|
Chapter 8 Process Handling |

|
8.5 Coroutines
We've spent the last several pages on almost microscopic details of process behavior. Rather than continue our descent into the murky depths, we'll revert to a higher-level view of processes.
Earlier in this chapter, we covered ways of controlling multiple simultaneous jobs within an interactive login session; now we'll consider multiple process control within shell programs. When two (or more) processes are explicitly programmed to run simultaneously and possibly communicate with each other, we call them coroutines .
This is actually nothing new: a pipeline is an example of coroutines. The shell's pipeline construct encapsulates a fairly sophisticated set of rules about how processes interact with each other. If we take a closer look at these rules, we'll be better able to understand other ways of handling coroutines-most of which turn out to be simpler than pipelines.
When you invoke a simple pipeline, say ls | more , the shell invokes a series of UNIX primitive operations, a.k.a. system calls . In effect, the shell tells UNIX to do the following things; in case you're interested, we include in parentheses the actual system call used at each step:
Create two subprocesses, which we'll call P1 and P2 (the fork system call).
Set up I/O between the processes so that P1's standard output feeds into P2's standard input (pipe ).
Start /bin/ls in process P1 (exec ).
Start /bin/more in process P2 (exec ).
Wait for both processes to finish (wait ).
You can probably imagine how the above steps change when the pipeline involves more than two processes.
Now let's make things simpler. We'll see how to get multiple processes to run at the same time if the processes do not need to communicate. For example, we want the processes dave and bob to run as coroutines, without communication, in a shell script. Our initial solution would be this:
dave & bob
Assume for the moment that bob is the last command in the script. The above will work-but only if dave finishes first. If dave is still running when the script finishes, then it becomes an orphan , i.e., it enters one of the "funny states" we mentioned earlier in this chapter. Never mind the details of orphanhood; just believe that you don't want this to happen, and if it does, you may need to use the "runaway process" method of stopping it, discussed earlier in this chapter.
8.5.1 wait
There is a way of making sure the script doesn't finish before dave does: the built-in command wait . Without arguments, wait simply waits until all background jobs have finished. So to make sure the above code behaves properly, we would add wait , like this:
dave & bob wait
Here, if bob finishes first, the parent shell will wait for dave to finish before finishing itself.
If your script has more than one background job and you need to wait for specific ones to finish, you can give wait the same type of job argument (with a percent sign) as you would use with kill , fg , or bg .
However, you will probably find that wait without arguments suffices for all coroutines you will ever program. Situations in which you would need to wait for specific background jobs are quite complex and beyond the scope of this book.
8.5.2 Advantages and Disadvantages of Coroutines
In fact, you may be wondering why you would ever need to program coroutines that don't communicate with each other. For example, why not just run bob after dave in the usual way? What advantage is there in running the two jobs simultaneously?
If you are running on a computer with one processor (CPU), then there is a performance advantage-but only if you have the bgnice option turned off (see Chapter 3, Customizing Your Environment ), and even then only in certain situations.
Roughly speaking, you can characterize a process in terms of how it uses system resources in three ways: whether it is CPU intensive (e.g., does lots of number crunching), I/O intensive (does a lot of reading or writing to the disk), or interactive (requires user intervention).
We already know from Chapter 1 that it makes no sense to run an interactive job in the background. But apart from that, the more two or more processes differ with respect to these three criteria, the more advantage there is in running them simultaneously. For example, a number-crunching statistical calculation would do well when running at the same time as a long, I/O-intensive database query.
On the other hand, if two processes use resources in similar ways, it may even be less efficient to run them at the same time as it would be to run them sequentially. Why? Basically, because under such circumstances, the operating system often has to "time-slice" the resource(s) in contention.
For example, if both processes are "disk hogs," the operating system may enter a mode where it constantly switches control of the disk back and forth between the two competing processes; the system ends up spending at least as much time doing the switching as it does on the processes themselves. This phenomenon is known as thrashing ; at its most severe, it can cause a system to come to a virtual standstill. Thrashing is a common problem; system administrators and operating system designers both spend lots of time trying to minimize it.
8.5.3 Parallelization
But if you have a computer with multiple CPUs (such as a Pyramid, Sequent, or Sun MP), you should be less concerned about thrashing. Furthermore, coroutines can provide dramatic increases in speed on this type of machine, which is often called a parallel computer; analogously, breaking up a process into coroutines is sometimes called parallelizing the job.
Normally, when you start a background job on a multiple-CPU machine, the computer will assign it to the next available processor. This means that the two jobs are actually-not just metaphorically-running at the same time.
In this case, the running time of the coroutines is essentially equal to that of the longest-running job plus a bit of overhead, instead of the sum of the run times of all processes (although if the CPUs all share a common disk drive, the possibility of I/O-related thrashing still exists). In the best case-all jobs having the same run time and no I/O contention-you get a speedup factor equal to the number of jobs.
Parallelizing a program is often not easy; there are several subtle issues involved and there's plenty of room for error. Nevertheless, it's worthwhile to know how to parallelize a shell script whether or not you have a parallel machine, especially since such machines are becoming more and more common.
We'll show how to do this-and give you an idea of some of the problems involved-by means of a simple task whose solution is amenable to parallelization.
Task 8.3
Write a utility that allows you to make multiple copies of a file at the same time.
