
2.2. Normalization
E.F. Codd, then a researcher for IBM, first presented the concept of database normalization in several important papers written in the 1970s. The aim of normalization remains the same today: to eradicate certain undesirable characteristics from a database design. Specifically, the goal is to remove certain kinds of data redundancy and therefore avoid update anomalies. Update anomalies are difficulties with the insert, update, and delete operations on a database due to the data structure. Normalization additionally aids in the production of a design that is a high-quality representation of the real world; thus normalization increases the clarity of the data model.
As an example, say we misspelled "Herbie Hancock" in our database and we want to update it. We would have to visit each CD by Herbie Hancock and fix the artist's name. If the updates are controlled by an application which enables us to edit only one record at a time, we end up having to edit many rows. It would be much more desirable to have the name "Herbie Hancock" stored only once so we have to maintain it in just one place.
2.2.1. First Normal Form (1NF)
The general concept of normalization is broken up into several "normal forms." An entity is said to be in the first normal form when all attributes are single-valued. To apply the first normal form to an entity, we have to verify that each attribute in the entity has a single value for each instance of the entity. If any attribute has repeating values, it is not in 1NF.
A quick look back at our database reveals that we have repeating values in the Songs attribute, so the CD is clearly not in 1NF. To remedy this problem, an entity with repeating values indicates that we have missed at least one other entity. One way to discover other entities is to look at each attribute and ask the question "What thing does this describe?"
What does Song describe? It lists the songs on the CD. So Song is another "thing" that we capture data about and is probably an entity. We will add it to our diagram and give it a Song Name attribute. To complete the Song entity, we need to ask if there is more about a Song that we would like to capture. We identified earlier song length as something we might want to capture. Figure 2-1 shows the new data model.
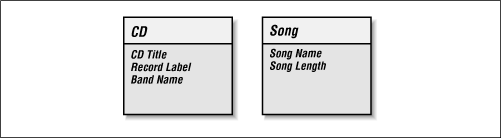
Figure 2-1. A data model with CD and Song entities
Now that the Song Name and Song Length are attributes in a Song entity, we have a data model with two entities in 1NF. None of their attributes contain multiple values. Unfortunately, we have not shown any way of relating a CD to a Song.
2.2.2. The Unique Identifier
Before discussing relationships, we need to impose one more rule on entities. Each entity must have a unique identifier -- we'll call it the ID. An ID is an attribute of an entity that meets the following rules:
It is unique across all instances of the entity.
It has a non-NULL value for each instance of the entity, for the entire lifetime of the instance.
It has a value that never changes for the entire lifetime of the instance.
The ID is very important because it gives us a way to know which instance of an entity we are dealing with. Identifier selection is critical because it is also used to model relationships. If, after you've selected an ID for an entity, you find that it doesn't meet one of the above rules, this could affect your entire data model.
Novice data modelers often make the mistake of choosing attributes that should not be identifiers and making them identifiers. If, for example, you have a Person entity, it might be tempting to use the Name attribute as the identifier because all people have a name and that name never changes. But what if a person marries? What if the person decides to legally change his name? What if you misspelled the name when you first entered it? If any of these events causes a name change, the third rule of identifiers is violated. Worse, is a name really ever unique? Unless you can guarantee with 100% certainty that the Name is unique, you will be violating the first rule. Finally, you do know that all Person instances have non-NULL names. But are you certain that you will always know the name of a Person when you first enter information about them in the database? Depending on your application processes, you may not know the name of a Person when a record is first created. The lesson to be learned is that there are many problems with taking a nonidentifying attribute and making it one.
The solution to the identifier problem is to invent an identifying attribute that has no other meaning except to serve as an identifying attribute. Because this attribute is invented and completely unrelated to the entity, we have full control over it and guarantee that it meets the rules of unique identifiers. Figure 2-1 adds invented ID attributes to each of our entities. A unique identifier is diagrammed as an underlined attribute.
