
3.2. Primary Services
There are many value-added services available for distributed applications. The OMG (the CORBA governing body), for example, has defined 13 of these services for use in CORBA-compliant ORBs. This book looks at six value-added services that are called the primary services, because they are required to create an effective CTM. The primary services include concurrency, transactions, persistence, distributed objects, naming, and security.
The six primary services are not new concepts; the OMG defined interfaces for a most of them in CORBA some time ago. In most traditional CORBA ORBs, services are add-on subsystems that are explicitly utilized by the application code. This means that the server-side component developer has to write code to use primary service APIs right alongside their business logic. The use of primary services becomes complicated when they are used in combination with resource management techniques because the primary services are themselves complex. Using them in combination only compounds the problem.
As more complex component interactions are discovered, coordinating these services becomes a difficult task, requiring system-level expertise unrelated to the task of writing the application's business logic. Application developers can become so mired in the system-level concerns of coordinating various primary services and resource management mechanisms that their main responsibility, modeling the business, is all but forgotten.
EJB servers automatically manage all the primary services. This relieves the application developers from the task of mastering these complicated services. Instead, developers can focus on defining the business logic that describes the system, and leave the system-level concerns to the CTM. The following sections describe each of the primary services and explain how they are supported by EJB.
3.2.1. Concurrency
Session beans do not support concurrent access. This makes sense if you consider the nature of both stateful and stateless session beans. A stateful bean is an extension of one client and only serves that client. It doesn't make sense to make stateful beans concurrent if they are only used by the client that created them. Stateless session beans don't need to be concurrent because they don't maintain state that needs to be shared. The scope of the operations performed by a stateless bean is limited to the scope of each method invocation. No conversational state is maintained.
Entity beans represent data in the database that is shared and needs to be accessed concurrently. Entity beans are shared components. In Titan's EJB system, for example, there are only three ships: Paradise, Utopia, and Valhalla. At any given moment the Ship entity bean that represents the Utopia might be accessed by hundreds of clients. To make concurrent access to entity beans possible, EJB needs to protect the data represented by the shared bean, while allowing many clients to access the bean simultaneously.
In a distributed object system, problems arise when you attempt to share distributed objects among clients. If two clients are both using the same EJB object, how do you keep one client from writing over the changes of the other? If, for example, one client reads the state of an instance just before a different client makes a change to the same instance, the data that the first client read becomes invalid. Figure 3-5 shows two clients sharing the same EJB object.
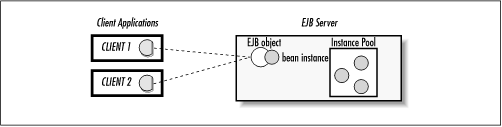
Figure 3-5. Clients sharing access to an EJB object
EJB has addressed the dangers associated with concurrency by implementing a simple solution: EJB, by default, prohibits concurrent access to bean instances. In other words, several clients can be connected to one EJB object, but only one client thread can access the bean instance at a time. If, for example, one of the clients invokes a method on the EJB object, no other client can access that bean instance until the method invocation is complete. In fact, if the method is part of a larger transaction, then the bean instance cannot be accessed at all, except within the same transactional context, until the entire transaction is complete.
Since EJB servers handle concurrency automatically, a bean's methods do not have to be made thread-safe. In fact, the EJB specification prohibits use of the synchronized keyword. Prohibiting the use of the thread synchronization primitives prevents developers from thinking that they control synchronization and enhances the performance of bean instances at runtime. In addition, EJB explicitly prohibits beans from creating their own threads. In other words, as a bean developer you cannot create a thread within a bean. The EJB container has to maintain complete control over the bean to properly manage concurrency, transactions, and persistence. Allowing the bean developer to create arbitrary threads would compromise the container's ability to track what the bean is doing, and thus would make it impossible for the container to manage the primary services.
3.2.1.1. Reentrance
When talking about concurrency, we need to discuss the related concept of reentrance. Reentrance is when a thread of control attempts to reenter a bean instance. In EJB, bean instances are nonreentrant by default, which means that loopbacks are not allowed. Before I explain what a loopback is, it is important that you understand a very fundamental concept in EJB: enterprise beans interact using each other's remote references and do not interact directly. In other words, when bean A operates on bean B, it does so the same way an application client would, by using B's remote interface as implemented by an EJB object. This rule enforces complete location transparency. Because interactions with beans always take place using remote references, beans can be relocated--possibly to a different server--with little or no impact on the rest of the application.
Figure 3-6 shows that, from a bean's point of view, only clients perform business method invocations. When a bean instance has a business method invoked, it cannot tell the difference between an application client and a bean client.
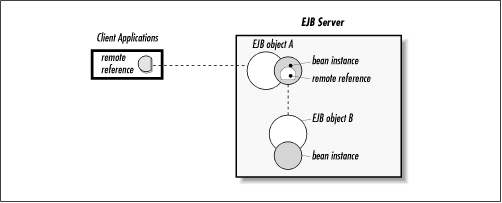
Figure 3-6. Beans access each other through EJB objects
A loopback occurs when bean A invokes a method on bean B that then attempts to make a call back to bean A. Figure 3-7 shows this type of interaction. In Figure 3-7, client 1 invokes a method on bean A. In response to the method invocation, bean A invokes a method on bean B. At this point, there is no problem because client 1 controls access to bean A and bean A is the client of bean B. If, however, bean B attempts to call a method on bean A, it would be blocked because the thread has already entered bean A. By calling its caller, bean B is performing a loopback. This is illegal by default because EJB doesn't allow a thread of control to reenter a bean instance. To say that beans are nonreentrant by default is to say that loopbacks are not allowed.
