| Справочное описание GLib | ||||
|---|---|---|---|---|
Character Set ConversionCharacter Set Conversion — конвертирование строк между разными наборами символов используя |
#include <glib.h>
gchar* g_convert (const gchar *str,
gssize len,
const gchar *to_codeset,
const gchar *from_codeset,
gsize *bytes_read,
gsize *bytes_written,
GError **error);
gchar* g_convert_with_fallback (const gchar *str,
gssize len,
const gchar *to_codeset,
const gchar *from_codeset,
gchar *fallback,
gsize *bytes_read,
gsize *bytes_written,
GError **error);
GIConv;
gchar* g_convert_with_iconv (const gchar *str,
gssize len,
GIConv converter,
gsize *bytes_read,
gsize *bytes_written,
GError **error);
#define G_CONVERT_ERROR
GIConv g_iconv_open (const gchar *to_codeset,
const gchar *from_codeset);
size_t g_iconv (GIConv converter,
gchar **inbuf,
gsize *inbytes_left,
gchar **outbuf,
gsize *outbytes_left);
gint g_iconv_close (GIConv converter);
gchar* g_locale_to_utf8 (const gchar *opsysstring,
gssize len,
gsize *bytes_read,
gsize *bytes_written,
GError **error);
gchar* g_filename_to_utf8 (const gchar *opsysstring,
gssize len,
gsize *bytes_read,
gsize *bytes_written,
GError **error);
gchar* g_filename_from_utf8 (const gchar *utf8string,
gssize len,
gsize *bytes_read,
gsize *bytes_written,
GError **error);
gchar* g_filename_from_uri (const gchar *uri,
gchar **hostname,
GError **error);
gchar* g_filename_to_uri (const gchar *filename,
const gchar *hostname,
GError **error);
gboolean g_get_filename_charsets (G_CONST_RETURN gchar ***charsets);
gchar* g_filename_display_name (const gchar *filename);
gchar* g_filename_display_basename (const gchar *filename);
gchar** g_uri_list_extract_uris (const gchar *uri_list);
gchar* g_locale_from_utf8 (const gchar *utf8string,
gssize len,
gsize *bytes_read,
gsize *bytes_written,
GError **error);
enum GConvertError;
gboolean g_get_charset (G_CONST_RETURN char **charset);
Исторически, Unix не имел определённой кодировки для имен файла:
имя файла допустимо пока в нём нет разделителей пути ("/").
Однако, отображение имён файла может требовать преобразования:
из набора символа в котором оно создавалось, в набор символов
с которым оперирует приложение. Рассмотрим Испанское имя файла
"Presentación.sxi". Если
приложение которое создавало его использует ISO-8859-1 для его кодировки,
то фактическое имя файла на диске должно выглядеть так:
Character: P r e s e n t a c i ó n . s x i
Hex code: 50 72 65 73 65 6e 74 61 63 69 f3 6e 2e 73 78 69
Однако, если приложение использует UTF-8, фактическое имя файла на диске будет выглядеть так:
Character: P r e s e n t a c i ó n . s x i
Hex code: 50 72 65 73 65 6e 74 61 63 69 c3 b3 6e 2e 73 78 69
Glib использует UTF-8 для строк, и GUI toolkits такой как GTK+
который использует Glib делает тоже самое. Если вы получили имя файла из
файловой системы, например, из
readdir(3) или из g_dir_read_name()open(2)
или fopen(3).
По умолчанию, Glib предполагает что имена файлов на диске находятся в кодировке UTF-8.
Это правильное предположение для файловых систем которые были созданы относительно недавно:
большинство приложений используют UTF-8 кодировку для их строк, а так же для имён файлов которые
они создают. Однако, более старые файловые системы могут по прежнему создавать имена файлов
в "старых" кодировках, таких как ISO-8859-1. В этом случае, по причинам совместимости, вы можете
инструктировать Glib использовать эту специальную кодировки для имен файлов а не UTF-8.
Вы можете выполнить это определив кодировку для имён файлов в переменной окружения
G_FILENAME_ENCODING.
