
 |  |
8.6. Internationalization with XSLT
In this section, we explore the key techniques for internationalization (i18n) using XSLT. Although both Java and XSLT offer excellent support for i18n, pulling everything together into a working application is quite challenging. Hopefully this material will help to minimize some of the common obstacles.
8.6.1. XSLT Stylesheet Design
In its simplest form, i18n is accomplished by providing a separate XSLT stylesheet for each supported language. While this is easy to visualize, it results in far too much duplication of effort. This is because XSLT stylesheets typically contain some degree of programming logic in addition to pure display information. To illustrate this point, directory.xml is presented in Example 8-16. This is a very basic XML datafile that will be transformed using either English or Spanish XSLT stylesheets.
Example 8-16. directory.xml
<?xml version="1.0" encoding="UTF-8"?>
<directory>
<employee category="manager">
<name>Joe Smith</name>
<phone>4-0192</phone>
</employee>
<employee category="programmer">
<name>Sally Jones</name>
<phone>4-2831</phone>
</employee>
<employee category="programmer">
<name>Roger Clark</name>
<phone>4-3345</phone>
</employee>
</directory>The screen shot shown in Figure 8-6 shows how an XSLT stylesheet transforms this XML into HTML.
And finally, Example 8-17 lists the XSLT stylesheet that produces this output.
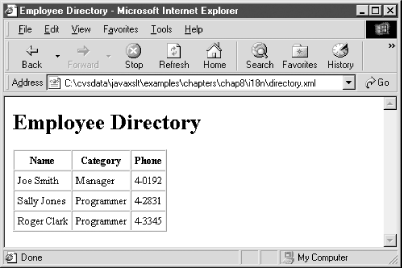
Figure 8-6. English XSLT output
Example 8-17. directory_basic.xslt
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" encoding="UTF-8"/>
<xsl:template match="/">
<html>
<head>
<title>Employee Directory</title>
</head>
<body>
<h1>Employee Directory</h1>
<table cellpadding="4" cellspacing="0" border="1">
<tr>
<th>Name</th>
<th>Category</th>
<th>Phone</th>
</tr>
<xsl:for-each select="directory/employee">
<tr>
<td>
<xsl:value-of select="name"/>
</td>
<td>
<xsl:choose>
<xsl:when test="@category='manager'">
<xsl:text>Manager</xsl:text>
</xsl:when>
<xsl:when test="@category='programmer'">
<xsl:text>Programmer</xsl:text>
</xsl:when>
<xsl:otherwise>
<xsl:text>Other</xsl:text>
</xsl:otherwise>
</xsl:choose>
</td>
<td>
<xsl:value-of select="phone"/>
</td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>In this stylesheet, all locale-specific content is highlighted. This is information that must be changed to support a different language. As you can see, only a small portion of the XSLT is specific to the English language and is embedded directly within the stylesheet logic. The entire stylesheet must be rewritten to support another language.
Fortunately, there is an easy solution to this problem. XSLT stylesheets can import other stylesheets; templates and variables in the importing stylesheet take precedence over conflicting items in the imported stylesheet. By isolating locale-specific content, we can use <xsl:import> to support multiple languages while reusing all of the stylesheet logic. Example 8-18 shows a revised version of our XSLT stylesheet.
Example 8-18. directory_en.xslt
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" encoding="UTF-8"/>
<!-- Isolate locale-specific content -->
<xsl:variable name="lang.pageTitle" select="'Employee Directory'"/>
<xsl:variable name="lang.nameHeading" select="'Name'"/>
<xsl:variable name="lang.categoryHeading" select="'Category'"/>
<xsl:variable name="lang.phoneHeading" select="'Phone'"/>
<xsl:variable name="lang.manager" select="'Manager'"/>
<xsl:variable name="lang.programmer" select="'Programmer'"/>
<xsl:variable name="lang.other" select="'Other'"/>
<xsl:template match="/">
<html>
<head>
<title><xsl:value-of select="$lang.pageTitle"/></title>
</head>
<body>
<h1><xsl:value-of select="$lang.pageTitle"/></h1>
<table cellpadding="4" cellspacing="0" border="1">
<tr>
<th><xsl:value-of select="$lang.nameHeading"/></th>
<th><xsl:value-of select="$lang.categoryHeading"/></th>
<th><xsl:value-of select="$lang.phoneHeading"/></th>
</tr>
<xsl:for-each select="directory/employee">
<tr>
<td>
<xsl:value-of select="name"/>
</td>
<td>
<xsl:choose>
<xsl:when test="@category='manager'">
<xsl:value-of select="$lang.manager"/>
</xsl:when>
<xsl:when test="@category='programmer'">
<xsl:value-of select="$lang.programmer"/>
</xsl:when>
<xsl:otherwise>
<xsl:value-of select="$lang.other"/>
</xsl:otherwise>
</xsl:choose>
</td>
<td>
<xsl:value-of select="phone"/>
</td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>The XSLT stylesheet is now much more amenable to i18n. All locale-specific content is declared as a series of variables. Therefore, importing stylesheets can override them. The lang. naming convention makes the stylesheet more maintainable; it is not a requirement or part of the XSLT specification. Other than isolating this content, the remainder of the stylesheet is exactly the same as it was before.
