
12.6. HTML Forms
Managing HTML forms requires a little extra work and a few special tricks when you're dealing with localized content. To understand the problem, imagine this situation. An HTML form is sent as part of a Japanese page. It asks the user for his name, which he enters as a string of Japanese characters. How is that name submitted to the servlet? And, more importantly, how can the servlet read it?
The answer to the first question is that all HTML form data is sent as a sequence of bytes. Those bytes are an encoded representation of the original characters. With Western European languages, the encoding is the default, ISO-8859-1, with one byte per character. For other languages, there can be other encodings. Browsers tend to encode form data using the same encoding that was applied to the page containing the form. Thus, if the Japanese page mentioned was encoded using Shift_JIS, the submitted form data would also be encoded using Shift_JIS. Note, however, that if the page did not specify a charset and the user had to manually choose Shift_JIS encoding for viewing, many browsers stubbornly submit the form data using ISO-8859-1.[5] Generally, the encoded byte string contains a large number of special bytes that have to be URL-encoded. For example, if we assume the Japanese form sends the user's name using a GET request, the resulting URL might look like this:
[5] For more information on the internationalization of HTML and HTML forms, see RFC 2070 at http://www.ietf.org/rfc/rfc2070.txt.
http://server:port/servlet/NameHandler?name=%8CK%8C%B4%90%B3%8E%9F
The answer to the second question, how can a servlet read the submitted information, is a bit more complicated. A servlet has two choices. First, a servlet can leave the form data in its raw encoded format, treating it essentially like a sequence of bytes--with each byte awkwardly stored as a character in the parameter string. This tactic is useful only if the servlet does not need to manipulate the data and can be sure that the data is output only to the same user using the same charset. Alternatively, a servlet can convert the form data from its native encoded format to a Java-friendly Unicode string. This allows the servlet to freely manipulate the text and output the text using alternate charsets. There is one problem with this plan, however. Browsers currently provide no information to indicate which encoding was used on the form data. Browsers may provide that information in the future (using the Content-Type header in a POST, most likely), but for now, the servlet is left responsible for tracking that information.
12.6.1. The Hidden Charset
The commonly accepted technique for tracking the charset of submitted form data is to use a hidden charset form field.[6] Its value should be set to the charset of the page in which it is contained. Then, any servlet receiving the form can read the value of the charset field and know how to decode the submitted form data.
[6]Hidden form fields, if you remember, were first discussed in Chapter 7, "Session Tracking", where they were used for session tracking.
Example 12-11 demonstrates this technique with a form generator that sets the charset to match the charset of the page. Here's an English resource bundle that might accompanying the servlet, stored as CharsetForm_en.properties:
title=CharsetForm header=<H1>Charset Form</H1> prompt=Enter text:
And here's a Japanese resource, to be stored as CharsetForm_ja.properties:
title=CharsetForm header=<H1>\u6587\u5b57\u30bb\u30c3\u30c8\u30fb\u30d5\u30a9\u30fc\u30e0</H1> prompt=\u30c6\u30ad\u30b9\u30c8\u3092\u5165\u529b\u3057\u3066\u304f\u3060\ \u3055\u3044
A screen shot of the Japanese version is shown in Figure 12-6.