Например, если ваша инсталяция использует ISO-8859-1 для имен файлов, вы можете поместить следующее в свой
~/.profile:
export G_FILENAME_ENCODING=ISO-8859-1
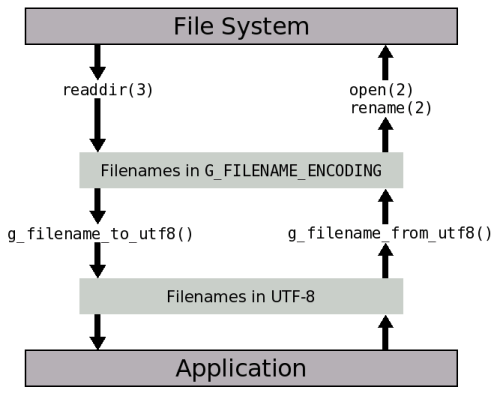
Glib обеспечивает функции g_filename_to_utf8()g_filename_from_utf8()G_FILENAME_ENCODING в кодировку UTF-8 и наоборот.
Схема 1, “Конвертация между кодировками имён файлов” иллюстрирует как эти функции используются
для конвертации между UTF-8 и кодировкой имён файлов в файловой системе.
Эта секция суммирует детали описанные выше. Вы можете использовать это как контрольный список необходимых вещей выполняемых для того чтобы удостоверится что ваше приложение выполняет перекодировку имён файлов корректно.
Если вы получаете имя файла из файловой системы с помощью функций
таких как readdir(3) или
gtk_file_chooser_get_filename()open(2),
rename(2), или
fopen(3) — изначальные имена файлов которые понимает файловая система.
Если вам нужно отобразить имя файла, конвертируйте его в UTF-8 перед использованием
g_filename_to_utf8()Unknown file name".
Не конвертируйте эту
строку обратно в кодировку используемую для имён файла
если вы хотите поместить её в файловую систему;
используйте оригинальное имя файла вместо этого.
Например, окно документа в текстовом процессоре
может отобразить "Unknown file name" в своём заголовке, но при этом
всё ещё позволяет пользователю сохранить файл, так как это сохранит
исходное имя внутренне. Это может произойти если пользователь
не имеет установленной переменной окружения G_FILENAME_ENCODING
даже если у него есть файлы имена которых не закодированы в UTF-8.
Если ваш пользовательский интерфейс позволяет пользователю печатать имя файла
для сохранения или переименования, конвертируйте его в кодировку используемую для имен файлов файловой системы
используя g_filename_from_utf8()fopen(3). Если конверсия неудалась,
у пользователя запрашивается другое имя файла. Это может произойти
если пользователь печатает Японскими символами когда
G_FILENAME_ENCODING установлена в
ISO-8859-1, например.
gchar* g_convert (const gchar *str,
gssize len,
const gchar *to_codeset,
const gchar *from_codeset,
gsize *bytes_read,
gsize *bytes_written,
GError **error);
Конвертирует строку из одного символьного набора в другой.
Помните что вы должны использовать g_iconv()
для поточных конвертаций[2].
str : |
строка для конвертации |
len : |
длина строки, или -1 если строка это nul-завершённый[1]. |
to_codeset : |
имя набора символов в который конвертируется str
|
from_codeset : |
набор символов str.
|
bytes_read : |
Размещение для хранения количества байт во входной строке которые были успешно конвертированы,
или NULL.
Даже если конвертация полностью удалась, это значение может быть меньше чем
len если были частичные символы в конце ввода.
Если произошла ошибка
G_CONVERT_ERROR_ILLEGAL_SEQUENCE, значение хранит смещение
байт после последней допустимой последовательности ввода.
|
bytes_written : |
количество байт сохраняемое в буфере вывода (не включая завершающий nul). |
error : |
расположение для хранения произошедшей ошибки, или
NULL для игнорирования ошибок.
Любая из ошибок в
GConvertError может произойти.
|
| Возвращает : | Если конвертация выполнена, вновь распределённую nul-завершённую строку, которая должна быть освобождена
g_free().
Иначе устанавливается NULL
и error.
|
gchar* g_convert_with_fallback (const gchar *str,
gssize len,
const gchar *to_codeset,
const gchar *from_codeset,
gchar *fallback,
gsize *bytes_read,
gsize *bytes_written,
GError **error);
Конвертирует строку из одного набора символов в другой, возможно включая
последовательности перехода в аварийный режим для символов не подходящих для вывода.
