

|
Chapter 20 |

|
20. PLVcmt and PLVrb: Commit and Rollback Processing
PL/Vision provides two packages that help you manage transaction processing in PL/SQL applications: PLVcmt and PLVrb. These packages provide a layer of code around the transaction-oriented builtins of the PL/SQL language. If you make full use of PLVcmt and PLVrb, you will no longer need to make direct calls to COMMIT and ROLLBACK. Instead, you will call the corresponding programs in these two packages; by doing so, you will greatly increase your flexibility, improve your ability to test your code, and reduce overall code volume.
20.1 PLVcmt: Enhancing Commit Processing
The PLVcmt (PL/Vision CoMmiT) package encapsulates logic and complexity for dealing with commit processing. For example, you can use PLVcmt to rapidly define scripts that execute commits every 1,000 transactions. You can replace any direct calls to COMMIT with a call to PLV cmt.perform_commit and thereby give yourself additional testing and debugging flexibility. By providing a programmatic interface to commit activity in PL/SQL , PL/Vision gives you the ability to change transaction-level behavior at runtime. You can also reduce the volume of code you write to perform commits in your applications.
20.1.1 Who Needs PLVcmt?
In my first book on PL/SQL , I used more that 900 pages to talk about almost every aspect of the PL/SQL language. But notice that word: almost. I did not, in fact, cover two very important commands in PL/SQL : COMMIT and ROLLBACK. Why didn't I discuss these commands? For two reasons: oversight and rationalization. The oversight was due to the fact that I had up to that time rarely performed commits in my PL/SQL programs (they were usually a part of Oracle Forms applications or were developer utilities).
When I did issue a commit, I didn't pay much attention. There just wasn't much to it. And that is where the rationalization part of the explanation comes in. Even when I did realize that COMMIT and ROLLBACK were missing from my book (fairly late in the game, but in time to include them), I said to myself: they are so simple and easy to use. I don't really need to write about that aspect of PL/SQL . Everybody knows about them from the SQL language anyway.
Since those days, I have had good reason to take a second, longer look at the (deceptively) simple COMMIT statement and its use in PL/SQL programs. I found from work at an account in early 1996 that there can be much more to committing than meets the eye. I found, in particular, that by managing your commit processing from within a package you can greatly improve your flexibility in testing. You will also gain an additional, welcome level of control in your batch processing applications. In fact, coming out of my experience I would make the following recommendation:
NOTE: You should never make a direct call to COMMIT, ROLLBACK, or SAVEPOINT in your code. By doing so, you hard-code irreversible operations into your PL/SQL programs and limit your flexibility.
At this point, you must surely consider me a package fanatic. What is the big deal about the COMMIT statement? Why would you possibly want to go to the trouble of building a package just to do a commit? Well, certainly on the logical level, a COMMIT is a very big deal. It completes a transaction by saving information to the database. When you are writing applications to manage data in your Oracle7 Server, the commit is a central and critical step. It certainly is easy enough to do a commit. You just type the following statement in your program:
COMMIT;
No, executing a commit is easy. Determining when and how often to do the commit can be more challenging. Managing rollbacks is, furthermore, even more interesting. I found that a package gave me the flexibility I needed to meet their requirements. The PLVcmt package arose from this application's challenges.
20.1.1.1 Commit processing challenges
My customer, which I'll refer to as Bigdata Inc., needed to perform a complex data translation from one Oracle database instance to another. Approximately 20 million records in two tables were involved. It wasn't one of those all-or-nothing situations. If we could manage to get through a million records before some failure occurred, that was fine. All we had to do was come up with a mechanism for keeping track of which records had already been processed, so we didn't do them again. We used a "transfer indicator," which also led to a distributed transaction.
I've got to be honest with you: I have not spent many hours of my career (prior to Bigdata) working with this kind of volume of data. It sure puts a different spin on everything you do. When a simple SELECT could take hours to complete, you get very careful about the queries you execute. You no longer make casual statements (and take casual actions) like: "Let's just run this and see how it works. If it fails, we'll try it again." Three days later (or two weeks later), the job might crash from a "snapshot too old" error and you are back at square one -- if you didn't take precautions.
In fact, I quickly became intimate with a range of Oracle errors that earlier had been fairly academic to me: the -015NN series. Errors like:
ORA-01555 snapshot too old (rollback segment too small) ORA-01562 failed to extend rollback segment
became a regular and unwelcome part of my life. Sure, we had big rollback segments, but one of our tables took up 2 gigabytes of storage in the database. We simply couldn't execute queries across the entire table at the same time that updates were taking place. I learned to "chunk down" by primary key ranges the rows I processed in each pass of my program. And I discovered the need to get flexible when it came to commits.
