

|
Chapter 9 |

|
9. Records in PL/SQL
Contents:
Record Basics
Table-Based Records
Cursor-Based Records
Programmer-Defined Records
Assigning Values to and from Records
Record Types and Record Compatibility
Nested Records
Records in PL/SQL programs are very similar in concept and structure to the rows of a database table. A record is a composite data structure, which means that it is composed of more than one element or component, each with its own value. The record as a whole does not have value of its own; instead, each individual component or field has a value. The record gives you a way to store and access these values as a group.
If you are not familiar with using records in your programs, you might initially find them complicated. When used properly, however, records will greatly simplify your life as a programmer. You will often need to transfer data from the database into PL/SQL structures and then use the procedural language to further massage, change, or display that data. When you use a cursor to read information from the database, for example, you can pass that table's record directly into a single PL/SQL record. When you do this you preserve the relationship between all the attributes from the table.
9.1 Record Basics
This section introduces the different types of records and the benefits of using them in your programs.
9.1.1 Different Types of Records
PL/SQL supports three different kinds of records: table-based, cursor-based, and programmer-defined. These different types of records are used in different ways and for different purposes, but all three share the same internal structure: every record is composed of one or more fields. However, the way these fields are defined in the record depend on the record type. Table 9.1 shows this information about each record type.
|
Record Type |
Description |
Fields in Record |
|---|---|---|
|
Table-based |
A record based on a table's column structure. |
Each field corresponds to -- and has the same name as -- a column in a table. |
|
Cursor-based |
A record based on the cursor's SELECT statement. |
Each field corresponds to a column or expression in the cursor SELECT statement. |
|
Programmer-defined |
A record whose structure you, the programmer, get to define with a declaration statement. |
Each field is defined explicitly (its name and datatype) in the TYPE statement for that record; a field in a programmer-defined record can even be another record. |
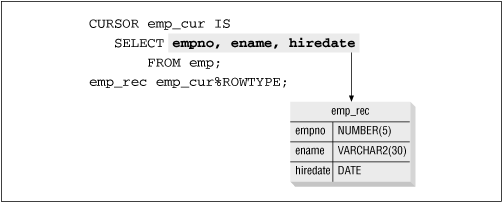
Figure 9.1 illustrates the way a cursor record adopts the structure of the SELECT statement by using the %ROWTYPE declaration attribute (explained later in this chapter).
Figure 9.1: Mapping of cursor structure to PL/SQL record
9.1.2 Accessing Record-Based Data
You access the fields within a record using dot notation, just as you would identify a column from a database table, in the following format:
<record name>.<field name>
You would reference the first_name column from the employee table as follows:
employee.first_name
You would reference the emp_full_name field in the employee PL/SQL record as:
employee_rec.emp_full_name
The record or tuple structure of relational database tables has proven to be a very powerful way to represent data in a database, and records in your programs offer similar advantages. The next section describes briefly the reasons you might want to use records. The rest of this chapter show you how to define and use each of the different types of records, and the situations appropriate to each record type.
9.1.3 Benefits of Using Records
The record data structure provides a high-level way of addressing and manipulating program-based data. This approach offers the following benefits:
- Data abstraction
-
Instead of working with individual attributes of an entity or object, you think of and manipulate that entity as a "thing in itself."
- Aggregate operations
-
You can perform operations which apply to all the columns of a record.
- Leaner, cleaner code
-
You can write less code and make what you do write more understandable.
The following sections describe each of these benefits.
9.1.3.1 Data abstraction
When you abstract something, you generalize it. You distance yourself from the nitty-gritty details and concentrate on the big picture. When you create modules, you abstract the individual actions of the module into a name. The name (and program specification) represents those actions.
When you create a record, you abstract all the different attributes or fields of the subject of that record. You establish a relationship between all those different attributes and you give that relationship a name by defining a record.
9.1.3.2 Aggregate operations
Once you have stored information in records, you can perform operations on whole blocks of data at a time, rather than on each individual attribute. This kind of aggregate operation reinforces the abstraction of the record. Very often you are not really interested in making changes to individual components of a record, but instead to the object which represents all of those different components.
Suppose that in my job I need to work with companies, but I don't really care about whether a company has two lines of address information or three. I want to work at the level of the company itself, making changes to, deleting, or analyzing the status of a company. In all these cases I am talking about a whole row in the database, not any specific column. The company record hides all that information from me, yet makes it accessible when and if I need it. This orientation brings you closer to viewing your data as a collection of objects with rules applied to those objects.
9.1.3.3 Leaner, cleaner code