Помните что это не гарантирует что спецификация для последовательности аварийного режима
в fallback будет учтена. Некоторые системы могут выполнять
приблизительную конвертацию из from_codeset
в to_codeset в их iconv() функциях,
в этом случае GLib будет просто возвращать эту приблизительную конвертацию.
Помните что вы должны использовать g_iconv()
для конвертации строк[2].
str : |
строка для конвертации |
len : |
длина строки, или -1 если строка это nul-terminated[1]. |
to_codeset : |
имя набора символов в который конвертируется строка str
|
from_codeset : |
набор символов str.
|
fallback : |
UTF-8 строка для использования вместо символа не представленного в целевой кодировке.
(Строка должна быть доступна для представления в целевой кодировке).
Если NULL, символы не в целевой кодировке
будут представлены как Unicode escapes \uxxxx или \Uxxxxyyyy.
|
bytes_read : |
Расположение для хранения количества байт во входной строке которые были успешно конвертированы,
или NULL.
Даже если конвертация была полностью выполнена, это значение может быть
меньше чем len если есть частичные символы завершающие ввод.
|
bytes_written : |
количество байт сохранённых в буфер вывода (не включая завершающий nul). |
error : |
расположение для хранения произошедшей ошибки, или
NULL для игнорирования ошибок.
Любые ошибки в GConvertError могут произойти.
|
| Возвращает : | Если конвертация была полностью выполнена, вновь распределёная nul-завершённая строка, которая может быть освобождена с помощью
g_free().
Иначе NULL
и error будут установлены.
|
typedef struct _GIConv GIConv;
GIConv структура оболочка
iconv()
gchar* g_convert_with_iconv (const gchar *str,
gssize len,
GIConv converter,
gsize *bytes_read,
gsize *bytes_written,
GError **error);
Конвертирует строку из одного набора символов в другой.
Помните что вы должны использовать g_iconv() для поточных конвертаций[2].
str : |
строка для конвертации |
len : |
длина строки, или -1 если строка это nul-terminated[1]. |
converter : |
дескриптор конвертации из g_iconv_open()
|
bytes_read : |
размещение для хранения количества байт во входной строке
которые были успешно конвертированы, или NULL.
Даже если конвертация полностью выполнена, это значение может быть меньше
чем len, если были частичные символы в конце ввода.
Если произошла ошибка
G_CONVERT_ERROR_ILLEGAL_SEQUENCE, будет сохранено значение
смещения байт после последней допустимой последовательности ввода.
|
bytes_written : |
количество байт сохраняемых в буфере вывода (не включая завершающий nul). |
error : |
размещение для хранения произошедшей ошибки, или
NULL для игнорирования ошибок.
Могут произойти любые ошибки указанные в
GConvertError.
|
| Возвращает : | если конвертация полностью выполнена, вновь распределённую nul-завершённую строку,
которая может быть освобождена
g_free(). Иначе
NULL и error будут установлены.
|
#define G_CONVERT_ERROR g_convert_error_quark()
Домен ошибки (Error domain) для конвертации набора символов. Ошибки в этом домене будут из перечисления GConvertError. Смотрите GError для детальной информации об ошибках.
GIConv g_iconv_open (const gchar *to_codeset,
const gchar *from_codeset);
То же самое что и стандартная подпрограмма UNIX iconv_open(),
но может быть реализована через libiconv на разновидностях UNIX где имеется недостаток в родной реализации.
GLib обеспечивает g_convert()
и g_locale_to_utf8()
которые вероятно являются более удобными чем исходные оболочки iconv.
to_codeset : |
определяет устанавливаемую кодировку |
from_codeset : |
из какой кодировки перекодируется |
| Возвращает : | "дескриптор конвертора", или (GIConv)-1 если открываемый конвертер недоступен. |
size_t g_iconv (GIConv converter,
gchar **inbuf,
gsize *inbytes_left,
gchar **outbuf,
gsize *outbytes_left);
Тоже самое как стандартная подпрограмма UNIX iconv(),
но может быть реализована через libiconv на разновидностях UNIX в которых нет родной реализации.
