| CONTENTS |
Chapter 15. Design Strategies
- 15.1 Hash Codes in Compound Primary Keys
- 15.2 Passing Objects by Value
- 15.3 Improved Performance with Session Beans
- 15.4 Bean Adapters
- 15.5 Implementing a Common Interface
- 15.6 Entity Beans Without Create Methods
- 15.7 EJB 1.1: Object-to-Relational Mapping Tools
- 15.8 Avoid Emulating Entity Beans with Session Beans
- 15.9 Direct Database Access from Session Beans
- 15.10 Avoid Chaining Stateful Session Beans
The previous 14 chapters have presented the core EJB technology. What's left is a grab bag of miscellaneous issues: how to solve particular design problems, how to work with particular kinds of databases, and topics of that nature.
15.1 Hash Codes in Compound Primary Keys
Chapter 11 discusses the necessity of overriding the Object.hashCode() and Object.equals() methods in the primary key class of an entity bean. With complex primary keys that have several fields, overriding Object.equals() is fairly trivial. However, overriding Object.hashCode() is more complicated, because an integer value that can serve as a suitable hash code must be created from several fields.
One solution is to concatenate all the values into a String and use the String object's hashCode() method to create a hash code value for the whole primary key. The String class has a decent hash code algorithm that generates a fairly well-distributed and repeatable hash code value from any set of characters.
The following code shows how to create such a hash code for a hypothetical primary key:
public class HypotheticalPrimaryKey implements java.io.Serializable {
public int primary_id;
public short secondary_id;
public java.util.Date date;
public String desc;
public int hashCode() {
StringBuffer strBuff = new StringBuffer();
strBuff.append(primary_id);
strBuff.append(secondary_id);
strBuff.append(date);
strBuff.append(desc);
String str = strBuff.toString();
int hashCode = str.hashCode();
return hashCode;
}
// the constructor, equals, and toString methods follow
}
A StringBuffer cuts down on the number of objects created, since String concatenation is expensive. The code could be improved by saving the hash code in a private variable and returning that value in subsequent method calls; this way, the hash code is calculated only once in the life of the instance.
15.1.1 Well-Distributed Versus Unique Hash Codes
A Hashtable is designed to provide fast lookups by binding an object to a key. Given any object's key, looking up the object in a hash table is a quick operation. For the lookup, the key is converted to an integer value using the key's hashCode() method.
Hash codes do not need to be unique, only well distributed. By "well distributed" we mean that, given any two keys, the chances are very good that the hash codes for the keys will be different. A well-distributed hash code algorithm reduces, but does not eliminate, the possibility that different keys evaluate to the same hash code. When keys evaluate to the same hash code, they are stored together and uniquely identified by their equals() methods. If you look up an object using a key that evaluates to a hash code that is shared by several other keys, the Hashtable locates the group of objects that have been stored with the same hash code; then it uses the key's equals() method to determine which key (and hence, which object) you want. (That's why you have to override the equals() method in primary keys as well as the hashCode() method.) Therefore, the emphasis in designing a good hash code algorithm is on producing codes that are well distributed rather than unique. This strategy allows you to design an index for associating keys with objects that is easy to compute and therefore fast.
15.2 Passing Objects by Value
Passing objects by value is tricky with Enterprise JavaBeans. Two simple rules will keep you out of most problem areas: objects that are passed by value should be fine-grained dependent objects or wrappers used in bulk accessors, and dependent objects should be immutable.
15.2.1 EJB 1.1: Dependent Objects
The concept of dependent objects was addressed in Chapter 6, which describes the use of dependent objects in EJB 2.0. But for EJB 1.1, dependent objects are a new concept. EJB 2.0 and EJB 1.1 use dependent objects differently, because EJB 2.0 can accommodate much more fine-grained entity beans than EJB 1.1.
Dependent objects are objects that have meaning only within the context of another business object. They typically represent fairly fine-grained business concepts, such as an address, phone number, or order item. For example, an address has little meaning when it is not associated with a business object such as Person or Organization. It depends on the context of the business object to give it meaning. Such an object can be thought of as a wrapper for related data. The fields that make up an address (street, city, state, and zip) should be packaged together in a single object called AddressDO. In turn, the AddressDO object is usually an attribute or property of another business object; in EJB, we would typically see a dependent object such as AddressDO as a property of an entity bean.
