
12.3. Non-Western European Languages
Let's continue now with a look at how a servlet outputs a page written in a non-Western European language, such as Russian, Japanese, Chinese, Korean, or Hebrew. To understand how to work with these languages, we must first understand how things work behind the scenes of our previous examples.
12.3.1. Charsets
Let's begin looking at the situation from the perspective of the browser. Imagine having the browser's job. You make an HTTP request to some URL and receive a response. That response, in the basest terms, is nothing more than a long sequence of bytes. How do you know how to display that response?
A common way, and in fact the default way, is to assume that every byte represents one of 256 possible characters and to further assume that the character a byte represents can be determined by looking up the byte value in some table. The default table is specified by the ISO-8859-1 standard, also called Latin-1. It contains byte-to-character mappings for the characters most commonly used in Western European languages. So, by default, you (acting as the browser) can receive a sequence of bytes and convert them to a sequence of Western European characters.
Now whatdo you do if you want to receive text that isn't written in a Western European language? You have to take the long sequence of bytes in the response and interpret it differently, using some other byte-sequence to character mapping. Technically put, you need to use a different charset.[2] There are an infinite number of potential charsets. Fortunately, there are only a few dozen that are commonly used.
[2] A charset (a byte-sequence to character mapping) is not the same as a character set (a set of characters). See RFC 2278 at http://www.ietf.org/rfc/rfc2278.txt for a full explanation.
Some charsets use single-byte characters in a fashion similar to ISO-8859-1, though with a different byte-to-character mapping. For example, ISO-8859-5 defines a byte-to-character mapping for the characters of the Cyrillic (Russian) alphabet, while ISO-8859-8 defines a mapping for the Hebrew alphabet.[3]
[3] It's useful to note that, for nearly all charsets, the byte values between and 127 decimal represent the standard US-ASCII characters, allowing English text to be added to a page written in nearly any language.
Other charsets use multibyte characters, where it may take more than one byte to represent a single character. This is most common with languages that contain thousands of characters, such as Chinese, Japanese, and Korean--often referred to collectively as CJK. Charsets used to display these languages include Big5 (Chinese), Shift_JIS ( Japanese), and EUC-KR (Korean). A table listing languages and their corresponding charsets can be found in Appendix E, "Charsets".
What this boils down to is that if you (as the browser again) know the charset in which the response was encoded, you can determine how to interpret the bytes you receive. Just one question remains: how can you determine the charset? You can do it in one of two ways. First, you can require your user to tell you the charset. With Netscape Navigator 3, this is done through Options | Document Encoding; with Netscape Navigator 4, it is done through View | Encoding. With Microsoft Internet Explorer 4, it's done through View | Fonts. This approach often requires the user to try a few charsets until the display makes sense. The second possibility is that the server (or servlet) specifies the charset in the Content-Type header you receive. For example, the following Content-Type value:
text/html; charset=Shift_JIS
indicates that the charset is Shift_JIS. Unfortunately, a few older browsers can be confused by the inclusion of a charset in the Content-Type header.
12.3.2. Writing Encoded Output
Now that we understand charsets from the perspective of the browser, it's time to return to the perspective of the servlet. A servlet's role is to do the following:
-
Choose a charset and set it for the servlet
-
Get a PrintWriter for that charset
-
Output characters that can be displayed using that charset
Example 12-5 demonstrates with a servlet that says "Hello World" and displays the current date and time in Japanese. A screen shot is shown in Figure 12-4.