20.1.1.2 Committing every ? records
When I first started with the account, we agreed that committing every 10,000 records would be great. This is the kind of code we wrote to handle the situation:
commit_counter := 0
FOR original_rec IN original_cur
LOOP
translate_data (original_rec);
IF commit_counter >= 10000
THEN
COMMIT;
commit_counter := 0;
ELSE
commit_counter := commit_counter + 1;
END IF;
END LOOP;
COMMIT;
Of course, there were a number of different programs and each had this logic, along with a declaration of commit_counter , in each program. We soon found, however, that 10,000 was simply too high a number. We blew out rollback segments on a maddeningly occasional, but unpredictable basis. So we decided to change the number to 1,000 and off I went to each of the different programs removing that troublesome zero.
I felt dumb doing this, but of course we faced looming deadlines and had no time to reflect. The next complication I ran into was the need to run my script in "test mode:" perform the data translation for one or several records and then examine the accuracy of the data. In this situation, I found that I would rather not commit at all. Just run the program, use queries to examine the changes, and then issue a ROLLBACK. To do this, I went back into my program and commented-out the entire IF statement having to do with commits and keeping counts.
commit_counter := 0
FOR original_rec IN original_cur
LOOP
translate_data (original_rec);
/*
IF commit_counter >= 1000
THEN
COMMIT;
commit_counter := 0;
ELSE
commit_counter := commit_counter + 1;
END IF;
*/
END LOOP;
COMMIT;
Once I got through several debug-test cycles, I reactivated my commit logic by removing the comment markers and recompiling.
20.1.1.3 What committed when?
It was then time to run the process for the full sweep of the data (in its manageable chunks). So I started the program and went home for the weekend. Saturday and Sunday were very pleasant, but I came back in on Monday and found that the job has stopped on Sunday afternoon. I had a heck of a time figuring out why it had stopped and how far it had gotten. I realized that it would have been very useful to have a log of each commit performed by the program. So I changed my basic loop (shown previously) as follows:
commit_counter := 0
FOR original_rec IN original_cur
LOOP
translate_data (original_rec);
IF commit_counter >= 1000
THEN
COMMIT;
DBMS_OUTPUT.PUT_LINE
('Commit at' ||
original_rec.keyvalue);
commit_counter := 0;
ELSE
commit_counter :=
commit_counter + 1;
END IF;
END LOOP;
COMMIT;
Now, every time a commit occurred, the primary key value would be displayed. I set up this job to run and after an hour or two it died -- this time because my program's output had exceeded the DBMS_OUTPUT default buffer of 2K! This was getting very frustrating. Maybe I should expand the size of the buffer. Maybe I should be writing the commit log out to a table. Or maybe it was just time for a break.
With a moment to reflect, I saw the insanity of my way. Here I was putting out little fires, patching up this hole, then that hole in my logic. In the process, the code I had written to perform commits was actually getting more complicated than the actual application logic -- and, again, it was repeated in several different programs.
20.1.1.4 Getting back on track
Time out! I declared to myself and the rest of the technical team. I had committed several grievous errors, any one of which should have raised a red flag:
-
I repeated the same code in multiple programs (declaration of commit_counter , IF statement, etc.). This should always be avoided by consolidating repetitive code behind a procedural interface.
-
I edited my code in order to move from "test mode" to "production" status -- I inserted and then removed the comment markers. You want to avoid whenever possible these kinds of last-minute, "no problem" edits of code. Any time you change your code, you really should retest. Do you want to introduce another round of testing right after you thought you finished all your testing?
No, it was time to go back to square one, do some top-down design, and do it right...the second time around.
The first thing that caught my eye is that I could simply be smarter about how to determine when to perform my commit. Rather than use an independent counter, I could take advantage of the %ROWCOUNT cursor attribute to figure out how many rows I had fetched. Combined with use of the MOD function, I could change my loop to the following, more concise implementation:
FOR original_rec IN original_cur
LOOP
translate_data (original_rec);
IF MOD (original_cur%ROWCOUNT, 1000) = 0
THEN
COMMIT;
END IF;
END LOOP;
COMMIT;
In this approach, whenever the number of rows fetched is a multiple of 1000, the MOD function returns 0 and COMMIT is executed. No local variable counter to declare and maintain -- when working within a cursor loop anyway. This was a satisfying discovery, but it didn't address some of my other concerns: turning off commits for test purposes, changing the number to use in the call to MOD, and so on. No, I decided to press on...and come up with a package-based solution, which turned into PLVcmt.
20.1.1.5 The impact of PLVcmt
Here is what my data translation loop looks like when I use a package-based approach:
PLVcmt.init_counter; FOR original_rec IN original_cur LOOP translate_data (original_rec); PLVcmt.increment_and_commit; END LOOP; PLVcmt.perform_commit;
In other words:
-
I initialize my commit package values.
-
I commit based on the counter inside the loop.