Here's a typical implementation of an AddressDO object:
public class AddressDO implements java.io.Serializable {
private String street;
private String city;
private String state;
private String zip;
public Address(String str, String cty, String st, String zp) {
street = str;
city = cty;
state = st;
zip = zp;
}
public String getStreet() {return street;}
public String getCity() {return city;}
public String getState() {return state;}
public String getZip() {return zip;}
}
We want to make sure that clients do not change an AddressDO object's fields. The reason is quite simple: the AddressDO object is a copy, not a remote reference. Changes to an AddressDO object are not reflected in the entity from which it originated. If a client changes the AddressDO object, those changes will not be reflected in the database. Making the AddressDO object immutable helps to ensure that clients do not mistake this fine-grained object for a remote reference, thinking that a change to an address property will be reflected on the server.
To change an address, the client is required to remove the AddressDO object and add a new one with the changes. Again, this is because the dependent object is not a remote object and changes to its state are not reflected on the server. Here is the remote interface to a hypothetical Employee bean that aggregates address information:
public interface Employee extends javax.ejb.EJBObject {
public AddressDO [] getAddresses() throws RemoteException;
public void removeAddress(AddressDO adrs) throws RemoteException;
public void addAddress(AddressDO adrs) throws RemoteException;
// ... Other business methods follow.
}
In this interface, the Employee can have many addresses, which are obtained as a collection of pass-by-value AddressDO objects. To remove an address, the target AddressDO object is passed back to the bean in the removeAddress() method. The bean class then removes the matching AddressDO object from its persistence fields. To add an address, an AddressDO object is passed to the bean by value.
Dependent objects may be persistence fields or they may be properties that are created as needed. The following code demonstrates both strategies using the AddressDO object. In the first listing, the AddressDO object is a persistence field, while in the second the AddressDO object is a property that does not correspond to any single field; we create the AddressDO object as needed but do not save it as part of the bean. Instead, the AddressDO object corresponds to four persistence fields: street, city, state, and zip.
// Address as a persistence field
public class Person extends javax.ejb.EntityBean {
public AddressDO address;
public AddressDO getAddress() {
return address;
}
public void setAddress(AddressDO addr) {
address = addr;
}
...
}
// Address as a property
public class Person extends javax.ejb.EntityBean {
public String street;
public String city;
public String state;
public String zip;
public AddressDO getAddress() {
return new AddressDO(street, city, state, zip);
}
public void setAddress(AddressDO addr) {
street = addr.street;
city = addr.city;
state = addr.state;
zip = addr.zip;
}
...
}
When a dependent object is used as a property, it can be synchronized with the persistence fields in the accessor methods themselves or in the ejbLoad() and ejbStore() methods. Both strategies are acceptable.
This discussion of dependent objects has been full of generalizations and thus may not be applicable to all situations. That said, it is recommended that only very fine-grained, dependent, immutable objects should be passed by value. All other business concepts should be represented as entity or session beans. A very fine-grained object is one that has very little behavior, consisting mostly of get and set methods. A dependent object is one that has little meaning outside the context of its aggregator. An immutable object is one that provides only get methods and thus cannot be modified once created.
15.2.2 Validation Rules in Dependent Objects
Dependent objects make excellent homes for format-validation rules. Format validation ensures that a simple data construct adheres to a predetermined structure or form. As an example, a Zip Code always has a certain format. It must be composed of digits; it must be five or nine digits in length; and if it has nine digits, it must use a hyphen as a separator between the fifth and sixth digits. Checking to see that a Zip Code follows these rules is format validation.
One problem that all developers face is deciding where to put validation code. Should data be validated at the user interface (UI), or should it be done by the bean that uses the data? Validating the data at the UI has the advantage of conserving network resources and improving performance. However, validating data in the bean, on the middle tier, ensures that the logic is reusable across user interfaces. Dependent objects provide a logical compromise that allows data to be validated on the client but remain independent of the UI. Since the validation logic is located in the constructor of the dependent object, the object automatically validates the data when it is created. When data is entered at the UI (e.g., GUI, servlet, or JSP), the UI can validate it using its corresponding dependent object. If the data is valid, the dependent object is created; if the data is invalid, the constructor throws an exception.