We'll call this script mcp . The command mcp filename dest1 dest2 ... should copy filename to all of the destinations given. The code for this should be fairly obvious:
file=$1
shift
for dest in "$@"; do
cp $file $dest
done
Now let's say we have a parallel computer and we want this command to run as fast as possible. To parallelize this script, it's a simple matter of firing off the cp commands in the background and adding a wait at the end:
file=$1
shift
for dest in "$@"; do
cp $file $dest &
done
wait
Simple, right? Well, there is one little problem: what happens if the user specifies duplicate destinations? If you're lucky, the file just gets copied to the same place twice. Otherwise, the identical cp commands will interfere with each other, possibly resulting in a file that contains two interspersed copies of the original file. In contrast, if you give the regular cp command two arguments that point to the same file, it will print an error message and do nothing.
To fix this problem, we would have to write code that checks the argument list for duplicates. Although this isn't too hard to do (see the exercises at the end of this chapter), the time it takes that code to run might offset any gain in speed from parallelization; furthermore, the code that does the checking detracts from the simple elegance of the script.
As you can see, even a seemingly trivial parallelization task has problems resulting from multiple processes having concurrent access to a given system resource (a file in this case). Such problems, known as concurrency control issues, become much more difficult as the complexity of the application increases. Complex concurrent programs often have much more code for handling the special cases than for the actual job the program is supposed to do!
Therefore it shouldn't surprise you that much research has been and is being done on parallelization, the ultimate goal being to devise a tool that parallelizes code automatically. (Such tools do exist; they usually work in the confines of some narrow subset of the problem.) Even if you don't have access to a multiple-CPU machine, parallelizing a shell script is an interesting exercise that should acquaint you with some of the issues that surround coroutines.
8.5.4 Coroutines with Two-way Pipes
Now that we have seen how to program coroutines that don't communicate with each other, we'll build on that foundation and discuss how to get them to communicate-in a more sophisticated way than with a pipeline. The Korn shell has a set of features that allow programmers to set up two-way communication between coroutines. These features aren't included in most Bourne shells.
If you start a background process by appending |& to a command instead of & , the Korn shell will set up a special two-way pipeline between the parent shell and the new background process. read -p in the parent shell reads a line of the background process' standard output; similarly, print -p in the parent shell feeds into the standard input of the background process. Figure 8.2 shows how this works.
Figure 8.2: Coroutine I/O
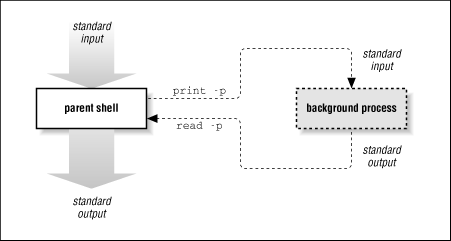
This scheme has some intriguing possibilities. Notice the following things: first, the parent shell communicates with the background process independently of its own standard input and output. Second, the background process need not have any idea that a shell script is communicating with it in this manner. This means that the background process can be any pre-existing program that uses its standard input and output in normal ways.
Here's a task that shows a simple example:
Task 8.4
You would like to have an online calculator, but the existing UNIX utility dc (1) uses Reverse Polish Notation (RPN), a la Hewlett-Packard calculators. You'd rather have one that works like the $3.95 model you got with that magazine subscription. Write a calculator program that accepts standard algebraic notation.
The objective here is to write the program without re-implementing the calculation engine that dc already has-in other words, to write a program that translates algebraic notation to RPN and passes the translated line to dc to do the actual calculation. [12]
[12] The utility bc (1) actually provides similar functionality.
We'll assume that the function alg2rpn , which does the translation, already exists: given a line of algebraic notation as argument, it prints the RPN equivalent on the standard output. If we have this, then the calculator program (which we'll call adc ) is very simple:
dc |&
while read line'?adc> '; do
print -p "$(alg2rpn $line)"
read -p answer
print " = $answer"
done
The first line of this code starts dc as a coroutine with a two-way pipe. Then the while loop prompts the user for a line and reads it until the user types [CTRL-D] for end-of-input. The loop body converts the line to RPN, passes it to dc through the pipe, reads dc 's answer, and prints it after an equal sign. For example:
$ adc
adc> 2 + 3
= 5
adc> (7 * 8) + 54
= 110
adc> ^D
$
Actually-as you may have noticed-it's not entirely necessary to have a two-way pipe with dc . You could do it with a standard pipe and let dc do its own output, like this:
{ while read line'?adc> '; do
print "$(alg2rpn $line)"
done
} | dc
The only difference from the above is the lack of equal sign before each answer is printed.
But: what if you wanted to make a fancy graphical user interface (GUI), like the xcalc program that comes with many X Window System installations? Then, clearly, dc 's own output would not be satisfactory, and you would need full control of your own standard output in the parent process. The user interface would have to capture dc 's output and display it in the window properly. The two-way pipe is an excellent solution to this problem: just imagine that, instead of print " = $answer ", there is a call to a routine that displays the answer in the "readout" section of the calculator window.
All of this suggests that the two-way pipe scheme is great for writing shell scripts that interpose a software layer between the user (or some other program) and an existing program that uses standard input and output. In particular, it's great for writing new interfaces to old, standard UNIX programs that expect line-at-a-time, character-based user input and output. The new interfaces could be GUIs, or they could be network interface programs that talk to users over links to remote machines. In other words, the Korn shell's two-way pipe construct is designed to help develop very up-to-date software!
8.5.5 Two-way Pipes Versus Standard Pipes
Before we leave the subject of coroutines, we'll complete the circle by showing how the two-way pipe construct compares to regular pipelines. As you may have been able to figure out by now, it is possible to program a standard pipeline by using |& with print -p .
This has the advantage of reserving the parent shell's standard output for other use. The disadvantage is that the child process' standard output is directed to the two-way pipe: if the parent process doesn't read it with read -p , then it's effectively lost.
|
|

|
|
| 8.4 trap | 
|
8.6 Subshells |