
6.4. Prototypes
Perl lets you define your own functions to be called like Perl's built-in functions. Consider push(@array, $item), which must tacitly receive a reference to @array, not just the list values held in @array, so that the array can be modified. Prototypes let you declare subroutines to take arguments just like many of the built-ins, that is, with certain constraints on the number and types of arguments. We call them "prototypes", but they work more like automatic templates for the calling context than like what C or Java programmers would think of as prototypes. With these templates, Perl will automatically add implicit backslashes, or calls to scalar, or whatever else it takes to get things to show up in a way that matches the template. For instance, if you declare:
then mypush takes arguments exactly like push does. For this to work, the declaration of the function to be called must be visible at compile time. The prototype only affects the interpretation of function calls when the & character is omitted. In other words, if you call it like a built-in function, it behaves like a built-in function. If you call it like an old-fashioned subroutine, then it behaves like an old-fashioned subroutine. The & suppresses prototype checks and associated contextual effects.sub mypush (\@@);
Since prototypes are taken into consideration only at compile time, it naturally falls out that they have no influence on subroutine references like \&foo or on indirect subroutine calls like &{$subref} or $subref->(). Method calls are not influenced by prototypes, either. That's because the actual function to be called is indeterminate at compile time, depending as it does on inheritance, which is dynamically determined in Perl.
Since the intent is primarily to let you define subroutines that work like built-in functions, here are some prototypes you might use to emulate the corresponding built-ins:
| Declared as | Called as |
|---|---|
| sub mylink ($$) | mylink $old, $new |
| sub myreverse (@) | myreverse $a,$b,$c |
| sub myjoin ($@) | myjoin ":",$a,$b,$c |
| sub mypop (\@) | mypop @array |
| sub mysplice (\@$$@) | mysplice @array,@array,0,@pushme |
| sub mykeys (\%) | mykeys %{$hashref} |
| sub mypipe (**) | mypipe READHANDLE, WRITEHANDLE |
| sub myindex ($$;$) | myindex &getstring, "substr" |
| myindex &getstring, "substr", $start | |
| sub mysyswrite (*$;$$) | mysyswrite OUTF, $buf |
| mysyswrite OUTF, $buf, length($buf)-$off, $off | |
| sub myopen (*;$@) | myopen HANDLE |
| myopen HANDLE, $name | |
| myopen HANDLE, "-|", @cmd | |
| sub mygrep (&@) | mygrep { /foo/ } $a,$b,$c |
| sub myrand ($) | myrand 42 |
| sub mytime () | mytime |
Any backslashed prototype character (shown between parentheses in the left column above) represents an actual argument (exemplified in the right column), which absolutely must start with that character. Just as the first argument to keys must start with %, so too must the first argument to mykeys.
A semicolon separates mandatory arguments from optional arguments. (It would be redundant before @ or %, since lists can be null.) Unbackslashed prototype characters have special meanings. Any unbackslashed @ or % eats all the rest of the actual arguments and forces list context. (It's equivalent to LIST in a syntax description.) An argument represented by $ has scalar context forced on it. An & requires a reference to a named or anonymous subroutine.
A * allows the subroutine to accept anything in that slot that would be accepted by a built-in as a filehandle: a bare name, a constant, a scalar expression, a typeglob, or a reference to a typeglob. The value will be available to the subroutine either as a simple scalar or (in the latter two cases) as a reference to the typeglob. If you wish to always convert such arguments to a typeglob reference, use Symbol::qualify_to_ref as follows:
use Symbol 'qualify_to_ref';
sub foo (*) {
my $fh = qualify_to_ref(shift, caller);
...
}
Note how the last three examples in the table are treated
specially by the parser. mygrep is parsed as a true list operator,
myrand is parsed as a true unary operator with unary precedence
the same as rand, and mytime is truly argumentless, just like
time.
That is, if you say:
you'll get mytime() + 2, not mytime(2), which is how it would be parsed without the prototype, or with a unary prototype.mytime +2;
The mygrep example also illustrates how & is treated specially when it is the first argument. Ordinarily, an & prototype would demand an argument like \&foo or sub{}. When it is the first argument, however, you can leave off the sub of your anonymous subroutine, and just pass a bare block in the "indirect object" slot (with no comma after it). So one nifty thing about the & prototype is that you can generate new syntax with it, provided the & is in the initial position:
sub try (&$) {
my ($try, $catch) = @_;
eval { &$try };
if ($@) {
local $_ = $@;
&$catch;
}
}
sub catch (&) { $_[0] }
try {
die "phooey";
} # not the end of the function call!
catch {
/phooey/ and print "unphooey\n";
};
This prints "unphooey". What happens is that
try is called with two arguments, the anonymous
function {die "phooey";} and the return
value of the catch function, which in this case is
nothing but its own argument, the entire block of yet another
anonymous function. Within try, the first function
argument is called while protected within an eval
block to trap anything that blows up. If something does blow up, the
second function is called with a local version of the global
$_ variable set to the raised
exception.[3] If this all
sounds like pure gobbledygook, you'll have to read about
die and eval in Chapter 29, "Functions", and then go check out anonymous
functions and closures in Chapter 8, "References". On
the other hand, if it intrigues you, you might check out the
Error module on CPAN, which uses this to implement
elaborately structured exception handling with try,
catch, except,
otherwise, and finally clauses.
