
 |  |
1.9. Canonicalizing Strings with Unicode Combined Characters
1.9.1. Problem
You have two strings that look the same when you print them out, but they don't test as string equal and sometimes even have different lengths. How can you get Perl to consider them the same strings?
1.9.2. Solution
When you have otherwise equivalent strings, at least some of which contain Unicode combining character sequences, instead of comparing them directly, compare the results of running them through the NFD( ) function from the Unicode::Normalize module.
use Unicode::Normalize;
$s1 = "fa\x{E7}ade";
$s2 = "fac\x{0327}ade";
if (NFD($s1) eq NFD($s2)) { print "Yup!\n" }1.9.3. Discussion
The same character sequence can sometimes be specified in multiple ways. Sometimes this is because of legacy encodings, such as the letters from Latin1 that contain diacritical marks. These can be specified directly with a single character (like U+00E7, LATIN SMALL LETTER C WITH CEDILLA) or indirectly via the base character (like U+0063, LATIN SMALL LETTER C) followed by a combining character (U+0327, COMBINING CEDILLA).
Another possibility is that you have two or more marks following a
base character, but the order of those marks varies in your data.
Imagine you wanted the letter "c" to have both a cedilla and a caron
on top of it in order to print a 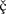 . That could be specified in any of these ways:
. That could be specified in any of these ways:
$string = v231.780; # LATIN SMALL LETTER C WITH CEDILLA # COMBINING CARON $string = v99.807.780; # LATIN SMALL LETTER C # COMBINING CARON # COMBINING CEDILLA $string = v99.780.807 # LATIN SMALL LETTER C # COMBINING CEDILLA # COMBINING CARON
The normalization
functions rearrange those into a reliable ordering. Several are
provided, including NFD( ) for canonical
decomposition and NFC( ) for canonical
decomposition followed by canonical composition. No matter which of
these three ways you used to specify your , the NFD version is v99.807.780, whereas the NFC version is v231.780.
Sometimes you may prefer NFKD( ) and NFKC( ), which are like the previous two functions except that they perform compatible decomposition, which for NFKC( ) is then followed by canonical composition. For example, \x{FB00} is the double-f ligature. Its NFD and NFC forms are the same thing, "\x{FB00}", but its NFKD and NFKC forms return a two-character string, "\x{66}\x{66}".
1.9.4. See Also
The Universal Character Code section at the beginning of this chapter; the documentation for the Unicode::Normalize module; Recipe 8.20
|  | |
| 1.8. Treating Unicode Combined Characters as Single Characters |  | 1.10. Treating a Unicode String as Octets |

Copyright © 2003 O'Reilly & Associates. All rights reserved.