Using records also helps you to write clearer code and less of it. When I use records, I invariably produce programs which have fewer lines of code, are less vulnerable to change, and need fewer comments. Records also cut down on variable sprawl; instead of declaring many individual variables, I declare a single record. This lack of clutter creates aesthetically attractive code which requires fewer resources to maintain.
9.1.4 Guidelines for Using Records
Use of PL/SQL records can have a dramatic impact on your programs, both in initial development and in ongoing maintenance. To ensure that I personally get the most out of record structures, I have set the following guidelines for my development:
-
Create corresponding cursors and records. Whenever I create a cursor in my programs, I also create a corresponding record (except in the case of cursor FOR loops). I always FETCH into a record, rather than into individual variables. In those few instances when it might involve a little extra work over simply fetching into a single variable, I marvel at the elegance of this approach and compliment myself on my commitment to principle.
-
Create table-based records. Whenever I need to store table-based data within my programs, I create a new (or use a predefined) table-based record to store that data. I keep my variable use to a minimum and dynamically link my program data structures to my RDBMS data structures with the %ROWTYPE attribute.
-
Pass records as parameters. Whenever appropriate, I pass records rather than individual variables as parameters in my procedural interfaces. This way, my procedure calls are less likely to change over time, making my code more stable. There is a downside to this technique, however: if a record is passed as an OUT or IN OUT parameter, its field values are saved by the PL/SQL program in case of the need for a rollback. This can use up memory and consume unnecessary CPU cycles.
9.1.5 Referencing a Record and its Fields
The rules you must follow for referencing a record in its entirety or a particular field in the record are the same for all types of records: table, cursor, and programmer-defined.
A record's structure is similar to that of a database table. Where a table has columns, a record has fields. You reference a table's column by its name in a SQL statement, as in:
SELECT company_id FROM company;
Of course, the fully qualified name of a column is:
<table_name>.<column_name>
This full name is often required in a SQL statement to avoid ambiguity, as is true in the following statement:
SELECT employee.company_id, COUNT(*) total_employees FROM company, employee WHERE company.company_id = employee.company_id;
If I do not preface the name of company_id with the appropriate table name, the SQL compiler will not know to which table that column belongs. The same is true for a record's fields. You reference a record by its name, and you reference a record's field by its full name using dot notation, as in:
<record_name>.<field_name>
So if I create a record named company_rec, which contains a company_id field, then I would reference this field as follows:
company_rec.company_id
You must always use the fully qualified name of a field when referencing that field. If you don't, PL/SQL will never be able to determine the "default" record for a field, as it does in a SQL statement.
You do not, on the other hand, need to use dot notation when you reference the record as a whole; you simply provide the name of the record. In the following example, I pass a record as a parameter to a procedure:
DECLARE TYPE customer_sales_rectype IS RECORD (...); customer_rec customer_sales_rectype; BEGIN display_sales_data (customer_rec); END;
I didn't make a single dotted reference to any particular field in the customer record. Instead I declared the record type, used it to create the record, used the record type again to define the type for the parameter in the procedure specification, and finally called the procedure, passing it the specific record I declared.
9.1.6 Comparing Two Records
While it is possible to stay at the record level in certain situations, you can't avoid direct references to fields in many other cases. If you want to compare records, for example, you must always do so through comparison of the records' individual fields.
Suppose you want to know if the old company information is the same as the new company information, both being stored in records of the same structure. The following test for equality will not compile:
IF old_company_rec = new_company_rec /-- Illegal syntax! THEN ... END IF;
even though the structures of the two records are absolutely identical and based on the same record type (in this case, a table record type).
PL/SQL will not automatically compare each individual field in the old company record to the corresponding field in the new company record. Instead, you will have to perform that detailed check yourself, as in:
IF old_company_rec.name = new_company_rec.name AND old_company_rec.incorp_date = new_company_rec.incorp_date AND old_company_rec.address1 = new_company_rec.address1 AND THEN ... the two records are identical ... END IF;
Of course, you do not simply examine the value of a particular field when you work with records and their fields. Instead, you will assign values to the record and its fields, from either scalar variables or other records. You can reference a record's field on both sides of the assignment operator. In the following example I change the contents of a record, even though that record was just filled from a cursor:
DECLARE CURSOR company_cur IS ...; company_rec company_cur%ROWTYPE; BEGIN OPEN company_cur; FETCH company_cur INTO company_rec; company_rec.name := 'New Name'; END;
There is, in other words, no such thing as a "read-only" PL/SQL record structure.
|
|

|
|
| 8.10 RAISE Nothing but Exceptions |

|
9.2 Table-Based Records |

Copyright (c) 2000 O'Reilly & Associates. All rights reserved.