The Spanish version of the stylesheet is shown in Example 8-19.
Example 8-19. directory_es.xslt
<?xml version="1.0" encoding="UTF-8"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:import href="directory_en.xslt"/> <xsl:output method="html" encoding="UTF-8"/> <!-- Isolate locale-specific content --> <xsl:variable name="lang.pageTitle" select="'Empleado guía telefónica'"/> <xsl:variable name="lang.nameHeading" select="'Nombre'"/> <xsl:variable name="lang.categoryHeading" select="'Categoría'"/> <xsl:variable name="lang.phoneHeading" select="'Teléfono'"/> <xsl:variable name="lang.manager" select="'Gerente'"/> <xsl:variable name="lang.programmer" select="'Programador'"/> <xsl:variable name="lang.other" select="'Otro'"/> </xsl:stylesheet>
The Spanish stylesheet is much shorter because it merely overrides each of the locale-specific variables. The <xsl:import> is key:
<xsl:import href="directory_en.xslt"/>
Because of XSLT conflict-resolution rules, the variables defined in directory_es.xslt take precedence over those defined in directory_en.xslt. The same logic can be applied to templates, as well. This is useful in scenarios where the importing stylesheet needs to change behavior in addition to simply defining text translations.
The following line is optional:
<xsl:output method="html" encoding="UTF-8"/>
In this example, the output method and encoding are identical to the English version of the stylesheet, so this line has no effect. However, the importing stylesheet may specify a different output method and encoding if desired.
To perform the Spanish transformation using Xalan, issue the following command:
$ java org.apache.xalan.xslt.Process -IN directory.xml -XSL directory_es.xslt
Figure 8-7 shows the result of this transformation when displayed in a web browser.
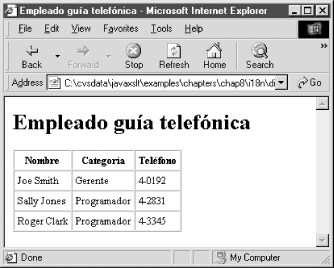
Figure 8-7. Spanish output
NOTE: In the i18n example stylesheets presented in this chapter, common functionality is placed into one stylesheet. Importing stylesheets then replace locale-specific text. This same technique can be applied to any stylesheet and is particularly important when writing custom XSLT for a specific browser. Most of your code should be portable across a variety of browsers and should be placed into reusable stylesheets. The parts that change should be placed into browser-specific stylesheets that import the common stylesheets.
8.6.2. Encodings
A character encoding is a numeric representation of a particular character.[41] The US-ASCII encoding for the A character, for example, is 65. When computers read and write files using US-ASCII encoding, each character is stored as one byte of data. Of this byte, only seven bits are actually used to represent characters. The first (most significant) bit must always be 0. Therefore, US-ASCII can represent only 128 different characters. Of course, this presents a problem for languages that require more than 128 characters. For these languages, another character encoding must be used.
[41] Refer to Java Internationalization by Andy Deitsch and David Czarnecki (O'Reilly) for more detailed information on character encodings.
The most comprehensive character encoding is called ISO/IEC 10646. This is also known as the Universal Character Set (UCS) and allocates a 32-bit number for each character. Although this allows UCS to uniquely identify every character in every language, it is not directly compatible with most computer software. Also, using 32 bits to represent each character results in a lot of wasted memory.
Unicode is the official implementation of ISO/IEC 10646 and currently uses 16-bit characters. You can learn more about Unicode at http://www.unicode.org. UCS Transformation Formats (UTFs) are designed to support the UCS encoding while maintaining compatibility with existing computer software and encodings. UTF-8 and UTF-16 are the most common transformation formats, and all XML parsers and XSLT processors are required to support both.
