
 |  |
7.4. Interior Routing Protocols
Routing protocols are divided into two general groups: interior and exterior protocols. An interior protocol is a routing protocol used inside -- interior to -- an independent network system. In TCP/IP terminology, these independent network systems are called autonomous systems.[74] Within an autonomous system (AS), routing information is exchanged using an interior protocol chosen by the autonomous system's administration.
[74]Autonomous systems are described in Chapter 2, "Delivering the Data".
All interior routing protocols perform the same basic functions. They determine the "best" route to each destination and distribute routing information among the systems on a network. How they perform these functions (in particular, how they decide which routes are best) is what makes routing protocols different from each other. There are several interior protocols:
-
The Routing Information Protocol (RIP) is the interior protocol most commonly used on Unix systems. RIP is included as part of the Unix software delivered with most systems. It is adequate for local area networks and is simple to configure. RIP selects the route with the lowest "hop count" (metric) as the best route. The RIP hop count represents the number of gateways through which data must pass to reach its destination. RIP assumes the best route is the one that uses the fewest gateways. This approach to route choice is called a distance-vector algorithm.
-
Hello is a protocol that uses delay as the deciding factor when choosing the best route. Delay is the length of time it takes a datagram to make the round trip between its source and destination. A Hello packet contains a timestamp indicating when it was sent. When the packet arrives at its destination, the receiving system subtracts the timestamp from the current time to estimate how long it took the packet to arrive. Hello is not widely used. It was the interior protocol of the original 56 Kbps NSFNET backbone and has had very little use otherwise.
-
Intermediate System to Intermediate System (IS-IS) is an interior routing protocol from the OSI protocol suite. It is a Shortest Path First (SPF) link-state protocol. It was the interior routing protocol used on the T1 NSFNET backbone, and it is still used by some large service providers.
-
Open Shortest Path First (OSPF) is another link-state protocol developed for TCP/IP. It is suitable for very large networks and provides several advantages over RIP.
Of these protocols, we will discuss RIP and OSPF in detail. OSPF is widely used on routers. RIP is widely used on Unix systems. We will start the discussion with RIP.
7.4.1. Routing Information Protocol
As delivered with many Unix systems, Routing Information Protocol (RIP) is run by the routing daemon routed (pronounced "route" "d"). When routed starts, it issues a request for routing updates and then listens for responses to its request. When a system configured to supply RIP information hears the request, it responds with an update packet based on the information in its routing table. The update packet contains the destination addresses from the routing table and the routing metric associated with each destination. Update packets are issued in response to requests as well as periodically to keep routing information accurate.
To build the routing table, routed uses the information in the update packets. If the routing update contains a route to a destination that does not exist in the local routing table, the new route is added. If the update describes a route whose destination is already in the local table, the new route is used only if it is a better route. As noted previously, RIP considers a route with a lower " hop count" to be a better route. In RIP terminology, the hop count is called the cost of the route or the routing metric. We saw earlier that the routing metric in the local routing table can be manually controlled using the metric argument of the route command. To select the best route, RIP must first determine the cost of the route. The cost of a route is determined by adding the cost of reaching the gateway that sent the update to the metric contained in the RIP update packet. If the total cost is less than the cost of the current route, the new route is used.
RIP also deletes routes from the routing table. It accomplishes this in two ways. First, if the gateway to a destination says the cost of the route is greater than 15, the route is deleted. Second, RIP assumes that a gateway that doesn't send updates is dead. All routes through a gateway are deleted if no updates are received from that gateway for a specified time period. In general, RIP issues routing updates every 30 seconds. In many implementations, if a gateway does not issue routing updates for 180 seconds, all routes through that gateway are deleted from the routing table.
7.4.1.1. Running RIP with routed
To run RIP using the routing daemon (routed),[75] enter the following command:
[75]On some systems the routing daemon is in.routed.
# routed
The routed statement is often used without any command-line arguments, but you may want to use the -q option. The -q option prevents routed from advertising routes. It just listens to the routes advertised by other systems. If your computer is not a gateway, you should probably use the -q option.
In the section on static routing, we did not need to comment out the routed statement found in the inetinit startup file because Solaris runs routed only if the system has two network interfaces or if the /etc/gateways file is found. If your Unix system starts routed unconditionally, no action is required to run RIP; just boot your system and RIP will run. Otherwise, you need to make sure the routed command is in your startup and the conditions required by your system are met. The easiest way to get Solaris to run routed is to create a gateways file -- even an empty one will do.
routed reads /etc/gateways at startup and adds its information to the routing table. routed can build a functioning routing table simply by using the RIP updates received from the RIP suppliers. However, it is sometimes useful to supplement this information with, for example, an initial default route or information about a gateway that does not announce its routes. The /etc/gateways file stores this additional routing information.