Example 12-5. Hello to Japanese speakers
import java.io.*;
import java.text.*;
import java.util.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class HelloJapan extends HttpServlet {
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException {
res.setContentType("text/plain; charset=Shift_JIS");
PrintWriter out = res.getWriter();
res.setHeader("Content-Language", "ja");
Locale locale = new Locale("ja", "");
DateFormat full = DateFormat.getDateTimeInstance(DateFormat.LONG,
DateFormat.LONG,
locale);
out.println("In Japanese:");
out.println("\u4eca\u65e5\u306f\u4e16\u754c"); // Hello World
out.println(full.format(new Date()));
}
}
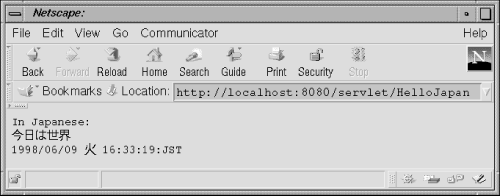
Figure 12-4. A Japanese Hello
This servlet starts by setting the content type to "text/plain" and the charset to "Shift_JIS". Then it calls res.getWriter() just like always--except in this case the PrintWriter it receives is special. This PrintWriter encodes all the servlet's output in the Shift_JIS charset because that charset is specified in the Content-Type header. This second line is therefore equivalent to the following:
PrintWriter out = new PrintWriter( new OutputStreamWriter(res.getOutputStream(), "Shift_JIS"), true);
Note that the call to res.getWriter() may throw an UnsupportedEncodingException if the charset is not recognized by Java[4] or an IllegalStateException if getOutputStream() has been called already on this request.
[4] With some early versions of Java, it may in some situations erroneously throw an IllegalArgumentException if the charset is not recognized.
The servlet next creates a Locale with the language "ja" to represent a generic Japanese environment and then creates a DateFormat to match. Finally, it prints the equivalent of "Hello World" in Japanese, using Unicode escapes for the characters, and outputs the current date and time.
For this servlet to work, your server's classpath must include the sun.io.CharToByte* converter classes or their equivalent. On some platforms, these are not always included by default. Also, for the Japanese glyphs (or glyphs from other languages) to display correctly in the browser, the browser has to support the charset and have access to the necessary fonts to display the charset.
For more information on the internationalization capabilities of Netscape Navigator, see http://home.netscape.com/eng/intl/index.html. For more information on the capabilities of Microsoft Internet Explorer, see http://www.microsoft.com/ie/intlhome.htm.
12.3.3. Reading and Writing Encoded Output
It can often be prohibitively slow to enter hundreds or thousands of Unicode escapes manually in Java source files. An easier option is to read localized text from an encoded file. For example, let's assume the "Hello World" Japanese text we want to output is saved by someone on the localization team in a file named HelloWorld.ISO-2022-JP, using the ISO-2022-JP encoding to make things more interesting. A servlet can read this file and send the content to the browser using the Shift_JIS encoding, as shown in Example 12-6.
Example 12-6. Sending localized output read from a file
import java.io.*;
import java.text.*;
import java.util.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class HelloJapanReader extends HttpServlet {
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException {
res.setContentType("text/plain; charset=Shift_JIS");
PrintWriter out = res.getWriter();
res.setHeader("Content-Language", "ja");
Locale locale = new Locale("ja", "");
DateFormat full = DateFormat.getDateTimeInstance(DateFormat.LONG,
DateFormat.LONG,
locale);
out.println("In Japanese:");
try {
FileInputStream fis =
new FileInputStream(req.getRealPath("/HelloWorld.ISO-2022-JP"));
InputStreamReader isr = new InputStreamReader(fis, "ISO-2022-JP");
BufferedReader reader = new BufferedReader(isr);
String line = null;
while ((line = reader.readLine()) != null) {
out.println(line);
}
}
catch (FileNotFoundException e) {
// No Hello for you
}
out.println(full.format(new Date()));
}
}
This servlet is essentially a character encoding converter. It reads the HelloWorld.ISO-2022-JP text encoded with ISO-2022-JP and internally converts it to Unicode. Then, it outputs the same text by converting from Unicode to Shift_JIS.
 |  |  |
| 12.2. Conforming to Local Customs |  | 12.4. Multiple Languages |

Copyright © 2001 O'Reilly & Associates. All rights reserved.