
15.2. Effects of Character Semantics
The upshot of all this is that a typical built-in operator will operate on characters unless it is in the scope of a use bytes pragma. However, even outside the scope of use bytes, if all of the operands of the operator are stored as 8-bit characters (that is, none of the operands are stored in utf8), then character semantics are indistinguishable from byte semantics, and the result of the operator will be stored in 8-bit form internally. This preserves backward compatibility as long as you don't feed your program any characters wider than Latin-1.
The utf8 pragma is primarily a compatibility device that enables recognition of UTF-8 in literals and identifiers encountered by the parser. It may also be used for enabling some of the more experimental Unicode support features. Our long-term goal is to turn the utf8 pragma into a no-op.
The use bytes pragma will never turn into a no-op. Not only is it necessary for byte-oriented code, but it also has the side effect of defining byte-oriented wrappers around certain functions for use outside the scope of use bytes. As of this writing, the only defined wrapper is for length, but there are likely to be more as time goes by. To use such a wrapper, say:
use bytes (); # Load wrappers without importing byte semantics.
...
$charlen = length("\x{ffff_ffff}"); # Returns 1.
$bytelen = bytes::length("\x{ffff_ffff}"); # Returns 7.
Outside the scope of a use bytes declaration, Perl version 5.6 works (or
at least, is intended to work) like this:
-
Strings and patterns may now contain characters that have an ordinal value larger than 255:
Presuming you have a Unicode-capable editor to edit your program, such characters will typically occur directly within the literal strings as UTF-8 characters. For now, you have to declare a use utf8 at the top of your program to enable the use of UTF-8 in literals.use utf8; $convergence = "
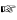
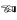 ";
";If you don't have a Unicode editor, you can always specify a particular character in ASCII with an extension of the \x notation. A character in the Latin-1 range may be written either as \x{ab} or as \xab, but if the number exceeds two hexidecimal digits, you must use braces. Unicode characters are specified by putting the hexadecimal code within braces after the \x. For instance, a Unicode smiley face is \x{263A}. There is no syntactic construct in Perl that assumes Unicode characters are exactly 16 bits, so you may not use \u263A as you can in other languages; \x{263A} is the closest equivalent.
For inserting named characters via \N{CHARNAME}, see the use charnames pragma in Chapter 31, "Pragmatic Modules".
-
Identifiers within the Perl script may contain Unicode alphanumeric characters, including ideographs:
Again, use utf8 is needed (for now) to recognize UTF-8 in your script. You are currently on your own when it comes to using the canonical forms of characters--Perl doesn't (yet) attempt to canonicalize variable names for you. We recommend that you canonicalize your programs to Normalization Form C, since that's what Perl will someday canonicalize to by default. See www.unicode.org for the latest technical report on canonicalization.use utf8; $
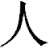 ++; # A child is born.
++; # A child is born. -
Regular expressions match characters instead of bytes. For instance, dot matches a character instead of a byte. If the Unicode Consortium ever gets around to approving the Tengwar script, then (despite the fact that such characters are represented in four bytes of UTF-8), this matches:
The \C pattern is provided to force a match on a single byte ("char" in C, hence \C). Use \C with care, since it can put you out of sync with the character boundaries in your string, and you may get "Malformed UTF-8 character" errors. You may not use \C in square brackets, since it doesn't represent any particular character or set of characters."\N{TENGWAR LETTER SILME NUQUERNA}" =~ /^.$/ -
Character classes in regular expressions match characters instead of bytes and match against the character properties specified in the Unicode properties database. So \w can be used to match an ideograph:
"
" =~ /\w/ -
Named Unicode properties and block ranges can be used as character classes via the new \p (matches property) and \P (doesn't match property) constructs. For instance, \p{Lu} matches any character with the Unicode uppercase property, while \p{M} matches any mark character. Single-letter properties may omit the brackets, so mark characters can be matched by \pM also. Many predefined character classes are available, such as \p{IsMirrored} and \p{InTibetan}:
