
13.2. Object-oriented Database Access in C++
The C APIs work great for procedural C development. They do not, however, fit into the object-oriented world of C++ all that well. In order to demonstrate how these two APIs work in real code, we will spend the rest of the chapter using them to create a C++ API for object-oriented database development.
Because we are trying to illustrate MySQL and mSQL database access, we will focus on issues specific to MySQL and mSQL and not try to create the perfect general C++ API. In the MySQL and mSQL world, there are three basic concepts: the connection, the result set, and the rows in the result set. We will use these concepts as the core of the object model on which our library will be based. Figure 13-1 shows these objects in a UML diagram.[20]
[20] UML is the new Unified Modeling Language created by Grady Booch, Ivar Jacobson, and James Rumbaugh as a new standard for documenting the object-oriented design and analysis.
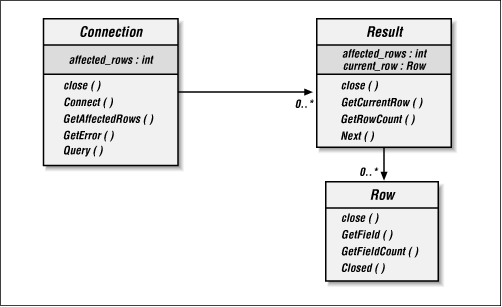
Figure 13-1. Object-oriented database access library
13.2.1. The Database Connection
Database access in any environment starts with the connection. As you saw in the first two examples, MySQL and mSQL have two different ways of representing the same concept -- a connection to the database. We will start our object-oriented library by abstracting on that concept and creating a Connection object. A Connection object should be able to establish a connection to the server, select the appropriate database, send queries, and return results. Example 13-1 is the header file that declares the interface for the Connection object.
Example 13-1. The Connection Class Header
#ifndef l_connection_h
#define l_connection_h
#include <sys/time.h>
#if defined(HAS_MSQL)
#include <msql.h>
#elif defined(HAS_MYSQL)
#include <mysql.h>
#endif
#include "result.h"
class Connection {
private:
int affected_rows;
#if defined(HAS_MSQL)
int connection;
#elif defined(HAS_MYSQL)
MYSQL mysql;
MYSQL *connection;
#else
#error No database defined.
#endif
public:
Connection(char *, char *);
Connection(char *, char *, char *, char *);
~Connection();
void Close();
void Connect(char *host, char *db, char *uid, char *pw);
int GetAffectedRows();
char *GetError();
int IsConnected();
Result *Query(char *);
};
#endif // l_connection_hThe methods the Connection class will expose to the world are uniform no matter which database engine you use. Underneath the covers, however, the class will have private data members specific to the library you compile it against. For making a connection, the only distinct data members are those that represent a database connection. As we noted earlier, mSQL uses an int to represent a connection and MySQL uses a MYSQL pointer with an additional MYSQL value to handle establishing the connection.
13.2.1.1. Connecting to the database
Any applications we write against this API now need only to create a new Connection instance using one of the associated constructors in order to connect to the database. Similarly, an application can disconnect by deleting the Connection instance. It can even reuse a Connection instance by making direct calls to Close() and Connect(). Example 13-1 shows the implementation for the constructors and the Connect() method.
Example 13-1. Connecting to MySQL and mSQL Inside the Connection Class
#include "connection.h"
Connection::Connection(char *host, char *db) {
#if defined(HAS_MSQL)
connection = -1;
#elif defined(HAS_MYSQL)
connection = (MYSQL *)NULL;
#else
#error No database linked.
#endif
Connect(host, db, (char *)NULL, (char *)NULL);
}
Connection::Connection(char *host, char *db, char *uid, char *pw) {
#if defined(HAS_MSQL)
connection = -1;
#elif defined(HAS_MYSQL)
connection = (MYSQL *)NULL;
#else
#error No database linked.
#endif
Connect(host, db, uid, pw);
}
void Connection::Connect(char *host, char *db, char *uid, char *pw) {
int state;
if( IsConnected() ) {
throw "Connection has already been established.";
}
#if defined(HAS_MSQL)
connection = msqlConnect(host);
state = msqlSelectDB(connection, db);
#elif defined (HAS_MYSQL)
mysql_init(&mysql);
connection = mysql_real_connect(&mysql, host,
uid, pw,
db, 0, 0);
#else
#error No database linked.
