
 |  |
Chapter 18. Client-Side Performance Tuning
Contents:
Slow server compensationSoft mount issues
Adjusting for network reliability problems
NFS over wide-area networks
NFS async thread tuning
Attribute caching
Mount point constructions
Stale filehandles
18.1. Slow server compensation
The RPC retransmission algorithm cannot distinguish between a slow server and a congested network. If a reply is not received from the server within the RPC timeout period, the request is retransmitted subject to the timeout and retransmission parameters for that mount point. It is immaterial to the RPC mechanism whether the original request is still enqueued on the server or if it was lost on the network. Excessive RPC retransmissions place an additional strain on the server, further degrading response time.18.1.1. Identifying NFS retransmissions
Inspection of the load average and disk activity on the servers may indicate that the servers are heavily loaded and imposing the tightest constraint. The NFS client-side statistics provide the most concrete evidence that one or more slow servers are to blame:
The -rc option is given to nfsstat to look at the RPC statistics only, for client-side NFS operations. The call type demographics contained in the NFS-specific statistics are not of value in this analysis. The test for a slow server is having badxid and timeout of the same magnitude. In the previous example, badxid is nearly a third the value of timeout for connection-oriented RPC, and nearly half the value of timeout for connectionless RPC. Connection-oriented transports use a higher timeout than connectionless transports, therefore the number of timeouts will generally be less for connection-oriented transports. The high badxid count implies that requests are reaching the various NFS servers, but the servers are too loaded to send replies before the local host's RPC calls time out and are retransmitted. badxid is incremented each time a duplicate reply is received for a retransmitted request (an RPC request retains its XID through all retransmission cycles). In this case, the server is replying to all requests, including the retransmitted ones. The client is simply not patient enough to wait for replies from the slow server. If there is more than one NFS server, the client may be outpacing all of them or just one particularly sluggish node.% nfsstat -rc Client rpc: Connection-oriented: calls badcalls badxids timeouts newcreds badverfs 1753584 1412 18 64 0 0 timers cantconn nomem interrupts 0 1317 0 18 Connectionless: calls badcalls retrans badxids timeouts newcreds 12443 41 334 80 166 0 badverfs timers nomem cantsend 0 4321 0 206
If the server has a duplicate request cache, retransmitted requests that match a non-idempotent NFS call currently in progress are ignored. Only those requests in progress are recognized and filtered, so it is still possible for a sufficiently loaded server to generate duplicate replies that show up in the badxid counts of its clients. Without a duplicate request cache, badxid and timeout may be nearly equal, while the cache will reduce the number of duplicate replies. With or without a duplicate request cache, if the badxid and timeout statistics reported by nfsstat (on the client) are of the same magnitude, then server performance is an issue deserving further investigation.
A mixture of network and server-related problems can make interpretation of the nfsstat figures difficult. A client served by four hosts may find that two of the hosts are particularly slow while a third is located across a network router that is digesting streams of large write packets. One slow server can be masked by other, faster servers: a retransmission rate of 10% (calculated as timeout/calls) would indicate short periods of server sluggishness or network congestion if the retransmissions were evenly distributed among all servers. However, if all timeouts occurred while talking to just one server, the retransmission rate for that server could be 50% or higher.
A simple method for finding the distribution of retransmitted requests is to perform the same set of disk operations on each server, measuring the incremental number of RPC timeouts that occur when loading each server in turn. This experiment may point to a server that is noticeably slower than its peers, if a large percentage of the RPC timeouts are attributed to that host. Alternatively, you may shift your focus away from server performance if timeouts are fairly evenly distributed or if no timeouts occur during the server loading experiment. Fluctuations in server performance may vary by the time of day, so that more timeouts occur during periods of peak server usage in the morning and after lunch, for example.
Server response time may be clamped at some minimum value due to fixed-cost delays of sending packets through routers, or due to static configurations that cannot be changed for political or historical reasons. If server response cannot be improved, then the clients of that server must adjust their mount parameters to avoid further loading it with retransmitted requests. The relative patience of the client is determined by the timeout, retransmission count, and hard-mount variables.
