|
|
15.1 Understanding NFSUsing NFS, clients can mount partitions of a server as if they were physically connected to the client. In addition to allowing remote access to files over the network, NFS allows many (relatively) low-cost computer systems to share the same high-capacity disk drive at the same time. NFS clients and servers have been written for many different operating systems. NFS is nearly transparent. In practice, a workstation user simply logs into the workstation and begins working, accessing it as if the files were locally stored. In many environments, workstations are set up to mount the disks on the server automatically at boot time or when files on the disk are first referenced. NFS also has a network-mounting program that can be configured to mount the NFS disk automatically when an attempt is made to access files stored on remote disks. There are several basic security problems with NFS:
One of the key design features behind NFS is the concept of server statelessness. Unlike other systems, there is no "state" kept on a server to indicate that a client is performing a remote file operation. Thus, if the client crashes and is rebooted, there is no state in the server that needs to be recovered. Alternatively, if the server crashes and is rebooted, the client can continue operating on the remote file as if nothing really happened�there is no server-side state to recreate.[2] We'll discuss this concept further in later sections.
15.1.1 NFS HistoryNFS was developed inside Sun Microsystems in the early 1980s. Since that time, NFS has undergone three major revisions:
NFS is based on two similar but distinct protocols: MOUNT and NFS. Both make use of a data object known as a file handle. There is also a distributed protocol for file locking, which is not technically part of NFS, and which does not have any obvious security ramifications,[4] so we won't describe the file-locking protocol here.
15.1.2 File HandlesEach object on the NFS-mounted filesystem is referenced by a unique object called a file handle. A file handle is viewed by the client as being opaque�the client cannot interpret the contents. However, to the server, the contents have considerable meaning. The file handles uniquely identify every file and directory on the server computer. The Unix NFS server stores three pieces of information inside each file handle.
Note that the file handle doesn't include a pathname; a pathname is not necessary and is, in fact, subject to change while a file is being accessed. 15.1.3 The MOUNT ProtocolThe MOUNT protocol is used for the initial negotiation between the NFS client and the NFS server. Using MOUNT, a client can determine which filesystems are available for mounting and can obtain a token (the file handle) that is used to access the root directory of a particular filesystem. After that file handle is returned, it can thereafter be used to retrieve file handles for other directories and files on the server. Another benefit of the MOUNT protocol is that you can export only a portion of a local partition to a remote client. By specifying that the root is a directory on the partition, the MOUNT service will return its file handle to the client. To the client, this file handle behaves exactly like one for the root of a partition: reads, writes, and directory lookups all behave the same way. MOUNT is an RPC service. The service is provided by the mountd or rpc.mountd daemon, which is started automatically at boot time. (On Solaris systems, for example, mountd is located in /usr/lib/nfs/mountd, and is started by the script /etc/rc3.d/S15nfs.server.) MOUNT is often given the RPC program number 100,005. The standard mountd normally responds to six different requests:
Although the MOUNT protocol provides useful information within an organization, the information that it provides could be used by those outside an organization to launch an attack. For this reason, you should prevent people outside your organization from accessing your computer's mount daemon. The best way to do this is by using a host-based or network-based firewall. See Chapter 11 for further information. The MOUNT protocol is based on Sun Microsystems' RPC and External Data Representation (XDR) protocols. For a complete description of the MOUNT protocol, see RFC 1094. 15.1.4 The NFS ProtocolThe NFS protocol takes over where the MOUNT protocol leaves off. With the NFS protocol, a client can list the contents of an exported filesystem's directories; obtain file handles for other directories and files; and even create, read, or modify files (as permitted by Unix permissions). Here is a list of the RPC functions that perform operations on directories:
These RPC functions can be used with files:
NFS Version 3 added a number of additional RPC functions. With the exception of MKNOD, these new functions simply allow improved performance:
All communication between the NFS client and the NFS server is based upon Sun's RPC system (described in Chapter 13), which lets programs running on one computer call subroutines that are executed on another. RPC uses Sun's XDR system to allow the exchange of information between different kinds of computers (see Figure 15-1). Sun built NFS upon the Internet User Datagram Protocol (UDP), believing that UDP was faster and more efficient than TCP. However, NFS required reliable transmission and, as time went on, many tuning parameters were added that made NFS resemble TCP in many respects. NFS Version 3 allows the use of TCP, which actually improves performance over low-bandwidth, high-latency links such as modem-based PPP connections because TCP's backoff and retransmission algorithms are significantly better than those in NFS. Figure 15-1. NFS protocol stack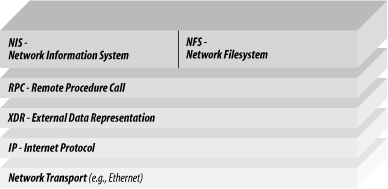 15.1.4.1 How NFS creates a reliable filesystem from a best-effort protocolUDP is fast but only best-effort. "Best effort" means that the protocol does not guarantee that UDP packets transmitted will ever be delivered, or that they will be delivered in order. NFS works around this problem by requiring the NFS server to acknowledge every RPC command with a result code that indicates whether the command was successfully completed. If the NFS client does not get an acknowledgment within a certain amount of time, it retransmits the original command. If the NFS client does not receive an acknowledgment, that indicates that UDP lost either the original RPC command or the RPC acknowledgment. If the original RPC command was lost, there is no problem�the server sees it for the first time when it is retransmitted. But if the acknowledgment was lost, the server will actually get the same NFS command twice. For most NFS commands, this duplication of requests presents no problem. With READ, for example, the same block of data can be read once or a dozen times, without consequence. Even with the WRITE command, the same block of data can be written twice to the same point in the file, without consequence, so long as there is not more than one process writing to the file at the same time.[5]
Other commands, however, cannot be executed twice in a row. MKDIR, for example, will fail the second time that it is executed because the requested directory will already exist. For commands that cannot be repeated, some NFS servers maintain a cache of the last few commands that were executed. When the server receives a MKDIR request, it first checks the cache to see if it has already received the MKDIR request. If so, the server merely retransmits the acknowledgment (which must have been lost). 15.1.4.2 Hard, soft, and spongy mountsIf the NFS client still receives no acknowledgment, it will retransmit the request again and again, each time doubling the time that it waits between retries. If the network filesystem was mounted with the soft option, the request will eventually time out. If the network filesystem is mounted with the hard option, the client continues sending the request until the client is rebooted or gets an acknowledgment. Some BSD-derived versions of Unix also have a spongy option that is similar to hard, except that the stat, lookup, fsstat, readlink, and readdir operations behave as if they have a soft MOUNT. NFS uses the mount command to specify whether a filesystem is mounted with the hard or soft option. To mount a filesystem soft, specify the soft option. For example: /etc/mount -o soft zeus:/big /zbig This command mounts the directory /big stored on the server called zeus locally in the directory /zbig. The option -o soft tells the mount program that you wish the filesystem mounted soft. To mount a filesystem hard, do not specify the soft option: /etc/mount zeus:/big /zbig On some systems you need to be explicit that this is an NFS mount. You may also be able to use a URL format for the path and server. Here are examples of each: mount -F nfs zeus:/big /zbig mount nfs://zeus/bin /zbig Deciding whether to mount a filesystem hard or soft can be difficult because there are advantages and disadvantages to each option. Diskless workstations often hard-mount the directories that they use to keep system programs; if a server crashes, the workstations wait until the server is rebooted, then continue file access with no problem. Filesystems containing home directories are usually hard-mounted so that all disk writes to those filesystems will be performed correctly. On the other hand, if you mount many filesystems with the hard option, you will discover that your workstation may stop working every time any server crashes and won't work again until it reboots. If there are many libraries and archives that you keep mounted on your system, but that are not critical, you may wish to mount them soft. You may also wish to specify the intr option, which is like the hard option except that the user can interrupt it by typing the kill character (usually Ctrl-C). As a general rule of thumb, read-only filesystems can be mounted soft without any chance of accidental loss of data. An alternative to using soft mounts is to mount everything hard (or spongy, when available) but avoid mounting your nonessential NFS partitions directly in the root directory. This practice will prevent the Unix getpwd( ) function from hanging when a server is down.[6]
15.1.4.3 Connectionless and statelessAs we've mentioned, NFS servers are stateless by design. Stateless means that all of the information that the client needs to mount a remote filesystem is kept on the client, instead of having additional information with the mount stored on the server. After a file handle is issued for a file, that file handle will remain good even if the server is shut down and rebooted as long as the file continues to exist and no major changes are made to the configuration of the server that would change the values (e.g., a filesystem rebuild or restore from tape). Early NFS servers were also connectionless. Connectionless means that the server program does not keep track of every client that has remotely mounted the filesystem.[7] When offering NFS over a TCP connection, however, NFS is not connectionless: there is one TCP connection for each mounted filesystem.
