

|
Chapter 6 Packet Filtering |

|
6.3 What Does a Packet Look Like?
To understand packet filtering, you first have to understand packets and how they are handled at each layer of the TCP/IP protocol stack:
-
Application layer (e.g., FTP , Telnet, HTTP )
-
Transport layer ( TCP or UDP )
-
Internet layer ( IP )
-
Network access layer (e.g., Ethernet, FDDI , ATM )
Packets are constructed in such a way that layers for each protocol used for a particular connection are wrapped around the packets, like the layers of skin on an onion.
At each layer, a packet has two parts: the header and the body. The header contains protocol information relevant to that layer, while the body contains the data for that layer which often consists of a whole packet from the next layer in the stack. Each layer treats the information it gets from the layer above it as data, and applies its own header to this data. At each layer, the packet contains all of the information passed from the higher layer; nothing is lost. This process of preserving the data while attaching a new header is known as encapsulation .
At the application layer, the packet consists simply of the data to be transferred (for example, part of a file being transferred during an FTP session). As it moves to the transport layer, the Transmission Control Protocol ( TCP ) or the User Datagram Protocol ( UDP ) preserves the data from the previous layer and attaches a header to it. At the next layer, IP considers the entire packet (consisting now of the TCP or UDP header and the data) to be data, and now attaches its own IP header. Finally, at the network access layer, Ethernet or another network protocol considers the entire IP packet passed to it to be data, and attaches its own header. Figure 6.2 shows how this works.
Figure 6.2: Data encapsulation
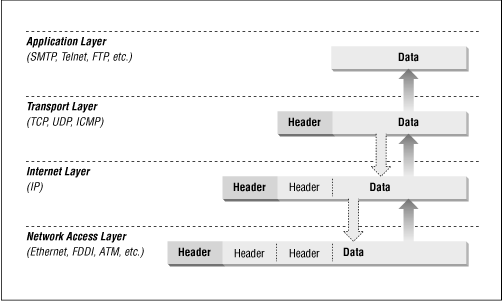
At the other side of the connection, this process is reversed. As the data is passed up from one layer to the next higher layer, each header (each skin of the onion) is stripped off by its respective layer. For example, the Internet layer removes the IP header before passing the encapsulated data up to the transport layer ( TCP or UDP ).
In trying to understand packet filtering, the most important information from our point of view is in the headers of the various layers. The sections below look at several examples of different types of packets and show the contents of each of the headers that packet filtering routers will be examining. We assume a certain knowledge of TCP / IP fundamentals, and concentrate on discussing the particular issues related to packet filtering. For a detailed introduction to TCP/IP , see Appendix C .
In the discussion below, we start with a simple example demonstrating TCP/IP over Ethernet. From there, we go on to discuss IP 's packet filtering characteristics, then protocols above IP (such as TCP , UDP , ICMP , and RPC ), protocols below IP (such as Ethernet), and finally non- IP protocols (such as AppleTalk or IPX ).
6.3.1 TCP/IP /Ethernet Example
Let's consider an example of a TCP/IP packet (for example, one that is part of a Telnet connection) on an Ethernet. There are four layers that we're interested in here: the Ethernet layer, the IP layer, the TCP layer, and the data layer. In this section, we'll consider them from bottom to top and look at the contents of the headers that the packet filtering routers will be examining.
6.3.1.1 Ethernet layer
At the Ethernet layer, the packet consists of two parts: the Ethernet header and the Ethernet body. In general, you won't be able to do packet filtering based on information in the Ethernet header. Basically, the header tells you:
-
What kind of packet this is - we'll assume in this example that it is an IP packet, as opposed to an AppleTalk packet, a Novell packet, a DECNET packet, or some other kind of packet.
-
The Ethernet address of the machine that put the packet onto this particular Ethernet network segment - the original source machine, if it's attached to this segment; otherwise, the last router in the path from the source machine to here.
-
The Ethernet address of the packet's destination on this particular Ethernet network segment - perhaps the destination machine, if it's attached to this segment; otherwise, the next router in the path from here to the destination machine.
