
8.5. Bandwidth Management
Armed with a basic ability to monitor our data throughput over time, we can now discuss how to use this information to effectively manage the available bandwidth.
The general principle behind bandwidth management is to optimize the use of the available bandwidth to satisfy certain requirements of the system. The nature of these requirements varies greatly from one application to the next, and so do the approaches used to manage bandwidth. The general approach is to assess the performance of the system in terms of data input and output rates, content conversion rates, and computation times. Based on this assessment, we can try to adjust resource allocations to improve the overall performance of the system.
In order to demonstrate some of the ways that bandwidth can be managed, we'll first look at how a streaming audio agent would be implemented. In many ways, streaming audio is a worst-case scenario for bandwidth-limited applications, since there are heavy real-time constraints as well as computation requirements. After this, we will look at implementing a component of a Java-based WWW browser, to see how bandwidth can be managed across multiple input streams to maximize perceived performance.
8.5.1. Streaming Multimedia
In this case, the primary purpose of the local agent is to receive multimedia data from the network, process it as needed to convert it to a format suitable for presentation, and present the multimedia data to the user. The driving factor is optimizing the presentation to the user. We want audio to play without skips, video to play as smoothly and consistently as possible, and graphics to display when they are supposed to in the overall presentation. Typically, we also need the audio, video, and graphics display to be synchronized with each other, and to maintain that synchronization even if some data is late arriving.
In order to focus on the basic issues at play here, let's look at the simplest case: a single stream of media data being received in a low-bandwidth environment for real-time playback. This is a particularly relevant example, since modem-rate audio streaming has become so popular on the Web. The audio samples are typically compressed before being transmitted, so the audio receiver must decode the compressed data into audio samples before playing them on the local audio device. Using our ContentConsumer and ContentProducer classes, we can define a StreamProducer extension of ContentProducer that simply provides a ContentProducer interface to an InputStream. In our application, this StreamProducer acts as a source of compressed audio data. The AudioProducer is a ContentProducer extension that generates audio samples from compressed audio data by decoding the compressed data. We set its source to be the StreamProducer that we just wrapped around our RTInputStream. Finally, we define an AudioConsumer extension of Content-Consumer that consumes audio samples by sending them to the local audio device. We won't bother implementing these subclasses yet; for now we only need to note that they extend the ContentConsumer and ContentProducer interfaces.
With these classes in hand, our streaming audio playback might be implemented along the following lines:
// Get the audio input stream, typically from a Socket connection with // a server. InputStream audioIn = ... // Wrap it with a real-time stream so we can monitor data throughput // off of the wire RTInputStream rtAudioIn = new RTInputStream(audioIn); // Make our audio pipeline: // compressed audio -> raw audio -> audio device StreamProducer stProd = new StreamProducer(rtAudioIn); AudioProducer audioProd = new AudioProducer(); audioProd.setSource(stProd); String audioFileSpec = "/dev/audio"; AudioConsumer audioCons = new AudioConsumer(audioFileSpec); audioCons.setSource(audioProd); // Start playback audioCons.consumeAll();
Here we simply take our source of raw data, in the form of an InputStream, wrap it with an RTInputStream to allow us to monitor the input data rate, then wrap it with a StreamProducer so that we can build up the rest of the pipeline. We create an AudioProducer and set the StreamProducer as its source, then create an AudioConsumer pointing to an appropriate local device driver and set the AudioProducer as its source. To begin the streaming playback, we simply call the consumeAll() method on the AudioConsumer, which causes it to call the produce() method on its source, and so on up the pipeline until the StreamProducer does a read on its InputStream. All along the pipeline, we are maintaining data throughput measurements using the facilities built into our RTInputStream, ContentConsumer, and ContentProducer classes.