The most common use of the /etc/gateways file is to define an active default route, so we'll use that as an example. This one example is sufficient because all entries in the /etc/gateways file have the same basic format. The following entry specifies crab as the default gateway:
net 0.0.0.0 gateway 172.16.12.1 metric 1 active
The entry starts with the keyword net. All entries start with either the keyword net or the keyword host to indicate whether the address that follows is a network address or a host address. The destination address 0.0.0.0 is the address used for the default route. In the route command we used the keyword default to indicate this route, but in /etc/gateways the default route is indicated by network address 0.0.0.0.
Next is the keyword gateway followed by the gateway's IP address. In this case it is the address of crab (172.16.12.1).
Then comes the keyword metric followed by a numeric metric value. The metric is the cost of the route. The metric was almost meaningless when used with static routing, but now that we are running RIP, the metric is used to make routing decisions. The RIP metric represents the number of gateways through which data must pass to reach its final destination. But as we saw with ifconfig, the metric is really an arbitrary value used by the administrator to prefer one route over another. (The system administrator is free to assign any metric value.) However, it is useful to vary the metric only if you have more than one route to the same destination. With only one gateway to the Internet, the correct metric to use for crab is 1.
All /etc/gateways entries end with either the keyword passive or the keyword active. "Passive" means the gateway listed in the entry is not required to provide RIP updates. Use passive to prevent RIP from deleting the route if no updates are expected from the gateway. A passive route is placed in the routing table and kept there as long as the system is up. In effect, it becomes a permanent static route.
The keyword active, on the other hand, creates a route that can be updated by RIP. An active gateway is expected to supply routing information and will be removed from the routing table if, over a period of time, it does not provide routing updates. Active routes are used to "prime the pump" during the RIP startup phase, with the expectation that the routes will be updated by RIP when the protocol is up and running.
Our sample entry ends with the keyword active, which means that this default route will be deleted if no routing updates are received from crab. Default routes are convenient; this is especially true when you use static routing. But when you use dynamic routing, default routes should be used with caution, especially if you have multiple gateways that can reach the same destination. A passive default route prevents the routing protocol from dynamically updating the route to reflect changing network conditions. Use an active default route that can be updated by the routing protocol.
RIP is easy to implement and simple to configure. Perfect! Well, not quite. RIP has three serious shortcomings:
- Limited network diameter
-
The longest RIP route is 15 hops. A RIP router cannot maintain a complete routing table for a network that has destinations more than 15 hops away. The hop count cannot be increased because of the second shortcoming.
- Slow convergence
-
Deleting a bad route sometimes requires the exchange of multiple routing update packets until the route's cost reaches 16. This is called "counting to infinity" because RIP keeps incrementing the route's cost until it becomes greater than the largest valid RIP metric. (In this case, 16 is infinity.) Additionally, RIP may wait 180 seconds before deleting the invalid routes. In network-speak, we say that these conditions delay the "convergence of routing," i.e., it takes a long time for the routing table to reflect the current state of the network.
- Classful routing
-
RIP interprets all addresses using the class rules described in Chapter 2, "Delivering the Data". For RIP, all addresses are class A, B, or C, which makes RIP incompatible with the current practice of interpreting an address based on the address bit mask.
Nothing can be done to change the limited network diameter. A small metric is essential to reduce the impact of counting to infinity. However, limited network size is the least important of RIP's shortcomings. The real work of improving RIP concentrates on the other two problems, slow convergence and classful routing.
Features have been added to RIP to address slow convergence. Before discussing them we must understand how the "counting-to-infinity" problem occurs. Figure 7-2 illustrates a network where a counting-to-infinity problem might happen.