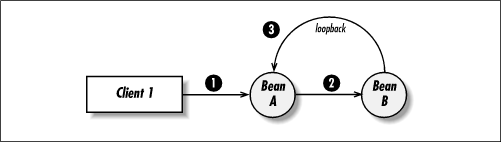
Figure 3-7. A loopback scenario
The nonreentrance policy is applied differently to session beans and entity beans. Session beans can never be reentrant, and they throw a RemoteException if a loopback is attempted. The same is true of a nonreentrant entity bean. Entity beans can be configured in the deployment descriptor to allow reentrance at deployment time. Making an entity bean reentrant, however, is discouraged by the specification.
As discussed previously, client access to a bean is synchronized so that only one client can access any given bean at one time. Reentrance addresses a thread of control--initiated by a client request--that attempts to reaccess a bean instance. The problem with reentrant code is that the EJB object--which intercepts and delegates method invocations on the bean instance--cannot differentiate between reentrant code and multithreaded access from the same client with the same transactional context. (More about transactional context in Chapter 8, "Transactions".) If you permit reentrance, you also permit multithreaded access to the bean instance. Multithreaded access to a bean instance can result in corrupted data because threads impact each other's work trying to accomplish their separate tasks.
It's important to remember that reentrant code is different from a bean instance that simply invokes its own methods at an instance level. In other words, method foo() on a bean instance can invoke its own public, protected, default, or private methods directly as much as it wants. Here is an example of intra-instance method invocation that is perfectly legal:
public HypotheticalBean extends EntityBean {
public int x;
public double foo() {
int i = this.getX();
return this.boo(i);
}
public int getX() {
return x;
}
private double boo(int i) {
double value = i * Math.PI;
return value;
}
}
In the previous code fragment, the business method, foo(), invokes another business method, getX(), and then a private method, boo(). The method invocations made within the body of foo() are intra-instance invocations and are not considered reentrant.
3.2.2. Transactions
Component transaction monitors (CTMs) were developed to bring the robust, scalable transactional integrity of traditional TP monitors to the dynamic world of distributed objects. Enterprise JavaBeans, as a server-side component model for CTMs, provides robust support for transactions.
A transaction is a unit-of-work or a set of tasks that are executed together. Transactions are atomic; in other words, all the tasks in a transaction must be completed together to consider the transaction a success. In the previous chapter we used the TravelAgent bean to describe how a session bean controls the interactions of other beans. Here is a code snippet showing the bookPassage() method described in Chapter 2, "Architectural Overview":
public Ticket bookPassage(CreditCard card, double price)
throws IncompleteConversationalState { // EJB 1.0: also throws RemoteException
if (customer == null || cruise == null || cabin == null) {
throw new IncompleteConversationalState();
}
try {
ReservationHome resHome = (ReservationHome)
getHome("ReservationHome",ReservationHome.class);
Reservation reservation =
resHome.create(customer, cruise, cabin, price);
ProcessPaymentHome ppHome = (ProcessPaymentHome)
getHome("ProcessPaymentHome",ProcessPaymentHome.class);
ProcessPayment process = ppHome.create();
process.byCredit(customer, card, price);
Ticket ticket = new Ticket(customer, cruise, cabin, price);
return ticket;
} catch(Exception e) {
// EJB 1.0: throw new RemoteException("",e);
throw new EJBException(e);
}
}
The bookPassage() method consists of two tasks that must be completed together: the creation of a new Reservation bean and processing of the payment. When the TravelAgent bean is used to book a passenger, the charges to the passenger's credit card and the creation of the reservation must both be successful. It would be inappropriate for the ProcessPayment bean to charge the customer's credit card if the creation of a new Reservation bean fails. Likewise, you can't make a reservation if the customer credit card is not charged. An EJB server monitors the transaction to ensure that all the tasks are completed successfully.
Transactions are managed automatically, so as a bean developer you don't need to use any APIs to explicitly manage a bean's involvement in a transaction. Simply declaring the transactional attribute at deployment time tells the EJB server how to manage the bean at runtime. EJB does provide a mechanism that allows beans to manage transactions explicitly, if necessary. Setting the transactional attributes during deployment is discussed in Chapter 8, "Transactions", as is explicit management of transactions and other transactional topics.
3.2.3. Persistence
Entity beans represent the behavior and data associated with real-world people, places, or things. Unlike session type beans, entity beans are persistent. That means that the state of an entity is stored permanently in a database. This allows entities to be durable so that both their behavior and data can be accessed at any time without concern that the information will be lost because of a system failure.
When a bean's state is automatically managed by a persistence service, the container is responsible for synchronizing an entity bean's instance fields with the data in the database. This automatic persistence is called container-managed persistence. When beans are designed to manage their own state, as is often the case when dealing with legacy systems, it is called bean-managed persistence.
