the function terminates, the memory associated with the PL/SQL table is lost. If, on the other hand, I declare the PL/SQL table in a package, that table remains in memory for the duration of my session (see Chapter 16 for more information about packages). I want my PL/SQL table to persist in memory for the duration of a user session, so I will use a stored package structure.
10.9.5.3 The package specification
The specification for my company package is shown in the following example. It contains a single module called name, which returns the name of the company. Does it seem silly to create a package for this single module? Not really. Beyond the technical justification I just provided, you should realize that in a production environment the company package would contain a number of other modules, such as procedures to return data about the company. And if it were the first module for the package, you are planning well for the future by starting with a package instead of a standalone module:
PACKAGE company_pkg
IS
/*
|| Retrieve the name of the company. If you specify REUSE for
|| the access type, then it will try to get the name from
|| the PL/SQL table. Otherwise, it will just use the database
|| table and do a standard look-up.
*/
FUNCTION name
(id_in IN company.company_id%TYPE,
access_type_in IN VARCHAR2 := 'REUSE')
RETURN VARCHAR2;
END company_pkg;
In this example, the name function takes two parameters: id_in and access_type_in. The access type determines whether the function will try to reuse the name from the PL/SQL table or always get the name from the database table. By providing this parameter, developers can use the company.name function even if they do not want to make use of the PL/SQL table. This would be the case, for example, if the lookup information changes frequently and you cannot afford to use a value returned just minutes past.
What's missing from the package specification is just as interesting as what's there. Notice that the PL/SQL table which holds the names for the foreign key does not appear in the parameter lists of the name module. It isn't even declared in the specification. Instead, the PL/SQL table is declared in the body of the package -- and is completely hidden to developers who make use of this function. By hiding the PL/SQL table, I make this package usable in the Oracle Developer/2000 environment, which, as I've mentioned, is based on PL/SQL Version 1.1 and does not directly support directly PL/SQL tables.
10.9.5.4 The package body
Let's now turn our attention to the package body. In the rest of this section I'll examine the various components of the body individually, listed below:
- company_table_type
-
PL/SQL table type declaration for the table which holds the company names.
- company_table
-
PL/SQL table declaration. The actual declaration of the table.
- name_from_database
-
Private function. Returns the name from the database if not yet stored in the PL/SQL table.
- name
-
Public function. Returns the name to a user of the package. The name might come from the PL/SQL table or the database table.
The body of the company package first declares the table type and table for the company names, as shown below. The datatype for the table's single column is based on the company name column, through use of the %TYPE attribute. This way if the column's length ever changes, this function will automatically adjust:
TYPE company_table_type IS TABLE OF company.name%TYPE INDEX BY BINARY_INTEGER; company_table company_table_type;
The private function name_from_database shown in the next example retrieves the company name from the database. The name function calls name_from_database from two different locations. This function is essentially the same code as that shown in the Post-Query trigger at the start of the section:
FUNCTION name_from_database (id_in IN company.company_id%TYPE)
RETURN company.name%TYPE
IS
CURSOR comp_cur IS
SELECT name FROM company
WHERE company_id = id_in;
return_value company.name%TYPE := NULL;
BEGIN
OPEN comp_cur;
FETCH comp_cur INTO return_value;
CLOSE comp_cur;
RETURN return_value;
END;
Notice that I do not check for %FOUND or %NOTFOUND after I have fetched a record from the cursor. If the FETCH fails, then the value of return_value is not changed. The initial value of NULL is returned by the function, which is what I want. Remember that the name_from_database function is only callable from within the package body. Programmers cannot call this function as they would call the company.name function.
Now that you have seen all the private components of the package, let's see how I use them to build the single public module of the company package: the name function (whose full implementation is shown below). The body of the program consists of only six lines:
