
Chapter 22. The java.text Package
The java.text package consists of classes and interfaces that are useful for writing internationalized programs that handle local customs, such as date and time formatting and string alphabetization, correctly. This package is new as of Java 1.1. Figure 22-1 shows its class hierarchy.
The NumberFormat class formats numbers, monetary quantities, and percentages as appropriate for the default or specified locale. DateFormat formats dates and times in a locale-specific way. The concrete DecimalFormat and SimpleDateFormat subclasses of these classes can be used for customized number, date, and time formatting. MessageFormat allows substitution of dynamic values, including formatted numbers and dates, into static message strings. ChoiceFormat formats a number using an enumerated set of string values. Collator compares strings according to the customary sorting order for a locale. BreakIterator scans text to find word, line, and sentence boundaries following locale-specific rules.
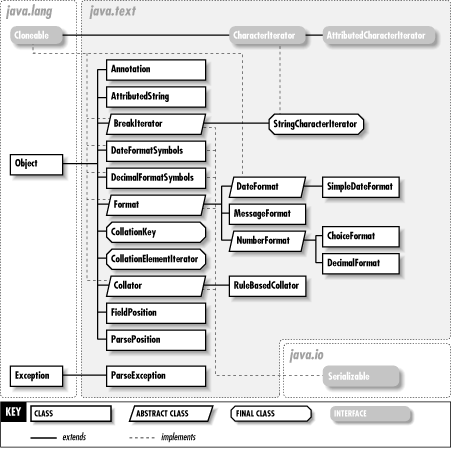
Figure 22-1. The java.text package
| Annotation | Java 1.2 | |
|
|
||
| java.text | ||
This class is a wrapper for a the value of a text attribute that represents an annotation. Annotations differ from other types of text attributes in two ways. First, annotations are linked to the text they are applied to, so changing the text invalidates or corrupts the meaning of the annotation. Second, annotations cannot be merged with adjacent annotations, even if they have the same value. Putting an annotation value in an Annotation wrapper serves to indicate these special characteristics. Note that two of the attribute keys defined by AttributedCharaterIterator.Attribute, READING and INPUT_METHOD_SEGMENT, must be used with Annotation objects.
| public class Annotation { | ||
| // | Public Constructors | |
| public Annotation (Object value); | ||
| // | Public Instance Methods | |
| public Object getValue (); | ||
| // | Public Methods Overriding Object | |
| public String toString (); | ||
| } | ||
| AttributedCharacterIterator | Java 1.2 | |
|
|
||
| java.text | cloneable | |
This interface extends CharacterIterator for working with text that is marked up with attributes in some way. It defines an inner class, AttributedCharaterIterator.Attribute, that represents attribute keys. AttributedCharacterIterator defines methods for querying the attribute keys, values, and runs for the text being iterated over. getAllAttributeKeys() returns the Set of all attribute keys that appear anywhere in the text. getAttributes() returns a Map that contains the attribute keys and values that apply to the current character. getAttribute() returns the value associated with the specified attribute key for the current character.
getRunStart() and getRunLimit() return the index of the first and last characters in a run. A run is a string of adjacent characters for which an attribute has the same value or is undefined (i.e., has a value of null). A run can also be defined for a set of attributes, in which case it is a set of adjacent characters for which all attributes in the set hold a constant value (which may include null). Programs that process or display attributed text must usually work with it one run at a time. The no-argument versions of getRunStart() and getRunLimit() return the start and end of the run that includes the current character and all attributes that are applied to the current character. The other versions of these methods return the start and end of the run of the specified attribute or set of attributes that includes the current character.
The AttributedString class provides a simple way to define short strings of attributed text and obtain an AttributedCharacterIterator over them. Most applications that process attributed text are working with attributed text from specialized data sources, stored in some specialized data format, so they need to define a custom implementation of AttributedCharacterIterator.
| public interface AttributedCharacterIterator extends CharacterIterator { | ||
| // | Inner Classes | |
| ; | ||
| // | Public Instance Methods | |
| public abstract java.util.Set getAllAttributeKeys (); | ||
| public abstract Object getAttribute (AttributedCharacterIterator.Attribute attribute); | ||
| public abstract java.util.Map getAttributes (); | ||
| public abstract int getRunLimit (); | ||
| public abstract int getRunLimit (java.util.Set attributes); | ||
| public abstract int getRunLimit (AttributedCharacterIterator.Attribute attribute); | ||
| public abstract int getRunStart (); | ||
| public abstract int getRunStart (AttributedCharacterIterator.Attribute attribute); | ||
| public abstract int getRunStart (java.util.Set attributes); | ||
| } | ||
Hierarchy: (AttributedCharacterIterator(CharacterIterator(Cloneable)))
Passed To: Too many methods to list.
Returned By: java.awt.event.InputMethodEvent.getText(), java.awt.im.InputMethodRequests.{cancelLatestCommittedText(), getCommittedText(), getSelectedText()}, AttributedString.getIterator()
| AttributedCharacterIterator.Attribute | Java 1.2 | |
|
|
||
| java.text | serializable | |
This class defines the types of the attribute keys used with AttributedCharacterIterator and AttributedString. It defines several constant Attribute keys that are commonly used with multilingual text and input methods. The LANGUAGE key represents the language of the underlying text. The value of this key should be a Locale object. The READING key represents arbitrary reading information associated with text. The value must be an Annotation object. The INPUT_METHOD_SEGMENT key serves to define text segments (usually words) that an input method operates on. The value of this attribute should be an Annotation object that contains null. Other classes may subclass this class and define other attribute keys that are useful in other circumstances or problem domains. See, for example, java.awt.font.TextAttribute in Java Foundation Classes in a Nutshell (O'Reilly).
| public static class AttributedCharacterIterator.Attribute implements Serializable { | ||
| // | Protected Constructors | |
| protected Attribute (String name); | ||
| // | Public Constants | |
| public static final AttributedCharacterIterator.Attribute INPUT_METHOD_SEGMENT ; | ||
| public static final AttributedCharacterIterator.Attribute LANGUAGE ; | ||
| public static final AttributedCharacterIterator.Attribute READING ; | ||
| // | Public Methods Overriding Object | |
| public final boolean equals (Object obj); | ||
| public final int hashCode (); | ||
| public String toString (); | ||
| // | Protected Instance Methods | |
| protected String getName (); | ||
| protected Object readResolve () throws java.io.InvalidObjectException; | ||
| } | ||
Subclasses: java.awt.font.TextAttribute
Passed To: java.awt.im.InputMethodRequests.{cancelLatestCommittedText(), getCommittedText(), getSelectedText()}, AttributedCharacterIterator.{getAttribute(), getRunLimit(), getRunStart()}, AttributedString.{addAttribute(), AttributedString(), getIterator()}
Returned By: java.awt.Font.getAvailableAttributes()
Type Of: AttributedCharacterIterator.Attribute.{INPUT_METHOD_SEGMENT, LANGUAGE, READING}
| AttributedString | Java 1.2 | |
|
|
||
| java.text | ||
This class represents text and associated attributes. An AttributedString can be defined in terms of an underlying AttributedCharacterIterator or an underlying String. Additional attributes can be specified with the addAttribute() and addAttributes() methods. getIterator() returns an AttributedCharacterIterator over the AttributedString or over a specified portion of the string. Note that two of the getIterator() methods take an array of Attribute keys as an argument. These methods return an AttributedCharacterIterator that ignores all attributes that are not in the specified array. If the array argument is null, however, the returned iterator contains all attributes.