Each vendor gets to choose the exact mechanism for implementing container-managed persistence, but the vendor's implementation must support the EJB callback methods and transactions. The most common mechanisms used in persistence by EJB vendors are object-to-relational persistence and object database persistence.
3.2.3.1. Object-to-relational persistence
Object-to-relational persistence is perhaps the most common persistence mechanism used in distributed object systems today. Object-to-relational persistence involves mapping entity bean fields to relational database tables and columns. An entity bean's fields represent its state. In Titan's system, for example, the CabinBean models the business concept of a ship's cabin. The following code shows an abbreviated definition of the CabinBean:
public class CabinBean implements javax.ejb.EntityBean {
public int id;
public String name;
public int deckLevel;
// Business and component-level methods follow.
}
With object-to-relational database mapping, the variable fields of an entity bean correspond to columns in a relational database. The Cabin's name, for example, maps to the column labeled NAME in a table called CABIN in Titan's relational database. Figure 3-8 shows a graphical depiction of this type of mapping.
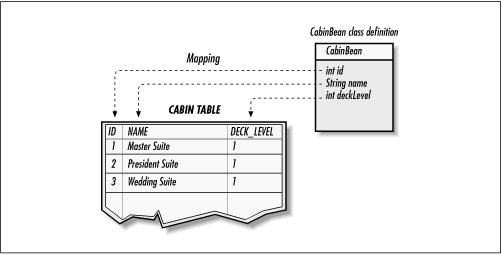
Figure 3-8. Object-to-relational mapping of entity beans
Really good EJB systems provide wizards or administrative interfaces for mapping relational database tables to the fields of entity bean classes. Using these wizards, mapping entities to tables is a fairly straightforward process and is usually performed at deployment time. Figure 3-9 shows WebLogic's object-to-relational mapping wizard.
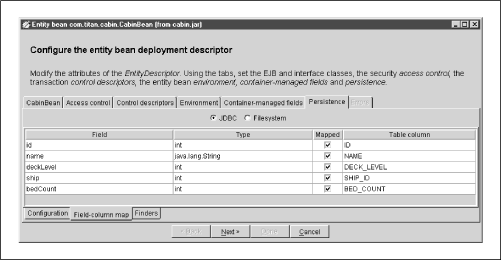
Figure 3-9. Object-to-relational mapping wizard
Once a bean's fields are mapped to the relational database, the container takes over the responsibility of keeping the state of an entity bean instance consistent with the corresponding tables in the database. This process is called synchronizingthe state of the bean instance. In the case of CabinBean, bean instances at runtime will map one-to-one to rows in the CABIN table of the relational database. When a change is made to a Cabin bean, it is written to the appropriate row in the database. Frequently, bean types will map to more than one table. These are more complicated mappings, often requiring an SQL join. Good EJB deployment tools should provide wizards that make multitable mappings fairly easy.
In addition to synchronizing the state of an entity, EJB provides mechanisms for creating and removing entities. Calls to the EJB home to create and remove entities will result in a corresponding insertion or deletion of records in the database. Because entities store their state in database tables, new records (and therefore bean identities) can be added to tables from outside the EJB system. In other words, inserting a record into the CABIN table--whether done by EJB or by direct access to the database--creates a new Cabin entity. It's not created in the sense of instantiating a Java object, but in the sense that the data that describes a Cabin entity has been added to the system.
Object-to-relational persistence can become very complex because objects don't always map cleanly to a relational database. Although you can specify any Java serializable type as a container-managed field, Java objects don't always map seamlessly to a relational database. You frequently need to convert Java types to some nonobject type just prior to synchronization so that the data can be stored in a relational database. Techniques for handling these types of problems are described in more detail in Chapter 9, "Design Strategies".
NOTE
EJB 1.1 allows the container-managed fields to include remote references to EJB objects (remote interface types) and EJB homes (home interface types). EJB 1.0 allows only Java primitives and serializable types as container-managed fields. While the ability to store an EJB reference in a container-managed field makes it much easier to model relationships between entity beans, it has made persistence more complicated for vendors. In EJB 1.1, the container must convert any container-managed field that holds a remote or home interface reference into a serializable primary key or handle. We'll learn more about container-managed fields in Chapter 6, "Entity Beans".
There are many other impedance mismatches when mapping object-to-relational databases, and some EJB vendor implementations deal with them better than others. Relational databases, however, are still a very good persistence store because they are stable and well-understood. There is no shortage of developers who understand them or products that support them. In addition, the large number of SQL-standard relational databases makes it fairly easy to migrate from one database to another.
3.2.3.2. Object database persistence
Object-oriented databases are designed to preserve object types and object graphs and therefore are a much better match for components written in an object-oriented language like Java. They offer a cleaner mapping between entity beans and the database than a traditional relational database. Serializable objects can be preserved without the mismatch associated with object-to-relational persistence because the object's definition and state are simply saved as is to the database. Not only are the object's definition and state saved to the database, complex relationships such as circular references can also be maintained. Because object databases store the objects as objects, object databases are viewed by many developers as a superior database technology for object persistence.