The following code shows a dependent object that represents a Zip Code. It adheres to the rules for a dependent object as I have defined them and also includes format-validation rules in the constructor:
public class ZipCodeDO implements java.io.Serializable {
private String code;
private String boxNumber;
public ZipCode(String zipcode) throws ValidationException {
if (zipcode == null)
throw new ValidationException("Zip Code cannot be null");
else if (zipcode.length()==5 && ! isDigits(zipcode))
throw new ValidationException("Zip Code must be all digits");
else if (zipcode.length()==10 ) {
if (zipcode.charAt(5) == '-' ) {
code = zipcode.substring(0,5);
if (isDigits( code )){
boxNumber = zipcode.substring(6);
if (isDigits( boxNumber ))
return;
}
}
throw new ValidationException("Zip Code must be of form #####-####");
}
}
private boolean isDigits(String str) {
for (int i = 0; i < str.length(); i++) {
char chr = str.charAt(i);
if ( ! Character.isDigit(chr)) {
return false;
}
}
return true;
}
public String getCode() { return code; }
public String getBoxNumber() { return boxNumber; }
public String toString() {
return code+'-'+boxNumber;
}
}
This simple example illustrates that format validation can be performed by dependent objects when the object is constructed at the user interface or client. Any format-validation errors are reported immediately, without any interaction with the middle tier of the application. In addition, any business object that uses ZipCodeDO automatically gains the benefit of the validation code, making the validation rules reusable (and consistent) across beans. Placing format validation in the dependent object is also a good coding practice because it makes the dependent object responsible for its own validation; responsibility is a key concept in object-oriented programming. Of course, dependent objects are useful for validation only if the Enterprise JavaBeans implementation supports pass-by-value.
As an alternative to using dependent objects, format validation can be performed by the accessors of enterprise beans. If, for example, a customer bean has accessors for setting and obtaining the Zip Code, those accessors could incorporate the validation code. While this strategy is more efficient from a network perspective—passing a String value is more efficient than passing a dependent object by value—it is less reusable than housing format-validation rules in dependent objects.
15.2.3 Bulk Accessors for Remote Clients
Most entity beans have several persistence fields that are manipulated through accessor methods. Unfortunately, the one-to-one nature of the accessor idiom can result in many invocations when accessing an entity, which translates into a lot of network traffic when using remote references. Every field you want to modify requires a method invocation, which in turn requires you to go out to the network. One way to reduce network traffic when accessing entities from remote clients is to use bulk accessors, which package access to several persistence fields into a single accessor method. Bulk accessors provide get and set methods that work with structures or simple pass-by-value objects. The following code shows how a bulk accessor could be implemented for the Cabin bean:
// CabinData DataObject
public class CabinData {
public String name;
public int deckLevel;
public int bedCount;
public CabinData() {
}
public CabinData(String name, int deckLevel, int bedCount) {
this.name = name;
this.deckLevel = deckLevel;
this.bedCount = bedCount;
}
}
// CabinBean using bulk accessors
public class CabinBean implements javax.ejb.EntityBean {
public int id;
public String name;
public int deckLevel;
public int ship;
public int bedCount;
// bulk accessors
public CabinData getData() {
return new CabinData(name,deckLevel,bedCount);
}
public void setData(CabinData data) {
name = data.name;
deckLevel = data.deckLevel;
bedCount = data.bedCount;
}
// simple accessors and entity methods
public String getName() {
return name;
}
public void setName(String str) {
name = str;
}
// more methods follow
}
The getData() and setData() methods allow several fields to be packaged into a simple object and passed between the client and bean in one method call. This is much more efficient than requiring three separate calls to set the name, deck level, and bed count.
15.2.3.1 Rules-of-thumb for bulk accessors
Here are some guidelines for creating bulk accessors:
- Data objects are not dependent objects
-
Data objects and dependent objects serve clearly different purposes, but they may appear at first to be the same. Where dependent objects represent business concepts, data objects do not; they are simply an efficient way of packaging an entity's fields for access by clients. Data objects may package dependent objects along with more primitive attributes, but they are not dependent objects themselves.