| public class AttributedString { | ||
| // | Public Constructors | |
| public AttributedString (String text); | ||
| public AttributedString (AttributedCharacterIterator text); | ||
| public AttributedString (String text, java.util.Map attributes); | ||
| public AttributedString (AttributedCharacterIterator text, int beginIndex, int endIndex); | ||
| public AttributedString (AttributedCharacterIterator text, int beginIndex, int endIndex, AttributedCharacterIterator.Attribute[ ] attributes); | ||
| // | Public Instance Methods | |
| public void addAttribute (AttributedCharacterIterator.Attribute attribute, Object value); | ||
| public void addAttribute (AttributedCharacterIterator.Attribute attribute, Object value, int beginIndex, int endIndex); | ||
| public void addAttributes (java.util.Map attributes, int beginIndex, int endIndex); | ||
| public AttributedCharacterIterator getIterator (); | ||
| public AttributedCharacterIterator getIterator (AttributedCharacterIterator.Attribute[ ] attributes); | ||
| public AttributedCharacterIterator getIterator (AttributedCharacterIterator.Attribute[ ] attributes, int beginIndex, int endIndex); | ||
| } | ||
| BreakIterator | Java 1.1 | |
|
|
||
| java.text | cloneable PJ1.1 | |
This class determines character, word, sentence, and line breaks in a block of text in a way that is independent of locale and text encoding. As an abstract class, BreakIterator cannot be instantiated directly. Instead, you must use one of the class methods getCharacterInstance(), getWordInstance(), getSentenceInstance(), or getLineInstance() to return an instance of a nonabstract subclass of BreakIterator. These various factory methods return a BreakIterator object that is configured to locate the requested boundary types and is localized to work for the optionally specified locale.
Once you have obtained an appropriate BreakIterator object, use setText() to specify the text in which to locate boundaries. To locate boundaries in a Java String object, simply specify the string. To locate boundaries in text that uses some other encoding, you must specify a CharacterIterator object for that text so that the BreakIterator object can locate the individual characters of the text. Having set the text to be searched, you can determine the character positions of characters, words, sentences, or line breaks with the first(), last(), next(), previous(), current(), and following() methods, which perform the obvious functions. Note that these methods do not return text itself, but merely the position of the appropriate word, sentence, or line break.
| public abstract class BreakIterator implements Cloneable { | ||
| // | Protected Constructors | |
| protected BreakIterator (); | ||
| // | Public Constants | |
| public static final int DONE ; | =-1 | |
| // | Public Class Methods | |
| public static java.util.Locale[ ] getAvailableLocales (); | synchronized | |
| public static BreakIterator getCharacterInstance (); | ||
| public static BreakIterator getCharacterInstance (java.util.Locale where); | ||
| public static BreakIterator getLineInstance (); | ||
| public static BreakIterator getLineInstance (java.util.Locale where); | ||
| public static BreakIterator getSentenceInstance (); | ||
| public static BreakIterator getSentenceInstance (java.util.Locale where); | ||
| public static BreakIterator getWordInstance (); | ||
| public static BreakIterator getWordInstance (java.util.Locale where); | ||
| // | Public Instance Methods | |
| public abstract int current (); | ||
| public abstract int first (); | ||
| public abstract int following (int offset); | ||
| public abstract CharacterIterator getText (); | ||
| 1.2 | public boolean isBoundary (int offset); | |
| public abstract int last (); | ||
| public abstract int next (); | ||
| public abstract int next (int n); | ||
| 1.2 | public int preceding (int offset); | |
| public abstract int previous (); | ||
| public abstract void setText (CharacterIterator newText); | ||
| public void setText (String newText); | ||
| // | Public Methods Overriding Object | |
| public Object clone (); | ||
| } | ||
Hierarchy: Object-->BreakIterator(Cloneable)
Passed To: java.awt.font.LineBreakMeasurer.LineBreakMeasurer()
Returned By: BreakIterator.{getCharacterInstance(), getLineInstance(), getSentenceInstance(), getWordInstance()}
| CharacterIterator | Java 1.1 | |
|
|
||
| java.text | cloneable PJ1.1 | |
This interface defines an API for portably iterating through the characters that make up a string of text, regardless of the encoding of that text. Such an API is necessary because the number of bytes per character is different for different encodings, and some encodings even use variable-width characters within the same string of text. In addition to allowing iteration, a class that implements the CharacterIterator interface for non-Unicode text also performs translation of characters from their native encoding to standard Java Unicode characters.
CharacterIterator is similar to java.util.Enumeration, but is somewhat more complex than that interface. The first() and last() methods return the first and last characters in the text, and the next() and prev() methods allow you to loop forward or backwards through the characters of the text. These methods return the DONE constant when they go beyond the first or last character in the text; a test for this constant can be used to terminate a loop. The CharacterIterator interface also allows random access to the characters in a string of text. The getBeginIndex() and getEndIndex() methods return the character positions for the start and end of the string, and setIndex() sets the current position. getIndex() returns the index of the current position, and current() returns the character at that position.
| public interface CharacterIterator extends Cloneable { | ||
| // | Public Constants | |
| public static final char DONE ; | ='\uFFFF' | |
| // | Public Instance Methods | |
| public abstract Object clone (); | ||
| public abstract char current (); | ||
| public abstract char first (); | ||
| public abstract int getBeginIndex (); | ||
| public abstract int getEndIndex (); | ||
| public abstract int getIndex (); | ||
| public abstract char last (); | ||
| public abstract char next (); | ||
| public abstract char previous (); | ||
| public abstract char setIndex (int position); | ||
| } | ||
Hierarchy: (CharacterIterator(Cloneable))
Implementations: AttributedCharacterIterator, StringCharacterIterator, javax.swing.text.Segment
Passed To: java.awt.Font.{canDisplayUpTo(), createGlyphVector(), getLineMetrics(), getStringBounds()}, java.awt.FontMetrics.{getLineMetrics(), getStringBounds()}, BreakIterator.setText(), CollationElementIterator.setText(), RuleBasedCollator.getCollationElementIterator()
Returned By: BreakIterator.getText()
| ChoiceFormat | Java 1.1 | |
|
|
||
| java.text | cloneable serializable PJ1.1 | |
This class is a subclass of Format that converts a number to a String in a way reminiscent of a switch statement or an enumerated type. Each ChoiceFormat object has an array of doubles known as its limits and an array of strings known as its formats. When the format() method is called to format a number x, the ChoiceFormat finds an index i such that:
limits[i] <= x < limits[i+1]
If x is less than the first element of the array, the first element is used, and if it is greater than the last, the last element is used. Once the index i has been determined, it is used as the index into the array of strings, and the indexed string is returned as the result of the format() method.