The input stream is something that we have little control over, so we can do little at that stage of our pipeline besides monitoring the input data rate using the RTInputStream. There are some data buffering issues that we have to deal with in the other stages, however. Let's start with the tail end of the pipeline, the AudioConsumer. Most audio devices on computers have a small internal data buffer in which to hold audio samples. Since in most cases an application can feed audio data to the device much faster than it can play the samples back in real time, our AudioConsumer needs to provide some external data buffering. For example, assuming that our audio device accepts 16-bit audio samples from an audio stream that was sampled at CD rates (e.g., 44,000 samples per second), the audio device plays back data at 44,000 x 2 = 88kB/s. Assuming a ready supply of audio data, such as a local audio file, this data rate will be well exceeded by the application feeding the audio device. So our AudioConsumer class will have to buffer audio samples when the audio device has filled its internal data buffers. Its doConsume() implementation may look something like the following:
public boolean doConsume(byte data[]) {
// If we already have data queued in our local buffer, then
// put this new data into the end of the queue and pull the
// first data out of the queue
if (!buffer.isEmpty()) {
buffer.append(data);
data = buffer.remove();
}
// Try to write the data to the audio device
int numBytes = device.write(data);
if (numBytes < data.length) {
// Add any remaining bytes to the beginning of our
// local buffer
byte newBuf = new byte[data.length - numBytes];
System.arraycopy(data, numBytes, newBuf, 0, newBuf.length);
buffer.prepend(newBuf);
}
if (numBytes > 0)
return true;
else
return false;
}
We assume that device is a data member of the AudioConsumer class that represents an interface to the audio device driver, and that buffer is another data member that is some sort of storage class for holding data arrays.
The workhorse of our audio pipeline is the AudioProducer class, and it's here that our data throughput monitoring will be the most useful. The AudioProducer must take the compressed audio data stream, decompress the data, and pass the audio samples on to the AudioConsumer. It will also have to maintain its own data buffer for compressed audio data, for the same reasons that the AudioConsumer needs to maintain its own data buffer. A given amount of compressed audio data will take some amount of time to be transmitted over the network and be fed to the AudioProducer. It also takes some non-finite amount of time for the AudioProducer to decode a chunk of compressed audio data into audio samples, and some time for the audio device to consume this data (e.g., to play the audio samples). Ideally, we want the audio playback to be continuous and free from skips or blank spots, since these are very noticeable to even the casual listener. The AudioProducer needs a data buffer so that it can maintain a constant flow of audio samples to the AudioConsumer regardless of the rates at which compressed data is fed into the producer, or audio samples are pulled out of the producer by the consumer. Our streaming audio pipeline now looks like Figure 8-1, with a compressed audio data buffer on the AudioProducer.
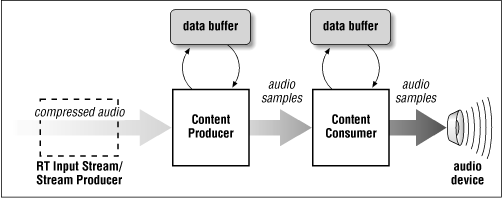
Figure 8-1. Streaming audio pipeline
Suppose the input stream of compressed audio starts, and we let the AudioProducer begin decompressing data and immediately pass it on to the AudioConsumer before moving on to the next chunk of compressed audio data, with no data buffering. If the AudioConsumer finishes playing the first set of audio samples before the AudioProducer is ready with the next set, then we will hear a gap in the audio playback. This can happen if the compressed data stream slows down to the point that the time to download and decode a given amount of compressed audio is greater than the time for the resulting audio samples to be played. It can also happen if the local CPU resources become scarce (i.e., the user has started an intensive spreadsheet calculation while listening to the audio clip). In this case, the additional decode time makes the AudioProducer's data production rate lag behind the AudioConsumer's consumption rate, and we hear gaps in the audio again.
So now that we've justified the need for both the AudioProducer and the AudioConsumer to have data buffers, we need to decide how much data to buffer at each stage. We'll assume that the AudioConsumer will be the simpleton in the pipeline, and that it will simply buffer any data that the audio device can't buffer itself. This allows us to concentrate on the AudioProducer as the main data manager in the pipeline.
When the AudioProducer starts reading from the input stream, it doesn't know how fast to expect the compressed data to arrive, or how long it will take to decode the compressed data into audio samples. For this reason, the AudioProducer needs to read and decode some compressed data in order to gauge the effective bandwidth of the network connection and the rate at which the producer can output audio samples to the consumer; from this information AudioProducer estimates a safe data buffer size. During playback, it also needs to check the input rate of compressed data, and its own output data rate, to see if conditions warrant a change in the buffer size. A noticeable drop in the input rate may warrant a pause in the playback while the AudioProducer fills a larger buffer so that the remainder of the audio clip can be played without interruption. The same applies when local CPU resources have become scarce because other applications are starting or becoming more active, thus slowing the rate at which the AudioProducer can decode audio samples.
