

|
Chapter 13 Troubleshooting DNS and BIND |

|
13.6 Problem Symptoms
Some problems, unfortunately, aren't as easy to identify as the ones we listed. You'll experience some misbehavior but won't be able to attribute it directly to its cause, often because any of a number of problems may cause the symptoms you see. For cases like this, we'll suggest some of the common causes of these symptoms and ways to isolate them.
13.6.1 Local Name Can't Be Looked Up
The first thing to do when a program like telnet or ftp can't look up a local name is to use nslookup to try to look up the same name. When we say "the same name," we mean literally the same name - don't add a domain and a trailing dot if the user didn't type either one. Don't query a different name server than the user did.
As often as not, the user mistyped the name, or doesn't understand how the search list works, and just needs direction. Occasionally, you'll turn up real host configuration errors:
-
Syntax errors in resolv.conf (problem 11 in the "Potential Problem List" mentioned earlier in this chapter)
-
An unset default domain (problem 12)
You can check for either of these using nslookup 's set all command.
If nslookup points to a problem with the name server, rather than with the host configuration, check for the problems associated with the type of name server. If the name server is the primary master for the zone, but it doesn't respond with data you think it should:
-
Check that the db file contains the data in question, and that the name server has been signaled to reload it (problem 2).
-
Check the conf or boot file and the pertinent db file for syntax errors (problem 5).
-
Ensure that the records have trailing dots, if they require them (problem 6).
If the name server is a slave server, you should first check whether or not its master has the correct data. If it does, and the slave doesn't:
-
Make sure you've incremented the serial number on the primary (problem 1).
-
Look for a problem on the slave in updating the zone (problem 3).
If the primary doesn't have the correct data, of course, diagnose the problem on the primary.
If the problem server is a caching-only name server:
-
Make sure it has its cache data (problem 7).
-
Check that your parent zone's delegation to your zone exists and is correct (problems 9 and 10). Remember that to a caching-only server, your zone looks just like any other remote zone. Even though the host it runs on may be inside your zone, the caching-only name server must be able to locate an authoritative server for your zone from your parent zone's servers.
13.6.2 Remote Names Can't Be Looked Up
If your local lookups succeed, but you can't look up names outside your local zones, there is a different set of problems to check:
-
First, did you just set up your servers? You might have omitted the cache data (problem 7).
-
Can you ping the remote zone's name servers? Maybe you can't reach the remote zone's servers because of connectivity loss (problem 8).
-
Is the remote zone new? Maybe its delegation hasn't yet appeared (problem 9). Or the delegation information for the remote zone may be wrong or out of date, due to neglect (problem 10).
-
Does the domain name actually exist on the remote zone's servers (problem 2)? On all of them (problems 1 and 3)?
13.6.3 Wrong or Inconsistent Answer
If you get the wrong answer when looking up a local name, or an inconsistent answer, depending on which name server you ask or when you ask, first check the synchronization between your name servers:
-
Are they all holding the same serial number for the zone? Did you forget to increment the serial number on the primary after you made a change (problem 1)? If you did, the name servers may all have the same serial number, but they will answer differently out of their authoritative data.
-
Did you roll the serial number back to one (problem 1 again)? Then the primary's serial number will appear much lower than the slaves' serial numbers.
-
Did you forget to signal the primary (problem 2)? Then the primary will return (via nslookup , for example) a different serial number than the serial number in the data file.
-
Are the slaves having trouble updating from the primary (problem 3)? If so, they should have syslog ged appropriate error messages.
-
Is the name server's round robin feature rotating the addresses of the domain name you're looking up?
If you get these results when looking up a name in a remote zone, you should check whether the remote zone's name servers have lost synchronization. You can use tools like nslookup to determine whether the remote zone's administrator has forgotten to increment the serial number, for example. If the name servers answer differently from their authoritative data but show the same serial number, the serial number probably wasn't incremented. If the primary's serial number is much lower than the slaves', the primary's serial number was probably accidentally reset. We usually assume a zone's primary name server is running on the host listed as the origin in the SOA record.
You probably can't determine conclusively that the primary hasn't been signaled, though. It's also difficult to pin down updating problems between remote name servers. In cases like this, if you've determined that the remote name servers are giving out incorrect data, contact the zone administrator and (gently) relay what you've found. This will help the administrator track down the problem on the remote end.
If you can determine that a parent server - a remote zone's parent, your zone's parent, or even your zone - is giving out a bad answer, check whether this is coming from old delegation information. Sometimes this will require contacting both the administrator of the remote zone and the administrator of its parent to compare the delegation and the current, correct list of authoritative name servers.