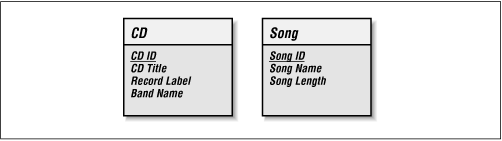
Figure 2-1. The CD and Song entities with their unique identifiers
2.2.3. Relationships
The identifiers in our entities enable us to model their relationships. A relationship describes a binary association between two entities. A relationship may also exist between an entity and itself. Such a relationship is called a recursive relationship. Each entity within a relationship describes and is described by the other. Each side of the relationship has two components: a name and a degree.
Each side of the relationship has a name that describes the relationship. Take two hypothetical entities, an Employee and a Department. One possible relationship between the two is that an Employee is "assigned to" a Department. That Department is "responsible for" an Employee. The Employee side of the relationship is thus named "assigned to" and the Department side "responsible for."
Degree, also referred to as cardinality, states how many instances of the describing entity must describe one instance of the described entity. Degree is expressed using two different values: "one and only one" (1) and "one or many" (M). An employee is assigned to one department at a time, so Employee has a one and only one relationship with Department. In the other direction, a department is responsible for many employees. We therefore say Department has a "one or many" relationship with Employee. As a result a Department could have exactly one Employee.
It is sometimes helpful to express a relationship verbally. One way of doing this is to plug the various components of a direction of the relationship into this formula:
entity1 has [one and only one | one or many] entity2
Using this formula, Employee and Department would be expressed like so:
Each Employee must be assigned to one and only one Department.
Each Department may be responsible for one or many Employees.
We can use this formula to describe the entities in our data model. A CD contains one or many Songs and a Song is contained on one and only one CD. In our data model, this relationship can be shown by drawing a line between the two entities. Degree is expressed with a straight line for "one and only one" relationships or "crows feet" for "one or many" relationships. Figure 2-1 illustrates these conventions.
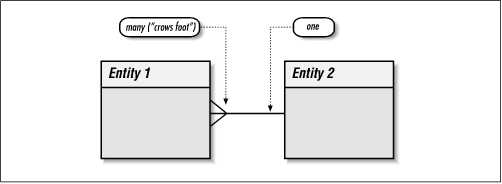
Figure 2-1. Anatomy of a relationship
How does this apply to the relationship between Song and CD? In reality, a Song can be contained on many CDs, but we ignore this for the purposes of this example. Figure 2-2 shows the data model with the relationships in place.
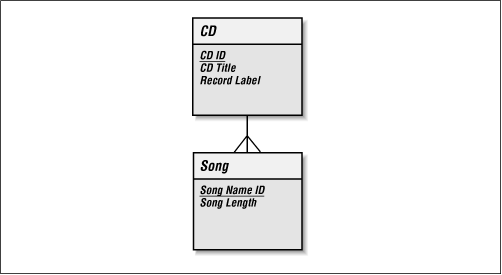
Figure 2-2. CD-Song relationship
With these relationships firmly in place, we can go back to the normalization process and improve upon the design. So far, we have normalized repeating song values into a new entity and modeled the relationship between it and the CD entity.
2.2.4. Second Normal Form (2NF)
An entity is said to be in the second normal form if it is already in 1NF and all nonidentifying attributes are dependent on the entity's entire unique identifier. If any attribute is not dependent entirely on the entity's unique identifier, that attribute has been misplaced and must be removed. Normalize these attributes either by finding the entity where it belongs or by creating an additional entity where the attribute should be placed.
In our example, "Herbie Hancock" is the Band Name for two different CDs. This fact illustrates that Band Name is not entirely dependent on CD ID. This duplication is a problem because if, for example, we had misspelled "Herbie Hancock," we would have to update the value in multiple places. We thus have a sign that Band Name should be part of a new entity with some relationship to CD. As before, we resolve this problem by asking the question: "What does a band name describe"? It describes a band, or more generally, an artist. Artist is yet another thing we are capturing data about and is therefore probably an entity. We will add it to our diagram with Band Name as an attribute. Since all artists may not be bands, we will rename the attribute Artist Name. Figure 2-1 shows the new state of the model.