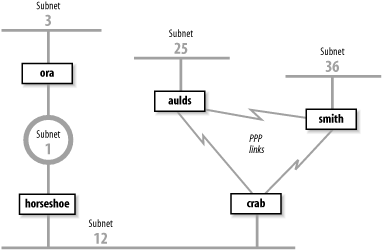
Figure 7-2. Sample network
Figure 7-2 shows that crab reaches subnet 3 through horseshoe and then through ora. Subnet 3 is two hops away from crab and one hop away from horseshoe. Therefore horseshoe advertises a cost of 1 for subnet 3 and crab advertises a cost of 2, and traffic continues to be routed through horseshoe. That is, until something goes wrong. If ora crashes, horseshoe waits for an update from ora for 180 seconds. While waiting, horseshoe continues to send updates to crab that keep the route to subnet 3 in crab's routing table. When horseshoe's timer finally expires, it removes all routes through ora from its routing table, including the route to subnet 3. It then receives an update from crab advertising that crab is two hops away from subnet 3. horseshoe installs this route and announces that it is three hops away from subnet 3. crab receives this update, installs the route, and announces that it is four hops away from subnet 3. Things continue on in this manner until the cost of the route to subnet 3 reaches 16 in both routing tables. If the update interval is 30 seconds, this could take a long time!
Split horizon and poison reverse are two features that attempt to avoid counting to infinity. Here's how:
- Split horizon
-
With this feature, a router does not advertise routes on the link from which those routes were obtained. This would solve the count-to-infinity problem described above. Using the split horizon rule, crab would not announce the route to subnet 3 on subnet 12 because it learned that route from the updates it received from horseshoe on subnet 12. While this feature works for the previous example described, it does not work for all count-to-infinity configurations. (More on this later.)
- Poison reverse
-
This feature is an enhancement of split horizon. It uses the same idea: "Don't advertise routes on the link from which those routes were obtained." But it adds a positive action to that essentially negative rule. Poison reverse says that a router should advertise an infinite distance for routes on this link. With poison reverse, crab would advertise subnet 3 with a cost of 16 to all systems on subnet 12. The cost of 16 means that subnet 3 cannot be reached through crab.
Split horizon and poison reverse solve the problem described above. But what happens if crab crashes? Refer to Figure 7-2. With split horizon, aulds and smith do not advertise to crab the route to subnet 12 because they learned the route from crab. They do, however, advertise the route to subnet 12 to each other. When crab goes down, aulds and smith perform their own count to infinity before they remove the route to subnet 12. Triggered updates address this problem.
Triggered updates are a big improvement. Instead of waiting the normal 30-second update interval, a triggered update is sent immediately. Therefore, when an upstream router crashes or a local link goes down, the router sends the changes to its neighbors immediately after it updates its local routing table. Without triggered updates, counting to infinity can take almost eight minutes! With triggered updates, neighbors are informed in a few seconds. Triggered updates also use network bandwidth efficiently. They don't include the full routing table; they include only the routes that have changed.
Triggered updates take positive action to eliminate bad routes. Using triggered updates, a router advertises the routes deleted from its routing table with an infinite cost to force downstream routers to also remove them. Again, look at Figure 7-2. If crab crashes, smith and aulds wait 180 seconds and remove the routes to subnets 1, 3, and 12 from their routing tables. They then send each other triggered updates with a metric of 16 for subnets 1, 3, and 12. Thus they tell each other that they cannot reach these networks and no count to infinity occurs. Split horizon, poison reverse, and triggered updates go a long way toward eliminating counting to infinity.
It is the final shortcoming -- the fact that RIP is incompatible with CIDR supernets and variable-length subnets -- that caused the RIP protocol to be moved to "historical" status in 1996. RIP is not compatible with current and future plans for the TCP/IP protocol stack. A new version of RIP had to be created to address this final problem.
7.4.2. RIP Version 2
RIP version 2 (RIP-2), defined in RFC 2453, is a new version of RIP. It is not a completely new protocol; it simply defines extensions to the RIP packet format. RIP-2 adds a network mask and a next-hop address to the destination address and metric found in the original RIP packet.
The network mask frees the RIP-2 router from the limitation of interpreting addresses based on outdated address class rules. The mask is applied to the destination address to determine how the address should be interpreted. Using the mask, RIP-2 routers support variable-length subnets and CIDR supernets.
The next-hop address is the IP address of the gateway that handles the route. If the address is 0.0.0.0, the source of the update packet is the gateway for the route. The next-hop route permits a RIP-2 supplier to provide routing information about gateways that do not speak RIP-2. Its function is similar to an ICMP Redirect, pointing to the best gateway for a route and eliminating extra routing hops.
RIP-2 adds other new features to RIP. It transmits updates via the multicast address 224.0.0.9 to reduce the load on systems that are not capable of processing a RIP-2 packet. RIP-2 also introduces a packet authentication scheme to reduce the possibility of accepting erroneous updates from misconfigured systems.