A ChoiceFormat object may also be created by encoding its limits and formats into a single string known as its pattern. A typical pattern looks like the one below, used to return the singular or plural form of a word based on the numeric value passed to the format() method:
ChoiceFormat cf = new ChoiceFormat("0#errors|1#error|2#errors");
A ChoiceFormat object created in this way returns the string "errors" when it formats the number 0 or any number greater than or equal to 2. It returns "error" when it formats the number 1. In the syntax shown here, note the pound sign (#) used to separate the limit number from the string that corresponds to that case and the vertical bar (|) used to separate the individual cases. You can use the applyPattern() method to change the pattern used by a ChoiceFormat object; use toPattern() to query the pattern it uses.
| public class ChoiceFormat extends NumberFormat { | ||
| // | Public Constructors | |
| public ChoiceFormat (String newPattern); | ||
| public ChoiceFormat (double[ ] limits, String[ ] formats); | ||
| // | Public Class Methods | |
| public static final double nextDouble (double d); | ||
| public static double nextDouble (double d, boolean positive); | ||
| public static final double previousDouble (double d); | ||
| // | Public Instance Methods | |
| public void applyPattern (String newPattern); | ||
| public Object[ ] getFormats (); | ||
| public double[ ] getLimits (); | ||
| public void setChoices (double[ ] limits, String[ ] formats); | ||
| public String toPattern (); | ||
| // | Public Methods Overriding NumberFormat | |
| public Object clone (); | ||
| public boolean equals (Object obj); | ||
| public StringBuffer format (long number, StringBuffer toAppendTo, FieldPosition status); | ||
| public StringBuffer format (double number, StringBuffer toAppendTo, FieldPosition status); | ||
| public int hashCode (); | ||
| public Number parse (String text, ParsePosition status); | ||
| } | ||
Hierarchy: Object-->Format(Cloneable,Serializable)-->NumberFormat-->ChoiceFormat
| CollationElementIterator | Java 1.1 | |
|
|
||
| java.text | PJ1.1 | |
A CollationElementIterator object is returned by the getCollationElementIterator() method of the RuleBasedCollator object. The purpose of this class is to allow a program to iterate (with the next() method) through the characters of a string, returning ordering values for each of the collation keys in the string. Note that collation keys are not exactly the same as characters. In the traditional Spanish collation order, for example, the two-character sequence "ch" is treated as a single collation key that comes alphabetically between the letters "c" and "d". The value returned by the next() method is the collation order of the next collation key in the string. This numeric value can be directly compared to the value returned by next() for other CollationElementIterator objects. The value returned by next() can also be decomposed into primary, secondary, and tertiary ordering values with the static methods of this class. This class is used by RuleBasedCollator to implement its compare() method and to create CollationKey objects. Few applications ever need to use it directly.
| public final class CollationElementIterator { | ||
| // | No Constructor | |
| // | Public Constants | |
| public static final int NULLORDER ; | =-1 | |
| // | Public Class Methods | |
| public static final int primaryOrder (int order); | ||
| public static final short secondaryOrder (int order); | ||
| public static final short tertiaryOrder (int order); | ||
| // | Public Instance Methods | |
| 1.2 | public int getMaxExpansion (int order); | |
| public int getOffset (); | ||
| public int next (); | ||
| 1.2 | public int previous (); | |
| public void reset (); | ||
| public void setOffset (int newOffset); | ||
| 1.2 | public void setText (CharacterIterator source); | |
| public void setText (String source); | ||
| } | ||
Returned By: RuleBasedCollator.getCollationElementIterator()
| CollationKey | Java 1.1 | |
|
|
||
| java.text | comparable PJ1.1 | |
CollationKey objects compare strings more quickly than is possible with Collation.compare(). Objects of this class are returned by Collation.getCollationKey(). To compare two CollationKey objects, invoke the compareTo() method of key A, passing the key B as an argument (both CollationKey objects must be created through the same Collation object). The return value of this method is less than zero if the key A is collated before the key B, equal to zero if they are equivalent for the purposes of collation, or greater than zero if the key A is collated after the key B. Use getSourceString() to obtain the string represented by a CollationKey.
| public final class CollationKey implements Comparable { | ||
| // | No Constructor | |
| // | Public Instance Methods | |
| public int compareTo (CollationKey target); | ||
| public String getSourceString (); | ||
| public byte[ ] toByteArray (); | ||
| // | Methods Implementing Comparable | |
| 1.2 | public int compareTo (Object o); | |
| // | Public Methods Overriding Object | |
| public boolean equals (Object target); | ||
| public int hashCode (); | ||
| } | ||
Hierarchy: Object-->CollationKey(Comparable)
Passed To: CollationKey.compareTo()
Returned By: Collator.getCollationKey(), RuleBasedCollator.getCollationKey()
| Collator | Java 1.1 | |
|
|
||
| java.text | cloneable PJ1.1 | |
This class compares, orders, and sorts strings in a way appropriate for the default locale or some other specified locale. Because it is an abstract class, it cannot be instantiated directly. Instead, you must use the static getInstance() method to obtain an instance of a Collator subclass that is appropriate for the default or specified locale. You can use getAvailableLocales() to determine whether a Collator object is available for a desired locale.
Once an appropriate Collator object has been obtained, you can use the compare() method to compare strings. The possible return values of this method are -1, 0, and 1, which indicate, respectively, that the first string is collated before the second, that the two are equivalent for collation purposes, and that the first string is collated after the second. The equals() method is a convenient shortcut for testing two strings for collation equivalence.
When sorting an array of strings, each string in the array is typically compared more than once. Using the compare() method in this case is inefficient. A more efficient method for comparing strings multiple times is to use getCollationKey() for each string to create CollationKey objects. These objects can then be compared to each other more quickly than the strings themselves can be compared.