If you can't induce the administrator to fix his data, and it's causing your name server problems, or if you can't track down the administrator, you can always use the bogus substatement or bogusns directive to instruct your name server not to query that particular server.
13.6.4 Lookups Take a Long Time
Long name resolution is usually due to one of two problems:
-
Connectivity loss (problem 8), which you can diagnose with name server debugging output and tools like ping
-
Incorrect delegation information (problem 10), which points to the wrong name servers or the wrong IP addresses
Usually, going over the debugging output and sending a few ping s will point to one or the other. Either you can't reach the name servers at all, or you can reach the hosts, but the name servers aren't responding.
Sometimes, though, the results are inconclusive. For example, the parent name servers delegate to a set of name servers that don't respond to ping s or queries, but connectivity to the remote network seems all right (a traceroute , for example, will get you to the remote network's "doorstep" - the last router between you and the host). Is the delegation information so badly out of date that the name servers have long since moved to other addresses? Are the hosts simply down? Or is there really a remote network problem? Usually, finding out will require a call or a message to the administrator of the remote zone. (And remember, whois gives you phone numbers!)
13.6.5 rlogin and rsh to Host Fails Access Check
This is a problem you expect to see right after you set up your name servers. Users unaware of the change from the host table to domain name service won't know to update their .rhosts files. (We covered what needs to be updated in Chapter 6 .) Consequently, rlogin 's or rsh 's access check will fail and deny the user access.
Other causes of this problem are missing or incorrect in-addr.arpa delegation (problems 9 and 10), and forgetting to add a PTR record for the client host (problem 4). If you've recently upgraded to BIND 4.9 or 8 and have PTR data for more than one in-addr.arpa subdomain in a single file, your name server may be ignoring the out-of-zone data. Any of these situations will result in the same behavior:
%rlogin wormholePassword:
In other words, the user is prompted for a password despite having set up passwordless access with .rhosts or hosts.equiv . If you were to look at the syslog file on the destination host ( wormhole , in this case), you'd probably see something like this:
May 4 18:06:22 wormhole inetd[22514]: login/tcp: Connection
from unknown (192.249.249.213)
You can tell which problem it is by stepping through the resolution process with nslookup . First query one of your in-addr.arpa domain's parent name servers for NS records for your in-addr subdomain. If these are correct, query the name servers listed for the PTR record corresponding to the IP address of the rlogin or rsh client. Make sure they all have the PTR record, and that the record maps to the right domain name. If not all the name servers have the record, check for a loss of synchronization between the primary and the slaves (problems 1 and 3).
13.6.6 Access to Services Denied
Sometimes rlogin and rsh aren't the only services to go. Occasionally you'll install DNS on your server and your diskless hosts won't boot, and hosts won't be able to mount disks from the server, either.
If this happens, make sure the case of the names your name servers return agrees with the case your previous name service returned. For example, if you were running NIS , and your NIS host's maps contained only lowercase names, you should make sure your name servers also return lowercase names. Some programs are case-sensitive and won't recognize names in a different case in a data file, such as /etc/bootparams or /etc/exports .
13.6.7 Name Server Is Infected with Bogus Root Server Data
NOTE: BIND name servers version 4.9 and newer are resistant to this problem.
Here's a problem that will be familiar to anyone who's run a name server on the Internet for any length of time:
%nslookupDefault Server: terminator.movie.edu Address: 192.249.249.3 >set type=ns>.Server: terminator.movie.edu Address: 192.249.249.3 Non-authoritative answer: (root) nameserver = NS . NIC . DDN . MIL (root) nameserver = B. ROOT-SERVERS . NET (root) nameserver = E. ROOT-SERVERS . NET (root) nameserver = D. ROOT-SERVERS . NET (root) nameserver = F. ROOT-SERVERS . NET (root) nameserver = C. ROOT-SERVERS . NET (root) nameserver = G. ROOT-SERVERS . NET (root) nameserver = hpfcsx.fc.hp.com (root) nameserver = hp-pcd.cv.hp.com (root) nameserver = hp-ses.sde.hp.com (root) nameserver = hpsatc1.gva.hp.com (root) nameserver = named_master.ch.apollo.hp.com (root) nameserver = A. ISI . EDU (root) nameserver = SRI-NIC . ARPA (root) nameserver = GUNTER-ADAM . ARPA Authoritative answers can be found from: (root) nameserver = NS . NIC . DDN . MIL (root) nameserver = B. ROOT-SERVERS . NET (root) nameserver = E. ROOT-SERVERS . NET (root) nameserver = D. ROOT-SERVERS . NET (root) nameserver = F. ROOT-SERVERS . NET (root) nameserver = C. ROOT-SERVERS . NET (root) nameserver = *** Error: record size incorrect (1050690 != 65519) *** terminator.movie.edu can't find .: Unspecified error
Whoa! Where in the heck did all those root name servers come from? And why is the record size messed up?