If you deal mostly with English text, UTF-8 is the most efficient and easiest to use. Because the first 128 UTF-8 characters are the same as the US-ASCII characters, existing applications can utilize many UTF-8 files transparently. When additional characters are required, however, UTF-8 encoding will use up to three bytes per character.
UTF-16 is more efficient than UTF-8 for Chinese, Japanese, and Korean (CJK) ideographs. When using UTF-16, each character requires two bytes, while many will require three bytes under UTF-8 encoding. Either UTF-8 or UTF-16 should work. However, it is wise to test actual transformations with both encodings to determine which results in the smallest file for your particular data. On a pragmatic note, many applications and operating systems, particularly Unix and Linux variants, offer better support for UTF-8 encoding.
As nearly every XSLT example in this book has shown, the <xsl:output> element determines the encoding of the XSLT result tree:
<xsl:output method="html" encoding="UTF-16"/>
If this element is missing from the stylesheet, the XSLT processor is supposed to default to either UTF-8 or UTF-16 encoding.[42]
[42] The XSLT specification does not say how the processor is supposed to select between UTF-8 and UTF-16.
8.6.2.1. Creating the XML and XSLT
The XML input data, XSLT stylesheet, and result tree do not have to use the same character encodings or language. For example, an XSLT stylesheet may be encoded in UTF-16, but may specify UTF-8 as its output method:
<?xml version="1.0" encoding="UTF-16"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="html" encoding="UTF-8"/> ...
Even though the first line specifies UTF-16, it is important that the text editor used to create this stylesheet actually uses UTF-16 encoding when saving the file. Otherwise, tools such as XML Spy (http://www.xmlspy.com) may report errors as shown in Figure 8-8.
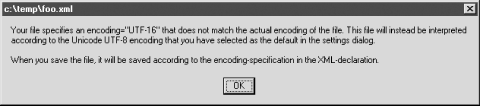
Figure 8-8. Error dialog
To further complicate matters, there are actually two variants of UTF-16. In UTF-16 Little Endian (UTF-16LE) encoding, the low byte of each two-byte character precedes the high byte. As expected, the high byte precedes the low byte in UTF-16 Big Endian (UTF-16BE) encoding. Fortunately, XML parsers can determine the encoding of a file by looking for a byte order mark. In UTF-16LE, the first byte of the file should start with 0xFFFE. In UTF-16BE files, the byte order mark is 0xFEFF.
For the upcoming Chinese example, the NJStar Chinese word processor (http://www.njstar.com) was used to input the Chinese characters. This is an example of an editor that has the ability to input ideographs and store files in various encodings. The Windows NT version of Notepad can save files in Unicode (UTF-16LE) format, and the Windows 2000 version of Notepad adds support for UTF-8 and UTF-16BE.
If all else fails, encoded text files can be created with Java using the java.io.OutputStreamWriter class as follows:
FileOutputStream fos = new FileOutputStream("myFile.xml");
// the OutputStreamWriter specifies the encoding of the file
PrintWriter pw = new PrintWriter(new OutputStreamWriter(fos, "UTF-16"));
...write to pw just like any other PrintWriter
pw.close( );8.6.3. Putting It All Together
Getting all of the pieces to work together is often the trickiest aspect of i18n. To demonstrate the concepts, we will now look at XML datafiles, XSLT stylesheets, and a servlet that work together to support any combination of English, Chinese, and Spanish. A basic HTML form makes it possible for users to select which XML file and XSLT stylesheet will be used to perform a transformation. The screen shot in Figure 8-9 shows what this web page looks like.
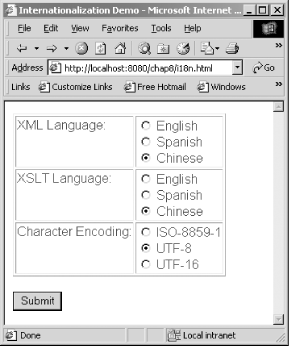
Figure 8-9. XML and XSLT language selection
As you can see, there are three versions of the XML data, one for each language. Other than the language, the three files are identical. There are also three versions of the XSLT stylesheet, and the user can select any combination of XML and XSLT language. The character encoding for the resulting transformation is also configurable. UTF-8 and UTF-16 are compatible with Unicode and can display the Spanish and Chinese characters directly. ISO-8859-1, however, can display only extended character sets using entities such as 文.