Because we are considering IP packets in this example, we know that the Ethernet body contains an IP packet.
6.3.1.2 IP layer
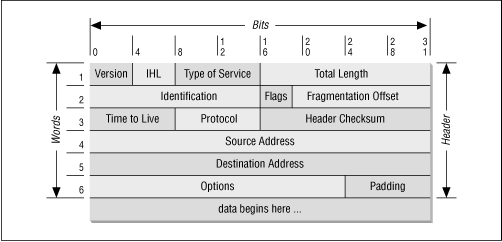
At the IP layer, the IP packet is made up of two parts: the IP header and the IP body, as shown in Figure 6.3 . From a packet filtering point of view, the IP header contains four interesting pieces of information:
-
The IP source address - four bytes long, and typically written as something like 172.16.244.34.
-
The IP destination address - just like the IP source address.
-
The IP protocol type - identifies the IP body as a TCP packet, as opposed to a UDP packet, an Internet Control Message Protocol ( ICMP ) packet, or some other type of packet.
-
The IP options field - which is almost always empty, but which is where options like the IP source route and the IP security options would be specified if they were used for a given packet. (See the discussion in " IP options" below.)
IP may divide up a packet that is too large to cross a given network into a series of smaller packets called fragments . Fragmenting a packet doesn't change its structure at the IP layer (the IP headers are duplicated into each fragment), but it may mean that the body contains only a part of a packet at the next layer. (See the discussion in " IP fragmentation" below.)
Figure 6.3: IP header and body
The IP body in this example contains an unfragmented TCP packet, although it could just as well contain the first fragment of a fragmented TCP packet.
6.3.1.3 TCP layer
At the TCP layer, the packet again contains two parts: the TCP header and the TCP body. ( Figure 13.12 in Appendix C shows the format of the TCP header and body.) From a packet filtering point of view, the TCP header contains three interesting pieces of information:
-
The TCP source port - a two-byte number, which specifies what client or server process the packet is coming from on the source machine
-
The TCP destination port - just like the TCP source port
-
The TCP flags field
The TCP flags field contains one bit of interest for packet filtering: the ACK bit. By examining the ACK bit, a packet filtering router can determine whether a given packet is the first packet initiating a TCP connection (if the ACK bit is not set) or is a subsequent packet (if the ACK bit is set). The ACK bit is part of the TCP mechanism that guarantees delivery of the data. The ACK bit is set whenever one side of a connection has received data from the other side (it acknowledges the received data). Therefore, the ACK bit is set on all packets going in either direction except the very first packet from the client to the server.
The TCP body contains the actual "data" being transmitted - e.g., for Telnet the keystrokes or screen displays that are part of a Telnet session, or for FTP the data being transferred or commands being issued as part of an FTP session.
6.3.2 IP
IP serves as a common middle ground for the Internet. It can have many different layers below it, such as Ethernet, token ring, FDDI , PPP , or carrier pigeon.[2] IP can have many other protocols layered on top of it, with TCP , UDP , and ICMP being by far the most common, at least outside of research environments. In this section, we discuss the special characteristics of IP relevant to packet filtering.
[2] See RFC1149, dated 1 April 1990, which defines the Avian Transport Protocol; RFC s dated 1 April are usually worth reading.
6.3.2.1 IP options
As we saw in the discussion of the IP layer above, IP headers include an options field, which is usually empty. In its design, the IP options field was intended as a place for special information or handling instructions that didn't have a specific field of their own in the header. However, TCP/IP 's designers did such a good job of providing fields for everything necessary that the options field is almost always empty. In practice, IP options are very seldom used except for break-in attempts and (very rarely) for network debugging.
The most common IP option a firewall would be confronted with is the IP source route option. Source routing lets the source of a packet specify the route the packet is supposed to take to its destination, rather than letting each router along the way use its routing tables to decide where to send the packet next. Source routing is supposed to override the instructions in the routing tables. In theory, the source routing option is useful for working around routers with broken or incorrect routing tables; if you know the route that the packet should take, but the routing tables are broken, you can override the bad information in the routing tables by specifying appropriate IP source route options on all your packets. In practice though, source routing is commonly used only by attackers who are attempting to circumvent security measures by causing packets to follow unexpected paths.