#endif
if( !IsConnected() ) {
throw GetError();
}
if( state < 0 ) {
throw GetError();
}
}The two constructors are clearly designed to support the different parameters required by MySQL and mSQL connections. The API, nevertheless, should allow for both constructors to work against either database. The API accomplishes this by ignoring the user ID and password when an application using a mSQL calls the 4-argument constructor. Similarly, null values are passed to MySQL for the user ID and password when the 2-argument constructor is called. The actual database connectivity occurs in the Connect() method.
The Connect() method encapsulates all steps required for a connection. For MySQL, it calls mysql_real_connect() . For mSQL, it instead calls msqlConnect() followed by msqlSelectDB() . If either step fails, Connect() throws an exception.
13.2.1.2. Disconnecting from the database
A Connection's other logic function is to disconnect from the database and free up the resources it has hidden from the application. This functionality occurs in the Close() method. Example 13-1 provides all of the functionality for disconnecting from MySQL and mSQL.
Example 13-1. Freeing up Database Resources
Connection::~Connection() {
if( IsConnected() ) {
Close();
}
}
void Connection::Close() {
if( !IsConnected() ) {
return;
}
#if defined(HAS_MSQL)
msqlClose(connection);
connection = -1;
#elif defined(HAS_MYSQL)
mysql_close(connection);
connection = (MYSQL *)NULL;
#else
#error No database linked.
#endif
}The mysql_close() and msqlClose() methods respectively free up the resources associated with connections to MySQL and mSQL.
13.2.1.3. Making Calls to the database
In between opening a connection and closing it, you generally want to send statements to the database. The Connection class accomplishes this via a Query() method that takes a SQL statement as an argument. If the statement was a query, it returns an instance of the Result class from the object model in Figure 13-1. If, on the other hand, the statement was an update, the method will return NULL and set the affected_rows value to the number of rows affected by the update. Example 13-1 shows how the Connection class handles queries against MySQL and mSQL databases.
Example 13-1. Querying the Database
Result *Connection::Query(char *sql) {
T_RESULT *res;
int state;
// if not connectioned, there is nothing we can do
if( !IsConnected() ) {
throw "Not connected.";
}
// execute the query
#if defined(HAS_MSQL)
state = msqlQuery(connection, sql);
#elif defined(HAS_MYSQL)
state = mysql_query(connection, sql);
#else
#error No database linked.
#endif
// an error occurred
if( state < 0 ) {
throw GetError();
}
// grab the result, if there was any
#if defined(HAS_MSQL)
res = msqlStoreResult();
#elif defined(HAS_MYSQL)
res = mysql_store_result(connection);
#else
#error No database linked.
#endif
// if the result was null, it was an update or an error occurred
// NOTE: mSQL does not throw errors on msqlStoreResult()
if( res == (T_RESULT *)NULL ) {
// just set affected_rows to the return value from msqlQuery()
#if defined(HAS_MSQL)
affected_rows = state;
#elif defined(HAS_MYSQL)
// field_count != 0 means an error occurred
int field_count = mysql_num_fields(connection);
if( field_count != 0 ) {
throw GetError();
}
else {
// store the affected_rows
affected_rows = mysql_affected_rows(connection);
}
#else
#error No database linked.
#endif
// return NULL for updates
return (Result *)NULL;
}
// return a Result instance for queries
return new Result(res);
}The first part of a making-a-database call is calling either mysql_query() or msqlQuery() with the SQL to be executed. Both APIs return a nonzero on error. The next step is to call mysql_store_result() or msqlStoreResult() to check if results were generated and make those results usable by your application. At this point, the two database engines differ a bit on the processing details.
Under the mSQL API, msqlStoreResult() will not generate an error. This function is used by an application to move a newly generated result set into storage to be managed by the application instead of by the mSQL API. In other words, when you call msqlQuery(), it stores any results in a temporary area in memory managed by the API. Any subsequent call to msqlQuery() will wipe out that storage area. In order to store that result in an area of memory managed by your application, you need to call msqlStoreResult().
Because msqlStoreResult() does not generate an error, you need to worry about only two possibilities when you make an msqlStoreResult() call. If the call to the database was a query that generated a result set, msqlStoreResult() returns a pointer to an m_result structure to be managed by the application. For any other kind of call (an update, insert, delete, or create), msqlStoreResult() returns NULL. You can then find out how many rows were affected by a non-query through the return value from the original msqlQuery() call.