- Data objects are simple structures
-
Keep the data objects as simple as possible; ideally, they should be similar to a simple struct in C. In other words, the data object should not have any business logic at all; it should only have fields. All the business logic should remain in the entity bean, where it is centralized and can be maintained easily.
In order to keep the semantics of a C struct, data objects should not have accessor (get and set) methods for reading and writing their fields. The CabinData class does not have accessor methods; it only has fields and a couple of constructors. The lack of accessors reinforces the idea that the data object exists only to bundle fields together, not to "behave" in a particular manner. As a design concept, we want the data object to be a simple structure devoid of behavior; this is a matter of form following function. The exception is the multiargument constructor, which is left as a convenience for the developer.
- Bulk accessors bundle related fields
-
The bulk accessors can pass a subset of the entity's data. Some fields may have different security or transaction needs, which require that they be accessed separately. In the CabinBean, only a subset of the fields (name, deckLevel, bedCount) is passed in the data object. The id field is not included for several reasons: it does not describe the business concept, it is already found in the primary key, and the client should not edit it. The ship field is not passed because it should be updated only by certain individuals; the identities authorized to change this field are different from the identities allowed to change the other fields. Similarly, access to the ship may fall under a different transaction isolation level than the other fields (e.g., Serializable versus Read Committed).
In addition, it is more efficient to design bulk accessors that pass logically related fields. In entity beans with many fields, it is possible to group together certain fields that are normally edited at the same time. An Employee bean, for example, might have several fields that are demographic in nature (address, phone, email) and can be logically separated from fields that are specific to benefits (compensation, 401K, health, vacation). A group of logically related fields can have its own bulk accessor. You might even want several bulk accessors in the same bean:
public interface Employee extends javax.ejb.EJBObject { public EmployeeBenefitsData getBenefitsData() throws RemoteException; public void setBenefitsData(EmployeeBenefitsData data) throws RemoteException; public EmployeeDemographicData getDemographicData() throws RemoteException; public void setDemographicData(EmployeeDemographicData data) throws RemoteException; // more simple accessors and other business methods follow }
- Retain simple accessors
-
Simple accessors (get and set methods for single fields) should not be abandoned when using bulk accessors. It is still important to allow editing of single fields. It's just as wasteful to use a bulk accessor to change one field as it is to change several fields using simple accessors.
Local references in EJB 2.0 container-managed persistence are very efficient, so the performance benefits of bulk accessors are minimal. If you're using EJB 2.0, use bulk accessors with remote interfaces whenever it makes sense according to the guidelines given here, but use them sparingly with local interfaces.
15.2.4 Entity Objects
The earlier section on passing objects by value gave you some good ground rules for when and how to use pass-by-value in EJB. Business concepts that do not meet the dependent object criteria should be modeled as either session or entity beans. It is easy to mistakenly adopt a strategy of passing business objects that would normally qualify as entity beans (e.g., Customer, Ship, and City) by value to the clients. Overzealous use of bulk accessors that pass data objects loaded with business behavior is bad design. The belief is that passing the entity objects to the client avoids unnecessary network traffic by keeping the set and get methods local. The problem with this approach is object equivalence. Entities are supposed to represent the actual data on the database, which means that they are shared and always reflect the current state of the data. Once an object is resident on the client, it is no longer representative of the data. It is easy for a client to end up with many dirty copies of the same entity, resulting in inconsistent processing and representation of data.
While it is true that the set and get methods of entity objects can introduce a lot of network traffic, implementing pass-by-value objects instead of using entity beans is not the answer. The network problem can be avoided if you stick to the design strategy elaborated throughout this book: remote clients interact primarily with session beans, not entity beans. You can also reduce network traffic significantly by using bulk accessors, provided that these accessors transfer only structures with no business logic. Finally, try to keep the entity beans on the server encapsulated in workflow defined by session beans. This eliminates the network traffic associated with entities, while ensuring that they always represent the correct data.