If you look carefully, you'll notice that most of those records are bogus. SRI-NIC . ARPA , for example, is the original name of nic.ddn.mil , from the days when all ARPAnet hosts lived under the top-level ARPA domain. Moreover, even the name server on nic.ddn.mil was decommissioned as a root some time ago, replaced by a new root on ns.nic.ddn.mil (and that name server moved from the old NIC at SRI to the new one at NSI ...).
The name servers in hp.com aren't Internet roots, and haven't ever been. So how did these get into our cache? Here's how.
Remember when we described what a name server does when queried for a name it isn't authoritative for? It does its best to provide information that will be helpful to the querier: NS records that are as close as possible to the domain name the querier is after. Sometimes the queried name server can only get as close as the root name servers. And sometimes the name server has the wrong list of roots, either accidentally (because of incorrect configuration) or because no one went to the effort to keep the cache file up-to-date.
So what does that have to do with caching? Well, say your name server queries what it thinks is a 10.in-addr.arpa name server, and the name server turns out to know nothing about 10.in-addr.arpa . The name server, trying to be helpful, sends along its current list of root name servers in a response packet, but the list is wrong. BIND (versions 4.8.3 and earlier), trusting as a newborn, gratefully caches all this useless information. Later versions, older and wiser, flag this as a lame delegation and toss the bad data.
Why did nslookup return a record size error when we looked up your name server's list of root servers? The list of roots exceeded the size of a UDP response packet, but it was truncated to fit into a response. The length field in the response indicated that more data was included, though, so nslookup complained.
This infection can spread if the bogus NS records point to real - but nonroot - name servers. If these name servers give out more bogus data, your name server's cache may become polluted by more and more erroneous records.
The only ways to track down the source of these bogus roots are to turn name server debugging way up (to level four or above) and watch for the receipt of these records, or to patch your name server so that it reports receiving bad root information. With BIND 4.9 and BIND 8, you can see the source of the bad data in a database dump. Even when you think you've found the culprit, though, you may have only discovered another name server that was corrupted before yours, not the original source of the corruption. To uncover the original sinner, you'd have to work backwards, together with other administrators, to discover who made the first gaffe. If you don't have the tenacity to suffer through that process, it's probably easier just to upgrade to a BIND 4.9 or BIND 8 server.
13.6.8 Name Server Keeps Loading Old Data
Here's a weird class of problems related to the previous cache corruption problem. Sometimes, after decommissioning a name server, or changing a name server's IP address, you'll find the old address record lingering around. An old record may show up in a name server's cache or in a zone data file weeks, or even months, later. The record clearly should have timed out of any caches by now. So why's it still there? Well, there are a few reasons this happens. We'll describe the simpler cases first.
13.6.8.1 Old delegation information
The first (and simplest) case occurs if a parent zone doesn't keep up with its children, or if the children don't inform the parent of changes to the authoritative name servers for the zone. If the edu administrators have this old delegation information for movie.edu :
$ ORIGIN movie.edu. @ 86400 in ns terminator 86400 in ns wormhole terminator 86400 in a 192.249.249.3 wormhole 86400 in a 192.249.249.254 ; wormhole's former ; IP address
then the edu name servers will give out the bogus old address for wormhole .
This is easily corrected once it's isolated to the parent name servers: just contact the parent zone's administrator and ask to have the delegation information updated. If any of the child zone's servers have cached the bad data, kill them (to clear out their caches), delete any data files that contain the bad data, then restart them.
13.6.8.2 Unnecessary glue data
When named-xfer pulls zone data over from a master server, it transfers more than it strictly needs. This is a bug in BIND 4.8.3 and earlier. The main excess baggage named-xfer retrieves is the addresses of name servers for the zone, when those servers are outside of the zone. If the name servers are in the zone, their addresses are necessary as glue data. But if they're not in the zone, they don't belong in the zone's data file. So, for example, in a backup file for movie.edu , you'd find these partial contents of file db.movie :
$ ORIGIN edu. movie IN NS terminator.movie.edu. $ ORIGIN movie.edu. terminator IN A 192.249.249.3 $ ORIGIN edu. movie IN NS wormhole.movie.edu. $ ORIGIN movie.edu. wormhole IN A 192.249.249.1 IN A 192.253.253.1 IN A 192.249.249.254
But you'd also find similar records in db.192.249.249 and db.192.253.253 :
$ ORIGIN 249.192.in-addr.arpa. 249 IN NS terminator.movie.edu. $ ORIGIN movie.edu. terminator 56422 IN A 192.249.249.3 $ ORIGIN 249.192.in-addr.arpa. 249 IN NS wormhole.movie.edu. $ ORIGIN movie.edu. wormhole 56422 IN A 192.249.249.1 56422 IN A 192.253.253.1 56422 IN A 192.249.249.254
The last of wormhole 's addresses is wormhole 's former address.
