
2.3. Browser Requests
Every HTTP interaction starts with a request from a client, typically a web browser. A user provides a URL to the browser by typing it in, clicking on a hyperlink, or selecting a bookmark, and the browser fetches the corresponding document. To do that, it must create an HTTP request (see Figure 2-4).
Figure 2-4. The structure of HTTP request headers
Recall that in our previous example, a web browser generated the following request when it was asked to fetch the URL http://localhost/index.html :
GET /index.html HTTP/1.1 Host: localhost Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, image/xbm, */* Accept-Language: en Connection: Keep-Alive User-Agent: Mozilla/4.0 (compatible; MSIE 4.5; Mac_PowerPC) . . .
From our discussion of URLs, you know that the URL can be broken down into multiple elements. The browser creates a network connection by using the hostname and the port number (80 by default). The scheme (http) tells our web browser that it is using the HTTP protocol, so once the connection is established, it sends an HTTP request for the resource. The first line of an HTTP request is the request line, which includes a full virtual path and query string (if present); see Figure 2-5.
Figure 2-5. The request line
2.3.1. The Request Line
The first line of an HTTP request includes the request method, a URL to the resource being requested, and the version string of the protocol. Request methods are case-sensitive and uppercase. There are several request methods defined by HTTP although a web server may not make all of them available for each resource (see Table 2-1). The version string is the name and version of the protocol separated by a slash. HTTP 1.0 and HTTP 1.1 are represented as HTTP/1.0 and HTTP/1.1. Note that https requests also produce one of these two HTTP protocol strings.
Table 2-1. HTTP Request Methods
|
Method |
Description |
|---|---|
|
GET |
Asks the server for the given resource |
|
HEAD |
Used in the same cases that a GET is used but it only returns HTTP headers and no content |
|
POST |
Asks the server to modify information stored on the server |
|
PUT |
Asks the server to create or replace a resource on the server |
|
DELETE |
Asks the server to delete a resource on the server |
|
CONNECT |
Used to allow secure SSL connections to tunnel through HTTP connections |
|
OPTIONS |
Asks the server to list the request methods available for the given resource |
|
TRACE |
Asks the server to echo back the request headers as it received them |
Of the request methods listed in Table 2-1, the three you will encounter most often when writing CGI scripts are GET, HEAD, and POST. However, let's first take a look at why the PUT and DELETE methods are not used with CGI.
2.3.1.1. PUT and DELETE
The Web was originally conceived as a medium where users could both read and write content. However, the Web took off initially as a read-only medium and it is only through Web Distributed Authoring and Versioning (WebDAV) that interest is returning to the ability to write content to the Web. The PUT and DELETE methods tell the server to create, replace, or remove the resource they are directed at. Note that this means that if one of these requests is targeted at a CGI script (assuming the request is valid), the CGI script will be replaced or removed, but not executed. Thus, you do not need to worry about these request methods within your CGI scripts. While it might be possible to remap a PUT or DELETE request directed at a particular URL so that a different CGI script handles it, such a discussion of WebDAV implementation is beyond the scope of this book.
2.3.1.2. GET
GET is the standard request method for retrieving a document via HTTP on the Web. When you click on a hyperlink, type a location into your browser, or click on a bookmark, the browser generally creates a GET request for the URL you requested. GET requests are intended only to retrieve resources and should not have side effects. They should not alter information maintained on the web server; POST is intended for that purpose. GET requests do not have a content body.
In practice, some CGI developers do not understand nor follow the policy that GET requests should not have side effects, even though it is a good idea to do so. Because web browsers assume that GET requests have no side effects, they may be carefree about making multiple requests for the same document. For instance, if the user presses the browser's "back" button to return to a page that was originally requested via GET and is no longer in the browser's cache, the browser may GET a new copy. If the original request was via POST, however, the user would instead receive a message that the document is no longer available in the cache. If the user then decides to reload the request, he or she will generally receive a dialog confirming that they wish to resend the POST request. These features help the user avoid mistakenly sending a request multiple times when the request would modify information stored on the server.