[3] Yes, there are still unresolved issues having to do with the visibility of @_. We're ignoring that question for the moment. But if we make @_ lexically scoped someday, as already occurs in the experimental threaded versions of Perl, those anonymous subroutines can act like closures.
Here's a reimplementation of the grep operator (the built-in one is more efficient, of course):
sub mygrep (&@) {
my $coderef = shift;
my @result;
foreach $_ (@_) {
push(@result, $_) if &$coderef;
}
return @result;
}
Some folks would prefer to see full alphanumeric prototypes.
Alphanumerics have been intentionally left out of prototypes for the
express purpose of someday adding named, formal parameters. (Maybe.)
The current mechanism's main goal is to let module writers enforce a
certain amount of compile-time checking on module users.
6.4.1. Inlining Constant Functions
Functions prototyped with (), meaning that they take no arguments at all, are parsed like the time built-in. More interestingly, the compiler treats such functions as potential candidates for inlining. If the result of that function, after Perl's optimization and constant-folding pass, is either a constant or a lexically scoped scalar with no other references, then that value will be used in place of calls to that function. Calls made using &NAME are never inlined, however, just as they are not subject to any other prototype effects. (See the use constant pragma in Chapter 31, "Pragmatic Modules", for an easy way to declare such constants.)
Both version of these functions to compute 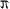 will be inlined
by the compiler:
will be inlined
by the compiler:
sub pi () { 3.14159 } # Not exact, but close
sub PI () { 4 * atan2(1, 1) } # As good as it gets
In fact, all of the following functions are inlined because Perl can
determine everything at compile time:
sub FLAG_FOO () { 1 << 8 }
sub FLAG_BAR () { 1 << 9 }
sub FLAG_MASK () { FLAG_FOO | FLAG_BAR }
sub OPT_GLARCH () { (0x1B58 & FLAG_MASK) == 0 }
sub GLARCH_VAL () {
if (OPT_GLARCH) { return 23 }
else { return 42 }
}
sub N () { int(GLARCH_VAL) / 3 }
BEGIN { # compiler runs this block at compile time
my $prod = 1; # persistent, private variable
for (1 .. N) { $prod *= $_ }
sub NFACT () { $prod }
}
In the last example, the NFACT function is inlined because it has a
void prototype and the variable it returns is not changed by that
function--and furthermore can't be changed by anyone else, since it's
in a lexical scope. So the compiler replaces uses of NFACT with
that value, which was precomputed at compile time because of the
surrounding BEGIN.
If you redefine a subroutine that was eligible for inlining, you'll get a mandatory warning. (You can use this warning to tell whether the compiler inlined a particular subroutine.) The warning is considered severe enough not to be optional, because previously compiled invocations of the function will still use the old value of the function. If you need to redefine the subroutine, ensure that it isn't inlined either by dropping the () prototype (which changes calling semantics, so beware) or by thwarting the inlining mechanism in some other way, such as:
sub not_inlined () {
return 23 if $$;
}
See Chapter 18, "Compiling" for more about what happens
during the compilation and execution phases of your program's
life.
6.4.2. Care with Prototypes
It's probably best to put prototypes on new functions, not retrofit prototypes onto older ones. These are context templates, not ANSI C prototypes, so you must be especially careful about silently imposing a different context. Suppose, for example, you decide that a function should take just one parameter, like this:
sub func ($) {
my $n = shift;
print "you gave me $n\n";
}
That makes it a unary operator (like the rand built-in)
and changes how the compiler determines the function's arguments. With the
new prototype, the function consumes just one, scalar-context
argument instead of many arguments in list context. If someone has
been calling it with an array or list expression, even if that array
or list contained just a single element, where before it worked,
now you've got something completely different:
func @foo; # counts @foo elements
func split /:/; # counts number of fields returned
func "a", "b", "c"; # passes "a" only, discards "b" and "c"
func("a", "b", "c"); # suddenly, a compiler error!
You've just supplied an implicit scalar in front of the
argument list, which can be more than a bit surprising. The old @foo
that used to hold one thing doesn't get passed in. Instead, 1 (the
number of elements in @foo) is now passed to func. And the
split, being called in scalar context, scribbles all over your
@_ parameter list. In the third example, because func has been
prototyped as a unary operator, only "a" is passed in; then the
return value from func is discarded as the comma operator goes on
to evaluate the next two items and return "c." In the final
example, the user now gets a syntax error at compile time on code that
used to compile and run just fine.
If you're writing new code and would like a unary operator that takes only a scalar variable, not any old scalar expression, you could prototype it to take a scalar reference:
sub func (\$) {
my $nref = shift;
print "you gave me $$nref\n";
}
Now the compiler won't let anything by that doesn't start with a
dollar sign:
func @foo; # compiler error, saw @, want $
func split/:/; # compiler error, saw function, want $
func $s; # this one is ok -- got real $ symbol
func $a[3]; # and this one
func $h{stuff}[-1]; # or even this
func 2+5; # scalar expr still a compiler error
func ${ \(2+5) }; # ok, but is the cure worse than the disease?
If you aren't careful, you can get yourself into trouble with
prototypes. But if you are careful, you can do a lot of neat things
with them. This is all very powerful, of course, and should only be
used in moderation to make the world a better place.
 |  |  |
| 6.3. Passing References |  | 6.5. Subroutine Attributes |

Copyright © 2001 O'Reilly & Associates. All rights reserved.