NOTE: BIND name servers version 4.9 and newer do not have this problem.
There's no reason to include the address records for terminator or wormhole in either in-addr.arpa backup file. They should be listed in db.movie , but since they're not necessary as glue in either in-addr.arpa subdomain, they shouldn't appear in db.192.249.249 or db.192.253.253 .
When the slave loads the in-addr.arpa backup file, it also loads the address records for terminator and wormhole . If the address is old, then the name server loads - and gives out - the wrong address:
%nslookup wormholeServer: wormhole.movie.edu Address: 192.249.249.1 Name: wormhole.movie.edu Address: 192.249.249.1, 192.253.253.1, 192.249.249.254
You might think, "If I clean the old address out of db.movie ," (you can think in italics), "the slaves will time it out of the in-addr.arpa subdomains. After all, there's a TTL on the address records."
Unfortunately, the slave servers don't age those records. They're given out with the TTL in the data file, but the slave never decrements the TTL or times out the record. So the old address could linger as long as the in-addr.arpa backup files remain unchanged. And in-addr.arpa zones are very stable if no one's adding new hosts to the network or shuffling IP addresses. There's no need to increment their serial numbers and have them reloaded by the slaves.
The secret is to increment all of the zones' serial numbers at once when you make a change affecting the zones' authoritative name servers. That way, you flush out any old, stale records and ensure that the slaves all load up-to-date glue.
13.6.8.3 Mutual infection
There's one more scenario we're familiar with that can cause these symptoms. This one doesn't require old data in files at all - just two slave name servers. BIND can run into problems when two name servers act as slave for each other, and when one zone is the child of the other; for example, when name server A loads movie.edu from name server B, and B loads fx.movie.edu from A.
NOTE: BIND name servers version 4.9 and newer are resistant to this problem.
In these cases, certain data can float back and forth between the two name servers indefinitely. In particular, the name servers can pass delegation data, which is really part of the "child" zone, back and forth.
How does this work? Say terminator.movie.edu is the primary master movie.edu server and it backs up fx.movie.edu from bladerunner . bladerunner is the primary master fx.movie.edu name server and backs up movie.edu from terminator . Then suppose you change bladerunner 's IP address. You remember to change named.conf on terminator to load fx.movie.edu from bladerunner 's new IP address, and you change the IP address in db.fx . You even update the fx subdomain's delegation data in db.movie on the primary to reflect the address change. Isn't that enough?
Nope. Here's why: terminator still has bladerunner 's old IP address in the backup file db.fx , and bladerunner still has its own old address in its backup copy of db.movie (a glue record in the fx delegation).
Now let's say you delete db.fx on terminator and kill and restart its name server. Won't that suffice? No, because bladerunner still has the old address and will pass it along to terminator in the next fx.movie.edu zone transfer. If you delete db.movie on bladerunner and kill and restart the name server, something similar will happen: bladerunner will get the old record back with the next movie.edu zone transfer.
That's a little complicated to follow - for us, too - so Figure 13.2 will help you picture what's going on.
Figure 13.2: Infection through zone transfer
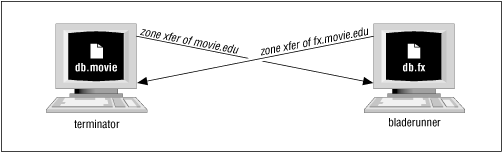
You need to rid both name servers of the old record simultaneously. Our solution to this problem is to bring both name servers down at the same time, clean out any backup files, and then start them both up again. That way, the caches can't re-infect each other.
13.6.8.4 What have I got?
How do you determine which of these problems is plaguing you? Pay attention to which name servers are distributing the old data, and which domains the data relate to:
-
Is the name server your parent name server? Check the parent for either old delegation information or parent-child infection.
-
Are both a name server and its parent affected? Then check for parent-child infection.
-
Are slaves affected, but not the primary? Check for stale data in backup files.
That's about all we can think to cover. It's certainly less than a comprehensive list, but we hope it'll help you solve the more common problems you encounter with DNS , and give you ideas about how to approach the rest. Boy, if we'd only had a troubleshooting guide when we started!
|
|

|
|
| 13.5 Interoperability and Version Problems |
|
14. Programming with the Resolver and Name Server Library Routines |