Many packet filtering systems take the approach of dropping any packet that has any IP option set, without even trying to figure out what the option is or what it means; in general, this seems to work well, without causing any special problems.
6.3.2.2 IP fragmentation
Another IP -level consideration for packet filtering is fragmentation. One of the features of IP is its ability to divide a large packet that otherwise couldn't traverse some network link (because of limitations on packet size along that link) into smaller packets, called fragments , which can traverse that link. The fragments are then reassembled into the full packet by the destination machine (not by the machine at the other end of the limited link; once a packet is fragmented, it stays fragmented until it reaches its destination).
IP fragmentation is illustrated in Figure 6.4 .
Figure 6.4: Data fragmentation
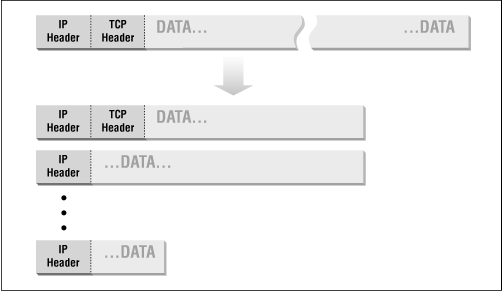
From a packet filtering point of view, the problem with fragmentation is that only the first fragment will contain the header information from higher-level protocols, like TCP , that the packet filtering system needs in order to decide whether or not to allow the full packet. The common packet filtering approach to dealing with fragmentation is to allow any nonfirst fragments through, and to do packet filtering only on the first fragment of a packet. This is safe because, if the packet filtering decides to drop the first fragment, the destination system will not be able to reassemble the rest of the fragments into the original packet, regardless of how many of the rest of the fragments it receives. If it can't reconstruct the original packet, the partially reassembled packet will not be accepted.
The destination host will hold the fragments in memory for a while, waiting to see if it gets the missing piece; this makes it possible for attackers to use fragmented packets in a denial of service attack. When the destination host gives up on reassembling the packet, it will send an ICMP "packet reassembly time expired" message back to the source host, which will tell an attacker that the host exists, and why the connection didn't succeed. There is nothing to be done about such denial of service attacks, but you can filter out the ICMP messages.
Outbound fragments could conceivably contain data you don't want to release to the world. For example, an outbound NFS packet would almost certainly be fragmented, and if the file was confidential, that information would be released. If this happens by accident, it's unlikely to be a problem; people do not generally hang around looking at the data in random packets going by just in case there's something interesting in them. You could wait a very long time for somebody to accidentally send a fragment out with interesting data in it.
If somebody inside intentionally uses fragmentation to transmit data, you have hostile users within the firewall, and no firewall can deal successfully with this problem. (They probably aren't very clever hostile users, though, because there are easier ways to get data out.)
The only situation in which you need to worry about outbound fragments is the one in which you allow a request in but block the outbound reply. In this situation, nonfirst fragments of the reply will get out, and the attacker has reason to expect them and look for them. You can deal with this by being careful to filter out requests and by not relying on filtering out the replies.
6.3.3 Protocols Above IP
IP serves as the base for a number of different protocols; by far the most common are TCP , UDP , and ICMP . These are, in fact, the only IP -based protocols that you're likely to see outside a research environment.
We discuss Remote Procedure Calls ( RPC s) as well in this section, although RPC is, strictly speaking, based on either TCP or UDP , not on IP itself. It makes sense to discuss it here, however, because, like TCP and UDP , RPC is intended to operate as a general-purpose session protocol on which application protocols can be layered.
In addition, we briefly discuss IP over IP (i.e., an IP packet encapsulated within another IP packet), which is used primarily for tunneling multicast IP packets over nonmulticast IP networks.