While object databases perform well when it comes to very complex object graphs, they are still fairly new to business systems and are not as widely accepted as relational databases. As a result, they are not as standardized as relational databases, making it more difficult to migrate from one database to another. In addition, fewer third-party products exist that support object databases, like products for reporting and data warehousing.
Several relational databases support extended features for native object persistence. These databases allow some objects to be preserved in relational database tables like other data types and offer some advantages over other databases.
3.2.3.3. Legacy persistence
EJB is often used to put an object wrapper on legacy systems, systems that are based on mainframe applications or nonrelational databases. Container-managed persistence in such an environment requires a special EJB container designed specifically for legacy data access. Vendors might, for example, provide mapping tools that allow beans to be mapped to IMS, CICS, b-trieve, or some other legacy application.
Regardless of the type of legacy system used, container-managed persistence is preferable to bean-managed persistence. With container-managed persistence, the bean's state is managed automatically, which is more efficient at runtime and more productive during bean development. Many projects, however, require that beans obtain their state from legacy systems that are not supported by mapping tools. In these cases, developers must use bean-managed persistence, which means that the developer doesn't use the automatic persistence service of the EJB server. Chapter 6, "Entity Beans" describes both container-managed and bean-managed persistence in detail.
3.2.4. Distributed Objects
Three main distributed object services are available today: CORBA, Java RMI, and DCOM. Each of these services uses a different RMI network protocol, but they all accomplish basically the same thing: location transparency.DCOM is primarily used in the Microsoft Windows environment and is not well supported by other operating systems. Its tight integration with Microsoft products makes it a good choice for Microsoft-only systems. CORBA is neither operating-system specific nor language specific and is therefore the most open distributed object service of the three. It's an ideal choice when integrating systems developed in multiple programming languages. Java RMI is a Java language abstraction or programming model for any kind of distributed object protocol. In the same way that the JDBC API can be used to access any SQL relational database, Java RMI is intended to be used with almost any distributed object protocol. In practice, Java RMI has traditionally been limited to the Java Remote Method Protocol ( JRMP)--known as Java RMI over JRMP--which can only be used between Java applications. Recently an implementation of Java RMI over IIOP ( Java RMI-IIOP), the CORBA protocol, has been developed. Java RMI-IIOP is a CORBA-compliant version of Java RMI, which allows developers to leverage the simplicity of the Java RMI programming model, while taking advantage of the platform- and language-independent CORBA protocol, IIOP.[2]
[2]Java RMI-IIOP is interoperable with CORBA ORBs that support the CORBA 2.3 specification. ORBs that support an older specification cannot be used with Java RMI-IIOP because they do not implement the Object by Value portion of the 2.3 specification.
When we discuss the remote interface, home interface, and other EJB interfaces and classes used on the client, we are talking about the client's view of the EJB system. The EJB client view doesn't include the EJB objects, container, instance swapping, or any of the other implementation specifics. As far as the client is concerned, a bean is defined by its remote interface and home interface. Everything else is invisible. As long as the EJB server supports the EJB client view, any distributed object protocol can be used.
Regardless of the protocol used, the server must support Java clients using the Java EJB client API, which means that the protocol must map to the Java RMI for EJB 1.0 or Java RMI-IIOP for EJB 1.1. Using Java RMI over DCOM seems a little far-fetched, but it is possible. Chapter 3, "Resource Management and the Primary Services" illustrates the Java language EJB API supported by different distributed object protocols.
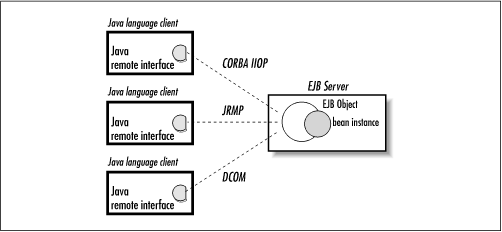
Figure 3-10. Java EJB client view supported by various protocols
EJB also allows servers to support access to beans by clients written in languages other than Java. An example of this is the EJB-to-CORBA mapping defined by Sun.[3] This document describes the CORBA IDL (Interface Definition Language) that can be used to access enterprise beans from CORBA clients. A CORBA client can be written in any language, including C++, Smalltalk, Ada, and even COBOL. The mapping also includes details about supporting the Java EJB client view as well as details on mapping the CORBA naming system to EJB servers and distributed transactions across CORBA objects and beans. Eventually, a EJB-to-DCOM mapping may be defined that will allow DCOM client applications written in languages like Visual Basic, Delphi, PowerBuilder, and others to access beans. Chapter 3, "Resource Management and the Primary Services" illustrates the possibilities for accessing an EJB server from different distributed object clients.
[3] Sun Microsystems' Enterprise JavaBeans™ to CORBA Mapping, Version 1.1, by Sanjeev Krishnan, Copyright 1999 by Sun Microsystems.
