

|
Chapter 11 Troubleshooting TCP/IP |

|
11.5 Checking Routing
The "network unreachable" error message clearly indicates a routing problem. If the problem is in the local host's routing table, it is easy to detect and resolve. First, use netstat -nr and grep to see whether or not a valid route to your destination is installed in the routing table. This example checks for a specific route to network 128.8.0.0:
%netstat -nr | grep '128\.8\.0'128.8.0.0 26.20.0.16 UG 0 37 std0
This same test, run on a system that did not have this route in its routing table, would return no response at all. For example, a user reports that the "network is down" because he cannot ftp to sunsite.unc.edu , and a ping test returns the following results:
%ping -s sunsite.unc.edu 56 2PING sunsite.unc.edu: 56 data bytes sendto: Network is unreachable ping: wrote sunsite.unc.edu 64 chars, ret=-1 sendto: Network is unreachable ping: wrote sunsite.unc.edu 64 chars, ret=-1 ----sunsite.unc.edu PING Statistics---- 2 packets transmitted, 0 packets received, 100% packet loss
Based on the "network unreachable" error message, check the user's routing table. In our example, we're looking for a route to sunsite.unc.edu . The IP address [4] of sunsite.unc.edu is 152.2.254.81, which is a class B address. Remember that routes are network-oriented. So we check for a route to network 152.2.0.0:
[4] Use nslookup to find the IP address if you don't know it. nslookup is discussed later in this chapter.
%netstat -nr | grep '152\.2\.0\.0'%
This test shows that there is no specific route to 152.2.0.0. If a route was found, grep would display it. Since there's no specific route to the destination, remember to look for a default route. This example shows a successful check for a default route:
%netstat -nr | grep defdefault 172.16.12.1 UG 0 101277 le0
If netstat shows the correct specific route, or a valid default route, the problem is not in the routing table. In that case, use traceroute , as described later in this chapter, to trace the route all the way to its destination.
If netstat doesn't return the expected route, it's a local routing problem. There are two ways to approach local routing problems, depending on whether the system uses static or dynamic routing. If you're using static routing, install the missing route using the route add command. Remember, most systems that use static routing rely on a default route, so the missing route could be the default route. Make sure that the startup files add the needed route to the table whenever the system reboots. See Chapter 7, Configuring Routing , for details about the route add command.
If you're using dynamic routing, make sure that the routing program is running. For example, the command below makes sure that gated is running:
%ps `cat /etc/gated.pid`PID TT STAT TIME COMMAND 27711 ? S 304:59 gated -tep /etc/log/gated.log
If the correct routing daemon is not running, restart it and specify tracing. Tracing allows you to check for problems that might be causing the daemon to terminate abnormally.
11.5.1 Checking RIP Updates
If the routing daemon is running and the local system receives routing updates via Routing Information Protocol (RIP), use ripquery to check the updates received from your RIP suppliers. For example, to check the RIP updates being received from almond and pecan , the peanut administrator enters the following command:
%ripquery -1 -n -r almond pecan44 bytes from almond.nuts.com(172.16.12.1): 0.0.0.0, metric 3 10.0.0.0, metric 0 264 bytes from pecan.nuts.com(172.16.12.3): 172.16.5.0, metric 2 172.16.3.0, metric 2 . . . 172.16.12.0, metric 2 172.16.13.0, metric 2
After an initial line identifying the gateway, ripquery shows the contents of the incoming RIP packets, one line per route. The first line of the report above indicates that ripquery received a response from almond . That line is followed by two lines for the two routes advertised by almond . almond advertises the default route (destination 0.0.0.0) with a metric of 3, and its direct route to Milnet (destination 10.0.0.0) with a metric of 0. Next, ripquery shows the routes advertised by pecan . These are the routes to the other nuts-net subnets.
The three ripquery options used in this example are:
- -1
-
Sends the query as a RIP version 1 packet. By default, queries are sent as RIP version 2 packets. Older systems may only support RIP version 1.