-
Then after the loop terminates, I perform a final commit.
Notice that the commit_counter variable has disappeared. I don't want to deal with that. Also gone is the code to display the commit action and the IF statement. Nor can you find a call to COMMIT. It's all tucked away somewhere else. Ah! A sigh of relief. And -- here is where it gets really dreamy -- if I want to run the program and not perform any commits, I wish to be able to simply call another PLVcmt program to tell it not to commit, like this:
execute PLVcmt.turn_off;
Without making any changes to my program, the behavior of the PLVcmt package would change. Now that would be a wondrous thing, would it not? Let's see how we might go about building such a package, because at least in this case, my fantasies can be transformed fully into reality.
Now that you've seen the inspiration behind PLVcmt and how useful it can be, it's time for a formal introduction. These following sections explain these features of the PLVcmt package:
-
Using a package-based substitute for COMMIT
-
Performing incremental commits
-
Controlling commit processing
-
Logging commit activity
20.1.2 The COMMIT Substitute
PLVcmt offers two programs that can perform commits for you: perform_commit and increment_and_commit . The perform_commit program is a direct substitution for COMMIT. The increment_and_commit program is used in conjunction with loops in situations where you want to commit every n transactions.
The header for perform_commit is:
PROCEDURE perform_commit (context_in IN VARCHAR2 := NULL);
The single argument to perform_commit , context_in , is an optional string that you want to associate with this commit point. This string is then logged with the PLVlog package when a commit is performed through PLVcmt and the user has requested that commits be shown.
A direct substitution for a call to COMMIT is this statement:
PLVcmt.perform_commit;
The following call to this procedure associates the commit point with a calculation of net sales for the current year.
PLVcmt.perform_commit ('Net sales ' || TO_CHAR (v_curr_year));
This string is ignored unless you have executed the PLVcmt.log command to turn on logging of commits.
20.1.3 Performing Incremental Commits
When you use PLVcmt, it is very easy to write code that handles the following kind of requirement: "commit every 100 records." With PLVcmt, you don't have to declare a local counter, increment the counter, or call COMMIT. Instead, you simply make calls to the appropriate PLVcmt programs and concentrate on writing your transaction logic.
Three PLVcmt programs implement incremental commits: the init_counter , commit_after , and increment_and_commit procedures.
20.1.3.1 Setting the commit point
The first step in using PLVcmt to perform incremental commits is to tell the package how often you want a commit to occur. You do this with the commit_after procedure, whose header is shown below:
PROCEDURE commit_after (count_in IN INTEGER);
where count_in is the number of transactions you want to occur before a commit takes place. The default, initial value of the count is 1, which means that every time you call PLVcmt.increment_and_commit , a COMMIT is executed (unless you have turned off commit processing, which is discussed in the next section).
In the following call to commit_after , I request that a commit occur every 100 transactions.
PLVcmt.commit_after (100);
In this next call to commit_after , I set the commit point to 0.
PLVcmt.commit_after (0);
This effectively turns off the execution of a COMMIT from within the increment_and_commit program. With the "commit after" set to zero, a COMMIT occurs only when PLVcmt.perform_commit is called.
NOTE: The commit point established by the commit_after procedure does not in any way affect the behavior of the perform_commit procedure.
20.1.3.2 Initializing the counter
You have called PLVcmt.commit_after to tell PLVcmt that you want to commit every n records. Before you start running your code, you should initialize the PLVcmt counter to make sure that n transactions occur before a commit.
The header for init_counter is:
PROCEDURE init_counter;
When called, this program sets the internal PLVcmt counter to 0. The only way to modify this counter is with a call to init_counter or to increment_and_commit .
20.1.3.3 Increment and commit
When you want to commit every n records, you can simply insert a call to the increment_and_commit procedure in your code. The header is:
PROCEDURE increment_and_commit (context_in IN VARCHAR2 := NULL);
This program always increments the PLVcmt counter. If the counter exceeds the commit-after value set with a call to PLVcmt.commit_after , then the perform_commit procedure is called. Immediately after that, PLVcmt calls its own init_counter to reset the counter to 0.
20.1.4 Controlling Commit Processing
One of the big advantages to using PLVcmt instead of issuing direct calls to COMMIT is that you have placed a layer of code between your application and COMMIT. This layer gives you (through PL/Vision) the ability to modify commit processing behavior without changing your application code. This is very important because it allows you to stabilize your code, but still change the way it works for purposes of testing and debugging. Figure 20.1 shows this layer of code.