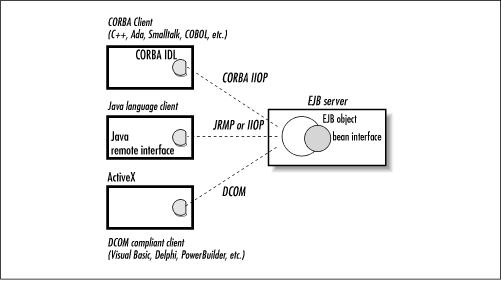
Figure 3-11. EJB accessed from different distributed clients
As a platform-independent and language-independent distributed object protocol, CORBA is often thought of as the superior of the three protocols discussed here. For all its advantages, however, CORBA suffers from some limitations. Pass-by-value, a feature easily supported by Java RMI-IIOP, was only recently introduced in the CORBA 2.3 specification and is not well supported. Another limitation of CORBA is with casting remote proxies. In Java RMI-JRMP, you can cast or widen a proxy's remote interface to a subtype or supertype of the interface, just like any other object. This is a powerful feature that allows remote objects to be polymorphic. In Java RMI-IIOP, you have to call a special narrowing method to change the interface of a proxy to a subtype, which is cumbersome.
However, JRMP is has its own limitations. While JRMP may be a more natural fit for Java-to-Java distributed object systems, it lacks inherent support for both security and transactional services--support that is a part of the CORBA IIOP specification. This limits the effectiveness of JRMP in heterogeneous environments where security and transactional contexts must be passed between systems.
3.2.5. Naming
All distributed object services use a naming service of some kind. Java RMI-JRMP and CORBA use their own naming services. All naming services do essentially the same thing regardless of how they are implemented: they provide clients with a mechanism for locating distributed objects.
To accomplish this, a naming service must provide two things: object binding and a lookup API. Object binding is the association of a distributed object with a natural language name or identifier. The CabinHome object, for example, might be bound to the name "cabin.Home" or "room." A binding is really a pointer or an index to a specific distributed object, which is necessary in an environment that manages hundreds of different distributed objects. A lookup API provides the client with an interface to the naming system. Simply put, lookup APIs allow clients to connect to a distributed service and request a remote reference to a specific object.
Enterprise JavaBeans mandates the use of the Java Naming and Directory Interface ( JNDI) as a lookup API on Java clients. JNDI supports just about any kind of naming and directory service. A directory service is a very advanced naming service that organizes distributed objects and other resources--printers, files, application servers, etc.--into hierarchical structures and provides more sophisticated management features. With directory services, metadata about distributed objects and other resources are also available to clients. The metadata provides attributes that describe the object or resource and can be used to perform searches. You can, for example, search for all the laser printers that support color printing in a particular building.
Directory services also allow resources to be linked virtually, which means that a resource can be located anywhere you choose in the directory services hierarchy. JNDI allows different types of directory services to be linked together so that a client can move between different types of services seamlessly. It's possible, for example, for a client to follow a directory link in a Novell NetWare directory into an EJB server, allowing the server to be integrated more tightly with other resources of the organization it serves.
There are many different kinds of directory and naming services; EJB vendors can choose the one that best meets their needs. All EJB servers, however, must provide JNDI access to their particular directory or naming service. EJB servers that support access to beans using non-Java clients must also support a naming system specific to the distributed object protocol used. The EJB-to-CORBA mapping, for example, specifies how EJB homes should be organized for CORBA Naming Service.
A Java client application would use JNDI to initiate a connection to an EJB server and to locate a specific EJB home. The following code shows how the JNDI API might be used to locate and obtain a reference to the EJB home CabinHome:
javax.naming.Context jndiContext =
new javax.naming.InitialContext(properties);
Object ref = jndiContext.lookup("cabin.Home");
// EJB 1.0: Use Java native cast instead of narrow()
CabinHome cabinHome = (CabinHome)
PortableRemoteObject.narrow(ref, CabinHome.class);
Cabin cabin = cabinHome.create(382, "Cabin 333",3);
cabin.setName("Cabin 444");
cabin.setDeckLevel(4);
The properties passed into the constructor of InitialContext tell the JNDI API where to find the EJB server and what JNDI service provider (driver) to load. The Context.lookup() method tells the JNDI service provider the name of the object to return from the EJB server. In this case, we are looking for the home interface to the Cabin bean. Once we have the Cabin bean's home interface, we can use it to create new cabins and access existing cabins.
NOTE
EJB 1.1 requires the use of the PortableRemoteObject.narrow() method to cast the remote reference obtained from JNDI into the CabinHome interface type. This is addressed in more detail in Chapter 4, "Developing Your First Enterprise Beans" and Chapter 5, "The Client View" and is not essential to the content covered here. EJB 1.0 uses native Java casting.
3.2.6. Security
Enterprise JavaBeans servers might support as many as three kinds of security: authentication, access control, and secure communication. Only access control is specifically addressed in the EJB 1.0 and EJB 1.1 specifications.
- Authentication
-
Simply put, authentication validates the identity of the user. The most common kind of authentication is a simple login screen that requires a username and a password. Once users have successfully passed through the authentication system, they are free to use the system. Authentication can also be based on secure ID cards, swipe cards, security certificates, and other forms of identification. While authentication is the primary safeguard against unauthorized access to a system, it is fairly crude because it doesn't police an authorized user's access to resources within the system.
- Access control
-
Access control (a.k.a. authorization) applies security policies that regulate what a specific user can and cannot do within a system. Access control ensures that users only access resources for which they have been given permission. Access control can police a user's access to subsystems, data, and business objects, or it can monitor more general behavior. Certain users, for example, may be allowed to update information while others are only allowed to view the data.