You can customize the way the Collator object performs comparisons by calling setStrength(). If you pass the constant PRIMARY to this method, the comparison looks only at primary differences in the strings; it compares letters but ignores accents and case differences. If you pass the constant SECONDARY, it ignores case differences but does not ignore accents. And if you pass TERTIARY (the default), the Collator object takes both accents and case differences into account in its comparison.
| public abstract class Collator implements Cloneablejava.util.Comparator { | ||
| // | Protected Constructors | |
| protected Collator (); | ||
| // | Public Constants | |
| public static final int CANONICAL_DECOMPOSITION ; | =1 | |
| public static final int FULL_DECOMPOSITION ; | =2 | |
| public static final int IDENTICAL ; | =3 | |
| public static final int NO_DECOMPOSITION ; | =0 | |
| public static final int PRIMARY ; | =0 | |
| public static final int SECONDARY ; | =1 | |
| public static final int TERTIARY ; | =2 | |
| // | Public Class Methods | |
| public static java.util.Locale[ ] getAvailableLocales (); | synchronized | |
| public static Collator getInstance (); | synchronized | |
| public static Collator getInstance (java.util.Locale desiredLocale); | synchronized | |
| // | Public Instance Methods | |
| public abstract int compare (String source, String target); | ||
| public boolean equals (String source, String target); | ||
| public abstract CollationKey getCollationKey (String source); | ||
| public int getDecomposition (); | synchronized | |
| public int getStrength (); | synchronized | |
| public void setDecomposition (int decompositionMode); | synchronized | |
| public void setStrength (int newStrength); | synchronized | |
| // | Methods Implementing Comparator | |
| 1.2 | public int compare (Object o1, Object o2); | |
| public boolean equals (Object that); | ||
| // | Public Methods Overriding Object | |
| public Object clone (); | ||
| public abstract int hashCode (); | ||
| } | ||
Hierarchy: Object-->Collator(Cloneable,java.util.Comparator)
Subclasses: RuleBasedCollator
Returned By: Collator.getInstance()
| DateFormat | Java 1.1 | |
|
|
||
| java.text | cloneable serializable PJ1.1 | |
This class formats and parses dates and times in a locale-specific way. As an abstract class, it cannot be instantiated directly, but it provides a number of static methods that return instances of a concrete subclass you can use to format dates in a variety of ways. The getDateInstance() methods return a DateFormat object suitable for formatting dates in either the default locale or a specified locale. A formatting style may also optionally be specified; the constants FULL, LONG, MEDIUM, SHORT, and DEFAULT specify this style. Similarly, the getTimeInstance() methods return a DateFormat object that formats and parses times, and the getDateTimeInstance() methods return a DateFormat object that formats both dates and times. These methods also optionally take a format style constant and a Locale. Finally, getInstance() returns a default DateFormat object that formats both dates and times in the SHORT format.
Once you have created a DateFormat object, you can use the setCalendar() and setTimeZone() methods if you want to format the date using a calendar or time zone other than the default. The various format() methods convert java.util.Date objects to strings using whatever format is encapsulated in the DateFormat object. The parse() and parseObject() methods perform the reverse operation; they parse a string formatted according to the rules of the DateFormat object and convert it into to a Date object. The DEFAULT, FULL, MEDIUM, LONG, and SHORT constants specify how verbose or compact the formatted date or time should be. The remaining constants, which all end with _FIELD, specify various fields of formatted dates and times and are used with the FieldPosition object that is optionally passed to format().
| public abstract class DateFormat extends Format { | ||
| // | Protected Constructors | |
| protected DateFormat (); | ||
| // | Public Constants | |
| public static final int AM_PM_FIELD ; | =14 | |
| public static final int DATE_FIELD ; | =3 | |
| public static final int DAY_OF_WEEK_FIELD ; | =9 | |
| public static final int DAY_OF_WEEK_IN_MONTH_FIELD ; | =11 | |
| public static final int DAY_OF_YEAR_FIELD ; | =10 | |
| public static final int DEFAULT ; | =2 | |
| public static final int ERA_FIELD ; | =0 | |
| public static final int FULL ; | =0 | |
| public static final int HOUR0_FIELD ; | =16 | |
| public static final int HOUR1_FIELD ; | =15 | |
| public static final int HOUR_OF_DAY0_FIELD ; | =5 | |
| public static final int HOUR_OF_DAY1_FIELD ; | =4 | |
| public static final int LONG ; | =1 | |
| public static final int MEDIUM ; | =2 | |
| public static final int MILLISECOND_FIELD ; | =8 | |
| public static final int MINUTE_FIELD ; | =6 | |
| public static final int MONTH_FIELD ; | =2 | |
| public static final int SECOND_FIELD ; | =7 | |
| public static final int SHORT ; | =3 | |
| public static final int TIMEZONE_FIELD ; | =17 | |
| public static final int WEEK_OF_MONTH_FIELD ; | =13 | |
| public static final int WEEK_OF_YEAR_FIELD ; | =12 | |
| public static final int YEAR_FIELD ; | =1 | |
| // | Public Class Methods | |
| public static java.util.Locale[ ] getAvailableLocales (); | ||
| public static final DateFormat getDateInstance (); | ||
| public static final DateFormat getDateInstance (int style); | ||
| public static final DateFormat getDateInstance (int style, java.util.Locale aLocale); | ||
| public static final DateFormat getDateTimeInstance (); | ||
| public static final DateFormat getDateTimeInstance (int dateStyle, int timeStyle); | ||
| public static final DateFormat getDateTimeInstance (int dateStyle, int timeStyle, java.util.Locale aLocale); | ||
| public static final DateFormat getInstance (); | ||
| public static final DateFormat getTimeInstance (); | ||
| public static final DateFormat getTimeInstance (int style); | ||
| public static final DateFormat getTimeInstance (int style, java.util.Locale aLocale); | ||
| // | Property Accessor Methods (by property name) | |
| public java.util.Calendar getCalendar (); | ||
| public void setCalendar (java.util.Calendar newCalendar); | ||
| public boolean isLenient (); | ||
| public void setLenient (boolean lenient); | ||
| public NumberFormat getNumberFormat (); | ||
| public void setNumberFormat (NumberFormat newNumberFormat); | ||
| public java.util.TimeZone getTimeZone (); | ||
| public void setTimeZone (java.util.TimeZone zone); | ||
| // | Public Instance Methods | |
| public final String format (java.util.Date date); | ||
| public abstract StringBuffer format (java.util.Date date, StringBuffer toAppendTo, FieldPosition fieldPosition); | ||
| public java.util.Date parse (String text) throws ParseException; | ||
| public abstract java.util.Date parse (String text, ParsePosition pos); | ||
| // | Public Methods Overriding Format | |
| public Object clone (); | ||
| public final StringBuffer format (Object obj, StringBuffer toAppendTo, FieldPosition fieldPosition); | ||
| public Object parseObject (String source, ParsePosition pos); | ||
| // | Public Methods Overriding Object | |
| public boolean equals (Object obj); | ||
| public int hashCode (); | ||
| // | Protected Instance Fields | |
| protected java.util.Calendar calendar ; | ||
| protected NumberFormat numberFormat ; | ||
| } | ||
Hierarchy: Object-->Format(Cloneable,Serializable)-->DateFormat
Subclasses: SimpleDateFormat
Returned By: DateFormat.{getDateInstance(), getDateTimeInstance(), getInstance(), getTimeInstance()}
| DateFormatSymbols | Java 1.1 | |
|
|
||
| java.text | cloneable serializable PJ1.1 | |
This class defines accessor methods for the various pieces of data, such as names of months and days, used by SimpleDateFormat to format and parse dates and times. You do not typically need to use this class unless you are formatting dates for an unsupported locale or in some highly customized way.