6.3.3.1 TCP
TCP is the protocol most commonly used for services on the Internet. For example, Telnet, FTP , SMTP , NNTP , and HTTP are all TCP -based services. TCP provides a reliable, bidirectional connection between two endpoints. Opening a TCP connection is like making a phone call: you dial the number, and after a short setup period, a fairly reliable connection is established between you and whomever you're calling.
TCP is reliable in that it makes three guarantees to the application layer:
-
The destination will receive the application data in the order it was sent.
-
The destination will receive all the application data.
-
The destination will not receive duplicates of any of the application data.
TCP will kill a connection rather than violate one of these guarantees. For example, if TCP packets from the middle of a session are lost in transit to the destination, the TCP layer will arrange for those packets to be retransmitted before handing the data up to the application layer. It won't hand up the data following the missing data until it has the missing data. If some of the data cannot be recovered, despite repeated attempts, the TCP layer will kill the connection and report this to the application layer, rather than hand up the data to the application layer with a gap in it.
These guarantees incur certain costs in both setup time (the two sides of a connection have to exchange startup information before they can actually begin moving data) and ongoing performance (the two sides of a connection have to keep track of the status of the connection, to determine what data needs to be resent to the other side to fill in gaps in the conversation).
TCP is bidirectional in that once a connection is established, a server can reply to a client over the same connection. You don't have to establish one connection from a client to a server for queries or commands and another from the server back to the client for answers.
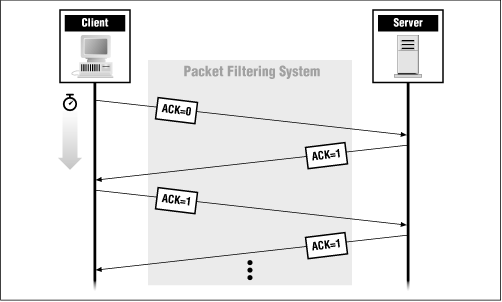
If you're trying to block a TCP connection, it is sufficient to simply block the first packet of the connection. Without that first packet (and, more importantly, the connection startup information it contains), any further packets in that connection won't be reassembled into a data stream by the receiver, and the connection will never be made. That first packet is recognizable because the ACK bit in its TCP header is not set; every other packet in the connection, regardless of which direction it's going, will have the ACK bit set.
Recognizing these "start-of-connection" TCP packets allows you to enforce a policy that allows internal clients to connect to external servers, but prevents external clients from connecting to internal servers. You do this by allowing start-of-connection TCP packets (those without the ACK bit set) only outbound and not inbound. Start of connection packets would be allowed out from internal clients to external servers, but would not be allowed in from external clients to internal servers. Attackers cannot subvert this approach simply by turning on the ACK bit in their start-of-connection packets, because the absence of the ACK bit is what identifies these packets as start of connection packets.
Packet filtering implementations vary in how they treat and let you handle the ACK bit. Some packet filtering implementations give direct access to the ACK bit - for example, by letting you include "ack" as a keyword in a packet filtering rule. Some other implementations give indirect access to the ACK bit. For example, the Cisco "established" keyword works by examining this bit (established is "true" if the ACK bit is set, and "false" if the ACK bit is not set). Finally, some implementations don't let you examine the ACK bit at all.
Figure 6.5 shows what ACK is set to on packets that are part of a TCP connection.
Figure 6.5: ACK bits on TCP packets
6.3.3.2 UDP
The body of an IP packet might contain a UDP packet instead of a TCP packet. UDP is a low-overhead alternative to TCP .
UDP is low overhead in that it doesn't make any of the reliability guarantees (delivery, ordering, and nonduplication) that TCP does, and, therefore, it doesn't need the mechanism to make those guarantees. Every UDP packet is independent; UDP packets aren't part of a "virtual circuit" as TCP packets are. Sending UDP packets is like dropping postcards in the mail: if you drop 100 postcards in the mail, even if they're all addressed to the same place, you can't be absolutely sure that they're all going to get there, and those that do get there probably won't be in exactly the same order they were in when you sent them.