Like the msqlStoreResult() call, mysql_store_result() is used to place the results generated by a query into storage managed by the application. Unlike the mSQL version, you need to wrapper mysql_store_result() with some exception handling. Specifically, a NULL return value from mysql_store_result() can mean either the call was a nonquery or an error occurred in storing the results. A call to mysql_num_fields() will tell you which is in fact the case. A field count not equal to zero means an error occurred. The number of affected rows, on the other hand, may be determined by a call to mysql_affected_rows() .[21]
[21]One particular situation behaves differently. MySQL is optimized for cases where you delete all records in a table. This optimization incorrectly causes some versions of MySQL to return for a mysql_affected_rows() call.
13.2.1.4. Other Connection behaviors
Throughout the Connection class are calls to two support methods, IsConnected() and GetError() . Testing for connection status is simple -- you just check the value of the connection attribute. It should be non-NULL for MySQL and something other than -1 for mSQL. Error messages, on the other hand, require some explanation.
Retrieving error messages under mSQL is very simple and straightforward. You just use the value of the msqlErrMsg global variable. This value is exactly what our GetError() method returns for mSQL. MySQL, however, is a little more complicated. Being multithreaded, it needs to provide threadsafe access to any error messages. It manages to make error handling work in a multithreaded environment by hiding error messages behind the mysql_error() function. Example 13-1 shows MySQL and mSQL error handling in the GetError() method as well as connection testing in IsConnected().
Example 13-1. Reading Errors and Other Support Tasks of the Connection Class
int Connection::GetAffectedRows() {
return affected_rows;
}
char *Connection::GetError() {
#if defined(HAS_MSQL)
return msqlErrMsg;
#elif defined(HAS_MYSQL)
if( IsConnected() ) {
return mysql_error(connection);
}
else {
return mysql_error(&mysql);
}
#else
#error No database linked.
#endif
}
int Connection::IsConnected() {
#if defined(HAS_MSQL)
return !(connection < 0);
#elif defined(HAS_MYSQL)
return !(!connection);
#else
#error No database linked.
#endif
)13.2.2. Error Handling Issues
While the error handling above is rather simple because we have encapsulated it into a simple API call in the Connection class, you should be aware of several potential pitfalls you can encounter. First, under mSQL, error handling is global to an application. For applications supporting multiple connections, the value of msqlErrMsg represents the last error from the most recent call to any mSQL API function. More to the point, even though mSQL itself is single threaded, you can write multithreaded applications against it -- but you need to be very careful about how you manage access to error messages. Specifically, you will need to write your own threadsafe API on top of the mSQL C API that copies error messages and associates them with the proper connections.
Both database engines manage the storage of error messages inside their respective APIs. Because you have no control over that storage, you may run into another issue regarding the persistence of error messages. In our C++ API, we are handling the error messages right after they occur -- before the application makes any other database calls. If we wanted to move on with other processing before dealing with an error message, we would need to copy the error message into storage managed by our application.
13.2.3. Result Sets
The Result class is an abstraction on the MySQL and mSQL result concepts. Specifically, should provide access to the data in a result set as well as the meta-data surrounding that result set. According to the object model from Figure 13-1, our Result class will support looping through the rows of a result set and getting the row count of a result set. Example 13-1 is the header file for the Result class.
Example 13-1. The Interface for a Result Class in result.h
#ifndef l_result_h
#define l_result_h
#include <sys/time.h>
#if defined(HAS_MSQL)
#include <msql.h>
#elif defined(HAS_MYSQL)
#include <mysql.h>
#endif
#include "row.h"
class Result {
private:
int row_count;
T_RESULT *result;
Row *current_row;
public:
Result(T_RESULT *);
~Result();
void Close();
Row *GetCurrentRow();
int GetRowCount();
int Next();
};
#endif // l_result_h13.2.3.1. Navigating results
Our Result class enables a developer to work through a result set one row at a time. Upon getting a Result instance from a call to Query() , an application should call Next() and GetCurrentRow() in succession until Next() returns 0. Example 13-1 shows how this functionality looks for MySQL and mSQL.
Example 13-1. Result Set Navigation
int Result::Next() {
T_ROW row;
if( result == (T_RESULT *)NULL ) {
throw "Result set closed.";
}
#if defined(HAS_MSQL)
row = msqlFetchRow(result);
#elif defined(HAS_MYSQL)
row = mysql_fetch_row(result);
#else
#error No database linked.