GLib обеспечивает g_convert() и g_locale_to_utf8()
которые намного удобнее чем исходные оболочки iconv.
converter : |
дескриптор конвертации из g_iconv_open()
|
inbuf : |
байты для конвертации |
inbytes_left : |
входной параметр, байты остаются для конвертации в inbuf
|
outbuf : |
конвертирует вывод байт |
outbytes_left : |
параметр ввода-вывода, байты доступные для заполнения в outbuf
|
| Возвращает : | подсчёт необратимый преобразований, или -1 при возникновении ошибки error |
gint g_iconv_close (GIConv converter);
Тоже самое что стандартная подпрограмма UNIX iconv_close(),
но может быть реализована через libiconv на разновидностях UNIX где нет родной реализации.
Должна вызываться для очистки дескриптора конвертации из g_iconv_open() когда вы выполняете конвертационные действия.
GLib обеспечивает g_convert() и g_locale_to_utf8()
которые намного удобнее чем исходные оболочки iconv.
converter : |
дескриптор конвертации из g_iconv_open()
|
| Возвращает : | -1 при ошибке, 0 при удачном выполнении |
gchar* g_locale_to_utf8 (const gchar *opsysstring,
gssize len,
gsize *bytes_read,
gsize *bytes_written,
GError **error);
Конвертирует строку которая находится в кодировке используемой для строк C runtime (обычно тоже самое что используется операционной системой) в текущей локали в строку UTF-8.
opsysstring : |
строка в кодировке текущей локали. В Windows это означает system codepage. |
len : |
длина строки, или -1 если строка это завершающий ноль (nul-terminated)[1]. |
bytes_read : |
размещение для хранения количества байт во входной строке когда конвертация полностью выполнена,
или NULL.
Даже если конвертация выполнена, этот параметр может быть меньше чем
len если есть части символов в конце ввода.
Если произошла ошибка
G_CONVERT_ERROR_ILLEGAL_SEQUENCE, будет сохранено значение
смещения байт после последней допустимой цепочки ввода.
|
bytes_written : |
количество байт сохранённых в буфере вывода (не включая завершающий nul). |
error : |
расположение для хранения произошедшей ошибки, или
NULL для игнорирования ошибок.
Могут произойти любые ошибки в
GConvertError.
|
| Возвращает : | Конвертируемая строка, или NULL при ошибке.
|
gchar* g_filename_to_utf8 (const gchar *opsysstring,
gssize len,
gsize *bytes_read,
gsize *bytes_written,
GError **error);
Конвертирует строку которая в кодировке используемой GLib для имён файлов в строку UTF-8. Помните что в Windows GLib использует UTF-8 для имён файлов.
opsysstring : |
строка в кодировке для имён файлов |
len : |
длина строки, или -1 если строка это завершающий ноль (nul-terminated)[1]. |
bytes_read : |
расположение для хранения количества байт во входной строке когда конвертация полностью выполнена,
или NULL.
Даже если конвертация удалась, это значение может быть меньше чем
len если есть части символов в конце ввода.
Если произошла ошибка
G_CONVERT_ERROR_ILLEGAL_SEQUENCE,
будет сохранено смещение байт после последней допустимой цепочки ввода.
|
bytes_written : |
количество байт сохранённых в буфере вывода (не включая завершающий ноль). |
error : |
размещение для хранения произошедшей ошибки, или
NULL для игнорирования ошибок.
Могут произойти любые ошибки в GConvertError.
|
| Возвращает : | Конвертированная строка, или NULL при ошибке.
|
gchar* g_filename_from_utf8 (const gchar *utf8string,
gssize len,
gsize *bytes_read,
gsize *bytes_written,
GError **error);
Конвертирует строку из UTF-8 в кодировку GLib используемую для имен файлов. Помните что в Windows GLib использует UTF-8 для имён файлов.
utf8string : |
строка в кодировке UTF-8. |
len : |
длина строки, или -1 если строка это завершающий ноль (nul-terminated). |
bytes_read : |
расположение для хранения количества байт во входной строке при удачном выполнении конвертации,
или NULL.
Даже если конвертация выполнена, это значение может быть меньше чем
len если есть части символов в конце ввода.
Если произошла ошибка
G_CONVERT_ERROR_ILLEGAL_SEQUENCE, сохраняется значение
смещения байт после последней допустимой цепочки ввода.
|
bytes_written : |
количество байт сохранённых в буфере вывода (не включая завершающий ноль). |
error : |
размещение для хранения произошедшей ошибки, или
NULL для игнорирования ошибок.