15.3 Improved Performance with Session Beans
In addition to defining the interactions among entity beans and other resources (workflow), session beans have another substantial benefit: they improve performance. The performance gains from using session beans are related to the concept of granularity. Granularity describes the scope of a business component, or how much business territory the component covers. The scope of these beans is limited to a single concept and can impact only the data associated with that concept. Session beans represent large, coarse-grained components with a scope that covers several business concepts—all the business concepts or processes the bean needs in order to accomplish a task. In distributed business computing, you rely on fine-grained components like entity beans to ensure simple, uniform, reusable, and safe access to data. Coarse-grained business components like session beans capture the interactions of entities or business processes that span multiple entities so that they can be reused; in doing so, they also improve performance on both the client and the server. As a rule of thumb, client applications should do most of their work with coarse-grained components like session beans, with limited direct interaction with entity beans.
To understand how session beans improve performance, we must address the most common problems cited with distributed component systems: network traffic, latency, and resource consumption.
15.3.1 Network Traffic and Latency with Remote Clients
One of the biggest problems of distributed component systems is that they generate a lot of network traffic. This is especially true of component systems that rely solely on entity-type business components, such as EJB's EntityBean component. Every method call on a remote reference begins a remote method-invocation loop, which sends information from the stub to the server and back to the stub. The loop requires data to be streamed to and from the client, consuming bandwidth. The reservation system for Titan Cruise Lines uses several entity beans (e.g., the Ship, Cabin, Cruise, and Customer EJBs). As we navigate through these fine-grained beans, requesting information, updating their states, and creating new beans, we generate network traffic if we are accessing the beans from remote clients. One client probably does not generate much traffic, but if we multiply that traffic level by thousands of clients, problems start to develop. Eventually, thousands of clients will produce so much network traffic that the system as a whole will suffer.
Another aspect of network communications is latency. Latency is the delay between the time at which we execute a command and the time at which it completes. With enterprise beans there is always a bit of latency due to the time it takes to communicate requests via the network. Each method invocation requires an RMI loop that takes time to travel from the client to the server and back to the client. A client that uses many beans will suffer from a time delay with each method invocation. Collectively, the latency delays can result in very slow clients that take several seconds to respond to each user action.
Accessing coarse-grained session beans from the client instead of fine-grained entity beans from remote clients can substantially reduce problems with network bandwidth and latency. In Chapter 12, we developed the bookPassage() method on the TravelAgent bean. The bookPassage() method encapsulates the interactions of entity beans that would otherwise have resided on the client. For the network cost of one method invocation on the client (bookPassage()), several tasks are performed on the EJB server. Using session beans to encapsulate several tasks reduces the number of remote method invocations needed to accomplish a task, which reduces the amount of network traffic and latency encountered while performing these tasks.
In EJB 2.0, a good design is to use remote component interfaces on the session bean that manages the workflow and local component interfaces on the enterprise beans (both entity and session) that it manages. This ensures the best performance.
15.3.2 Striking a Balance with Remote Clients
We don't want to abandon the use of entity business components, because they provide several advantages over traditional two-tier computing. They allow us to encapsulate the business logic and data of a business concept so that it can be used consistently and reused safely across applications. In short, entity business components are better for accessing business state because they simplify data access.
At the same time, we don't want to overuse entity beans on remote clients. Instead, we want the client to interact with coarse-grained session beans that encapsulate the interactions of small-grained entity beans. There are situations in which the client application should interact with entity beans directly. If a remote client application needs to edit a specific entity—change the address of a customer, for example—exposing the client to the entity bean is more practical than using a session bean. If, however, a task needs to be performed that involves the interactions of more than one entity bean—transferring money from one account to another, for example—a session bean should be used.
When a client application needs to perform a specific operation on an entity, such as an update, it makes sense to make the entity available to the client directly. If the client is performing a task that spans business concepts or otherwise involves more than one entity, that task should be modeled in a session bean as a workflow. A good design will emphasize the use of coarse-grained session beans as workflow and will limit the number of activities that require direct client access to entity beans.
In EJB 2.0, entity beans that are accessed by both remote clients and local enterprise beans can accommodate both by implementing both remote and local component interfaces. The methods defined in the remote and local component interfaces do not need to be identical; each should define methods appropriate to the clients that will use them. For example, the remote interfaces might make more use of bulk accessors than the local interface.