Unlike postcards, UDP packets can actually arrive more than once (without being ripped to shreds, which is normally the only way the same postcard gets delivered multiple times). Multiple copies are possible because the packet might be duplicated by the underlying network. For example, on an Ethernet, a packet would be duplicated if a router thought that it might have been the victim of an Ethernet collision. If the router was wrong, and the original packet had not been the victim of a collision, both the original and the duplicate would eventually arrive at the destination. (A confused application may also decide to send the same data twice, perhaps because it didn't get an expected response to the first one.)
All of these things can happen to TCP packets, too, but they will be corrected before the data is passed to the application. With UDP , the application is responsible for dealing with the packets, not corrected data.
UDP packets are very similar to TCP packets in structure. A UDP header contains UDP source and destination port numbers, just like the TCP source and destination port numbers. However, a UDP header does not contain anything resembling an ACK bit. The ACK bit is part of TCP 's mechanism for guaranteeing reliable delivery of data. Because UDP makes no such guarantees, it has no need for an ACK bit. There is no way for a packet filtering router to determine, simply by examining the header of an incoming UDP packet, whether that packet is a first packet from an external client to an internal server, or a response from an external server back to an internal client.
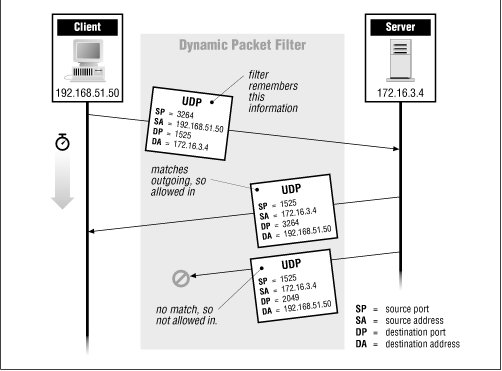
Some packet filtering implementations, such as CheckPoint's FireWall-1 product, Janus; Morning Star's SecureConnect Router; and the KarlBridge/KarlBrouter, have the capability of "remembering" outgoing UDP packets that they've seen. They can then allow only the corresponding response packets back in through the filtering mechanism. In order to be counted as a response, the incoming packet has to be from the host and port that the outbound packet was sent to, and has to be directed to the host and port that sent the outbound packet. This capability is often referred to as dynamic packet filtering , because the router is essentially modifying the filtering rules on the fly to accommodate these returning packets. The rules created to allow the responses are time-limited; they time out after a few seconds or minutes. Dynamic packet filtering may also be used for any situation in which the packet filtering rules change without somebody explictly changing the configuration; different products support different capabilities.
Figure 6.6 illustrates dynamic packet filtering at the UDP layer.
Figure 6.6: Dynamic packet filtering at the UDP layer
6.3.3.3 ICMP
ICMP is used for IP status and control messages. ICMP packets are carried in the body of IP packets, just as TCP and UDP packets are. Examples of ICMP messages include:
-
Echo request - what a host sends when you run ping .
-
Echo response - what a host responds to an "echo request" with.
-
Time exceeded - what a router returns when it determines that a packet appears to be looping; a more intuitive name might be maximum hopcount exceeded.
-
Destination unreachable - what a router returns when the destination of a packet can't be reached for some reason (e.g., because a network link is down).
-
Redirect - what a router sends a host in response to a packet the host should have sent to a different router; the router handles the original packet anyway (forwarding it to the router it should have gone to in the first place), and the redirect tells the host about the more efficient path for next time.
Unlike TCP or UDP , ICMP has no source or destination ports, and no other protocols layered on top of it. Instead, there is a set of defined ICMP message type codes; the particular code used dictates the interpretation of the rest of the ICMP packet.
Many packet filtering systems let you filter ICMP packets based on the ICMP message type field, much as they allow you to filter TCP or UDP packets based on the TCP or UDP source and destination port fields.
6.3.3.4 RPC
There are multiple remote procedure call protocols known as RPC s. The most popular is sometimes called "Sun RPC " because it was originally developed at Sun Microsystems. This is the protocol we'll be discussing, and it is the protocol most frequently referred to as simply " RPC ". Other remote procedure call mechanisms are specific to particular UNIX implementations or implementation families. (For example, OSF DCE has its own remote procedure call protocol.) These mechanisms differ in detail from RPC , but tend to have similar problems.
