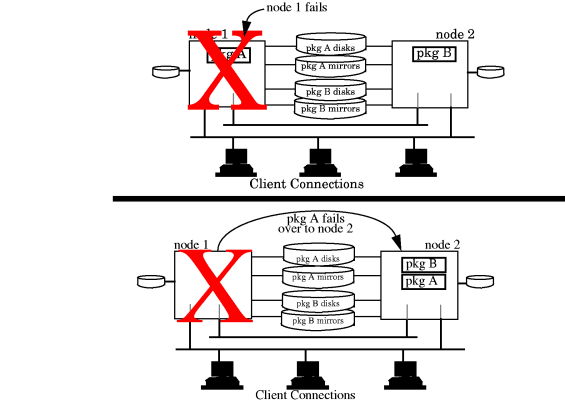
In an Serviceguard
cluster configuration, high availability is achieved by using redundant
hardware to eliminate single points of failure. This protects the
cluster against hardware faults, such as the node failure in Figure 1-1 “High
Availability Architecture. ”.
This architecture, which is typically implemented on one site
in a single data center, is sometimes called a local
cluster. For some installations, the level of protection
given by a local cluster is insufficient. Consider the order processing
center where power outages are common during harsh weather. Or consider
the systems running the stock market, where multiple system failures,
for any reason, have a significant financial impact. For these types
of installations, and many more like them, it is important to guard
not only against single points of failure, but against multiple
points of failure (MPOF), or against single massive
failures that cause many components to fail, such as the failure
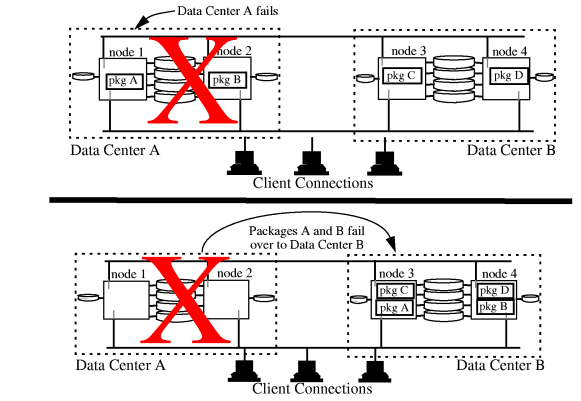
of a data center, of an entire site, or of a small area. A data
center, in the context of disaster recovery, is a physically
proximate collection of nodes and disks, usually all in one room.
Creating clusters that are resistant to multiple points of
failure or single massive failures requires a different type of
cluster architecture called a disaster
tolerant architecture. This architecture provides you
with the ability to fail over automatically to another part of the
cluster or manually to a different cluster after certain disasters.
Specifically, the disaster tolerant cluster provides appropriate
failover in the case where a disaster causes an entire data center
to fail, as shown in Figure 1-2 “Disaster
Tolerant Architecture ”.