| public class DateFormatSymbols implements CloneableSerializable { | ||
| // | Public Constructors | |
| public DateFormatSymbols (); | ||
| public DateFormatSymbols (java.util.Locale locale); | ||
| // | Property Accessor Methods (by property name) | |
| public String[ ] getAmPmStrings (); | ||
| public void setAmPmStrings (String[ ] newAmpms); | ||
| public String[ ] getEras (); | ||
| public void setEras (String[ ] newEras); | ||
| public String getLocalPatternChars (); | ||
| public void setLocalPatternChars (String newLocalPatternChars); | ||
| public String[ ] getMonths (); | ||
| public void setMonths (String[ ] newMonths); | ||
| public String[ ] getShortMonths (); | ||
| public void setShortMonths (String[ ] newShortMonths); | ||
| public String[ ] getShortWeekdays (); | ||
| public void setShortWeekdays (String[ ] newShortWeekdays); | ||
| public String[ ] getWeekdays (); | ||
| public void setWeekdays (String[ ] newWeekdays); | ||
| public String[ ][ ] getZoneStrings (); | ||
| public void setZoneStrings (String[ ][ ] newZoneStrings); | ||
| // | Public Methods Overriding Object | |
| public Object clone (); | ||
| public boolean equals (Object obj); | ||
| public int hashCode (); | ||
| } | ||
Hierarchy: Object-->DateFormatSymbols(Cloneable,Serializable)
Passed To: SimpleDateFormat.{setDateFormatSymbols(), SimpleDateFormat()}
Returned By: SimpleDateFormat.getDateFormatSymbols()
| DecimalFormat | Java 1.1 | |
|
|
||
| java.text | cloneable serializable PJ1.1 | |
This is the concrete Format class used by NumberFormat for all locales that use base 10 numbers. Most applications do not need to use this class directly; they can use the static methods of NumberFormat to obtain a default NumberFormat object for a desired locale and then perform minor locale-independent customizations on that object.
Applications that require highly customized number formatting and parsing may create custom DecimalFormat objects by passing a suitable pattern to the DecimalFormat() constructor method. The applyPattern() method can change this pattern. A pattern consists of a string of characters from the table below. For example:
"$#,##0.00;($#,##0.00)"
| Character | Meaning |
|---|---|
| # | A digit; zeros show as absent |
| 0 | A digit; zeros show as 0 |
| . | The locale-specific decimal separator |
| , | The locale-specific grouping separator (comma) |
| - | The locale-specific negative prefix |
| % | Shows value as a percentage |
| ; |
Separates positive number format (on left) from optional negative number format (on right) |
| ' |
Quotes a reserved character, so it appears literally in the output (apostrophe) |
| other | Appears literally in output |
A DecimalFormatSymbols object can be specified optionally when creating a DecimalFormat object. If one is not specified, a DecimalFormatSymbols object suitable for the default locale is used.
| public class DecimalFormat extends NumberFormat { | ||
| // | Public Constructors | |
| public DecimalFormat (); | ||
| public DecimalFormat (String pattern); | ||
| public DecimalFormat (String pattern, DecimalFormatSymbols symbols); | ||
| // | Property Accessor Methods (by property name) | |
| public DecimalFormatSymbols getDecimalFormatSymbols (); | ||
| public void setDecimalFormatSymbols (DecimalFormatSymbols newSymbols); | ||
| public boolean isDecimalSeparatorAlwaysShown (); | default:false | |
| public void setDecimalSeparatorAlwaysShown (boolean newValue); | ||
| public int getGroupingSize (); | default:3 | |
| public void setGroupingSize (int newValue); | ||
| 1.2 | public void setMaximumFractionDigits (int newValue); | Overrides:NumberFormat |
| 1.2 | public void setMaximumIntegerDigits (int newValue); | Overrides:NumberFormat |
| 1.2 | public void setMinimumFractionDigits (int newValue); | Overrides:NumberFormat |
| 1.2 | public void setMinimumIntegerDigits (int newValue); | Overrides:NumberFormat |
| public int getMultiplier (); | default:1 | |
| public void setMultiplier (int newValue); | ||
| public String getNegativePrefix (); | default:"-" | |
| public void setNegativePrefix (String newValue); | ||
| public String getNegativeSuffix (); | default:"" | |
| public void setNegativeSuffix (String newValue); | ||
| public String getPositivePrefix (); | default:"" | |
| public void setPositivePrefix (String newValue); | ||
| public String getPositiveSuffix (); | default:"" | |
| public void setPositiveSuffix (String newValue); | ||
| // | Public Instance Methods | |
| public void applyLocalizedPattern (String pattern); | ||
| public void applyPattern (String pattern); | ||
| public String toLocalizedPattern (); | ||
| public String toPattern (); | ||
| // | Public Methods Overriding NumberFormat | |
| public Object clone (); | ||
| public boolean equals (Object obj); | ||
| public StringBuffer format (long number, StringBuffer result, FieldPosition fieldPosition); | ||
| public StringBuffer format (double number, StringBuffer result, FieldPosition fieldPosition); | ||
| public int hashCode (); | ||
| public Number parse (String text, ParsePosition parsePosition); | ||
| } | ||
Hierarchy: Object-->Format(Cloneable,Serializable)-->NumberFormat-->DecimalFormat
| DecimalFormatSymbols | Java 1.1 | |
|
|
||
| java.text | cloneable serializable PJ1.1 | |
This class defines the various characters and strings, such as the decimal point, percent sign, and thousands separator, used by DecimalFormat when formatting numbers. You do not typically use this class directly unless you are formatting dates for an unsupported locale or in some highly customized way.