In this example, users explicitly specify their language preference. It is also possible to write a servlet that uses the Accept-Language HTTP header, which may contain a list of preferred languages:
en, es, ja
From this list, the application can attempt to select the appropriate language and character encoding without prompting the user. Chapter 13 of Java Servlet Programming, Second Edition by Jason Hunter (O'Reilly) presents a detailed discussion of this technique along with a class called LocaleNegotiator that maps more than 30 language codes to their appropriate character encodings.
In Figure 8-10, the results of three different transformations are displayed. In the first window, a Chinese XSLT stylesheet is applied to a Chinese XML datafile. In the second window, the English version of the XSLT stylesheet is applied to the Spanish XML data. Finally, the Spanish XSLT stylesheet is applied to the Chinese XML data.
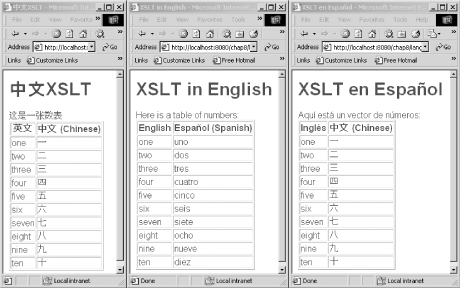
Figure 8-10. Several language combinations
The character encoding is generally transparent to the user. Switching to a different encoding makes no difference to the output displayed in Figure 8-10. However, it does make a difference when the page source is viewed. For example, when the output is UTF-8, the actual Chinese or Spanish characters are displayed in the source of the HTML page. When using ISO-8859-A, however, the source code looks something like this:
<html> <head> <META http-equiv="Content-Type" content="text/html; charset=ISO-8859-1"> <title>中文XSLT</title> </head> <body> <h1>中文XSLT</h1> ...remainder of page omitted
As you can see, the Chinese characters are replaced by their corresponding character entities, such as 中. The XSLT processor creates these entities automatically when the output encoding type cannot display the characters directly.
Browser Fonts
Recent versions of any major web browser can display UTF-8 and UTF-16 encoded characters without problems. Font configuration is the primary concern. If you are using Internet Explorer, be sure to select the View
Encoding
For the Chinese examples shown in this chapter, the Windows 2000 SimHei and SimSun fonts were installed. These and many other fonts are included with Windows 2000 but are not automatically installed unless the appropriate language settings are selected under the regional options window. This window can be found in the Windows 2000 Control Panel. A good source for font information on other versions of Windows is Fontboard at http://www.geocities.com/fontboard.
Sun Solaris users should start at the Sun Global Application Developer Corner web site at http://www.sun.com/developers/gadc/. This offers information on internationalization support in the latest versions of the Solaris operating system. For other versions of Unix or Linux, a good starting point is the Netscape 6 Help menu. The International Users option brings up a web page that provides numerous sources of fonts for various versions of Unix and Linux on which Netscape runs.
8.6.3.1. XML data
Each of the three XML datafiles used by this example follows the format shown in Example 8-20. As you can see, the XML data merely lists translations from English to another language. All three files follow the same naming convention: numbers_english.xml, numbers_spanish.xml, and numbers_chinese.xml.
Example 8-20. numbers_spanish.xml
<?xml version="1.0" encoding="UTF-8"?> <numbers> <language>Español (Spanish)</language> <number english="one">uno</number> <number english="two">dos</number> <number english="three">tres</number> <number english="four">cuatro</number> <number english="five">cinco</number> <number english="six">seis</number> <number english="seven">siete</number> <number english="eight">ocho</number> <number english="nine">nueve</number> <number english="ten">diez</number> </numbers>
8.6.3.2. XSLT stylesheets
The numbers_english.xslt stylesheet is shown in Example 8-21 and follows the same pattern that was introduced earlier in this chapter. Specifically, it isolates locale-specific data as a series of variables.