Example 12-11. Saving the charset in a hidden form field
import java.io.*;
import java.util.*;
import javax.servlet.*;
import javax.servlet.http.*;
import com.oreilly.servlet.LocaleNegotiator;
import com.oreilly.servlet.ServletUtils;
public class CharsetForm extends HttpServlet {
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException {
try {
String bundleName = "CharsetForm";
String acceptLanguage = req.getHeader("Accept-Language");
String acceptCharset = req.getHeader("Accept-Charset");
LocaleNegotiator negotiator =
new LocaleNegotiator(bundleName, acceptLanguage, acceptCharset);
Locale locale = negotiator.getLocale();
String charset = negotiator.getCharset();
ResourceBundle bundle = negotiator.getBundle(); // may be null
res.setContentType("text/html; charset=" + charset);
res.setHeader("Content-Language", locale.getLanguage());
res.setHeader("Vary", "Accept-Language");
PrintWriter out = res.getWriter();
if (bundle != null) {
out.println("<HTML><HEAD><TITLE>");
out.println(bundle.getString("title"));
out.println("</TITLE></HEAD>");
out.println("<BODY>");
out.println(bundle.getString("header"));
out.println("<FORM ACTION=/servlet/CharsetAction METHOD=get>");
out.println("<INPUT TYPE=hidden NAME=charset value=" + charset + ">");
out.println(bundle.getString("prompt"));
out.println("<INPUT TYPE=text NAME=text>");
out.println("</FORM>");
out.println("</BODY></HTML>");
}
else {
out.println("Bundle could not be found.");
}
}
catch (Exception e) {
log(ServletUtils.getStackTraceAsString(e));
}
}
}
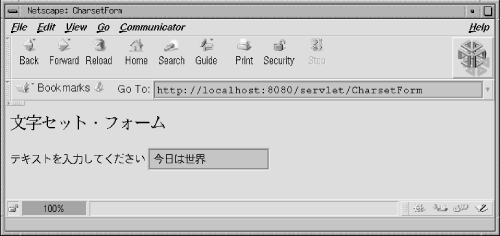
Figure 12-6. A Japanese form, with the user entering text
The servlet responsible for handling the submitted form is shown in Example 12-12. This servlet reads the submitted text and converts it to Unicode, then outputs the characters using the UTF-8 encoding. As a bonus, it also displays the received string as a Unicode escape string, showing what you would have to enter in a Java source file or resource bundle to create the same output. This lets the servlet act as a web-based native charset to Unicode string translator. Sample output is shown in Figure 12-7.
Example 12-12. Receiving the charset in a hidden form field
import java.io.*;
import java.text.*;
import java.util.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class CharsetAction extends HttpServlet {
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException {
try {
res.setContentType("text/plain; charset=UTF-8");
PrintWriter out = res.getWriter();
String charset = req.getParameter("charset");
// Get the text parameter
String text = req.getParameter("text");
// Now convert it from an array of bytes to an array of characters.
// Do this using the charset that was sent as a hidden field.
// Here we bother to read only the first line.
BufferedReader reader = new BufferedReader(
new InputStreamReader(new StringBufferInputStream(text), charset));
text = reader.readLine();
out.println("Received charset: " + charset);
out.println("Received text: " + text);
out.println("Received text (escaped): " + toUnicodeEscapeString(text));
}
catch (Exception e) {
e.printStackTrace();
}
}
public void doPost(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException {
doGet(req, res);
}
private static String toUnicodeEscapeString(String str) {
// Modeled after the code in java.util.Properties.save()
StringBuffer buf = new StringBuffer();
int len = str.length();
char ch;
for (int i = 0; i < len; i++) {
ch = str.charAt(i);
switch (ch) {
case '\\': buf.append("\\\\"); break;
case '\t': buf.append("\\t"); break;
case '\n': buf.append("\\n"); break;
case '\r': buf.append("\\r"); break;
default:
if (ch >= ' ' && ch <= 127) {
buf.append(ch);
}
else {
buf.append('\\');
buf.append('u');
buf.append(toHex((ch >> 12) & 0xF));
buf.append(toHex((ch >> 8) & 0xF));
buf.append(toHex((ch >> 4) & 0xF));
buf.append(toHex((ch >> 0) & 0xF));
}
}
}
return buf.toString();
}
private static char toHex(int nibble) {
return hexDigit[(nibble & 0xF)];
}
private static char[] hexDigit = {
'0','1','2','3','4','5','6','7','8','9','a','b','c','d','e','f'
};
}
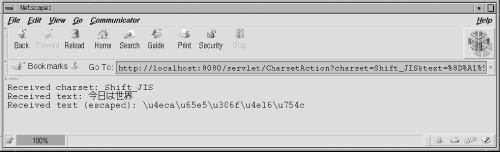
Figure 12-7. Handling a Japanese form
The most interesting part of this servlet is the bit that receives and converts the submitted text.
String text = req.getParameter("text");
BufferedReader reader = new BufferedReader(
new InputStreamReader(new StringBufferInputStream(text), charset));
text = reader.readLine();
The first line receives the text in its raw format. Although it's stored as a String, it's not a true String. Each character in the String stores one byte of the encoded text. The second and third lines wrap the text with a StringBufferInputStream, an InputStreamReader, and a BufferedReader. The decoding happens with the InputStreamReader, whose constructor accepts the encoding specified by the charset field. Finally, the BufferedReader wraps around the InputStreamReader for convenience. This lets us receive the text one line at a time, as shown in the fourth line.
 |  |  |
| 12.5. Dynamic Language Negotiation |  | 12.7. Receiving Multilingual Input |

Copyright © 2001 O'Reilly & Associates. All rights reserved.