You may also use \p and \P within square bracket character classes. (In version 5.6.0 of Perl, you need to use utf8 for character properties to work right. This restriction will be lifted in the future.) See Chapter 5, "Pattern Matching", for details of matching on Unicode properties."\N{greek:Iota}" =~ /\p{Lu}/ -
The special pattern \X matches any extended Unicode sequence (a "combining character sequence" in Standardese), where the first character is a base character and subsequent characters are mark characters that apply to the base character. It is equivalent to (?:\PM\pM*):
You may not use \X in square brackets, because it might match multiple characters and it doesn't match any particular character or set of characters."o\N{COMBINING TILDE BELOW}" =~ /\X/ -
The tr/// operator transliterates characters instead of bytes. To turn all characters outside the Latin-1 range into a question mark, you could say:
tr/\0-\x{10ffff}/\0-\xff?/; # utf8 to latin1 char -
Case translation operators use the Unicode case translation tables when provided character input. Note that uc translates to uppercase, while ucfirst translates to titlecase (for languages that make the distinction). Naturally the corresponding backslash sequences have the same semantics:
Be careful, because the Unicode case translation tables don't attempt to provide round-trip mappings in every instance, particularly for languages that use different numbers of characters for titlecase or uppercase than they do for the equivalent lowercase letter. As they say in the standard, while the case properties themselves are normative, the case mappings are only informational.$x = "\u$word"; # titlecase first letter of $word $x = "\U$word"; # uppercase $word $x = "\l$word"; # lowercase first letter of $word $x = "\L$word"; # lowercase $word
-
Most operators that deal with positions or lengths in the string will automatically switch to using character positions, including chop, substr, pos, index, rindex, sprintf, write, and length. Operators that deliberately don't switch include vec, pack, and unpack. Operators that really don't care include chomp, as well as any other operator that treats a string as a bucket of bits, such as the default sort and the operators dealing with filenames.
use bytes; $bytelen = length("I do

 ."); # 15 bytes
no bytes;
$charlen = length("I do ."); # but 9 characters
."); # 15 bytes
no bytes;
$charlen = length("I do ."); # but 9 characters -
The pack/unpack letters "c" and "C" do not change, since they're often used for byte-oriented formats. (Again, think "char" in the C language.) However, there is a new "U" specifier that will convert between UTF-8 characters and integers:
pack("U*", 1, 20, 300, 4000) eq v1.20.300.4000 -
The chr and ord functions work on characters:
In other words, chr and ord are like pack("U") and unpack("U"), not like pack("C") and unpack("C"). In fact, the latter two are how you now emulate byte-oriented chr and ord if you're too lazy to use bytes.chr(1).chr(20).chr(300).chr(4000) eq v1.20.300.4000
-
And finally, scalar reverse reverses by character rather than by byte:
"
" eq reverse " "
If you look in directory PATH_TO_PERLLIB/unicode, you'll find a number of files that have to do with defining the semantics above. The Unicode properties database from the Unicode Consortium is in a file called Unicode.300 (for Unicode 3.0). This file has already been processed by mktables.PL into lots of little .pl files in the same directory (and in subdirectories Is/, In/, and To/), some of which are automatically slurped in by Perl to implement things like \p (see the Is/ and In/ directories) and uc (see the To/ directory). Other files are slurped in by modules like the use charnames pragma (see Name.pl). But as of this writing, there are still a number of files that are just sitting there waiting for you to write an access module for them:
A much more readable summary of Unicode, with many hyperlinks, is in PATH_TO_PERLLIB/unicode/Unicode3.html.ArabLink.pl ArabLnkGrp.pl Bidirectional.pl Block.pl Category.pl CombiningClass.pl Decomposition.pl JamoShort.pl Number.pl To/Digit.pl
Note that when the Unicode consortium comes out with a new version, some of these filenames are likely to change, so you'll have to poke around. You can find PATH_TO_PERLLIB with the following incantation:
% perl -MConfig -le 'print $Config{privlib}'
To find out just about everything there is to find out about Unicode, you
should check out The Unicode Standard, Version 3.0
(ISBN 0-201-61633-5).
 |  |  |
| 15.1. Building Character |  | 15.3. Caution, Working |

Copyright © 2002 O'Reilly & Associates. All rights reserved.