- -n
-
Causes ripquery to display all output in numeric form. ripquery attempts to resolve all IP addresses to names if the -n option is not specified. It's a good idea to use the -n option; it produces a cleaner display, and you don't waste time resolving names.
- -r
-
Directs ripquery to use the RIP REQUEST command, instead of the RIP POLL command, to query the RIP supplier. RIP POLL is not universally supported. You are more likely to get a successful response if you specify -r on the ripquery command line.
The routes returned in these updates should be the routes you expect. If they are not, or if no routes are returned, check the configuration of the RIP suppliers. Routing configuration problems cause RIP suppliers to advertise routes that they shouldn't, or to fail to advertise the routes that they should. You can detect these problems only by applying your knowledge of your network configuration. You must know what is right to detect what is wrong. Don't expect to see error messages or strange garbled routes. For example, assume that in the previous test pecan returned the following update:
264 bytes from pecan.nuts.com(172.16.12.3): 0.0.0.0, metric 2 172.16.3.0, metric 2 . . . 172.16.12.0, metric 2 172.16.13.0, metric 2
This update shows that pecan is advertising itself as a default gateway with a lower cost (2 versus 3) than almond . This would cause every host on this subnet to use pecan as its default gateway. If this is not what you wanted, the routing configuration of pecan should be corrected. [5]
[5] Correct routing configuration is discussed in Chapter 7 .
11.5.2 Tracing Routes
If the local routing table and RIP suppliers are correct, the problem may be occurring some distance away from the local host. Remote routing problems can cause the "no answer" error message, as well as the "network unreachable" error message. But the "network unreachable" message does not always signify a routing problem. It can mean that the remote network cannot be reached because something is down between the local host and the remote destination. traceroute is the program that can help you locate these problems.
traceroute traces the route of UDP packets from the local host to a remote host. It prints the name (if it can be determined) and IP address of each gateway along the route to the remote host.
traceroute uses two techniques, small ttl (time-to-live) values and an invalid port number, to trace packets to their destination. traceroute sends out UDP packets with small ttl values to detect the intermediate gateways. The ttl values start at 1 and increase in increments of 1 for each group of three UDP packets sent. When a gateway receives a packet, it decrements the ttl. If the ttl is then 0, the packet is not forwarded and an ICMP "Time Exceeded" message is returned to the source of the packet. traceroute displays one line of output for each gateway from which it receives a "Time Exceeded" message. Figure 11.2 shows a sample of the single line of output that is displayed for a gateway, and it shows the meaning of each field in the line.
Figure 11.2: traceroute output
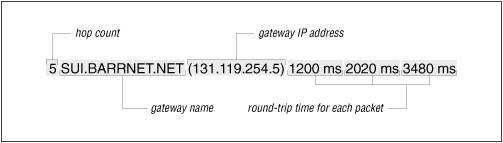
When the destination host receives a packet from
traceroute
, it
returns an ICMP "Unreachable Port" message. This happens because
traceroute
intentionally uses an invalid port number (33434) to
force this error. When
traceroute
receives the "Unreachable
Port" message, it knows that it has reached the destination host, and
it terminates the trace. So,
traceroute
is able to
develop a list of the gateways, starting at one hop away and
increasing one hop at a time until the remote host is reached.
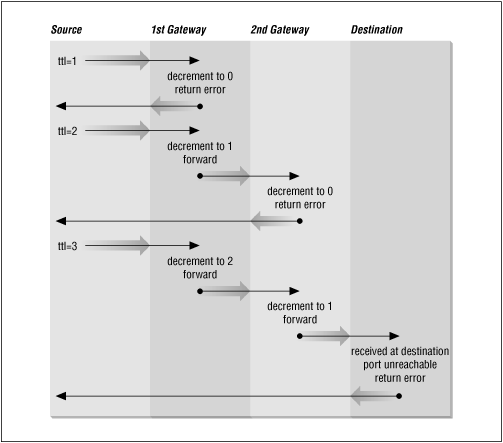
Figure 11.3
illustrates the flow of packets tracing to a host three hops away. The following shows
a
traceroute
to
ds.internic.net
from a Linux system hanging off
BBN PlaNET.
traceroute
sends out three packets at
each ttl value. If no response is received to a packet,
traceroute
prints an asterisk (
*
). If a response is received,
traceroute
displays the name and address of the gateway that
responded, and the packet's round-trip time in milliseconds.