The advantage of a stateless, connectionless system is that such systems are easier to write and debug. The programmer does not need to write any code for re-establishing connections after the network server crashes and restarts because there is no connection that must be re-established. If a client crashes (or if the network becomes disconnected), valuable resources are not tied up on the server maintaining a connection and state for that client. A second advantage of this approach is that it scales. That is, a connectionless, stateless NFS server works equally well if 10 clients are using a filesystem or if 10,000 are using it. Although system performance suffers under extremely heavy use, every file request made by a client using NFS should eventually be satisfied, and there is no performance penalty if a client mounts a filesystem but never uses it. 15.1.4.4 NFS and rootBecause the superuser can do so much damage on the typical Unix system, NFS takes special precautions in how it handles the superuser running on client computers. Instead of giving the client superuser unlimited privileges on the NFS server, NFS gives the superuser on the clients virtually no privileges: the superuser is mapped to the UID of the nobody user�usually a UID of 32767 or 60001 (although, occasionally -1 or -2 on pre-POSIX systems).[8] Some versions of NFS allow you to specify at mount time the UID to which to map root's accesses, with the UID of the nobody user as the default.
Thus, superusers on NFS client machines actually have fewer privileges (with respect to the NFS server) than ordinary users. However, this lack of privilege isn't usually much of a problem for would-be attackers who have root access because the superuser can simply su to a different UID such as bin or sys. On the other hand, treating the superuser in this way can protect other files on the NFS server. Most implementations of NFS do no remapping of any other UID, nor any remapping of any GID values.[9] Thus, if a server exports any file or directory with access permissions for some user or group, the superuser on a client machine can take on an identity to access that information. This rule implies that the exported file can be read or copied by someone remote or, worse, modified without authorization.
15.1.5 NFS Version 3During the 10 years of the life of NFS Version 2, a number of problems were discovered with it. These problems included:
NFS Version 3 (NFS 3) was the first major revision to NFS since the protocol was commercially released. As such, NFS 3 was designed to correct many of the problems that had been experienced with NFS. But NFS 3 was not a total rewrite. According to Pawlowski et al., there were three guiding principles in designing NFS 3:
Thus, while NFS 3 allows for improved performance and access to files larger than 4 GB, it does not make any fundamental changes to the overall NFS architecture. (That has been relegated to NFS Version 4.) As a result of the design criteria, there are relatively few changes between the NFS 2 and NFS 3 protocols:
Because RPC allows a server to respond to more than one version of a protocol at the same time, NFS 3 servers are potentially able to support the NFS 2 and 3 protocols simultaneously so that they can serve older NFS 2 clients while allowing easy upgradability to NFS 3. Likewise, most NFS 3 clients could continue to support the NFS 2 protocol as well so that they can speak with old and new servers.[11]
This need for backward compatibility effectively prevented the NFS 3 designers from adding new security features to the protocols. If NFS 3 had more security features, an attacker could avoid them by resorting to NFS 2. On the other hand, by changing a site from unsecure RPC to secure RPC, a site can achieve secure NFS for all of its NFS clients and servers, whether they are running NFS 2 or NFS 3. |

|
|