- Secure communication
-
Communication channels between a client and a server are frequently the focus of security concerns. A channel of communication can be secured by physical isolation (like a dedicated network connection) or by encrypting the communication between the client and the server. Physically securing communication is expensive, limiting, and pretty much impossible on the Internet, so we will focus on encryption. When communication is secured by encryption, the messages passed are encoded so that they cannot be read or manipulated by unauthorized individuals. This normally involves the exchange of cryptographic keys between the client and the server. The keys allow the receiver of the message to decode the message and read it.
Most EJB servers support secure communications--usually through SSL (secure socket layer)--and some mechanism for authentication, but EJB 1.0 and 1.1 only specify access control in their server-side component models. Authentication may be specified in subsequent versions, but secure communications will probably never be specified. Secure communications is really independent of the EJB specification and the distributed object protocol.
Although authentication is not specified in EJB, it is often accomplished using the JNDI API. In other words, a client using JNDI can provide authenticating information using the JNDI API to access a server or resources in the server. This information is frequently passed when the client attempts to initiate a JNDI connection to the EJB server. The following code shows how the client's password and username are added to the connection properties used to obtain a JNDI connection to the EJB server:
properties.put(Context.SECURITY_PRINCIPAL, userName );
properties.put(Context.SECURITY_CREDENTIALS, userPassword);
javax.naming.Context jndiContext =
new javax.naming.InitialContext(properties);
Object ref= jndiContext.lookup("titan.CabinHome");
// EJB 1.0: Use Java native cast instead of narrow()
CabinHome cabinHome = (CabinHome)
PortableRemoteObject.narrow(ref, CabinHome.class);
Enterprise JavaBeans 1.0 and 1.1 use slightly different models to control client access to beans and their methods. While EJB 1.0 access control is based on Identity objects with a method driven organization, EJB 1.1 changed authorization to be based on Principal types rather than Identity types and to be role-driven rather than method-driven.
EJB specifies that every client application accessing an EJB system must be associated with a security identity. The security identity represents the client as either a user or a role. A user might be a person, security credential, computer, or even a smart card. Normally, the user will be a person whose identity is assigned when he or she logs in. A role represents a grouping of identities and might be something like "manager," which is a group of user identities that are considered managers at a company.
When a client logs on to the EJB system, it is associated with a security identity for the duration of that session. The identity is found in a database or directory specific to the platform or EJB server. This database or directory is responsible for storing individual security identities and their memberships to groups.
Once a client application has been associated with an security identity, it is ready to use beans to accomplish some task. The EJB server keeps track of each client and its identity. When a client invokes a method on a home interface or a remote interface, the EJB server implicitly passes the client's identity with the method invocation. When the EJB object or EJB home receives the method invocation, it checks the identity to ensure that the client is allowed to invoke that method.
3.2.6.1. EJB 1.1: Role-driven access control
In EJB 1.1, the security identity is represented by a java.security.Principle object. As a security identity, the Principle acts as a representative for users, groups, organizations, smart cards, etc., to the EJB access control architecture. Deployment descriptors include tags that declare which logical roles are allowed to access which bean methods at runtime. The security roles are considered logical roles because they do not directly reflect users, groups, or any other security identities in a specific operational environment. Instead, security roles are mapped to real-world user groups and users when the bean is deployed. This allows a bean to be portable; every time the bean is deployed in a new system the roles can be mapped to the users and groups specific to that operational environment. Here is a portion of the Cabin bean's deployment descriptor that defines two security roles, ReadOnly and Administrator:
<security-role>
<description>
This role is allowed to execute any method on the bean.
They are allowed to read and change any cabin bean data.
</description>
<role-name>
Administrator
</role-name>
</security-role>
<security-role>
<description>
This role is allowed to locate and read cabin info.
This role is not allowed to change cabin bean data.
</description>
<role-name>
ReadOnly
</role-name>
</security-role>
The role names in this descriptor are not reserved or special names, with some sort of predefined meaning; they are simply logical names chosen by the bean assembler. In other words, the role names can be anything you want as long as they are descriptive.[4]
[4]For a complete understanding of XML, including specific rules for tag names and data, see XML Pocket Reference, by Robert Eckstein (O'Reilly).
How are roles mapped into actions that are allowed or forbidden? Once the security-role tags are declared, they can be associated with methods in the bean using method-permission tags. Each method-permission tag contains one or more method tags, which identify the bean methods associated with one or more logical roles identified by the role-name tags. The role-name tags must match the names defined by the security-role tags shown earlier.
<method-permission>
<role-name>Administrator</role-name>
<method>
<ejb-name>CabinEJB</ejb-name>
<method-name>*</method-name>
</method>
</method-permission>
</method-permission>
<role-name>ReadOnly</role-name>
<method>
<ejb-name>CabinEJB</ejb-name>
<method-name>getName</method-name>
</method>
<method>
<ejb-name>CabinEJB</ejb-name>
<method-name>getDeckLevel</method-name>
</method>
<method>
<ejb-name>CabinEJB</ejb-name>
<method-name>findByPrimaryKey</method-name>
</method>
</method-permission>
In the first method-permission, the Administrator role is associated with all methods on the Cabin bean, which is denoted by specifying the wildcard character (*) in the method-name of the method tag. In the second method-permission the ReadOnly role is limited to accessing only three methods: getName(), getDeckLevel(), and findByPrimaryKey(). Any attempt by a ReadOnly role to access a method that is not listed in the method-permission will result in an exception. This kind of access control makes for a fairly fine-grained authorization system.