| public final class DecimalFormatSymbols implements CloneableSerializable { | ||
| // | Public Constructors | |
| public DecimalFormatSymbols (); | ||
| public DecimalFormatSymbols (java.util.Locale locale); | ||
| // | Property Accessor Methods (by property name) | |
| public String getCurrencySymbol (); | default:"$" | |
| public void setCurrencySymbol (String currency); | ||
| public char getDecimalSeparator (); | default:. | |
| public void setDecimalSeparator (char decimalSeparator); | ||
| public char getDigit (); | default:# | |
| public void setDigit (char digit); | ||
| public char getGroupingSeparator (); | default:, | |
| public void setGroupingSeparator (char groupingSeparator); | ||
| public String getInfinity (); | default:"\u221E" | |
| public void setInfinity (String infinity); | ||
| public String getInternationalCurrencySymbol (); | default:"USD" | |
| public void setInternationalCurrencySymbol (String currency); | ||
| public char getMinusSign (); | default:- | |
| public void setMinusSign (char minusSign); | ||
| public char getMonetaryDecimalSeparator (); | default:. | |
| public void setMonetaryDecimalSeparator (char sep); | ||
| public String getNaN (); | default:"\uFFFD" | |
| public void setNaN (String NaN); | ||
| public char getPatternSeparator (); | default:; | |
| public void setPatternSeparator (char patternSeparator); | ||
| public char getPercent (); | default:% | |
| public void setPercent (char percent); | ||
| public char getPerMill (); | default:\u2030 | |
| public void setPerMill (char perMill); | ||
| public char getZeroDigit (); | default:0 | |
| public void setZeroDigit (char zeroDigit); | ||
| // | Public Methods Overriding Object | |
| public Object clone (); | ||
| public boolean equals (Object obj); | ||
| public int hashCode (); | ||
| } | ||
Hierarchy: Object-->DecimalFormatSymbols(Cloneable,Serializable)
Passed To: DecimalFormat.{DecimalFormat(), setDecimalFormatSymbols()}
Returned By: DecimalFormat.getDecimalFormatSymbols()
| FieldPosition | Java 1.1 | |
|
|
||
| java.text | PJ1.1 | |
FieldPosition objects are optionally passed to the format() methods of the Format class and its subclasses to return additional information about the formatting that has been performed. The getBeginIndex() and getEndIndex() methods of this class return the starting and ending character positions of some field of the formatted string. The integer value passed to the FieldPosition() constructor specifies what field of the returned string should have its bounds returned. The NumberFormat and DateFormat classes define various constants (which end with the string _FIELD) that can be used here. Typically, this bounds information is useful for aligning formatted strings in columns--for example, aligning the decimal points in a column of numbers.
| public class FieldPosition { | ||
| // | Public Constructors | |
| public FieldPosition (int field); | ||
| // | Public Instance Methods | |
| public int getBeginIndex (); | ||
| public int getEndIndex (); | ||
| public int getField (); | ||
| public void setBeginIndex (int bi); | ||
| public void setEndIndex (int ei); | ||
| // | Public Methods Overriding Object | |
| 1.2 | public boolean equals (Object obj); | |
| 1.2 | public int hashCode (); | |
| 1.2 | public String toString (); | |
| } | ||
Passed To: ChoiceFormat.format(), DateFormat.format(), DecimalFormat.format(), Format.format(), MessageFormat.format(), NumberFormat.format(), SimpleDateFormat.format()
| Format | Java 1.1 | |
|
|
||
| java.text | cloneable serializable PJ1.1 | |
This abstract class is the base class for all number, date, and string formatting classes in the java.text package. It defines two abstract methods that are implemented by subclasses. format() converts an object to a string using the formatting rules encapsulated by the Format subclass and optionally appends the resulting string to an existing StringBuffer. parseObject() performs the reverse operation; it parses a formatted string and returns the corresponding object. Status information for these two operations is returned in FieldPosition and ParsePosition objects. The nonabstract methods of this class are simple shortcuts that rely on implementations of the abstract methods. See ChoiceFormat, DateFormat, MessageFormat, and NumberFormat.
| public abstract class Format implements CloneableSerializable { | ||
| // | Public Constructors | |
| public Format (); | ||
| // | Public Instance Methods | |
| public final String format (Object obj); | ||
| public abstract StringBuffer format (Object obj, StringBuffer toAppendTo, FieldPosition pos); | ||
| public Object parseObject (String source) throws ParseException; | ||
| public abstract Object parseObject (String source, ParsePosition status); | ||
| // | Public Methods Overriding Object | |
| public Object clone (); | ||
| } | ||
Hierarchy: Object-->Format(Cloneable,Serializable)
Subclasses: DateFormat, MessageFormat, NumberFormat
Passed To: MessageFormat.{setFormat(), setFormats()}
Returned By: MessageFormat.getFormats()
| MessageFormat | Java 1.1 | |
|
|
||
| java.text | cloneable serializable PJ1.1 | |
This class formats and substitutes objects into specified positions in a message string (also known as the pattern string). It provides the closest Java equivalent to the printf() function of the C programming language. If a message is to be displayed only a single time, the simplest way to use the MessageFormat class is through the static format() method. This method is passed a message or pattern string and an array of argument objects to be formatted and substituted into the string. If the message is to be displayed several times, it makes more sense to create a MessageFormat object, supplying the pattern string, and then call the format() instance method of this object, supplying the array of objects to be formatted into the message.
The message or pattern string used by the MessageFormat contains digits enclosed in curly braces to indicate where each argument should be substituted. The sequence "{0}" indicates that the first object should be converted to a string (if necessary) and inserted at that point, while the sequence "{3}" indicates that the fourth object should be inserted. If the object to be inserted is not a string, MessageFormat checks to see if it is a Date or a subclass of Number. If so, it uses a default DateFormat or NumberFormat object to convert the value to a string. If not, it simply invokes the object's toString() method to convert it.
A digit within curly braces in a pattern string may be followed optionally by a comma, and one of the words "date", "time", "number", or "choice", to indicate that the corresponding argument should be formatted as a date, time, number, or choice before being substituted into the pattern string. Any of these keywords can additionally be followed by a comma and additional pattern information to be used in formatting the date, time, number, or choice. (See SimpleDateFormat, DecimalFormat, and ChoiceFormat for more information.)