15.3.3 Listing Behavior
Make decisions about whether to access data directly or through entity beans with care. Listing behavior that is specific to a workflow can be provided by direct data access from a session bean. Methods like listAvailableCabins() in the TravelAgent bean use direct data access because it is less expensive than creating a find method in the Cabin bean that returns a list of Cabin beans. Every bean that the system has to deal with requires resources; by avoiding the use of components where their benefit is questionable, we can improve the performance of the whole system. A CTM is like a powerful truck, and each business component it manages is like a small weight. A truck is much better at hauling around a bunch of weights than an lightweight vehicle like a bicycle, but piling too many weights on the truck will make it just as ineffective as the bicycle. If neither vehicle can move, which one is better?
Chapter 12 discussed the TravelAgent bean's listAvailableCabins() method as an example of a method that returns a list of tabular data. This section provides several different strategies for implementing listing behavior in your beans.
Tabular data is data that is arranged into rows and columns. Tabular data is often used to let application users select or inspect data in the system. Enterprise JavaBeans lets you use find methods to list entity beans, but this mechanism is not a silver bullet. In many circumstances, find methods that return remote references are a heavyweight solution to a lightweight problem. For example, Table 15-1 shows the schedule for a cruise.
|
Cruise ID |
Port-of-call |
Arrive |
Depart |
|---|---|---|---|
|
233 |
San Juan |
June 4, 2002 |
June 5, 2002 |
|
233 |
Aruba |
June 7, 2002 |
June 8, 2002 |
|
233 |
Cartagena |
June 9, 2002 |
June 10, 2002 |
|
233 |
San Blas Islands |
June 11, 2002 |
June 12, 2002 |
It would be possible to create a Port-Of-Call entity object that represents every destination and then obtain a list of destinations using a find method, but this would be overkill. Recognizing that the data is not shared and is useful only in this one circumstance, we would rather present the data as a simple tabular listing.
In this case, we will present the data to the bean client as an array of String objects, with the values separated by a character delimiter. Here is the method signature used to obtain the data:.
public interface Schedule implements javax.ejb.EJBObject {
public String [] getSchedule(int ID) throws RemoteException;
}
And here is the structure of the String values returned by the getSchedule() method:
233; San Juan; June 4, 2002; June 5, 2002 233; Aruba; June 7, 2002; June 8, 2002 233; Cartegena; June 9, 2002; June 10, 2002 233; San Blas Islands; June 11, 2002; June 12, 2002
The data could also be returned as a multidimensional array of strings, in which each column represents one field. This would certainly make it easier to reference each data item, but would also complicate navigation.
One disadvantage of using the simple array strategy is that Java is limited to single-type arrays. In other words, all the elements in the array must be of the same type. We use an array of Strings here because it has the most flexibility for representing other data types. We could also have used an array of Objects or even a Vector. The problem with using an Object array or a Vector is that there is no typing information at runtime or development time.
15.3.3.1 Implementing lists as arrays of structures
Instead of returning a simple array, a method that implements some sort of listing behavior can return an array of structures. For example, the cruise ship schedule data illustrated in Table 15-1 could be returned as an array of schedule structures. The structures are simple Java objects with no behavior (i.e., no methods) that are passed in an array. The definitions of the structure and the bean interface that would be used are:
// Definition of the bean that uses the structure
public interface Schedule implements javax.ejb.EJBObject {
public CruiseScheduleItem [] getSchedule(int ID)
throws RemoteException;
}
// Definition of the structure
public class CruiseScheduleItem {
public int cruiseID;
public String portName;
public java.util.Date arrival;
public java.util.Date departure;
}
Using structures allows the data elements to be of different types. In addition, the structures are self-describing: it is easy to determine the structure of the data in the tabular set based on its class definition.
15.3.3.2 Implementing lists as ResultSets
A more sophisticated and flexible way to implement a list is to provide a pass-by-value implementation of the java.sql.ResultSet interface. Although it is defined in the JDBC package (java.sql), the ResultSet interface is semantically independent of relational databases; it can be used to represent any set of tabular data. Since the ResultSet interface is familiar to most enterprise Java developers, it is an excellent construct for use in listing behavior. Using the ResultSet strategy, the signature of the getSchedule() method would be:
public interface Schedule implements javax.ejb.EJBObject {
public ResultSet getSchedule(int cruiseID) throws RemoteException;
}
In some cases, the tabular data displayed at the client may be generated using standard SQL through a JDBC driver. If the circumstances permit, you may choose to perform the query in a session bean and return the result set directly to the client through a listing method. However, there are many cases in which you don't want to return a ResultSet that comes directly from JDBC drivers. A ResultSet from a JDBC 1.x driver is normally connected directly to the database, which increases network overhead and exposes your data source to the client. In these cases, you can implement your own ResultSet object that uses arrays or vectors to cache the data. JDBC 2.0 provides a cached javax.sql.RowSet that looks like a ResultSet but is passed by value and provides features such as reverse scrolling. You can use the RowSet, but do not expose behavior that allows the result set to be updated. Data updates should be performed only by bean methods.