Since an XML deployment descriptor can be used to describe more than one enterprise bean, the tags used to declare method permissions and security roles are defined in a special section of the deployment descriptor, so that several beans can share the same security roles. The exact location of these tags and their relationship to other sections of the XML deployment descriptor will be covered in more detail in Chapter 10, "XML Deployment Descriptors".
When the bean is deployed, the person deploying the bean will examine the security-role information and map each logical role to a corresponding user group in the operational environment. The deployer need not be concerned with what roles go to which methods; he can rely on the descriptions given in the security-role tags to determine matches based on the description of the logical role. This unburdens the deployer, who may not be a developer, from having to understand how the bean works in order to deploy it.
Figure 3-12 shows the same bean deployed in two different environments (labeled X and Z). In each environment, the user groups in the operational environment are mapped to their logical equivalent roles in the XML deployment descriptor so that specific user groups have access privileges to specific methods on specific beans.
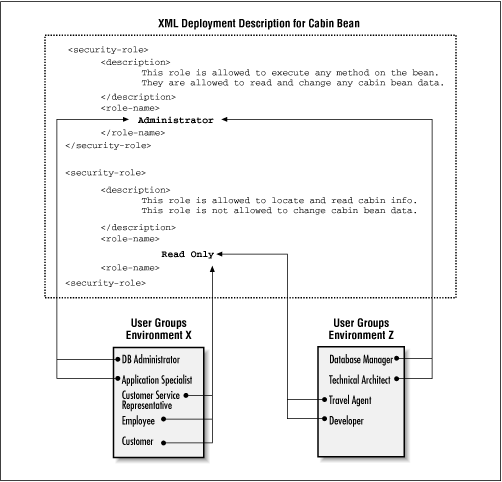
Figure 3-12. Mapping roles in the operational environment to logical roles in the deployment descriptor
As you can see from the figure, the ReadOnly role is mapped to those groups that should be limited to the get accessor methods and the find method. The Administrator role is mapped to those user groups that should have privileges to invoke any method on the Cabin bean.
The access control described here is implicit; once the bean is deployed the container takes care of checking that users only access methods for which they have permission. This is accomplished by propagating the security identity, the Principle, with each method invocation from the client to the bean. When a client invokes a method on a bean, the client's Principle is checked to see if it is a member of a role mapped to that method. If it's not, an exception is thrown and the client is denied permission to invoke the method. If the client is a member of a privileged role, the invocation is allowed to go forward and the method is invoked.
If a bean attempts to access any other beans while servicing a client, it will pass along the client's security identity for access control checks by the other beans. In this way, a client's Principle is propagated from one bean invocation to the next, ensuring that a client's access is controlled whether or not it invokes a bean method directly.
3.2.6.2. EJB 1.0: Method-driven access control
In EJB 1.0, the security identity is represented by a java.security.Identity object. This class was used in JDK 1.1 but has been deprecated and replaced by the new security architecture in JDK 1.2. The java.security.Identity object is used in JDK 1.1 to represent people, groups, organizations, smart cards, etc.
As you learned in Chapter 2, "Architectural Overview", every bean type in EJB 1.0 has a DeploymentDescriptor, which describes the bean and defines how it will be managed at runtime. The DeploymentDescriptor contains ControlDescriptors and AccessControlEntrys. The AccessControlEntrys list all the identities that are allowed to invoke the bean's methods. The ControlDescriptor defines, among other things, the runAs security identity for the bean methods.
The person deploying the bean decides who gets to access the bean's methods by choosing Identitys from the EJB server and mapping them to the bean and its methods. AccessControlEntrys are responsible for the mapping. An AccessControlEntry contains a method identifier and a list of the Identitys that are allowed to access the method. An AccessControlEntry that doesn't specify a specific method is the default AccessControlEntry for the bean. Any methods that don't have an AccessControlEntry use the bean's default AccessControlEntry. Figure 3-13 shows how the Cabin bean's DeploymentDescriptor would map a set of AccessControlEntrys defined for the CabinBean's methods.
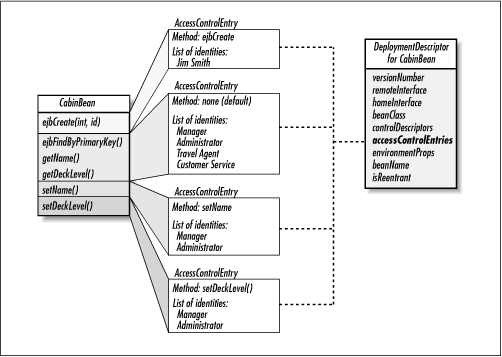
Figure 3-13. AccessControlEntrys for CabinBean
In addition to specifying the Identitys that have access to a bean's methods, the deployer also specifies the runAs Identity for the bean's methods. The runAs Identity was abandoned in EJB 1.1, but it's an important part of the EJB 1.0 access control architecture. While the AccessControlEntrys specify which Identitys have access to the bean's methods, the ControlDescriptors specify under which Identity the method will run. In other words, the runAs Identity is used as the bean's identity when it tries to invoke methods on other beans--this identity isn't necessarily the same as the identity that's currently accessing the bean. For example, it is possible to specify that the ejbCreate() method can only be accessed by Jim Smith but that it runs under Administrator's Identity. This is useful when beans or resources accessed in the body of the method require an Identity different from the one used to gain access to the method. The ejbCreate() method might call a method in bean X that requires the Administrator's Identity. If we want to use bean X in the ejbCreate() method, but we only want Jim Smith to create new cabins, we would use the ControlDescriptor and AccessControlEntry together to give us this kind of flexibility: the AccessControlEntry for ejbCreate() would specify that only Jim Smith can invoke the method, and the ControlDescriptor would specify that the bean's runAs Identity is Administrator.