Despite these changes, RIP-2 is compatible with RIP. The original RIP specification allowed for future versions of RIP. RIP has a version number in the packet header, and several empty fields for extending the packet. The new values used by RIP-2 did not require any changes to the structure of the packet. The new values are simply placed in the empty fields that the original protocol reserved for future use. Properly implemented RIP routers can receive RIP-2 packets and extract the data that they need from the packet without becoming confused by the new data.
Split horizon, poison reverse, triggered updates, and RIP-2 eliminate most of the problems with the original RIP protocol. But RIP-2 is still a distance-vector protocol. There are other, newer routing technologies that are considered superior for large networks. In particular, link-state routing protocols are favored because they provide rapid routing convergence and reduce the possibility of routing loops.
7.4.3. Open Shortest Path First
Open Shortest Path First (OSPF), defined by RFC 2328, is a link-state protocol. As such, it is very different from RIP. A router running RIP shares information about the entire network with its neighbors. Conversely, a router running OSPF shares information about its neighbors with the entire network. The "entire network" means, at most, a single autonomous system. RIP doesn't try to learn about the entire Internet, and OSPF doesn't try to advertise to the entire Internet. That's not their job. These are interior routing protocols, so their job is to construct the routing inside an autonomous system. OSPF further refines this task by defining a hierarchy of routing areas within an autonomous system:
- Areas
-
An area is an arbitrary collection of interconnected networks, hosts, and routers. Areas exchange routing information with other areas within the autonomous system through area border routers.
- Backbone
-
A backbone is a special area that interconnects all of the other areas within an autonomous system. Every area must connect to the backbone because the backbone is responsible for distributing routing information between the areas.
- Stub area
-
A stub area has only one area border router, which means that there is only one route out of the area. In this case, the area border router does not need to advertise external routes to the other routers within the stub area. It can simply advertise itself as the default route.
Only a large autonomous system needs to be subdivided into areas. The sample network shown in Figure 7-2 is small and would not need to be divided. We can, however, use it to illustrate the different areas. We could divide this autonomous system into any areas we wish. Assume we divide it into three areas: area 1 contains subnet 3; area 2 contains subnet 1 and subnet 12; and area 3 contains subnet 25, subnet 36, and the PPP links. Furthermore, we could define area 1 as a stub area because ora is that area's only area border router. We also could define area 2 as the backbone area because it interconnects the other two areas and all routing information between areas 1 and 3 must be distributed by area 2. Area 2 contains two area border routers, crab and ora, and one interior router, horseshoe. Area 3 contains three routers: crab, smith, and aulds.
Clearly OSPF provides lots of flexibility for subdividing an autonomous system. But why is it necessary? One problem for a link-state protocol is the large quantity of data that can be collected in the link-state database and the amount of time it can take to calculate the routes from that data. A look at the protocol shows why this is true.
Every OSPF router builds a directed graph of the entire network using the Dijkstra Shortest Path First (SPF) algorithm. A directed graph is a map of the network from the perspective of the router; that is, the root of the graph is the router. The graph is built from the link-state database, which includes information about every router on the network and all the neighbors of every router. The link-state database for the autonomous system in Figure 7-2 contains 5 routers and 10 neighbors: ora has 1 neighbor, horseshoe; horseshoe has 2 neighbors, ora and crab; crab has 3 neighbors, horseshoe, aulds, and smith; aulds has 2 neighbors, crab and smith; and smith has 2 neighbors, aulds and crab. Figure 7-3 shows the graph of this autonomous system from the perspective of ora.
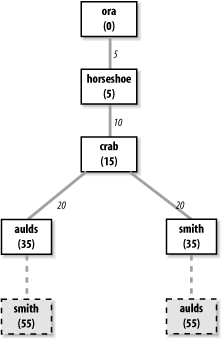
Figure 7-3. A network graph
The Dijkstra algorithm builds the map in this manner:
-
Install the local system as the root of the map with a cost of 0.
-
Locate the neighbors of the system just installed and add them to the map. The cost of reaching the neighbors is calculated as the sum of the cost of reaching the system just installed plus the cost it advertises for reaching each neighbor. For example, assume that crab advertises a cost of 20 for aulds and that the cost of reaching crab is 15. Then the cost for aulds in ora's map is 35.
-
Walk through the map and select the lowest-cost path for each destination. For example, when aulds is added to the map, its neighbors include smith. The path to smith through aulds is temporarily added to the map. In this third phase of the algorithm, the cost of reaching smith through crab is compared to the cost of reaching it through aulds. The lowest-cost path is selected. Figure 7-3 shows the deleted paths in dotted lines. Steps 2 and 3 of the algorithm are repeated for every system in the link-state database.