Могут произойти любые ошибки в
GConvertError.
|
| Возвращает : | Конвертируемая строка, или NULL при ошибке.
|
gchar* g_filename_from_uri (const gchar *uri,
gchar **hostname,
GError **error);
Конвертирует ASCII-кодировку URI в локальное имя файла в кодировке используемой для имён файлов.
uri : |
uri описывающий имя файла (escaped, encoded in ASCII). |
hostname : |
расположение для хранения имени узла (hostname) для URI, или
NULL.
Если нет имени узла (hostname) в URI, то в этом расположении сохраняется
NULL.
|
error : |
расположение для хранения произошедшей ошибки, или
NULL для игнорирования ошибок.
Могут происходить любые ошибки в GConvertError.
|
| Возвращает : | результат в виде вновь распределённой строки содержащей имя файла,
или NULL при ошибке.
|
gchar* g_filename_to_uri (const gchar *filename,
const gchar *hostname,
GError **error);
Конвертирует абсолютное имя файла в управляющие символы ASCII-кодировки URI, с компонентом пути упоминаемым далее в Разделе 3.3. RFC 2396.
filename : |
абсолютное имя файла определённое в GLib кодировке имён файлов, которое является дисковыми байтами имени файла в Unix, и UTF-8 в Windows |
hostname : |
Имя узла в кодировке UTF-8, или NULL если нет.
|
error : |
расположение для хранения произошедшей ошибки, или
NULL для игнорирования ошибок.
Могут происходить любые ошибки в GConvertError.
|
| Возвращает : | вновь распределённая строка содержащая результат URI,
или NULL при ошибке.
|
gboolean g_get_filename_charsets (G_CONST_RETURN gchar ***charsets);
Определяет привилегированные наборы символов используемые для имён файлов.
Первый набор символов из charsets это кодировка имени файла,
последующие наборы символов используются когда происходят попытки сгенерировать отображаемое представление имени файла,
смотрите g_filename_display_name().
В Unix, набор символов определяются с помощью переменных окружения G_FILENAME_ENCODING и
G_BROKEN_FILENAMES. В Windows, набор символов используемый в GLib API всегда UTF-8,
а переменные окружения не имеют никакого эффекта.
G_FILENAME_ENCODING может быть установлен для разделённого запятыми списка
набора символов имён. Специальная лексема "locale" применяется
для обозначения набора символов для текущей локали. Если G_FILENAME_ENCODING
не установлена, но установлена G_BROKEN_FILENAMES, набор символов текущей
локали применяется как кодировка имени файла. Если переменные окружения не установлены совсем,
в качестве кодировки имени файла применяется UTF-8, но набор символов текущей локали также помещается
в список кодировок.
Возвращаемые charsets принадлежат GLib и не должны освобождаться.
Помните что в Unix, независимо от локального набора символов или значения G_FILENAME_ENCODING,
фактические имена файлов представленные в системе могут быть в любой произвольной кодировке или просто тарабарщиной (gibberish).
charsets : |
расположение возвращаемого NULL-завершённого
списка кодировок имён
|
| Возвращает : | TRUE если кодировка имени файла UTF-8.
|
Начиная с версии 2.6
gchar* g_filename_display_name (const gchar *filename);
Конвертирует имя файла в допустимую UTF-8 строку. Конвертация необязательно
обратима, поэтому вы должны иметь оригинал и использовать возвращаемое значение
этой функции только непосредственно для отображения.
В отличие от g_filename_to_utf8(), результатом гарантировано будет не-NULL
даже если имя файла фактически не находится в кодировке имени файла GLib.
Если GLib не может понять кодировку filename, как последний способ
она заменяет неизвестные символы с помощью U+FFFD, символом замены Unicode.
Вы можете искать результат кодировки UTF-8 этого символа (который находится в восьмеричной записи "\357\277\275") для поиска вывода если
filename был в недопустимой кодировке.
Если вы знаете полное имя пути файла вы должны использовать
g_filename_display_basename(),
так как она позволяет перекодировку имён файлов на основе их расположения.
filename : |
имя пути предположительно в GLib кодировке имени файла |
| Возвращает : | вновь распределённая строка содержащая перевод имени файла в правильной UTF-8 |
Начиная с версии 2.6
gchar* g_filename_display_basename (const gchar *filename);
Возвращает отображаемое базовое имя для специфического имени файла, гарантировано в правильной UTF-8. Отображаемое имя может быть не идентично имени файла, например могут быть проблемы конвертации в UTF-8, а некоторые файлы могут быть оттранслированы в отображении.