A partial implementation of our AudioProducer is shown in Example 8-6. We have not included the implementation of the audio decode algorithm, and we have also left out the implementation of the buffer manipulation routines, since their intended operation is obvious from their use in the rest of the class implementation.
Example 8-6. The AudioProducer Class
package dcj.examples.Bandwidth;
import dcj.util.Bandwidth.*;
import java.io.InputStream;
import java.io.OutputStream;
public class AudioProducer extends ContentProducer
{
byte[] buffer = null;
long maxBuffer = 0;
long sampleRate;
// Buffer operations...
protected void appendToBuffer(byte[] data);
protected byte[] removeFromBuffer(long size);
// Method for computing new buffer size based on input
// data rate, our production rate, and the audio sample rate
protected void resizeBuffer(float inRate, float outRate,
long audioRate);
// Method that decodes a given chunk of compressed data into
// audio samples.
protected byte[] decode(byte[] cData);
public boolean produceAll() {
if (buffer == null) {
int maxLoop = 10;
long bytesPerLoop = 512;
for (int loop = 0; loop < maxLoop; loop++) {
byte[] data = produce(bytesPerLoop);
appendToBuffer(data);
}
// Assuming we know the rate at which data is required by the
// AudioConsumer (i.e., the sample rate of the audio), then
// estimate the buffer size needed for continuous playback
resizeBuffer(source.getAverageRate(), monitor.getAverageRate(),
sampleRate);
}
boolean success = false;
if (dest != null) {
byte[] data = produce();
while (data != null) {
success = dest.consume(data);
// Re-estimate buffer size
resizeBuffer(source.getLastRate(), monitor.getLastRate(),
sampleRate);
if (success)
data = produce();
else
data = null;
}
}
return success;
}
protected byte[] doProduction(long limit) {
byte[] sData = null;
// Ask our source for compressed data, and decode it.
if (source != null) {
sData = source.produce(limit);
}
byte[] audioData = decode(sData);
// If our buffer is not full, add the new data to it
if (buffer.length < maxBuffer) {
appendBuffer(audioData);
}
// If our buffer is now full, then return the requested
// amount of data, else return nothing.
if (buffer.length > maxBuffer) {
audioData = removeFromBuffer(limit);
}
else
audioData = null;
return audioData;
}
}
Our AudioProducer class extends the ContentProducer class by reimplementing the produceAll() and doProduction() methods to deal with the data buffering requirements of our application. The produceAll() implementation has the same basic structure as the implementation in the ContentProducer class, but here the method is also responsible for initializing the data buffer to a size that matches the environment it encounters when first called. The first time produceAll() is called, the data buffer has not yet been initialized, so the AudioProducer must first process some data in order to gauge the expected input and output data rates. It does this by requesting a series of data chunks from the input stream and decoding them by calling its own produce() method. In this case, we use ten chunks of compressed data of 512 bytes each to gauge the throughput, but we could use a single larger chunk of data, or many small chunks of data. The important thing is to try to match the expected interaction with the input stream and decoder as much as possible. We chose a set of medium-size chunks of data because we will be running the producer this way in full operation--get some data from the input stream, decode it, and either buffer it or hand it off to the AudioConsumer. We typically won't be asking for the entire audio clip before decoding it, since the driving requirement is that we want to stream audio data and play it back in real time. We also don't want to fragment the clip into chunks that are too small because the setup time for the decoder will start to affect the throughput rate.
When we have an initial estimate for the buffer size, the AudioProducer starts requesting data from the input stream and producing audio samples by calling its produce() method. After each produce/consume cycle, the produceAll() method recalculates the required buffer size by calling the resizeBuffer() method again. We do this to track changes in the network bandwidth and the local environment. If the input rate from the network or the output rate from the decoder drops too low, we want to increase the data buffer. If the change is dramatic, this may mean pausing the playback while the buffer fills with data; if this prevents a series of interruptions later, then it is worth it in terms of playback quality.
The doProduction() method manages the data buffer. It first requests compressed data from the input stream, then sends the data through the decoder. If the buffer is not full, then the audio samples are appended to the buffer. If the buffer is full, then the requested amount of data is pulled from the buffer and returned.