Figure 20.1: Code layer around COMMIT
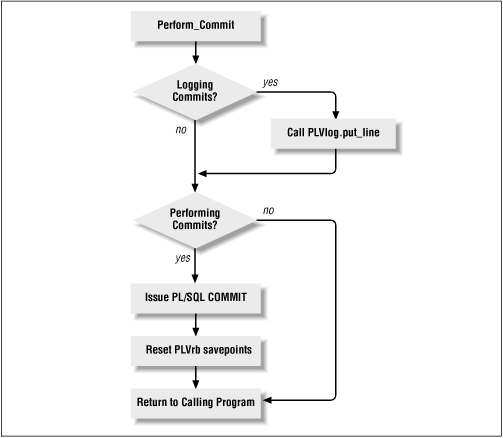
By using PLVcmt you can, in fact, actually disable COMMITs in your application. I have found this feature useful when I am working with test data. My code changes the data, but then I have to change it back for the next test. If, however, I call PLVcmt commit programs instead of issuing direct calls to COMMIT, I can simply tell PLVcmt to not commit for the test run. I can then run my code, examine the results within my current session, and perform a rollback. No recovery scripts are necessary.
PLVcmt offers a standard PL/Vision toggle to control commit processing. This triumvirate of programs is:
PROCEDURE turn_on; PROCEDURE turn_off; FUNCTION committing RETURN BOOLEAN;
One procedure to turn on commit processing, another to turn it off, and a final function to indicate the current state of affairs (for completeness and politeness). All the two procedures do is set the value of a private Boolean variable, but by correctly applying that Boolean inside an IF statement in PLVcmt, the package's user gets to fine-tune the package's behavior.
20.1.5 Logging Commits
The commit action in an application is a critical step. It is, for one thing, irreversible. Once you commit, you cannot uncommit. It is often very useful to know when commits have taken place and the action that was taken around that commit point. I have found this to be most important when I am executing long-running processes with incremental commits. How far along am I in processing my ten million transactions? The PLVcmt logging facility gives you access to this information.
Whenever you call PLVcmt.perform_commit and PLVcmt.increment_and_commit , you can supply a string or context for that action. This string is ignored unless logging is turned on. If logging is enabled, PLVcmt calls the PLVlog facility to log your message. You can, within PLVlog, send this information to a database table, PL/SQL table, operating system file (with Release 2.3 of PL/SQL ), or standard output (your screen).
PLVcmt offers a standard PL/Vision toggle to control commit processing. This triumvirate of programs is:
PROCEDURE log; PROCEDURE nolog; FUNCTION logging RETURN BOOLEAN;
NOTE: You do not have to turn on logging in PLVlog for the PLVcmt log to function properly. It will automatically turn on logging in PLVlog in order to write its commit-related information, and then reset the PLVlog status to its prior state.
20.1.6 Using PLVcmt
The following several examples show how to use these different elements of PLVcmt. First, we'll recast the previous anonymous block as a procedure so that it can be called from within a SQL*Plus session:
PROCEDURE translate_all
IS
CURSOR original_cur IS SELECT ...;
BEGIN
PLVcmt.init_counter;
FOR original_rec IN original_cur
LOOP
translate_data (original_rec);
PLVcmt.increment_and_commit
(original_rec.keyvalue);
END LOOP;
PLVcmt.perform_commit;
END translate_all;
Again, notice that by using PLVcmt I do not have to declare or manage a counter. By default, this program commits the data translation for each record fetched by the original data cursor and then commits on the way out. Whenever I increment inside the loop, I also pass the key value to PLVcmt for display -- when so specified. Now I can call this program in conjunction with other PLVcmt modules.
In the following SQL*Plus session, I specify that a commit should take place every 1,000 records:
SQL> exec PLVcmt.commit_after (1000) SQL> exec translate_all
In this next SQL*Plus session, I request a display of the commits as they occur and then sit back and watch the results:
SQL> exec PLVcmt.commit_after (1000) SQL> exec PLVcmt.log SQL> exec translate_all commit ON IL123457 commit ON KY000566 commit ON NY121249
The reason PLVcmt indicates that commit is on is that I could run this same session, but avoid doing any commits. However, I might still want to see the output to verify correctness. Here we go:
SQL> exec PLVcmt.turn_off SQL> exec PLVcmt.log SQL> exec translate_all commit OFF IL123457 commit OFF KY000566 commit OFF NY121249
Notice that I can achieve this change in behavior of my application without making any changes whatsoever to the application code itself. All the logic and complexity is hidden behind the interface of the package.
Since the writing of my first book, I have fallen in with love (sure, go ahead, laugh at me!) with these kinds of toggles and tightly controlled windows into packages. I can write my basic, useful package and then pack into it all kinds of flexibility, controlled by the user of the package. This flexibility makes my package more useful in a variety of circumstances. This improved usability increases the reusability of my own code and the code of others who have begun to use PL/Vision.
|
|

|
|
| 19.6 PLVfk: Generic Foreign Key Lookups |

|
20.2 PLVrb: Performing Rollbacks |

Copyright (c) 2000 O'Reilly & Associates. All rights reserved.