Example 8-21. numbers_english.xslt
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" encoding="UTF-8"/>
<xsl:variable name="lang.pageTitle">XSLT in English</xsl:variable>
<xsl:variable name="lang.tableCaption">
Here is a table of numbers:
</xsl:variable>
<xsl:variable name="lang.englishHeading">English</xsl:variable>
<xsl:template match="/">
<html>
<head>
<title><xsl:value-of select="$lang.pageTitle"/></title>
</head>
<body>
<xsl:apply-templates select="numbers"/>
</body>
</html>
</xsl:template>
<xsl:template match="numbers">
<h1><xsl:value-of select="$lang.pageTitle"/></h1>
<xsl:value-of select="$lang.tableCaption"/>
<table border="1">
<tr>
<th><xsl:value-of select="$lang.englishHeading"/></th>
<th>
<xsl:value-of select="language"/>
</th>
</tr>
<xsl:apply-templates select="number"/>
</table>
</xsl:template>
<xsl:template match="number">
<tr>
<td>
<xsl:value-of select="@english"/>
</td>
<td>
<xsl:value-of select="."/>
</td>
</tr>
</xsl:template>
</xsl:stylesheet>As you can see, the default output encoding of this stylesheet is UTF-8. This can (and will) be overridden by the servlet, however. The Spanish stylesheet, numbers_spanish.xslt, is shown in Example 8-22.
Example 8-22. numbers_spanish.xslt
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:import href="numbers_english.xslt"/>
<xsl:variable name="lang.pageTitle">XSLT en Español</xsl:variable>
<xsl:variable name="lang.tableCaption">
Aquí está un vector de números:
</xsl:variable>
<xsl:variable name="lang.englishHeading">Inglés</xsl:variable>
</xsl:stylesheet>The Chinese stylesheet, numbers_chinese.xslt, is not listed here because it is structured exactly like the Spanish stylesheet. In both cases, numbers_english.xslt is imported, and the three variables are overridden with language-specific text.
8.6.3.3. Web page and servlet
The user begins with the web page that was shown in Figure 8-9. The HTML source for this page is listed in Example 8-23. The language and encoding selections are posted to a servlet when the user clicks on the Submit button.
Example 8-23. i18n.html
<html>
<head>
<title>Internationalization Demo</title>
</head>
<body>
<form method="post" action="/chap8/languageDemo">
<table border="1">
<tr valign="top">
<td>XML Language:</td>
<td>
<input type="radio" name="xmlLanguage"
checked="checked" value="english"> English<br />
<input type="radio" name="xmlLanguage" value="spanish"> Spanish<br />
<input type="radio" name="xmlLanguage" value="chinese"> Chinese
</td>
</tr>
<tr valign="top">
<td>XSLT Language:</td>
<td>
<input type="radio" name="xsltLanguage"
checked="checked" value="english"> English<br />
<input type="radio" name="xsltLanguage" value="spanish"> Spanish<br />
<input type="radio" name="xsltLanguage" value="chinese"> Chinese
</td>
</tr>
<tr valign="top">
<td>Character Encoding:</td>
<td>
<input type="radio" name="charEnc" value="ISO-8859-1"> ISO-8859-1<br />
<input type="radio" name="charEnc" value="UTF-8"
checked="checked"> UTF-8<br />
<input type="radio" name="charEnc" value="UTF-16"> UTF-16<br />
</td>
</tr>
</table>
<p>
<input type="submit" name="submitBtn" value="Submit">
</p>
</form>
</body>
</html>The servlet, LanguageDemo.java, is shown in Example 8-24. This servlet accepts input from the i18n.html web page and then applies the XSLT transformation.
Example 8-24. LanguageDemo.java servlet
package chap8;
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
import javax.xml.transform.*;
import javax.xml.transform.stream.*;
/**
* Allows any combination of English, Spanish, and Chinese XML
* and XSLT.