2.3.1.3. HEAD
You may have noticed that we said that your web browser generally creates a GET request to fetch resources you have requested. If your browser has previously retrieved a resource, it may be stored within the browser's cache. In order for the browser to know whether to display the cached copy or whether to request a fresh copy, the browser can send a HEAD request. HEAD requests are formatted exactly like GET requests, and the server responds to it exactly like a GET request with one exception: it sends only the HTTP headers, it doesn't send the content. The browser can then check the meta-information contained in the headers, such as the modification date of the resource, to see if it has changed and whether it should replace the cached version with the newer version. HEAD requests do not have a content body either.
In practice, you can treat HEAD requests the same as GET requests in your CGI scripts, and the web server will truncate the content of your responses and return only headers. For this reason, we will rarely discuss to the HEAD request method in this book. If you are concerned about performance, you may wish to check the request method yourself and conserve resources by not generating content for HEAD requests. We will see how your script can determine the request method in the next chapter.
2.3.1.4. POST
POST is used with HTML forms to submit information that alters data stored on the web server. POST requests always include a body containing the submitted information formatted like a query string. POST requests thus require additional headers specifying the length of the content and its format. These headers are described in the following section.
Although POST requests should only be used to modify data on the server, CGI developers commonly use POST requests for CGI scripts that simply return information, but do not modify data. This practice is more common and less dangerous than the reverse situation -- using GET to modify data on the server. Developers use POST for any number of reasons:
Some developers believe that forms submitted via POST offer greater security over those submitted via GET because a user cannot modify the values within the URL in the browser as they can with GET. This reasoning is flawed. Knowledgeable users, as we will see in our security discussion in Chapter 8, "Security", can easily find ways around this.
The responses to resources received via POST cannot be bookmarked or hyperlinked (at least without using a bookmarklet; see Chapter 7, "JavaScript"). Although this is generally inconvenient for the user, sometimes this is the preferred behavior.
Note that users may encounter browser warnings about expired pages if they attempt to revisit cached pages obtained via POST.
2.3.2. Request Header Field Lines
The client generally sends several header fields with its request. As mentioned earlier, these consist of a field name, a colon, some combination of spaces or tabs (although one space is most common), and a value (see Figure 2-6). These fields are used to pass additional information about the request or about the client, or to add conditions to the request. We'll discuss the common browser headers here; they are listed in Table 2-2. Those connected with content negotiation and caching are discussed later in this chapter.
Figure 2-6. A header field line
Table 2-2. Common HTTP Request Headers
|
Header |
Description |
|---|---|
|
Host |
Specifies the target hostname |
|
Content-Length |
Specifies the length (in bytes) of the request content |
|
Content-Type |
Specifies the media type of the request |
|
Specifies the username and password of the user requesting the resource |
|
|
User-Agent |
Specifies the name, version, and platform of the client |
|
Referer |
Specifies the URL that referred the user to the current resource |
|
Cookie |
Returns a name/value pair set by the server on a previous response |
2.3.2.1. Host
The Host field is new and is required in HTTP 1.1. The client sends the host name of the web server in this field. This may sound redundant, since the host should know its own identity, right? Well, not always. A machine with one IP address may have multiple domain names mapped to it, such as www.oreilly.com and www.ora.com. When a request comes in, it looks at this header to determine what name the client is referring to it as, and thus maps the request to the correct content.
2.3.2.2. Content-Length
POST requests include a content body; in order for the web server to know how much data to read, it must declare the size of the body in bytes in the Content-Length field. There are a couple of circumstances where HTTP 1.1 clients may omit this field, but these cases don't concern us because the web server will still calculate this value for us and provide it to our CGI scripts as though it had been included in the original request. POST requests that contain empty contents supply a value of in this header. Requests that do not have a content body, such as GET and HEAD, omit this field.
2.3.2.3. Content-Type
The Content-Type header must always be provided with requests containing a body. It specifies the media type of the message. The most common value of this data received from an HTML form via POST is application/x-www-form-urlencoded, although another option for form input (used when submitting files) is multipart/form-data . We'll discuss how to specify the media type of requests in our discussion of HTML forms in Chapter 4, "Forms and CGI", and we will look at how to parse multipart requests in Chapter 5, "CGI.pm".
