
1.4. Enterprise Computing Scenarios
The previous sections have been rapid-fire introductions to the Java Enterprise APIs. Don't worry if you didn't understand all the information presented there: the rest of the chapters in this Part cover the APIs in more detail. The important message you should take from this chapter is that the Java Enterprise APIs are building blocks that work together to enable you to write distributed Java applications for enterprise computing. The network infrastructure of every enterprise is unique, and the Java Enterprise APIs can be combined in any number of ways to meet the specific needs and goals of a particular enterprise.
Figure 1-1 shows a network schematic for a hypothetical enterprise. It illustrates some of the many possible interconnections among network services and shows the Java Enterprise APIs that facilitate those interconnections. The figure is followed by example scenarios that demonstrate how the Java Enterprise APIs might be used to solve typical enterprise computing problems. You may find it useful to refer to Figure 1-1 while reading through the scenarios, but note that the figure does not illustrate the specific scenarios presented here.
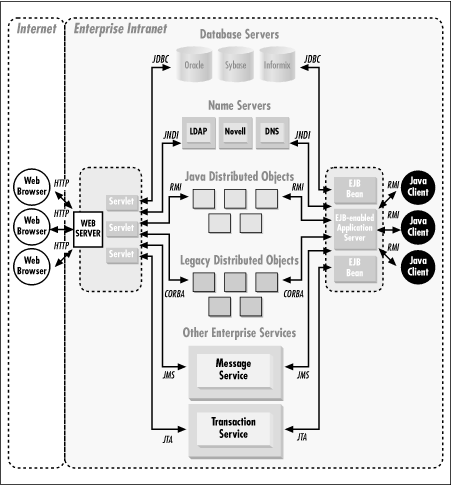
Figure 1-1. The distributed computing architecture of a hypothetical enterprise
1.4.1. Enabling E-Commerce for a Mail-Order Enterprise
CornCo Inc. runs a successful catalog-based mail-order business selling fresh flavored popcorn. They want to expand into the exciting world of electronic commerce over the Internet. Here's how they might do it:[2]
[2]This example is intended to illustrate only how the Java Enterprise APIs can be used together. I have ignored efficiency considerations, so the resulting design might not actually be practical for a large-scale e-commerce web site.
-
A customer visits the company's web site, www.cornco.com, and uses a web browser to interact with the company's web server. This allows the customer to view the company's products and make selections to purchase.
-
The web server uses a shopping-cart servlet to keep track of the products the customer has chosen to buy. The HTTP protocol is itself stateless, but servlets can persist between client requests, so this shopping-cart servlet can remember the customer's selections even while the customer continues to browse the web site.
-
When the customer is done browsing and is ready to purchase the selected products, the web server invokes a different checkout servlet. This servlet performs a number of important tasks, using several Enterprise APIs.
-
The checkout servlet uses JDBC to retrieve the list of products to be purchased (stored in a database by the shopping-cart servlet).
-
Next, the servlet queries the customer for a shipping address, a billing address, and other required information, and then uses JDBC again to store this information in a customer database. This database can be used, for example, by the CornCo marketing department for direct mail purposes.
-
The servlet then sends the customer's billing address and total purchase price to the billing server. This server is a legacy application, specific to CornCo, that has a nonstandard interface. Fortunately, however, the billing server exports itself as a CORBA object, so the servlet can treat the entire server as a CORBA remote object and invoke the necessary methods on it.
-
In order to ensure the very freshest product, CornCo maintains warehouses throughout the world. CornCo is a growing company, so the list of warehouses is frequently updated. The checkout servlet uses JNDI to contact a directory server and then uses the directory server to find a warehouse that is close to the customer and has the customer's requested products in stock.
-
Having located a warehouse that can fulfill the customer's order, the checkout servlet uses JMS to contact the company's enterprise messaging service. It uses this service to send the customer's order to the selected warehouse in the form of a message. This message is delivered to and queued up on the local computer at the warehouse.
1.4.2. Updating CornCo with Enterprise JavaBeans
You may have noticed a flaw in the previous scenario. The checkout servlet sends billing information to one server, and then sends fulfillment information to another server. But it performs these two actions independently, without any attempt to maintain transactional integrity and make them behave atomically. In other words, if a network failure or server crash were to occur after the billing information had been sent, but before the fulfillment information had been sent, the customer might receive a bill for popcorn that was never shipped.
The designers of the e-commerce system described in the previous section were aware of this problem, but since distributed transactions are complex, and CornCo did not own a transaction management server, they simply chose to ignore it. In practice, the number of customers who would have problems would be small, and it was easier for the original programmers to let the customer service department sort out any irregularities.
But now, CornCo has hired a new Vice President of Information Systems. She's tough as nails, and likes all her i's dotted and her t's crossed. She won't stand for this sloppy state of affairs. As her first official act as VP, she buys a high-end application server with Enterprise JavaBeans support and gives her e-commerce team the job of revamping the online ordering system to use it. The modified design might work like this:
-
The customer interacts with the web server and the shopping-cart servlet in the same way as before.
-
The checkout servlet is totally rewritten. Now it is merely a frontend for an Enterprise JavaBeans component that handles the interactions with the ordering and fulfillment servers and with the marketing database. The servlet uses JNDI to look up the enterprise bean, and then uses RMI to invoke methods on the bean (recall that all enterprise beans are RMI remote objects).
-
The major functionality of the checkout servlet is moved to a new checkout bean. The bean stores customer data in the marketing database using JDBC, sends billing information to the billing server using CORBA, looks up a warehouse using JNDI, and sends shipping information to the warehouse using JMS. The bean does not explicitly coordinate all these activities into a distributed transaction, however. Instead, when the bean is deployed within the EJB server, the system administrator configures the bean so that the server automatically wraps a distributed transaction around all of its actions. That is, when the checkout() method of the bean is called, it always behaves as an atomic operation.
-
In order for this automatic distributed transaction management to work, another change is required in the conversion from checkout servlet to checkout bean. The checkout servlet managed all its own connections to other enterprise services, but enterprise beans do not typically do this. Instead, they rely on their server for connection management. Thus, when the checkout bean wants to connect to the marketing database or the enterprise messaging system, for example, it asks the EJB server to establish that connection for it. The server doesn't need to know what the bean does with the connection, but it does need to manage the connection, if it is to perform transaction management on the connection.
 |  |  |
| 1.3. The Java Enterprise APIs |  | 1.5. Java Enterprise APIs Versus Jini |

Copyright © 2001 O'Reilly & Associates. All rights reserved.