
 |  |
Chapter 3. Network Information Service Operation
Contents:
Masters, slaves, and clientsBasics of NIS management
Files managed under NIS
Trace of a key match
The Network Information System (NIS) addresses these problems. It is a distributed database system that replaces copies of commonly replicated configuration files with a centralized management facility. Instead of having to manage each host's files (like /etc/hosts, /etc/passwd, /etc/group, /etc/ethers, and so on), you maintain one database for each file on one central server. Machines that are using NIS retrieve information as needed from these databases. If you add a new system to the network, you can modify one file on a central server and propagate this change to the rest of the network, rather than changing the hosts file for each individual host on the network. For a network of two or three systems, the difference may not be crucial; but for a large network with hundreds of systems, NIS is life-saving.
Because NIS enforces consistent views of files on the network, it is suited for files that have no host-specific information in them. The /etc/vfstab file of filesystems and mount points, for example, is a terrible candidate for management by NIS because it's different on just about every machine. Files that are generally the same on all hosts in a network, such as /etc/passwd and /etc/hosts, fit the NIS model of a distributed database nicely.
In addition to managing configuration files, NIS can be used for any general data file that is accessed on one or more key fields. In a later chapter, we will discuss how to use NIS to manage your own site-specific databases.
This discussion of networking services starts with NIS because it provides the consistency that is a prerequisite for the successful administration of a distributed filesystem. Imagine a network in which you share files from a common server, but you have a different home directory and user ID value on every host. The advantages of the shared filesystem are lost in such a loosely run network: you can't always read or write your files due to permission problems, and you don't get a consistent view of your files between machines because you don't always end up in the same home directory. We'll start with a brief description of the different roles systems play under NIS, and then look at how to install NIS on each type of machine.
3.1. Masters, slaves, and clients
NIS is built on the client-server model. An NIS server is a host that contains NIS data files, called maps. Clients are hosts that request information from these maps. Servers are further divided into master and slave servers: the master server is the true single owner of the map data. Slave NIS servers handle client requests, but they do not modify the NIS maps. The master server is responsible for all map maintenance and distribution to its slave servers. Once an NIS map is built on the master to include a change, the new map file is distributed to all slave servers. NIS clients "see" these changes when they perform queries on the map file -- it doesn't matter whether the clients are talking to a master or a slave server, because once the map data is distributed, all NIS servers have the same information.Before going any further, let's take a quick and simple look at how this works. Figure 3-1 shows the relationship between masters, slaves, and clients.
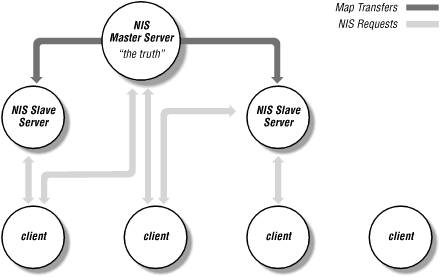
Figure 3-1. NIS masters, slaves, and clients
Consider the hosts NIS map, which replaces the /etc/hosts files on individual systems. If you're familiar with Unix adminstration, you know that this file tells the system how to convert hostnames into IP (internet) addresses. When a client needs to look up the internet address of some system, it would normally read the hosts file. If NIS is running, however, the client bypasses its hosts file, and instead asks an NIS server (either a master or a slave server -- it doesn't make any difference) for the information it needs.Now the other side of the coin: you've added a system, and need to modify the hosts NIS map. You only modify the hosts file on the "master server" -- remember, the master server knows the "truth" about the network.[4] Once you've made your changes, you can rebuild the NIS database (i.e., the NIS maps) on the master server. The master server then distributes new versions of the NIS maps to the slave servers, which now provide the updated information to the NIS clients.
[4]Remember: when you want to make a global change to the network, you must modify the file on the master server. Global changes made to slave servers or clients will, at best, be ignored.With the distinction between NIS servers and clients firmly established, we can see that each system fits into the NIS scheme in one of three ways:
- Client only
- This is typical of desktop workstations, where the system administrator tries to minimize the amount of host-specific tailoring required to bring a system onto the network. As an NIS client, the host gets all of its common configuration information from an extant server.
- Server only
- While the host services client requests for map information, it does not use NIS for its own operation. Server-only configuration may be useful when a server must provide global host and password information for the NIS clients, but security concerns prohibit the server from using these same files. However, bypassing the central configuration scheme opens some of the same loopholes that NIS was intended to close. Although it is possible to configure a system to be an NIS server only, we don't recommend it and don't cover it in this book.
- Client and server
- In most cases, an NIS server also functions as an NIS client so that its management is streamlined with that of other client-only hosts.
Now that we have this client-server model for the major administrative files, we need a way to discuss where and when a particular set of files applies to a given host. It is much too simple-minded for a single set of files to apply to every host on a network; a reasonable system must support different clusters of systems with different administrative requirements. For example, a group of administrative systems and a group of research systems might share the same network. In most cases, these two clusters of systems don't need to share the same administrative information. In some cases, sharing the same administrative files might be harmful.
To allow an administrator to set different policies for different systems, NIS provides the concept of a domain. Most precisely, a domain is a set of NIS maps. A client can refer to a map (for example, the hosts map) from any of several different domains. Most of the time, however, any given host will only look up data from one set of NIS maps. Therefore, it's common (although not precisely correct) to use the term "domain" to mean "the group of systems that share a set of NIS maps." All systems that need to share common configuration information are put into an NIS domain. Although each system can potentially look up information in any NIS domain, each system is assigned to a "default domain," meaning that the system, by default, looks up information from a particular set of NIS maps. In our example, the research systems would, by default, look at the maps in the research domain, rather than the maps from the accounting domain; and so on.
It is up to the administrator (or administrators) to decide how many different domains are needed. In Chapter 4, "System Management Using NIS", we will give some rules-of-thumb for deciding how many domains are needed. Lest you think this is terribly complex, we'll tell you now: many networks, possibly even most small networks, can get by with a single domain. We will also take a closer look at the precise definition of an NIS domain.
|  | |
| 2.4. Which directory service to use |  | 3.2. Basics of NIS management |