IF UPPER (access_type_in) = 'REUSE' THEN RETURN company_table (id_in); ELSE RETURN name_from_database; END IF;
In other words, if reuse is specified then get the value from the PL/SQL table; otherwise get the name from the database. What if the name is not in the PL/SQL table? Then PL/SQL raises the NO_DATA_FOUND exception and the action moves to the exception section, which consists of the following:
EXCEPTION
WHEN NO_DATA_FOUND
THEN
return_value := name_from_database;
IF return_value IS NOT NULL
THEN
company_table (id_in) := return_value;
END IF;
RETURN return_value;
END;
I try to get the name from the database. If the function returns a non-NULL value, then I save it to the table. Finally, I return that company name. The result is simple, readable code.
In this exception handler you can see the random-access nature of the PL/SQL table. The id_in foreign key value actually serves as the row in the table. I do not have to store the values in the PL/SQL sequentially. Instead, I simply populate those rows of the table which correspond to the foreign keys.
10.9.5.5 The company.name function
The following function combines the various elements described earlier. This name function is defined within the company package:
/* Filename on companion disk: selftune.spp (contains the full code for the package containing this function) */
FUNCTION name
(id_in IN company.company_id%TYPE,
access_type_in IN VARCHAR2 := 'REUSE')
RETURN company.name%TYPE
IS
return_value company.name%TYPE;
BEGIN
/* If REUSE (default), then try to get name from PL/SQL table */
IF UPPER (access_type_in) = 'REUSE'
THEN
RETURN company_table (id_in);
ELSE
/* Just get the name from the database table. */
RETURN name_from_database;
END IF;
EXCEPTION
/* If REUSE and PL/SQL table does not yet have value ... */
WHEN NO_DATA_FOUND
THEN
/* Get the name from the database */
return_value := name_from_database;
/* If name was found, save to PL/SQL table for next time. */
IF return_value IS NOT NULL
THEN
company_table (id_in) := return_value;
END IF;
/* Return the company name */
RETURN return_value;
END;
Using the company package, the Post-Query trigger shown in an earlier example becomes simply:
:employee.company_name := company.name (:employee.company_id);
IF :employee.company_name IS NULL
THEN
MESSAGE
(' Company with ID ' || TO_CHAR (:employee.company_id)
' not found in database.');
END IF;
In this call to company.name, I did not provide a value for the second parameter, so it takes the default value of REUSE and checks to see if the company name is in the PL/SQL table. Alternatively, I could specify the access type using a GLOBAL variable as follows:
:employee.company_name := company.name (:employee.company_id, :GLOBAL.access_type);
I could then modify the behavior and -- I hope -- the performance of my foreign key lookups without having to change my code. In other words, if I determine that the contents of a particular table are static throughout a session, I could set the GLOBAL to REUSE for that call. If, on the other hand, I determine that the data might change, I could change the GLOBAL to NOREUSE and then force the lookup to go against the database.
10.9.5.6 Performance impact of blended access
How much impact, you might ask, does the company.name function have on the lookup process? I tested the performance of this package with the SQL*Plus script shown in the following example.
The do package in the code below offers a substitution for the DBMS_OUTPUT package. The timer package makes use of DBMS_UTILITY and its GET_TIME function to measure elapsed time in 100ths of seconds. The do and timer packages are defined in Chapter 16 .
DECLARE
c VARCHAR2(100);
BEGIN
timer.capture;
FOR i IN 1 .. &num_iterations
LOOP
c := company.name (10, '&access_type');
END LOOP;
do.pl (c);
timer.show_elapsed;
END;
/
I executed the script on a 100Mhz 486 workstation with a local Oracle7 for Windows database. The results of this comparison of database and PL/SQL table lookup performance are shown in Table 10.2 .
|
Access Type |
Number of Accesses |
Elapsed Time (100ths of seconds) |
|---|---|---|
|
NOREUSE |
100 |
22-28 |
|
REUSE |
100 |
0-5 |
|
NOREUSE |
1000 |
230-240 |
|
REUSE |
1000 |
16-22 |
An access type of NOREUSE means that each access required a database query. An access type of REUSE means that the first request performed a database query, while all others worked with the PL/SQL table. Clearly, PL/SQL table access offers a significant performance savings -- and this is with a local database. You can expect even more of an improvement with a remote database. The benefit of this approach is obvious: it is always faster to access local memory than the Oracle database shared memory.

|

|

|
| 10.8 PL/SQL Table Enhancements in PL/SQL Release 2.3 |

|
III. Built-In Functions |

Copyright (c) 2000 O'Reilly & Associates. All rights reserved.