You can use the setLocale() method to specify a nondefault Locale that the MessageFormat should use when obtaining DateFormat and NumberFormat objects to format dates, time, and numbers inserted into the pattern. You can change the Format object used at a particular position in the pattern with the setFormat() method. You can set a new pattern for the MessageFormat object by calling applyPattern(), and you can obtain a string that represents the current formatting pattern by calling toPattern(). MessageFormat also supports a parse() method that can parse an array of objects out of a specified string, according to the specified pattern.
| public class MessageFormat extends Format { | ||
| // | Public Constructors | |
| public MessageFormat (String pattern); | ||
| // | Public Class Methods | |
| public static String format (String pattern, Object[ ] arguments); | ||
| // | Public Instance Methods | |
| public void applyPattern (String newPattern); | ||
| public final StringBuffer format (Object[ ] source, StringBuffer result, FieldPosition ignore); | ||
| public Format[ ] getFormats (); | ||
| public java.util.Locale getLocale (); | ||
| public Object[ ] parse (String source) throws ParseException; | ||
| public Object[ ] parse (String source, ParsePosition status); | ||
| public void setFormat (int variable, Format newFormat); | ||
| public void setFormats (Format[ ] newFormats); | ||
| public void setLocale (java.util.Locale theLocale); | ||
| public String toPattern (); | ||
| // | Public Methods Overriding Format | |
| public Object clone (); | ||
| public final StringBuffer format (Object source, StringBuffer result, FieldPosition ignore); | ||
| public Object parseObject (String text, ParsePosition status); | ||
| // | Public Methods Overriding Object | |
| public boolean equals (Object obj); | ||
| public int hashCode (); | ||
| } | ||
Hierarchy: Object-->Format(Cloneable,Serializable)-->MessageFormat
| NumberFormat | Java 1.1 | |
|
|
||
| java.text | cloneable serializable PJ1.1 | |
This class formats and parses numbers in a locale-specific way. As an abstract class, it cannot be instantiated directly, but it provides a number of static methods that return instances of a concrete subclass you can use for formatting. The getInstance() method returns a NumberFormat object suitable for normal formatting of numbers in either the default locale or in a specified locale. getCurrencyInstance() and getPercentInstance() return NumberFormat objects for formatting numbers that represent monetary amounts and percentages, in either the default locale or in a specified locale. getAvailableLocales() returns an array of locales for which NumberFormat objects are available.
Once you have created a suitable NumberFormat object, you can customize its locale-independent behavior with setMaximumFractionDigits(), setGroupingUsed(), and similar set methods. In order to customize the locale-dependent behavior, you can use instanceof to test if the NumberFormat object is an instance of DecimalFormat, and, if so, cast it to that type. The DecimalFormat class provides complete control over number formatting. Note, however, that a NumberFormat customized in this way may no longer be appropriate for the desired locale.
After creating and customizing a NumberFormat object, you can use the various format() methods to convert numbers to strings or string buffers, and you can use the parse() or parseObject() methods to convert strings to numbers. The constants defined by this class are to be used by the FieldPosition object. The NumberFormat class in not intended for the display of very large or very small numbers that require exponential notation, and it may not gracefully handle infinite or NaN (not-a-number) values.
| public abstract class NumberFormat extends Format { | ||
| // | Public Constructors | |
| public NumberFormat (); | ||
| // | Public Constants | |
| public static final int FRACTION_FIELD ; | =1 | |
| public static final int INTEGER_FIELD ; | =0 | |
| // | Public Class Methods | |
| public static java.util.Locale[ ] getAvailableLocales (); | ||
| public static final NumberFormat getCurrencyInstance (); | ||
| public static NumberFormat getCurrencyInstance (java.util.Locale inLocale); | ||
| public static final NumberFormat getInstance (); | ||
| public static NumberFormat getInstance (java.util.Locale inLocale); | ||
| public static final NumberFormat getNumberInstance (); | ||
| public static NumberFormat getNumberInstance (java.util.Locale inLocale); | ||
| public static final NumberFormat getPercentInstance (); | ||
| public static NumberFormat getPercentInstance (java.util.Locale inLocale); | ||
| // | Property Accessor Methods (by property name) | |
| public boolean isGroupingUsed (); | ||
| public void setGroupingUsed (boolean newValue); | ||
| public int getMaximumFractionDigits (); | ||
| public void setMaximumFractionDigits (int newValue); | ||
| public int getMaximumIntegerDigits (); | ||
| public void setMaximumIntegerDigits (int newValue); | ||
| public int getMinimumFractionDigits (); | ||
| public void setMinimumFractionDigits (int newValue); | ||
| public int getMinimumIntegerDigits (); | ||
| public void setMinimumIntegerDigits (int newValue); | ||
| public boolean isParseIntegerOnly (); | ||
| public void setParseIntegerOnly (boolean value); | ||
| // | Public Instance Methods | |
| public final String format (long number); | ||
| public final String format (double number); | ||
| public abstract StringBuffer format (long number, StringBuffer toAppendTo, FieldPosition pos); | ||
| public abstract StringBuffer format (double number, StringBuffer toAppendTo, FieldPosition pos); | ||
| public Number parse (String text) throws ParseException; | ||
| public abstract Number parse (String text, ParsePosition parsePosition); | ||
| // | Public Methods Overriding Format | |
| public Object clone (); | ||
| public final StringBuffer format (Object number, StringBuffer toAppendTo, FieldPosition pos); | ||
| public final Object parseObject (String source, ParsePosition parsePosition); | ||
| // | Public Methods Overriding Object | |
| public boolean equals (Object obj); | ||
| public int hashCode (); | ||
| } | ||
Hierarchy: Object-->Format(Cloneable,Serializable)-->NumberFormat
Subclasses: ChoiceFormat, DecimalFormat
Passed To: DateFormat.setNumberFormat()
Returned By: DateFormat.getNumberFormat(), NumberFormat.{getCurrencyInstance(), getInstance(), getNumberInstance(), getPercentInstance()}
Type Of: DateFormat.numberFormat
| ParseException | Java 1.1 | |
|
|
||
| java.text | serializable checked PJ1.1 | |
Signals that a string has an incorrect format and cannot be parsed. It is typically thrown by the parse() or parseObject() methods of Format and its subclasses, but is also thrown by certain methods in the java.text package that are passed patterns or other rules in string form. The getErrorOffset() method of this class returns the character position at which the parsing error occurred in the offending string.
| public class ParseException extends Exception { | ||
| // | Public Constructors | |
| public ParseException (String s, int errorOffset); | ||
| // | Public Instance Methods | |
| public int getErrorOffset (); | ||
| } | ||
Hierarchy: Object-->Throwable(Serializable)-->Exception-->ParseException
Thrown By: DateFormat.parse(), Format.parseObject(), MessageFormat.parse(), NumberFormat.parse(), RuleBasedCollator.RuleBasedCollator()
| ParsePosition | Java 1.1 | |
|
|
||
| java.text | PJ1.1 | |
ParsePosition objects are passed to the parse() and parseObject() methods of Format and its subclasses. The ParsePosition class represents the position in a string at which parsing should begin or at which parsing stopped. Before calling a parse() method, you can specify the starting position of parsing by passing the desired index to the ParsePosition() constructor or by calling the setIndex() of an existing ParsePosition object. When parse() returns, you can determine where parsing ended by calling getIndex(). When parsing multiple objects or values from a string, a single ParsePosition object can be used sequentially.