*/
public class LanguageDemo extends HttpServlet {
public void doPost(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException {
ServletContext ctx = getServletContext( );
// these are all required parameters from the HTML form
String xmlLang = req.getParameter("xmlLanguage");
String xsltLang = req.getParameter("xsltLanguage");
String charEnc = req.getParameter("charEnc");
// convert to system-dependent path names
String xmlFileName = ctx.getRealPath(
"/WEB-INF/xml/numbers_" + xmlLang + ".xml");
String xsltFileName = ctx.getRealPath(
"/WEB-INF/xslt/numbers_" + xsltLang + ".xslt");
// do this BEFORE calling HttpServletResponse.getWriter( )
res.setContentType("text/html; charset=" + charEnc);
try {
Source xmlSource = new StreamSource(new File(xmlFileName));
Source xsltSource = new StreamSource(new File(xsltFileName));
TransformerFactory transFact = TransformerFactory.newInstance( );
Transformer trans = transFact.newTransformer(xsltSource);
trans.setOutputProperty(OutputKeys.ENCODING, charEnc);
// note: res.getWriter( ) will use the encoding type that was
// specified earlier in the call to res.setContentType( )
trans.transform(xmlSource, new StreamResult(res.getWriter( )));
} catch (TransformerConfigurationException tce) {
throw new ServletException(tce);
} catch (TransformerException te) {
throw new ServletException(te);
}
}
}After getting the three request parameters for XML, XSLT, and encoding, the servlet converts the XML and XSLT names to actual filenames:
String xmlFileName = ctx.getRealPath(
"/WEB-INF/xml/numbers_" + xmlLang + ".xml");
String xsltFileName = ctx.getRealPath(
"/WEB-INF/xslt/numbers_" + xsltLang + ".xslt");Because the XML files and XSLT stylesheets are named consistently, it is easy to determine the filenames. The next step is to set the content type of the response:
// do this BEFORE calling HttpServletResponse.getWriter( )
res.setContentType("text/html; charset=" + charEnc);This is a critical step that instructs the servlet container to send the response to the client using the specified encoding type. This gets inserted into the Content-Type HTTP response header, allowing the browser to determine which encoding to expect. In our example, the three possible character encodings result in the following possible content types:
Content-Type: text/html; charset=ISO-8869-1 Content-Type: text/html; charset=UTF-8 Content-Type: text/html; charset=UTF-16
Next, the servlet uses the javax.xml.transform.Source interface and the javax.xml.transform.stream.StreamSource class to read from the XML and XSLT files:
Source xmlSource = new StreamSource(new File(xmlFileName)); Source xsltSource = new StreamSource(new File(xsltFileName));
By using java.io.File, the StreamSource will correctly determine the encoding of the XML and XSLT files by looking at the XML declaration within each of the files. The StreamSource constructor also accepts InputStream or Reader as parameters. Special precautions must be taken with the Reader constructors, because Java Reader implementations use the default Java character encoding, which is determined when the VM starts up. The InputStreamReader is used to explicitly specify an encoding as follows:
Source xmlSource = new StreamSource(new InputStreamReader(
new FileInputStream(xmlFileName), "UTF-8"));For more information on how Java uses encodings, see the JavaDoc package description for the java.lang package.
Our servlet then overrides the XSLT stylesheet's output encoding as follows:
trans.setOutputProperty(OutputKeys.ENCODING, charEnc);
This takes precedence over the encoding that was specified in the <xsl:output> element shown earlier in Example 8-21.
Finally, the servlet performs the transformation, sending the result tree to a Writer obtained from HttpServletResponse:
// note: res.getWriter( ) will use the encoding type that was // specified earlier in the call to res.setContentType( ) trans.transform(xmlSource, new StreamResult(res.getWriter( )));
As the comment indicates, the servlet container should set up the Writer to use the correct character encoding, as specified by the Content-Type HTTP header.[43]
[43] UTF-16 works under Tomcat 3.2.x but fails under Tomcat 4.0 beta 5. Hopefully this will be addressed in later versions of Tomcat.
8.6.4. I18n Troubleshooting Checklist
Here are a few things to consider when problems occur. First, rule out obvious problems:
-
Visit a web site that uses the language you are trying to produce. For example, http://www.chinadaily.com.cn/ has an option to view the site in Chinese. This will confirm that your browser loads the correct fonts.
-
Test your application with English XML data and XSLT stylesheets to verify that the transformations are performed correctly.
-
Perform the XSLT transformation on the command line. Save the result to a file and view with a Unicode-compatible text editor. If all else fails, view with a binary editor to see how the characters are being encoded.
-
Verify that your XML parser supports the encodings you are trying to parse.[44]
[44] Encoding supported by Apache's Xerces parser are documented at http://xml.apache.org/xerces-j/faq-general.html.
If these tests do not uncover the problem, try the following:
-
Stick with UTF-8 encoding until problems are resolved. This is the most compatible encoding.
-
Verify that the servlet sets the Content-Type header to:
Content-Type: text/html; charset=UTF-8
-
Verify that the XSLT stylesheet sets the appropriate encoding on the <xsl:output> element or override the encoding programmatically:
transformer.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
|  | |
| 8.5. XSLT as a Code Generator |  | 9. Development Environment, Testing, and Performance |

Copyright © 2002 O'Reilly & Associates. All rights reserved.