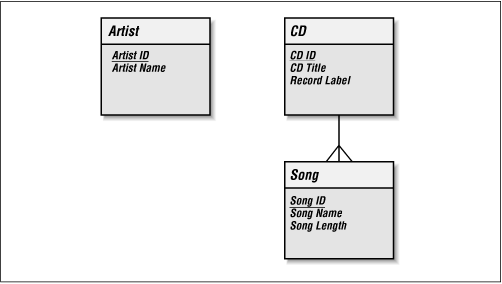
Figure 2-1. The data model with the new Artist entity
Of course, the relationships for the new Artist table are missing. We know that each Artist has one or many CDs. Each CD could have one or many Artists. We model this in Figure 2-2.
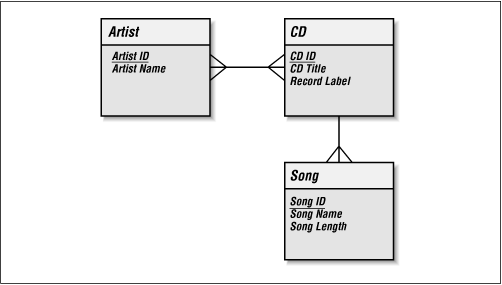
Figure 2-2. The Artist relationships in the data model
We originally had the Band Name attribute in the CD entity. It thus seemed natural to make Artist directly related to CD. But is this really correct? On closer inspection, it would seem that there should be a direct relationship between an Artist and a Song. Each Artist has one or more Songs. Each Song is performed by one and only one Artist. The true relationship appears in Figure 2-3.
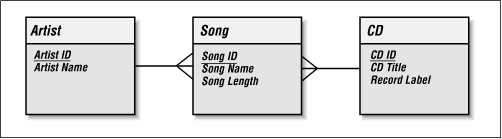
Figure 2-3. The real relationship between Artist and the rest of our data model
Not only does this make more sense than a relationship between Artist and CD, but it also addresses the issue of compilation CDs.
2.2.5. Kinds of Relationships
When modeling the relationship between entities, it is important to determine both directions of the relationship. After both sides of the relationship have been determined, we end up with three main kinds of relationships. If both sides of the relationship have a degree of one and only one, the relationship is called a "one-to-one" or "1-to-1" relationship. As we will find out later, one-to-one relationships are rare. We do not have one in our data model.
If one of the sides as a degree of "one or many" and the other side has a degree of "one and only one," the relationship is a "one-to-many" or "1-to-M" relationship. All of the relationships in our current data model are one-to-many relationships. This is to be expected since one-to-many relationships are the most common.
The final kind of relationships is where both sides of the relationship are "one or many" relationships. These kind of relationships are called "many-to-many" or "M-to-M" relationships. In an earlier version of our data model, the Artist-CD relationship was a many-to-many relationship.
2.2.6. Refining Relationships
As we noted earlier, one-to-one relationships are quite rare. In fact, if you encounter one during your data modeling, you should take a closer look at your design. A one-to-one relationship may imply that two entities are really the same entity. If they do turn out to be the same entity, they should be folded into a single entity.
Many-to-many relationships are more common than one-to-one relationships. In these relationships, there is often some data we want to capture about the relationship. For example, take a look at the earlier version of our data model in Figure 2-2 that had the many-to-many relationship between Artist and CD. What data might we want to capture about that relationship? An Artist has a relationship with a CD because an Artist has one or more Songs on that CD. The data model in Figure 2-3 is actually another representation of this many-to-many relationship.
All many-to-many relationships should be resolved using the following technique:
Create a new entity (sometimes referred to as a junction entity). Name it appropriately. If you cannot think of an appropriate name for the junction entity, name it by combining the names of the two related entities (e.g., ArtistCD). In our data model, Song is a junction entity for the Artist-CD relationship.