| public class ParsePosition { | ||
| // | Public Constructors | |
| public ParsePosition (int index); | ||
| // | Public Instance Methods | |
| 1.2 | public int getErrorIndex (); | |
| public int getIndex (); | ||
| 1.2 | public void setErrorIndex (int ei); | |
| public void setIndex (int index); | ||
| // | Public Methods Overriding Object | |
| 1.2 | public boolean equals (Object obj); | |
| 1.2 | public int hashCode (); | |
| 1.2 | public String toString (); | |
| } | ||
Passed To: ChoiceFormat.parse(), DateFormat.{parse(), parseObject()}, DecimalFormat.parse(), Format.parseObject(), MessageFormat.{parse(), parseObject()}, NumberFormat.{parse(), parseObject()}, SimpleDateFormat.parse()
| RuleBasedCollator | Java 1.1 | |
|
|
||
| java.text | cloneable PJ1.1 | |
This class is a concrete subclass of the abstract Collator class. It performs collations using a table of rules that are specified in textual form. Most applications do not use this class directly; instead they call Collator.getInstance() to obtain a Collator object (typically a RuleBasedCollator object) that implements the default collation order for a specified or default locale. You should need to use this class only if you are collating strings for a locale that is not supported by default or if you need to implement a highly customized collation order.
| public class RuleBasedCollator extends Collator { | ||
| // | Public Constructors | |
| public RuleBasedCollator (String rules) throws ParseException; | ||
| // | Public Instance Methods | |
| 1.2 | public CollationElementIterator getCollationElementIterator (CharacterIterator source); | |
| public CollationElementIterator getCollationElementIterator (String source); | ||
| public String getRules (); | ||
| // | Public Methods Overriding Collator | |
| public Object clone (); | ||
| public int compare (String source, String target); | synchronized | |
| public boolean equals (Object obj); | ||
| public CollationKey getCollationKey (String source); | synchronized | |
| public int hashCode (); | ||
| } | ||
Hierarchy: Object-->Collator(Cloneable,java.util.Comparator)-->RuleBasedCollator
| SimpleDateFormat | Java 1.1 | |
|
|
||
| java.text | cloneable serializable PJ1.1 | |
This is the concrete Format subclass used by DateFormat to handle the formatting and parsing of dates. Most applications should not use this class directly; instead, they should obtain a localized DateFormat object by calling one of the static methods of DateFormat.
SimpleDateFormat formats dates and times according to a pattern, which specifies the positions of the various fields of the date, and a DateFormatSymbols object, which specifies important auxiliary data, such as the names of months. Applications that require highly customized date or time formatting can create a custom SimpleDateFormat object by specifying the desired pattern. This creates a SimpleDateFormat object that uses the DateFormatSymbols object for the default locale. You may also specify an locale explicitly, to use the DateFormatSymbols object for that locale. You can even provide an explicit DateFormatSymbols object of your own if you need to format dates and times for an unsupported locale.
You can use the applyPattern() method of a SimpleDateFormat to change the formatting pattern used by the object. The syntax of this pattern is described in the table below. Any characters in the format string that do not appear in this table appear literally in the formatted date.
| Field | Full Form | Short Form |
|---|---|---|
| Year | yyyy (4 digits) | yy (2 digits) |
| Month | MMM (name) | MM (2 digits), M (1 or 2 digits) |
| Day of week | EEEE | EE |
| Day of month | dd (2 digits) | d (1 or 2 digits) |
| Hour (1-12) | hh (2 digits) | h (1 or 2 digits) |
| Hour (0-23) | HH (2 digits) | H (1 or 2 digits) |
| Hour (0-11) | KK | K |
| Hour (1-24) | kk | k |
| Minute | mm | |
| Second | ss | |
| Millisecond | SSS | |
| AM/PM | a | |
| Time zone | zzzz | zz |
| Day of week in month | F (e.g., 3rd Thursday) | |
| Day in year | DDD (3 digits) | D (1, 2, or 3 digits) |
| Week in year | ww | |
| Era (e.g., BC/AD) | G |
| public class SimpleDateFormat extends DateFormat { | ||
| // | Public Constructors | |
| public SimpleDateFormat (); | ||
| public SimpleDateFormat (String pattern); | ||
| public SimpleDateFormat (String pattern, DateFormatSymbols formatData); | ||
| public SimpleDateFormat (String pattern, java.util.Locale loc); | ||
| // | Public Instance Methods | |
| public void applyLocalizedPattern (String pattern); | ||
| public void applyPattern (String pattern); | ||
| 1.2 | public java.util.Date get2DigitYearStart (); | |
| public DateFormatSymbols getDateFormatSymbols (); | ||
| 1.2 | public void set2DigitYearStart (java.util.Date startDate); | |
| public void setDateFormatSymbols (DateFormatSymbols newFormatSymbols); | ||
| public String toLocalizedPattern (); | ||
| public String toPattern (); | ||
| // | Public Methods Overriding DateFormat | |
| public Object clone (); | ||
| public boolean equals (Object obj); | ||
| public StringBuffer format (java.util.Date date, StringBuffer toAppendTo, FieldPosition pos); | ||
| public int hashCode (); | ||
| public java.util.Date parse (String text, ParsePosition pos); | ||
| } | ||
Hierarchy: Object-->Format(Cloneable,Serializable)-->DateFormat-->SimpleDateFormat
| StringCharacterIterator | Java 1.1 | |
|
|
||
| java.text | cloneable PJ1.1 | |
This class is a trivial implementation of the CharacterIterator interface that works for text stored in Java String objects. See CharacterIterator for details.
| public final class StringCharacterIterator implements CharacterIterator { | ||
| // | Public Constructors | |
| public StringCharacterIterator (String text); | ||
| public StringCharacterIterator (String text, int pos); | ||
| public StringCharacterIterator (String text, int begin, int end, int pos); | ||
| // | Public Instance Methods | |
| 1.2 | public void setText (String text); | |
| // | Methods Implementing CharacterIterator | |
| public Object clone (); | ||
| public char current (); | ||
| public char first (); | ||
| public int getBeginIndex (); | ||
| public int getEndIndex (); | ||
| public int getIndex (); | ||
| public char last (); | ||
| public char next (); | ||
| public char previous (); | ||
| public char setIndex (int p); | ||
| // | Public Methods Overriding Object | |
| public boolean equals (Object obj); | ||
| public int hashCode (); | ||
| } | ||
Hierarchy: Object-->StringCharacterIterator(CharacterIterator(Cloneable))
 |  |  |
| 21.1. The java.security.spec Package |  | 23. The java.util Package |

Copyright © 2001 O'Reilly & Associates. All rights reserved.