On the server side, the bandwidth monitoring and management requirements are generally simpler, but can be made as complex as we would like. The primary requirement of the audio server is to send data over the network as quickly as possible, so that the client has a chance of playing the audio back in real time. If we are sending a pre-encoded data file, we may not even need a server agent; a simple file transfer is all that's required, assuming that the file system and the network I/O on the server is optimized to send data as quickly as possible. If we're streaming a live audio feed, the server will have to encode the audio stream as it is generated and send the compressed data over the network to the client. Again, assuming that the encoding scheme and the network connection are both fixed, there is not much the server agent can do to improve the situation if the network bandwidth to the client starts to degrade.
However, many client/server audio systems these days are designed to provide variable-bandwidth capabilities, so that the server can respond to the changing nature of the network connection. Typically, the server and the client engage in a bandwidth assessment period, much like the beginning of the produceAll() method in our AudioProducer. Once the expected bandwidth is known, then an encoding scheme with a given level of compression is chosen so that enough data will reach the client to allow constant playback. If the bandwidth changes significantly during the data streaming, then the client and server can renegotiate a new encoding scheme. The server alters its encoding process and begins sending compressed data in the new format; the client then alters its decoding process to handle the new format.
8.5.2. Web Browsing
One application that is often bandwidth-limited, but has very different constraints and goals from streaming audio, is viewing web pages. In this case, maintaining a constant stream of data to the final content consumer is not essential (unless the page has streaming audio incorporated). What is more important is allocating bandwidth to download page elements that are of most interest to the viewer, leaving the other elements to be downloaded later, or at a slower rate.
Let's suppose that we are asked to implement a web browser in Java. For discussion purposes, we'll ignore the initialization of the HTTP connection, and the download of the HTML code making up the requested page. We'll concentrate only on the next stage in loading a page, which is downloading all the media elements referenced in the page, such as images used for headers, icons, and figures. Our goal is to make it look like the page's images and other media elements are loading as fast as possible. In order to do that, we'll distinguish between elements of the page that the user is focusing on, and those that he isn't. If we take the whole HTML page and consider the segment that is inside the scrolling window of the user's web browser, as shown in Figure 8-2, then the focus elements are all of those media elements that lie inside of the scrolling browser window.
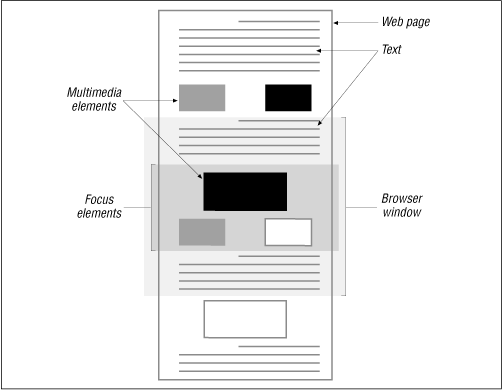
Figure 8-2. Focused and unfocused elements on a web page
Example 8-7 shows an HTMLPageLoader class that manages the loading of a set of HTML page elements. These page elements are given to the HTMLPageLoader in the form of URL objects created by some outside agent, such as a web browser. The HTMLPageLoader maintains three lists of elements: one (elements) contains all elements the loader has been asked to load; another (focusElements) contains elements that are within the user's current focus on the screen; and the third (loadedElements) is a list of elements that have been completely downloaded from their URL address. An external agent can add elements to the HTMLPageLoader using the addPageElements() method, and it can move elements on and off of the focus list using the focusElement() and defocusElement() methods. The loadElements() method is the workhorse of the class, responsible for downloading the content of each element in the page. The HTMLPageLoader class implements the Runnable interface so that loading the page elements can be performed in a separate thread from the agent that monitors and updates the focus list. The run() method simply calls loadElements().