18.1.2. Timeout period calculation
The timeout period is specified by the mount parameter timeo and is expressed in tenths of a second. For NFS over UDP, it specifies the value of a minor timeout, which occurs when the client RPC call over UDP does not receive a reply within the timeo period. In this case, the timeout period is doubled, and the RPC request is sent again. The process is repeated until the retransmission count specified by the retrans mount parameter is reached. A major timeout occurs when no reply is received after the retransmission threshold is reached. The default value for the minor timeout is vendor-specific; it can range from 5 to 13 tenths of a second. By default, clients are configured to retransmit from three to five times, although this value is also vendor-specific.When using NFS over TCP, the retrans parameter has no effect, and it is up to the TCP transport to generate the necessary retransmissions on behalf of NFS until the value specified by the timeo parameter is reached. In contrast to NFS over UDP, the mount parameter timeo in NFS over TCP specifies the value of a major timeout, and is typically in the range of hundreds of a tenth of a second (for example, Solaris has a major timeout of 600 tenths of a second). The minor timeout value is internally controlled by the underlying TCP transport, and all you have to worry about is the value of the major timeout specified by timeo.
After a major timeout, the message:
is printed on the client's console. If a reply is eventually received, the "not responding" message is followed with the message:NFS server host not responding still trying
Hard-mounting a filesystem guarantees that the sequence of retransmissions continues until the server replies. After a major timeout on a hard-mounted filesystem, the initial timeout period is doubled, beginning a new major cycle. Hard mounts are the default option. For example, a filesystem mounted via:[55]NFS server host ok
[55]We specifically use proto=udp to force the Solaris client to use the UDP protocol when communicating with the server, since the client by default will attempt to first communicate over TCP. Linux, on the other hand, uses UDP as the default transport for NFS.
has the retransmission sequence shown in Table 18-1.# mount -o proto=udp,retrans=3,timeo=10 wahoo:/export/home/wahoo /mnt
Table 18-1. NFS timeout sequence for NFS over UDP
|
Absolute Time
|
Current Timeout
|
New Timeout
|
Event
|
|---|---|---|---|
|
1.0
|
1.0
|
2.0
|
Minor
|
|
3.0
|
2.0
|
4.0
|
Minor
|
|
7.0
|
4.0
|
2.0
|
Major, double initial timeout
|
|
...NFS server wahoo not responding...
|
|||
|
9.0
|
2.0
|
4.0
|
Minor
|
|
13.0
|
4.0
|
8.0
|
Minor
|
|
21.0
|
8.0
|
4.0
|
Major, double initial timeout
|
Timeout periods are not increased without bound, for instance, the timeout period never exceeds 20 seconds (timeo=200) for Solaris clients using UDP, and 60 seconds for Linux. The system may also impose a minimum timeout period in order to avoid retransmitting too aggressively. Because certain NFS operations take longer to complete than others, Solaris uses three different values for the minimum (and initial) timeout of the various NFS operations. NFS write operations typically take the longest, therefore a minimum timeout of 1,250 msecs is used. NFS read operations have a minimum timeout of 875 msecs, and operations that act on metadata (such as getattr, lookup, access, etc.) usually take the least time, therefore they have the smaller minimum timeout of 750 msecs.
To accommodate slower servers, increase the timeo parameter used in the automounter maps or /etc/vfstab. Increasing retrans for UDP increases the length of the major timeout period, but it does so at the expense of sending more requests to the NFS server. These duplicate requests further load the server, particularly when they require repeating disk operations. In many cases, the client receives a reply after sending the second or third retransmission, so doubling the initial timeout period eliminates about half of the NFS calls sent to the slow server. In general, increasing the NFS RPC timeout is more helpful than increasing the retransmission count for hard-mounted filesystems accessed over UDP. If the server does not respond to the first few RPC requests, it is likely it will not respond for a "long" time, compared to the RPC timeout period. It's best to let the client sit back, double its timeout period on major timeouts, and wait for the server to recover. Increasing the retransmission count simply increases the noise level on the network while the client is waiting for the server to respond.Note that Solaris clients only use the timeo mount parameter as a starting value. The Solaris client constantly adjusts the actual timeout according to the smoothed average round-trip time experienced during NFS operations to the server. This allows the client to dynamically adjust the amount of time it is willing to wait for NFS responses given the recent past responsiveness of the NFS server.