Если GLib не может понять кодировку filename, как последний вариант она
заменяет неизвестные символы с помощью U+FFFD, символ замены Unicode.
Вы можете найти результат для UTF-8 кодировки этого символа (который находится в восьмеричном представлении "\357\277\275")
для поиска вывода если filename был в недопустимой кодировке.
Вы должны поместить полное имя пути файла в функцию чтобы можно было выполнить трансляцию известных расположений.
Эта функция предпочтительней чем
g_filename_display_name() если вам известен полный путь, так как это позволяет трансляцию.
filename : |
полное имя пути в кодировке имени файла GLib |
| Возвращает : | вновь распределённая строка содержащая представление базового имени файла в допустимой UTF-8 |
Начиная с версии 2.6
gchar** g_uri_list_extract_uris (const gchar *uri_list);
Разбирает URI список соответствующий text/uri-списку mime type, определённого в RFC 2483, в индивидуальные URIs, отменяя любые коментарии. URIs являются не утверждёнными.
uri_list : |
URI список |
| Возвращает : | вновь распределённый NULL-завершённый список
строк содержащих индивидуальные URIs. Массив должен быть освобождён с помощью
g_strfreev().
|
Начиная с версии 2.6
gchar* g_locale_from_utf8 (const gchar *utf8string,
gssize len,
gsize *bytes_read,
gsize *bytes_written,
GError **error);
Конвертирует строку из UTF-8 в кодировку используемую для строк C runtime (обычно тоже самое что используется операционной системой) в текущей локали.
utf8string : |
строка в кодировке UTF-8 |
len : |
длина строки, или -1 если строка завершающий ноль[1]. |
bytes_read : |
расположение для хранения количества байт во входной строке
когда конвертация полностью выполнена, или NULL.
Даже если конвертация завершилась успешно, это значение может быть меньше
чем len если есть части символов в конце ввода.
Если произошла ошибка
G_CONVERT_ERROR_ILLEGAL_SEQUENCE, сохраняется значение
смещения байт после последней удачной цепочки ввода.
|
bytes_written : |
количество байт сохранённых в буфере вывода (не включая завершающий ноль). |
error : |
расположение для хранения произошедшей ошибки, или
NULL для игнорирования ошибок.
Могут произойти любые ошибки в
GConvertError.
|
| Возвращает : | конвертированная строка, или NULL при ошибке.
|
typedef enum
{
G_CONVERT_ERROR_NO_CONVERSION,
G_CONVERT_ERROR_ILLEGAL_SEQUENCE,
G_CONVERT_ERROR_FAILED,
G_CONVERT_ERROR_PARTIAL_INPUT,
G_CONVERT_ERROR_BAD_URI,
G_CONVERT_ERROR_NOT_ABSOLUTE_PATH
} GConvertError;
Коды ошибок возвращаемые подпрограммами конвертации наборов символов.
gboolean g_get_charset (G_CONST_RETURN char **charset);
Получает набор символов для текущей локали; вы можете использовать этот набор символов как аргумент для
g_convert(), для конвертации из
текущей локальной кодировки в некоторую другую кодировку. (Часто
g_locale_to_utf8() и g_locale_from_utf8() являются хорошими shortcuts, всё же.)
Возвращаемое значение равно TRUE
если локальной кодировкой является UTF-8, в этом случае вы можете избежать вызова
g_convert().
Возвращаемая строка в charset не распределяется, и не должна освобождаться.
charset : |
расположение возвращаемого имени набора символов |
| Возвращает : | TRUE если возвращаемый набор символов UTF-8
|
[1]
Помните что некоторые кодировки могут позволять nul байтам находится в строках.
В этом случае, использовать -1 для параметра len опасно.
[2]
Несмотря на то, что byes_read может возвращать информацию о частичных символах,
функции g_convert_... являются в основном неподходящими для потоков.
Если основной конвертер поддерживает внутреннее состояние, то это не сохраняется через последовательность вызовов g_convert(), g_convert_with_iconv() или
g_convert_with_fallback().
(Примером этому является GNU C конвертер для CP1255 который не выдаст основной символ
пока он знает что следующий символ не знак который можно совместить с основным символом.)