ControlDescriptors, like AccessControlEntrys, can apply to a specific method or act as a default for the bean. The ControlDescriptor allows the deployer to specify one of three possible runAs modes:
- CLIENT_IDENTITY
-
The method runs under the calling client's Identity. In other words, the Identity used to gain access will also be the runAs Identity for the method.
- SPECIFIED_IDENTITY
-
The method runs under a previously chosen Identity. The Identity used is set on the ControlDescriptor when the bean is deployed.
- SYSTEM_IDENTITY
-
The method runs under a system Identity. The SYSTEM_IDENTITY is determined by the platform but is usually the Identity that the EJB server itself is running under.
Figure 3-14 illustrates how the runAs Identity can change in a chain of method invocations. Notice that the runAs Identity is the Identity used to test for access in subsequent method invocations.
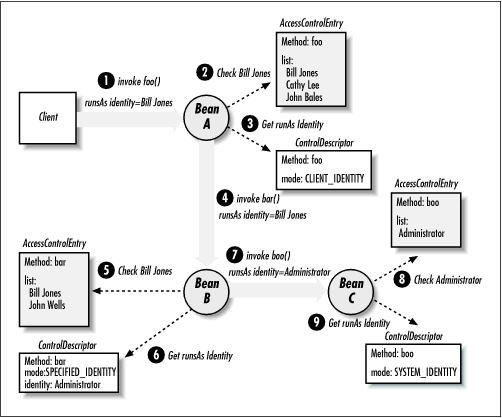
Figure 3-14. runAs Identity
-
The client who is identified as "Bill Jones" invokes the method foo() on bean A.
-
Before servicing the method, bean A checks to see if "Bill Jones" is in the AccessControlEntry for foo().
-
Once validated, foo() executes under the runAs Identity of the calling client.
-
While foo() is executing, it invokes method bar() on bean B.
-
Bean B checks method foo()'s runAs Identity ("Bill Jones") against the AccessControlEntry for method bar(). "Bill Jones" is in the AccessControlEntry's list of Identitys, so the method bar() is allowed to execute.
-
The method bar(), however, is executed under the Identity of "Administrator" as specified by bar()'s ControlDescriptor.
-
While bar() is executing, bean B invokes the method boo() on bean C.
-
Bean C checks and finds that bar()'s runAs Identity ("Administrator") is in the AccessControlEntry.
-
The ControlDescriptor for the method boo() requires that it be executed under the runAs Identity of the system.
This protocol applies equally to entity and stateless session beans. All the methods in a stateful session bean, however, have a single runAs Identity, which is the Identity used to create the session--the identity used when ejbCreate() is invoked. In other words, subsequent methods invoked on a stateful bean instance must not specify a conflicting runAs identity.
Here is a code fragment that shows how the access control setting can be made programmatically in a DeploymentDescriptor. In this example, we are setting the access control attributes for bean A. The AclRepository type is an imaginary interface into a proprietary database or directory.
// Create a new AccessControlEntry.
AccessControlEntry ace = new AccessControlEntry();
// Get a reference to the method foo() using reflection.
Class beanClass = ABean.class;
Class parameters [] = new Class[0];
Method fooMethod = beanClass.getDeclaredMethod("foo", parameters);
// Add the method reference to the AccessControlEntry.
ace.setMethod(fooMethod);
// Get a list of identities.
Identity [] identities = new Identity[3];
identities[0] = AclRepository.getIdentity("Bill Jones");
identities[1] = AclRepository.getIdentity("Cathy Lee");
identities[2] = AclRepository.getIdentity("John Bales");
// Add the identities to the AccessControlEntry.
ace.setAllowedIdentities(identities);
// Create a new ControlDescriptor.
ControlDescriptor cd = new ControlDescriptor();
// Set the foo() as the method and the runAs mode as CLIENT_IDENTITY.
cd.setMethod(fooMethod);
cd.setRunAsMode(ControlDescriptor.CLIENT_IDENTITY );
// Add the ControlDescriptor and AccessControlEntry to the
// DeploymentDescriptor for Bean A.
deploymentDescriptor.setAccessControlEntries(0,ace);
deploymentDescriptor.setControlDescriptors(0,cd);
 |  |  |
| 3.1. Resource Management |  | 3.3. What's Next? |

Copyright © 2001 O'Reilly & Associates. All rights reserved.