Strictly speaking, the RPC mechanism is not built on top of IP , but rather on top of UDP and TCP . However, like TCP and UDP , RPC is used as a general-purpose transport protocol by a variety of application protocols (such as NFS and NIS/YP , as we discuss in Chapter 8 ), so it makes sense to describe it here. NFS and NIS/YP are vulnerable services from a network security point of view. An attacker with access to your NFS server can probably read any file on your system. An attacker with access to your NIS/YP server can probably obtain your password file, on which he can run a password-cracking attack against your system.
In the TCP and UDP protocols, port numbers are two-byte fields. This means that there are only 65,536 possible port numbers for TCP and UDP services. There aren't enough ports to be able to assign a unique well-known port number to every possible service and application that might want one. Among other things, RPC addresses this limitation. Each RPC -based service is assigned a unique four-byte " RPC service number." This allows for 4,294,967,296 different services, each with a unique number. That's more than enough to assign a unique number to every possible service and application you'd need.
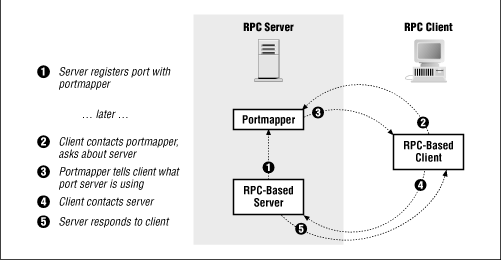
RPC is built on top of TCP and UDP so there needs to be some way of mapping the RPC service numbers of the RPC -based servers in use on a machine to the particular TCP or UDP ports those servers are using. This is where the portmapper server comes in.
The portmapper is the only RPC -related server that is guaranteed to run on a particular TCP or UDP port number (it is at port number 111 on both). When an RPC -based server such as an NFS or NIS/YP server starts, it allocates a random TCP and/or UDP (some use one, some the other, some both) port for itself.[3] Then, it contacts the portmapper server on the same machine to "register" its unique RPC service number and the particular port(s) it is using at the moment.
[3] Actually, most NFS implementations that we've seen always use port 2049; however, we're not willing to assume that NFS always will use that port, in every implementation. In fact, RFC 1094, the NFS protocol specification, says "The NFS protocol currently uses the UDP port number 2049. This is not an officially assigned port, so later versions of the protocol use the `Portmapping' facility of RPC ."
An RPC -based client program that wishes to contact a particular RPC -based server on a machine first contacts the portmapper server on that machine (which, remember, always runs on both TCP and UDP port 111). The client tells portmapper the unique RPC service number for the server it wishes to access, and portmapper responds with a message saying, in effect, either "I'm sorry, but that service isn't available on this machine at the moment," or "That service is currently running on TCP (or UDP ) port N on this machine at the moment." At that point, the client contacts the server on the port number it got from the portmapper , and continues its conversation directly with the server, without further involvement from the portmapper . ( Figure 6.7 shows this process.)
Figure 6.7: RPC and the portmapper
It's very difficult to use packet filtering to control RPC -based services, because you don't know what port the service will be using on a particular machine - and chances are that the port used will change every time the machine is rebooted. Blocking access to the portmapper isn't sufficient. An attacker can bypass the step of talking to the portmapper , and simply try all TCP and/or UDP ports (the 65,536 possible ports can all be checked on a particular machine in a matter of minutes), looking for the response expected from a particular RPC -based server like NFS or NIS/YP .
Some newer packet filtering products can talk to portmapper to determine what services are where and filter on that basis. Note that this has to be verified on a per-packet basis for UDP -based services. The packet filter will have to contact portmapper every time it receives a packet, because if the machine has rebooted, the service may have moved. Because TCP is connection-oriented, the port number only has to be verified on a per-connection basis. Using this mechanism to allow UDP -based services is going to result in high overhead and is probably not wise for data-intense applications like NFS .