Use the nfsstat -m command to review the kernel's observed response times over the UDP transport for all NFS mounts:
% nfsstat -m
/mnt from mahimahi:/export
Flags: vers=3,proto=udp,sec=sys,hard,intr,link,symlink,acl,rsize=32768,
wsize=32768,retrans=2,timeo=15
Attr cache: acregmin=3,acregmax=60,acdirmin=30,acdirmax=60
Lookups: srtt=13 (32ms), dev=6 (30ms), cur=4 (80ms)
Reads: srtt=24 (60ms), dev=14 (70ms), cur=10 (200ms)
Writes: srtt=46 (115ms), dev=27 (135ms), cur=19 (380ms)
All: srtt=20 (50ms), dev=11 (55ms), cur=8 (160ms)Without the kernel's values as a baseline, choosing a new timeout value is best done empirically. Doubling the initial value is a good baseline; after changing the timeout value observe the RPC timeout rate and badxid rate using nfsstat. At first glance, it does not appear that there is any harm in immediately going to timeo=200, the maximum initial timeout value used in the retransmission algorithm. If server performance is the sole constraint, then this is a fair assumption. However, even a well-tuned network endures bursts of traffic that can cause packets to be lost at congested network hardware interfaces or dropped by the server. In this case, the excessively long timeout will have a dramatic impact on client performance. With timeo=200, RPC retransmissions "avoid" network congestion by waiting for minutes while the actual traffic peak may have been only a few milliseconds in duration.
18.1.3. Retransmission rate thresholds
There is little agreement among system administrators about acceptable retransmission rate thresholds. Some people claim that any request retransmission indicates a performance problem, while others chose an arbitrary percentage as a "goal." Determining the retransmission rate threshold for your NFS clients depends upon your choice of the timeo mount parameter and your expected response time variations. The equation in Figure 18-1 expresses the expected retransmission rate as a function of the allowable response time variation and the timeo parameter.[56][56]This retransmission threshold equation was originally presented in the Prestoserve User's Manual, March 1991 edition. The Manual and the Prestoserve NFS write accelerator are produced by Legato Systems.
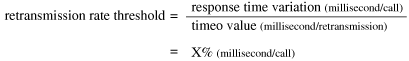
Figure 18-1. NFS retransmission threshold
If you allow a response time fluctuation of five milliseconds, or about 20% of a 25 millisecond average response time, and use a 1.1 second (1100 millisecond) timeout period for metadata operations, then your expected retransmission rate is (5/1100) = .45%.If you increase your timeout value, this equation dictates that you should decrease your retransmission rate threshold. This makes sense: if you make the clients more tolerant of a slow NFS server, they shouldn't be sending as many NFS RPC retransmissions. Similarly, if you want less variation in NFS client performance, and decide to reduce your allowable response time variation, you also need to reduce your retransmission threshold.
18.1.4. NFS over TCP is your friend
You can alternatively use NFS over TCP to ensure that data is not retransmitted excessively. This, of course, requires that both, the client and server support NFS over TCP. At the time of this writing, many NFS implementations already support NFS over TCP. The added TCP functionality comes at a price: TCP is a heavier weight protocol that uses more CPU cycles to perform extra checks per packet. Because of this, LAN environments have traditionally used NFS over UDP. Improvements in hardware, as well as better TCP implementations have narrowed the performance gap between the two.A Solaris client by default uses NFS Version 3 over TCP. If the server does not support it, then the client automatically falls back to NFS Version 3 over UDP or NFS Version 2 over one of the supported transports. Use the proto=tcp option to force a Solaris client to mount the filesystem using TCP only. In this case, the mount will fail instead of falling back to UDP if the server does not support TCP:
Use the tcp option to force a Linux client to mount the filesystem using TCP instead of its default of UDP. Again, if the server does not support TCP, the mount attempt will fail:# mount -o proto=tcp wahoo:/export /mnt
TCP partitions the payload into segments equivalent to the size of an Ethernet packet. If one of the segments gets lost, NFS does not need to retransmit the entire operation because TCP itself handles the retransmissions of the segments. In addition to retransmitting only the lost segment when necessary, TCP also controls the transmission rate in order to utilize the network resources more adequately, taking into account the ability of the receiver to consume the packets. This is accomplished through a simple flow control mechanism, where the receiver indicates to the sender how much data it can receive.# mount -o tcp wahoo:/export /mnt
TCP is extremely useful in error-prone or lossy networks, such as many WAN environments, which we discuss later in this chapter.
|  | |
| 17.5. Protocol filtering |  | 18.2. Soft mount issues |