#endif
if( !row ) {
current_row = (Row *)NULL;
return 0;
}
else {
current_row = new Row(result, row);
return 1;
}
}
Row *Result::GetCurrentRow() {
if( result == (T_RESULT *)NULL ) {
throw "Result set closed.";
}
return current_row;
}The row.h header file in Example 13-1 defines T_ROW and T_RESULT based on which database engine the application is being compiled for. The functionality for moving to the next row in both databases is identical and simple. You simple call mysql_fetch_row() or msqlFetchRow() . If the call returns NULL, there are no more rows left to process.
In an object-oriented environment, this is the only kind of navigation you should ever use. A database API in an OO world exists only to provide you access to the data -- not as a tool for the manipulation of that data. Manipulation should be encapsulated in domain objects. Not all applications, however, are object-oriented applications. MySQL and mSQL each provides a function that allows you to move to specific rows in the database. These methods are mysql_data_seek() and msqlDataSeek() respectively.
13.2.3.2. Cleaning up and row count
Database applications need to clean up after themselves. In talking about the Connection class, we mentioned how the result sets associated with a query are moved into storage managed by the application. The Close() method in the Result class frees the storage associated with that result. Example 13-1 shows how to clean up results and get a row count for a result set.
Example 13-1. Clean up and Row Count
void Result::Close() {
if( result == (T_RESULT *)NULL ) {
return;
}
#if defined(HAS_MSQL)
msqlFreeResult(result);
#elif defined(HAS_MYSQL)
mysql_free_result(result);
#else
#error No database linked.
#endif
result = (T_RESULT *)NULL;
}
int Result::GetRowCount() {
if( result == (T_RESULT *)NULL ) {
throw "Result set closed.";
}
if( row_count > -1 ) {
return row_count;
}
else {
#if defined(HAS_MSQL)
row_count = msqlNumRows(result);
#elif defined(HAS_MYSQL)
row_count = mysql_num_rows(result);
#else
#error No database linked.
#endif
return row_count;
}
}13.2.4. Rows
An individual row from a result set is represented in our object model by the Row class. The Row class enables an application to get at individual fields in a row. Example 13-1 shows the declaration of a Row class.
Example 13-1. The Row Class from row.h
#ifndef l_row_h
#define l_row_h
#include <sys/types.h>
#if defined(HAS_MSQL)
#include <msql.h>
#define T_RESULT m_result
#define T_ROW m_row
#elif defined(HAS_MYSQL)
#include <mysql.h>
#define T_RESULT MYSQL_RES
#define T_ROW MYSQL_ROW
#endif
class Row {
private:
T_RESULT *result;
T_ROW fields;
public:
Row(T_RESULT *, T_ROW);
~Row();
char *GetField(int);
int GetFieldCount();
int IsClosed();
void Close();
};
#endif // l_row_hBoth APIs have macros for datatypes representing a result set and a row within that result set. In both APIs, a row is really nothing more than an array of strings containing the data from that row. Access to that data is controlled by indexing on that array based on the query order. For example, if your query was SELECT user_id, password FROM users, then index would contain the user ID and index 1 the password. Our C++ API makes this indexing a little more user friendly. GetField(1) will actually return the first field, or fields[0]. Example 13-2 contains the full source listing for the Row class.
Example 13-2. The Implementation of the Row Class
#include <malloc.h>
#include "row.h"
Row::Row(T_RESULT *res, T_ROW row) {
fields = row;
result = res;
}
Row::~Row() {
if( !IsClosed() ) {
Close();
}
}
void Row::Close() {
if( IsClosed() ) {
throw "Row closed.";
}
fields = (T_ROW)NULL;
result = (T_RESULT *)NULL;
}
int Row::GetFieldCount() {
if( IsClosed() ) {
throw "Row closed.";
}
#if defined(HAS_MSQL)
return msqlNumFields(result);
#elif defined(HAS_MYSQL)
return mysql_num_fields(result);
#else
#error No database linked.
#endif
}
// Caller should be prepared for a possible NULL
// return value from this method.
char *Row::GetField(int field) {
if( IsClosed() ) {
throw "Row closed.";
}
if( field < 1 || field > GetFieldCount() ) {
throw "Field index out of bounds.";
}
return fields[field-1];
}
int Row::IsClosed() {
return (fields == (T_ROW)NULL);
}An example application using these C++ classes is packaged with the examples from this book.
 |  |  |
| 13. C and C++ |  | 14. Java and JDBC |

Copyright © 2001 O'Reilly & Associates. All rights reserved.