NOTE: Even though it is not sufficient, you should still block access to the portmapper , because some versions of portmapper are capable of being used as proxies for an attacker's clients.
So, what do you do to guard RPC -based services? A couple of observations: First, it turns out that most of the "dangerous" RPC -based services (particularly NIS/YP and NFS ) are offered only over UDP . Second, most services you'd want to access through a packet filter are TCP -based, not UDP -based; the notable exceptions are DNS , NTP , syslog , and Archie. These twin observations lead to the common approach many sites take in dealing with RPC using packet filtering: block UDP altogether, except for specific and tightly controlled "peepholes" for DNS , NTP , syslog and Archie. (See the discussion of these services in Chapter 8 .)
With this approach, if you wish to allow any TCP -based RPC service, you'll need to allow them all. TCP -based NFS servers, while available, are not yet widely used; if you're using them, however, you'll need to modify this approach accordingly.
6.3.3.5 IP over IP
In some circumstances, IP packets are encapsulated within other IP packets for transmission, yielding so-called " IP over IP. " The most common use of IP over IP is to carry multicast IP packets (that is, packets with multicast destination addresses) between networks that do support multicasting over intermediate networks that don't. To cross these intermediate networks, a special multicast router (or mrouter ) on each multicast network encapsulates the multicast IP packets that it wants to send into nonmulticast (i.e., normal) IP packets addressed to other mrouter s. The other mrouter s, upon receiving these encapsulated multicast packets, strip off the outer (nonmulticast) packet and then handle the inner (multicast) packet.
Multicast IP is becoming more and more popular on the Internet, primarily because of the conferencing and other services offered through the MBONE . We discuss the MBONE , and multicast services in general, in more detail in Chapter 2, Internet Services and Chapter 8 .
6.3.4 Protocols Below IP
It's theoretically possible to filter on information from below the IP level - for example, the Ethernet hardware address. However, doing so is very rarely useful because in most cases, all packets from the outside are coming from the same hardware address (the address of the router that handles your Internet connection). Furthermore, many routers have multiple connections with different lower-level protocols. As a result, doing filtering at lower levels would require configuring different interfaces with different kinds of rules for the different lower-level protocols. You couldn't write one rule to apply to all interfaces on a router that had two Ethernet connections and an FDDI connection, because the headers of Ethernet and FDDI packets, while similar, are not identical. In practice, IP is the lowest level protocol at which people choose to do packet filtering.
6.3.5 Application Layer Protocols
In most cases, there is a further protocol on top of TCP or UDP , specific to the application. These protocols differ widely in their specificity, and there are hundreds, if not thousands, of them (almost as many as there are network-based applications). Some newer packet filtering applications provide the ability to filter on application-layer protocols for particular well-known applications. For example, they may be able to recognize particular information in an FTP transaction in order to set up dynamic filters, or they may be able to compare the information in a packet to the application that it's supposed to be going to, to be sure that packets addressed to a DNS port are actually DNS packets.
6.3.6 IP Version 6
The current version of IP (at the time this book was written) is officially known as IP Version 4; throughout this book, whenever we talk about IP with no further qualification, that's what we're talking about. There is, however, a new version of IP in the works right now, known as IP Version 6 ( IP v6 for short). Why do we need a new version of IP , and how will IP v6 affect you?
As we mentioned in the section called "What the Future Holds" in Chapter 4, Firewall Design , the impetus to create IP v6 was one simple problem: the Internet is running out of IP addresses. The Internet has become so popular that there just won't be enough IP network numbers (particularly Class B network numbers, which have proven to be what most sites need) to go around; by some estimates, if nothing had been done, the Internet would have run out of addresses in 1995 or 1996. Fortunately, the problem was recognized, and something was done. Two things, actually - first, the implementation of a set of temporary measures and guidelines to make best possible use of the remaining unassigned addresses, and second, the design and implementation of a new version of IP that would permanently deal with the address-exhaustion issue.