2.3.2.4. Authorization
Web servers can require a login for access to some resources. If you have ever attempted to access a restricted area of a web site and been prompted for a login and password, then you have encountered this form of HTTP authentication (see Figure 2-7).[3] Note that the login prompt includes text identifying what you are logging in to; this is the realm . Resources that share the same login are part of the same realm. For most web servers, you assign resources to a realm by putting them in the same directory and configuring the web server to assign the directory a name for the realm along with authorization requirements. For example, if you wanted to restrict access to URL paths that begin with /protected , then you would add the following to httpd.conf (or access.conf, if you are using it):
[3]The distinction between authentication and authorization is subtle, but important. Authentication is the process of identifying someone. Authorization determines what that person can access.
<Location /protected> AuthType Basic AuthName "The Secret Files" AuthUserFile /usr/local/apache/conf/secret.users require valid-user </Location>
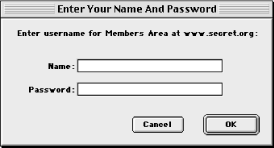
Figure 2-7. Prompt presented to the user for HTTP authorization
The user file contains usernames and encrypted passwords separated by a colon. You can use the htpasswd utility that comes with Apache to create and update this file; refer to its manpage or the Apache manual for usage. When the browser requests a resource in a restricted realm, the server informs the browser that it requires login information by sending a 401 status code and the name of the realm in the WWW-Authenticate header (we'll discuss this later in the chapter). The browser then prompts the user for a username and password for this realm (if it hasn't done so already) and resends the request with the credentials in an Authorization field. There are multiple types of HTTP authentication, but the only type that is widely supported by browsers and servers is basic authentication.
The Authorization field for basic authentication looks like this:
Authorization: Basic dXNlcjpwYXNzd29yZA==
The encoded portion is simply the username and password joined with a colon and Base64-encoded. This can be easily decoded, so basic authentication provides no security against third parties sniffing usernames and passwords unless the connection is secured via SSL.
The server handles authentication and authorization transparently for you. As we will see in the next chapter, you may access the login name from your CGI scripts but not the password.
2.3.2.5. User-Agent
This field indicates what client the user is using to access the Web. The value is generally comprised of a nickname of the browser, its version number, and the operating system and platform on which it's running. Here is an example from Netscape Communicator:
User-Agent: Mozilla/4.5 (Macintosh; I; PPC)
Unfortunately, Microsoft Internet Explorer made the dubious decision when it released its browser of also claiming to be "Mozilla," which is Netscape's nickname. Apparently this was done because a number of web sites used this field to distinguish Netscape browsers from others in order to take advantage of the additional features Netscape offered at the time. Microsoft made their browser compatible with many of these features and wanted its users to also take advantage of these enhanced web sites. Even now, the "Mozilla" moniker remains for the sake of backward-compatibility. Here is an example from Internet Explorer:
User-Agent: Mozilla/4.0 (compatible; MSIE 4.5; Mac_PowerPC)
2.3.2.6. Accept
The Accept field and related fields that begin with Accept, such as Accept-Language, are sent by the client to tell the server the categories of responses it is capable of understanding. These categories include file formats, languages, character sets, etc. We discuss this process in more detail later in this chapter in Section 2.6, "Content Negotiation".
2.3.2.7. Referer
No, this is not a typo. Unfortunately, the Referer field was misspelled in the original protocol and, due to the need to maintain backward-compatibility, we are stuck with it this way. This field provides the URL of the last page the user visited, which is generally the page that linked the user to the requested page:
Referer: http://localhost/index.html
This field is not always sent to the server; browsers provide this field only when the user generates a request by following a hyperlink, submitting a form, etc. Browsers don't generally provide this field when the user manually enters a URL or selects a bookmark, since these may involve a significant invasion of the user's privacy.
2.3.2.8. Cookies
Web browsers or servers may provide additional headers that are not part of the HTTP standard. The receiving application should ignore any headers it does not recognize. A example of a pair of headers not specified in the HTTP protocol are Set-Cookie and Cookie, which Netscape introduced to support browser cookies. Set-Cookie is sent by the server as part of a response:
Set-Cookie: cart_id=12345; path=/; expires=Sat, 18-Mar-05 19:06:19 GMT
This header contains data for the client to echo back in the Cookie header in future requests to that server:
Cookie: cart_id=12345
By assigning different values to each user, servers (and CGI scripts) can use cookies to differentiate between users. We discuss cookies extensively in Chapter 11, "Maintaining State".
 |  |  |
| 2.2. HTTP |  | 2.4. Server Responses |

Copyright © 2001 O'Reilly & Associates. All rights reserved.