Figure 11.3: Flow of traceroute packets
%traceroute ds.internic.nettraceroute to ds.internic.net (198.49.45.10), 30 hops max, 40 byte packets 1 gw-55.nuts.com (172.16.55.200) 0.95 ms 0.91 ms 0.91 ms 2 172.16.230.254 (172.16.230.254) 1.51 ms 1.33 ms 1.29 ms 3 gw225.nuts.com (172.16.2.252) 4.13 ms 1.94 ms 2.20 ms 4 192.221.253.2 (192.221.253.2) 52.90 ms 81.19 ms 58.09 ms 5 washdc1-br2.bbnplanet.net (4.0.36.17) 6.5 ms 5.8 ms 5.88 ms 6 nyc1-br1.bbnplanet.net (4.0.1.114) 13.24 ms 12.71 ms 12.96 ms 7 nyc1-br2.bbnplanet.net (4.0.1.178) 14.64 ms 13.32 ms 12.21 ms 8 cambridge1-br1.bbnplanet.net (4.0.2.86) 28.84 ms 27.78 ms 23.56 ms 9 cambridge1-cr14.bbnplanet.net (199.94.205.14) 19.9 ms 24.7 ms 22.3 ms 10 attbcstoll.bbnplanet.net (206.34.99.38) 34.31 ms 36.63 ms 32.21 ms 11 ds0.internic.net (198.49.45.10) 33.19 ms 33.34 ms *
This trace shows that 10 intermediate gateways are involved, that packets are making the trip, and that round-trip travel time for packets from this host to ds.internic.net is about 33 ms.
Variations and bugs in the implementation of ICMP on different types of gateways, and the unpredictable nature of the path a datagram can take through a network, can cause some odd displays. For this reason, you shouldn't examine the output of traceroute too closely. The most important things in the traceroute output are:
-
Did the packet get to its remote destination?
-
If not, where did it stop?
In the code below we show another trace of the path to ds.internic.net . This time the trace does not go all the way through to the InterNIC.
%traceroute ds.internic.nettraceroute to ds.internic.net (198.49.45.10), 30 hops max, 40 byte packets 1 gw-55.nuts.com (172.16.55.200) 0.959 ms 0.917 ms 0.913 ms 2 172.16.230.254 (172.16.230.254) 1.518 ms 1.337 ms 1.296 ms 3 gw225.nuts.com (172.16.2.252) 4.137 ms 1.945 ms 2.209 ms 4 192.221.253.2 (192.221.253.2) 52.903 ms 81.19 ms 58.097 ms 5 washdc1-br2.bbnplanet.net (4.0.36.17) 6.5 ms 5.8 ms 5.888 ms 6 nyc1-br1.bbnplanet.net (4.0.1.114) 13.244 ms 12.717 ms 12.968 ms 7 nyc1-br2.bbnplanet.net (4.0.1.178) 14.649 ms 13.323 ms 12.212 ms 8 cambridge1-br1.bbnplanet.net (4.0.2.86) 28.842 ms 27.784 ms 23.561 ms 9 * * * 10 * * * . . . 29 * * * 30 * * *
When traceroute fails to get packets through to the remote end system, the trace trails off, displaying a series of three asterisks at each hop count until the count reaches 30. If this happens, contact the administrator of the remote host you're trying to reach, and the administrator of the last gateway displayed in the trace. Describe the problem to them; they may be able to help. [6] In our example, the last gateway that responded to our packets was cambridge1-br1.bbnplanet.net . We would contact this system administrator, and the administrator of ds.internic.net .
[6] Chapter 13 , explains how to find out who is responsible for a specific computer.
|
|

|
|
| 11.4 Troubleshooting Network Access |
|
11.6 Checking Name Service |