If you're going to create a new version of IP in order to deal with address-space exhaustion, you might as well take advantage of the opportunity to deal with a whole raft of other problems or limitations in IP as well, such as encryption, authentication, source routing, and dynamic configuration. According to Steve Bellovin of AT&T Bell Laboratories, a well-known firewalls expert on the Internet and a participant in the IP v6 design process:[4]
[4] Steve Bellovin, posting to the Firewalls mailing list, December 31, 1994.
IP v6 is based on the concept of nested headers. That's how encryption and authentication are done; the "next protocol" field after the IP v6 header specifies an encryption or an authentication header. In turn, their next protocol fields would generally indicate either IP v6 or one of the usual transport protocols, such as TCP or UDP .
Nested IP over IP can be done even without encryption or authentication; that can be used as a form of source routing. A more efficient way is to use the source routing header - which is more useful than the corresponding IP v4 option, and is likely to be used much more, especially for mobile IP .
Some of the implications for firewalls are already apparent. A packet filter must follow down the full chain of headers, understanding and processing each one in turn. (And yes, this can make looking at port numbers more expensive.) A suitably cautious stance dictates that a packet with an unknown header be bounced, whether inbound or outbound. Also, the ease and prevalence of source routing means that cryptographic authentication is absolutely necessary. On the other hand, it is intended that such authentication be a standard, mandatory feature. Encrypted packets are opaque, and hence can't be examined; this is true today, of course, but there aren't very many encryptors in use now. That will change. Also note that encryption can be done host-to-host, host-to-gateway, or gateway-to-gateway, complicating the analysis still more.
Address-based filtering will also be affected, to some extent, by the new autoconfiguration mechanisms. It's vital that any host whose address is mentioned in a filter receive the same address each time. While this is the intent of the standard mechanisms, one needs to be careful about proprietary schemes, dial-up servers, etc. Also, high-order address bits can change, to accommodate the combination of provider-based addressing and easy switching among carriers.
Finally, IP v6 incorporates "flows." Flows are essentially virtual circuits at the IP level; they're intended to be used for things like video, intermediate-hop ATM circuit selection, etc. But they can also be used for firewalls, given appropriate authentication: the UDP reply problem might go away if the query had a flow id that was referenced by the response. This, by the way, is a vague idea of mine; there are no standards for how this should be done. The regular flow setup protocol won't work; it's too expensive. But a firewall traversal header might do the job.
As you can see, IP v6 could have a major impact on firewalls, especially with respect to packet filtering. As this book is being written, though, it's still too soon to tell just what those effects will be, and when we'll start to feel them.
Keep in mind that IP v6 won't be deployed overnight. IP v4 will be around for a long time, and many sites will continue to run it through the foreseeable future. The IP v6 designers are very sensitive to the transition issues, and a lot of attention is being paid to that area, and to various migration strategies sites might employ.
6.3.7 Non- IP Protocols
Other protocols at the same level as IP , e.g., AppleTalk and IPX , provide similar kinds of information as IP , although the headers and operations for these protocols, and, therefore their packet filtering characteristics, vary radically. Most packet filtering implementations support IP filtering only, and simply drop non- IP packets. Some packages provide limited packet filtering support for non- IP protocols, but this support is usually far less flexible and capable than the router's IP filtering capability.
At this time, packet filtering as a tool isn't as popular and well developed for non- IP protocols, presumably because these protocols are rarely used to communicate outside a single organization over the Internet. (The Internet is, by definition, a network of IP networks). Non- IP protocols are more of an issue for firewalls that are internal to an organization, and for this application, you would want to choose one of the packages that supports non- IP filtering.
Across the Internet, non- IP protocols are handled by encapsulating them within IP protocols. In most cases, you will be limited to permitting or denying encapsulated protocols in their entirety; you can accept all Appletalk-in- UDP connections, or reject them at all. A few packages that support non- IP protocols can recognize these connections when encapsulated and filter on fields in them.
|
|

|
|
| 6.2 Configuring a Packet Filtering Router |
|
6.4 What Does the Router Do with Packets? |