
 |  |
13.8. Protocol Case Study
This example is an actual case that was solved by protocol analysis. The problem was reported as an occasional ftp failure with the error message:
netout: Option not supported by protocol 421 Service not available, remote server has closed connection
Only one user reported the problem, and it occurred only when transferring large files from a workstation to the central computer via our backbone network.
We obtained the user's data file and were able to duplicate the problem from other workstations, but only when we transferred the file to the same central system via the backbone network. Figure 13-4 graphically summarizes the tests we ran to duplicate the problem.
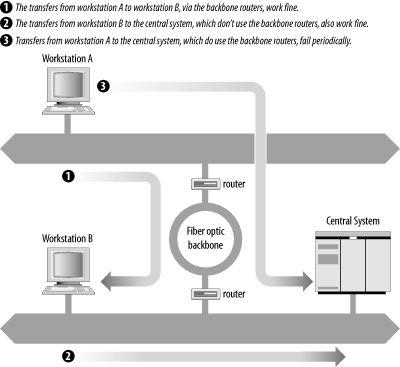
Figure 13-4. FTP test summary
We notified all users of the problem. In response, we received reports that others had also experienced it, but again only when transferring to the central system, and only when transferring via the backbone. They had not reported it because they rarely saw it. But the additional reports gave us some evidence that the problem did not relate to any recent network changes.
Because the problem had been duplicated on other systems, it probably was not a configuration problem on the user's system. The ftp failure could also be avoided if the backbone routers and the central system did not interact. So we concentrated our attention on those systems. We checked the routing tables and ARP tables, and ran ping tests on the central system and the routers. No problems were observed.
Based on this preliminary analysis, the ftp failure appeared to be a possible protocol interaction problem between a certain brand of routers and a central computer. We made that assessment because the transfer routinely failed when these two brands of systems were involved, but never failed in any other circumstance. If the router or the central system were misconfigured, they should fail when transferring data to other hosts. If the problem was an intermittent physical problem, it should occur randomly, regardless of the hosts involved. Instead, this problem occurred predictably, and only between two specific brands of computers. Perhaps there was something incompatible in the way these two systems implemented TCP/IP.
Therefore, we used snoop to capture the TCP/IP headers during several ftp test runs. Reviewing the dumps showed that all transfers that failed with the "netout" error message had an ICMP Parameter Error packet near the end of the session, usually about 50 packets before the final close. No successful transfer had this ICMP packet. Note that the error did not occur in the last packet in the data stream, as you might expect. It is common for an error to be detected, and for the data stream to continue for some time before the connection is actually shut down. Don't assume that an error will always be at the end of a data stream.
Here are the headers from the key packets. First, the IP header of the packet from the backbone router that caused the central system to send the error:
ETHER: ----- Ether Header ----- ETHER: ETHER: Packet 1 arrived at 16:56:36.39 ETHER: Packet size = 60 bytes ETHER: Destination = 8:0:25:30:6:51, CDC ETHER: Source = 0:0:93:e0:a0:bf, Proteon ETHER: Ethertype = 0800 (IP) ETHER: IP: ----- IP Header ----- IP: IP: Version = 4 IP: Header length = 20 bytes IP: Type of service = 0x00 IP: xxx. .... = 0 (precedence) IP: ...0 .... = normal delay IP: .... 0... = normal throughput IP: .... .0.. = normal reliability IP: Total length = 552 bytes IP: Identification = 8a22 IP: Flags = 0x0 IP: .0.. .... = may fragment IP: ..0. .... = last fragment IP: Fragment offset = 0 bytes IP: Time to live = 57 seconds/hops IP: Protocol = 6 (TCP) IP: Header checksum = ffff IP: Source address = 172.16.55.106, fs.wrotethebook.com IP: Destination address = 172.16.51.252, bnos.wrotethebook.com IP: No options IP:
And this is the ICMP Parameter Error packet sent from the central system in response to that packet:
ETHER: ----- Ether Header ----- ETHER: ETHER: Packet 3 arrived at 16:56:57.90 ETHER: Packet size = 98 bytes ETHER: Destination = 0:0:93:e0:a0:bf, Proteon ETHER: Source = 8:0:25:30:6:51, CDC ETHER: Ethertype = 0800 (IP) ETHER: IP: ----- IP Header ----- IP: IP: Version = 4 IP: Header length = 20 bytes IP: Type of service = 0x00 IP: xxx. .... = 0 (precedence) IP: ...0 .... = normal delay IP: .... 0... = normal throughput IP: .... .0.. = normal reliability IP: Total length = 56 bytes IP: Identification = 000c IP: Flags = 0x0 IP: .0.. .... = may fragment IP: ..0. .... = last fragment IP: Fragment offset = 0 bytes IP: Time to live = 59 seconds/hops IP: Protocol = 1 (ICMP) IP: Header checksum = 8a0b IP: Source address = 172.16.51.252, bnos.wrotethebook.com IP: Destination address = 172.16.55.106, fs.wrotethebook.com IP: No options IP: ICMP: ----- ICMP Header ----- ICMP: ICMP: Type = 12 (Parameter problem) ICMP: Code = 0 ICMP: Checksum = 0d9f ICMP: Pointer = 10
Each packet header is broken out bit by bit and mapped to the appropriate TCP/IP header fields. From this detailed analysis of each packet, we see that the router issued an IP Header Checksum of 0xffff, and that the central system objected to this checksum. We know that the central system objected to the checksum because it returned an ICMP Parameter Error with a Pointer of 10. The Parameter Error indicates that there is something wrong with the data the system has just received, and the Pointer identifies the specific data that the system thinks is in error. The tenth byte of the router's IP header is the IP Header Checksum. The data field of the ICMP error message returns the header that it believes is in error. When we displayed that data we noticed that when the central system returned the header, the checksum field was "corrected" to 0000. Clearly the central system disagreed with the router's checksum calculation.
Occasional checksum errors will occur. They can be caused by transmission problems, and are intended to detect these types of problems. Every protocol suite has a mechanism for recovering from checksum errors. So how should they be handled in TCP/IP?
To determine the correct protocol action in this situation, we turned to the authoritative sources -- the RFCs. RFC 791, Internet Protocol, provided information about the checksum calculation, but the best source for this particular problem was RFC 1122, Requirements for Internet Hosts -- Communication Layers, by R. Braden. This RFC provided two specific references that define the action to be taken. These excerpts are from page 29 of RFC 1122:
In the following, the action specified in certain cases is to "silently discard" a received datagram. This means that the datagram will be discarded without further processing and that the host will not send any ICMP error message (see Section 3.2.2) as a result....
... A host MUST verify the IP header checksum on every received datagram and silently discard every datagram that has a bad checksum.
Therefore, when a system receives a packet with a bad checksum, it is not supposed to do anything with it. The packet should be discarded, and the system should wait for the next packet to arrive. The system should not respond with an error message. A system cannot respond to a bad IP header checksum because it cannot really know where the packet came from. If the header checksum is in doubt, how do you know if the addresses in the header are correct? And if you don't know for sure where the packet came from, how can you respond to it?
IP relies on the upper-layer protocols to recover from these problems. If TCP is used (as it was in this case), the sending TCP eventually notices that the recipient has never acknowledged the segment, and it sends the segment again. If UDP is used, the sending application is responsible for recovering from the error. In neither case does recovery rely on an error message returned from the recipient.
Therefore, for an incorrect checksum, the central system should have simply discarded the bad packet. The vendor was informed of this problem and, much to their credit, they sent us a fix for the software within two weeks. Not only that, the fix worked perfectly!
Not all problems are resolved so cleanly. But the technique of analysis is the same no matter what the problem.
|  | |
| 13.7. Analyzing Protocol Problems |  | 13.9. Summary |

Copyright © 2002 O'Reilly & Associates. All rights reserved.