The information in the link-state database is gathered and distributed in a simple and efficient manner. An OSPF router discovers its neighbors through the use of Hello packets.[76] It sends Hello packets and listens for Hello packets from adjacent routers. The Hello packet identifies the local router and lists the adjacent routers from which it has received packets. When a router receives a Hello packet that lists it as an adjacent router, it knows it has found a neighbor. It knows this because it can hear packets from that neighbor and, because the neighbor lists it as an adjacent router, the neighbor must be able to hear packets from it. The newly discovered neighbor is added to the local system's neighbor list.
[76]Don't confuse Hello packets with the Hello protocol. These are OSPF Hello packets.
The OSPF router then advertises all of its neighbors. It does this by flooding a Link-State Advertisement (LSA) to the entire network. The LSA contains the address of every neighbor and the cost of reaching that neighbor from the local system. Flooding means that the router sends the LSA out of every interface and that every router that receives the LSA sends it out of every interface except the one from which it was received. To avoid flooding duplicate LSAs, the routers store a copy of the LSAs they receive and discard duplicates.
Figure 7-2 provides an example. When OSPF starts on horseshoe it sends a Hello packet on subnet 1 and one on subnet 12. ora and crab hear the Hello and respond with Hello packets that list horseshoe as an adjacent router. horseshoe hears their Hello packets and adds them to its neighbor list. horseshoe then creates an LSA that lists ora and crab as neighbors with appropriate costs assigned to each. For instance, horseshoe might assign a cost of 5 to ora and a cost of 10 to crab. horseshoe then floods the LSA on subnet 1 and subnet 12. ora hears the LSA and floods it on subnet 3. crab receives the LSA and floods it on both of its PPP links. aulds floods the LSA on the link toward smith, and smith floods it on the same link to aulds. When aulds and smith received the second copy of the LSA, they discarded it because it duplicated one that they had already received from crab. In this manner, every router in the entire network receives every other router's link-state advertisement.
OSPF routers track the state of their neighbors by listening for Hello packets. Hello packets are issued by all routers on a periodic basis. When a router stops issuing packets, it or the link it is attached to is assumed to be down. Its neighbors update their LSA and flood them through the network. The new LSAs are included into the link-state database on every router on the network, and every router recalculates its network map based on this new information. Clearly, limiting the number of routers by limiting the size of the network reduces the burden of recalculating the map. For many networks, the entire autonomous system is small enough. For others, dividing the autonomous system into areas improves efficiency.
Another feature of OSPF that improves efficiency is the designated router. The designated router is one router on the network that treats all other routers on the network as its neighbors, while all other routers treat only the designated router as their neighbor. This helps reduce the size of the link-state database and thus improves the speed of the Shortest-Path-First calculation. Imagine a broadcast network with 5 routers. Five routers each with 4 neighbors produce a link-state database with 20 entries. But if one of those routers is the designated router, then that router has 4 neighbors and all other routers have only 1 neighbor, for a total of 10 link-state database entries. While there is no need for a designated router on such a small network, the larger the network, the more dramatic the gains. For example, a broadcast network with 25 routers has a link-state database of 50 entries when a designated router is used, versus a database of 600 entries without one.
OSPF provides the router with an end-to-end view of the route between two systems instead of the limited next-hop view provided by RIP. Flooding quickly disseminates routing information throughout the network. Limiting the size of the link-state database through areas and designated routers speeds the SPF calculation. Taken altogether, OSPF is an efficient link-state routing protocol.
OSPF also offers additional features that RIP doesn't. It provides simple password authentication to ensure that the update comes from a valid router using an eight-character, clear-text password. It provides Message Digest 5 (MD5) crypto-checksum for stronger authentication.
OSPF also supports equal-cost multi-path routing . This mouthful means that OSPF routers can maintain more than one path to a single destination. Given the proper conditions, this feature can be used for load balancing across multiple network links. However, many systems are not designed to take advantage of this feature. Refer to your router's documentation to see if it supports load balancing across equal-cost OSPF routes.
With all of these features, OSPF is the preferred TCP/IP interior routing protocol for dedicated routers.
|  | |
| 7.3. Building a Static Routing Table |  | 7.5. Exterior Routing Protocols |

Copyright © 2002 O'Reilly & Associates. All rights reserved.