Relate the new entity to the two original entities. Each of the original entities should have a one-to-many relationship with the junction entity.
If the new entity does not have an obvious unique identifier, inherit the identifying attributes from the original entities into the junction entity and make them together the unique identifier for the new entity.
In almost all cases, you will find additional attributes that belong in the new junction entity. If not, the many-to-many relationship still needs to be resolved, otherwise you will have a problem translating your data model into a physical schema.
2.2.7. More 2NF
Our data model is still not in 2NF. The value of the Record Label attribute has only one value for each CD, but we see the same Record Label in multiple CDs. This situation is similar to the one we saw with Band Name. As with Band Name, this duplication indicates that Record Label should be part of its own entity. Each Record Label releases one or many CDs. Each CD is released by one and only one Record Label. Figure 2-1 models this relationship.
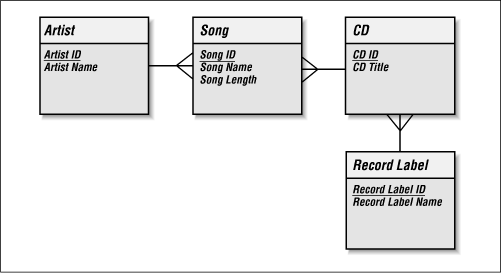
Figure 2-1. Our data model in the second normal form
2.2.8. Third Normal Form (3NF)
An entity is said to be in the third normal form if it is already in 2NF and no non-identifying attributes are dependent on any other nonidentifying attributes. Attributes that are dependent on other nonidentifying attributes are normalized by moving both the dependent attribute and the attribute on which it is dependent into a new entity.
If we wanted to track Record Label address information, we would have a problem for 3NF. The Record Label entity with address data would have State Name and State Abbreviation attributes. Though we really do not need this information to track CD data, we will add it to our data model for the sake of our example. Figure 2-1 shows address data in the Record Label entity.
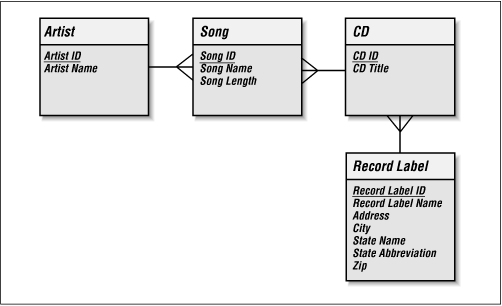
Figure 2-1. Record Label address information in our CD database
The values of State Name and State Abbreviation would conform to 1NF because they have only one value per record in the Record Label entity. The problem here is that State Name and State Abbreviation are dependent on each other. In other words, if we change the State Abbreviation for a particular Record Label -- from MN to CA -- we also have to change the State Name -- from Minnesota to California. We would normalize this by creating a State entity with State Name and State Abbreviation attributes. Figure 2-2 shows how to relate this new entity to the Record Label entity.
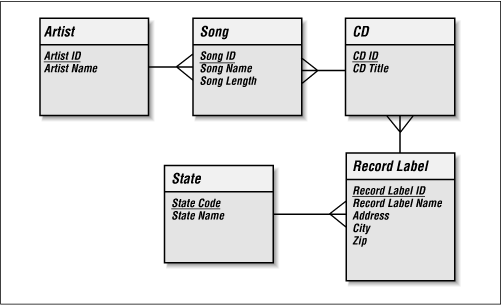
Figure 2-2. Our data model in the third normal form
Now that we are in 3NF, we can say that our data model is normalized. There are other normal forms which have some value from a database design standpoint, but these are beyond the scope of this book. For most design purposes, the third normal form is sufficient to guarantee a proper design.
 |  |  |
| 2. Database Design |  | 2.3. A Logical Data Modeling Methodology |

Copyright © 2001 O'Reilly & Associates. All rights reserved.