Example 8-7. An HTML Page Loader
package dcj.examples.Bandwidth;
import dcj.util.Bandwidth.*;
import java.io.InputStream;
import java.lang.Runnable;
public class HTMLPageLoader implements Runnable {
Vector elements;
Vector focusElements;
Vector loadedElements;
boolean focusUpdate;
Hashtable elementConsumers = new Hashtable;
public void run() {
loadElements();
}
public HTMLPageLoader(Vector urlList) {
elements = urlList.clone();
}
public void addPageElement(URL addr) {
elements.addElement(addr);
}
public void focusElement(URL addr) {
synchronized (elements) {
if (!elements.contains(addr)) {
addPageElement(addr);
}
}
synchronized (focusElements) {
if (!focusElements.contains(addr)) {
focusElements.addElement(addr);
}
focusUpdate = true;
}
}
public defocusElement(URL addr) {
synchronized (focusElements) {
if (focusElements.removeElement(addr)) {
focusUpdate = true;
}
}
}
public void loadElements() {
Vector localFocus = null;
boolean done = false;
boolean changedFocus = false;
Vector consumers;
synchronized (focusElements) {
if (!focusElements.isEmpty()) {
localFocus = (Vector)focusElements.clone();
}
}
synchronized (elements) {
if (localFocus == null) {
localFocus = elements.clone();
}
}
while (!done) {
Enumeration e = localFocus.elements();
while (e.hasMoreElements()) {
URL element = (URL)e.nextElement();
ContentConsumer c = getConsumer(element);
long byteCount = elementSize(element);
// Consume a maximum of 5 percent of the entire element
// in each loop.
if (byteCount > 20) {
byteCount = byteCount / 20;
}
c.consume(byteCount);
if (isComplete(element)) {
doneElements.addElement(element);
focusElements.removeElement(element);
localFocus.removeElement(element);
}
}
synchronized (focusElements) {
if (focusUpdate) {
localFocus = focusElements.clone();
focusUpdate = false;
changedFocus = true;
}
}
if (focusElements.isEmpty()) {
// No focus elements left, so we're either done loading
// the region the user is looking at, or we've finished
// the entire page.
if (doneElements.size() == elements.size()) {
done = true;
}
else {
localFocus = elements;
}
}
}
}
protected Vector getConsumer(URL item) {
ContentConsumer c;
// If the element has a consumer already,
// add it to the list.
if (elementConsumers.contains(item)) {
c = (ContentConsumer)elementConsumers.get(item);
}
else {
try {
InputStream in = item.openStream();
StreamProducer sp = new StreamProducer(in);
c = makeConsumerFor(item);
c.setSource(sp);
elementConsumers.put(item, c);
}
catch (Exception e) { }
}
return c;
}
}
The first thing the HTMLPageLoader does in its loadElements() method is check its focus list. If there are any elements on this list, these will be loaded first. If there are no focus elements, the loader takes the entire element list and begins loading them all. After initializing its hotlist, the loadElements() method enters a loop, loading chunks of the page elements until they are completely downloaded. Within the loop, the consumer for each element is obtained by calling the getConsumer() method. In the getConsumer() method, if a given element does not have a consumer already associated with it in the hashtable, one is generated and put into the hashtable. Each of the consumers associated with hotlist elements is then asked to consume a chunk of data for its element. If any of the elements are complete, the element is added to the "done" list. A check is made to see if the focus list has changed. If it has, the hotlist of elements is set to the current focus elements. If the list of focus elements is empty, we've either loaded all of the focus elements and can move on to the other page elements, or the page is completely loaded. If there are still unloaded elements, the hotlist is set to these elements. If not, the done flag is set to true, causing the loadElements() method to return.
The HTMLPageLoader class may be used in practice by a web browser as a separate I/O thread, running in parallel with a user interface thread that is redisplaying the page as the user scrolls up and down. The HMTLPageLoader thread is created once the URL elements of the page to be loaded have been determined:
Vector urls = ... HTMLPageLoader loader = new HTMLPageLoader(urls); Thread loaderThread = new Thread(loader); loaderThread.start();
We could also initialize the list of focus elements before starting the loader thread. The page display component of the user interface can then have a MouseMotionListener attached to it, which listens for mouse motion events. This listener could implement its mouseDragged() method along these lines:
public void mouseDragged(MouseEvent e) {
HTMLPageLoader loader = getLoader();
Rectangle focusArea =
getFocusArea(e.getX(), e.getY(), e.getComponent());
Vector urlList = getFocusItems(focusArea);
loader.defocusElements();
Enumeration e = urlList.elements();
while (e.hasMoreElements()) {
loader.focusElement((URL)e.nextElement());
}
}
This will cause the HTMLPageLoader to allocate the input bandwidth to the focus elements chosen by the user.
In this bandwidth-limited distributed application, we're not so much concerned with actual throughput rates, but rather with the relative amount of bandwidth allocated to different input streams in order to optimize the user's experience.
 |  |  |
| 8.4. Monitoring Bandwidth |  | 9. Collaborative Systems |

Copyright © 2001 O'Reilly & Associates. All rights reserved.