Sometimes the tabular data comes from several data sources or nonrelational databases. In these cases, you can query the data using the appropriate mechanisms within the listing bean and then reformat the data into your ResultSet implementation. Regardless of the source of the data, you should still present it as tabular data using a custom implementation of the ResultSet interface.
Using a ResultSet has a number of advantages and disadvantages. First, the advantages:
- Consistent interface for developers
-
The ResultSet interface provides a consistent interface that developers are familiar with and that is consistent across different listing behaviors. Developers do not need to learn several different constructs for working with tabular data; they use the same ResultSet interface for all listing methods.
- Consistent interface for automation
-
The ResultSet interface provides a consistent interface that allows software algorithms to operate on data independent of its content. You can create a builder that constructs an HTML or GUI table based on any set of results that implements the ResultSet.
- Metadata operations
-
The ResultSet interface defines several metadata methods that provide developers with runtime information describing the result set with which they are working.
- Flexibility
-
The ResultSet interface is independent of the data content, which allows tabular sets to change their schemas independently of the interfaces. A change in schema does not require a change to the method signatures of the listing operations.
And now, the disadvantages of using a ResultSet:
- Complexity
-
The ResultSet interface strategy is much more complex than returning a simple array or an array of structures. It normally requires you to develop a custom implementation of the ResultSet interface. If properly designed, the custom implementation can be reused across all your listing methods, but it is still a significant development effort.
- Hidden structure at development time
-
Although the ResultSet can describe itself through metadata at runtime, it cannot describe itself at development time. Unlike a simple array or an array of structures, the ResultSet interface provides no clues at development time about the structure of the underlying data. At runtime, metadata is available, but at development time, good documentation is required to express the structure of the data explicitly.
15.4 Bean Adapters
One of the most awkward aspects of the EJB bean interface types is that, in some cases, the callback methods are never used or are not relevant to the bean at all. A simple container-managed entity bean might have empty implementations for its ejbLoad(), ejbStore(), ejbActivate(), ejbPassivate(), or even its setEntity-Context() methods. Stateless session beans provide an even better example of unnecessary callback methods: they must implement the ejbActivate() and ejbPassivate() methods even though these methods are never invoked!
To simplify the appearance of the bean class definitions, we can introduce adapter classes that hide callback methods that are never used or have only minimal implementations. Here is an adapter for the entity bean that provides empty implementations of all the EntityBean methods:
public class EntityAdapter implements javax.ejb.EntityBean {
public EntityContext ejbContext;
public void ejbActivate() {}
public void ejbPassivate() {}
public void ejbLoad() {}
public void ejbStore() {}
public void ejbRemove() {}
public void setEntityContext(EntityContext ctx) {
ejbContext = ctx;
}
public void unsetEntityContext() {
ejbContext = null;
}
public EntityContext getEJBContext() {
return ejbContext;
}
}
We took care of capturing the EntityContext for use by the subclass. We can do this because most entity beans implement the context methods in exactly this way. We simply leverage the adapter class to manage this logic for our subclasses.
If a callback method is deemed necessary, we can just override it with a method in the bean class.
We can create a similar Adapter class for stateless session beans:
public class SessionAdapter implements javax.ejb.SessionBean {
public SessionContext ejbContext;
public void ejbActivate() {}
public void ejbPassivate() {}
public void ejbRemove() {}
public void setSessionContext(SessionContext ctx) {
ejbContext = ctx;
}
public SessionContext getEJBContext() {
return ejbContext;
}
}
Do not use these adapter classes when you need to override more than one or two of their methods. If you need to implement several of the callback methods, your code will be clearer if you do not use the adapter class. The adapter class also impacts the inheritance hierarchy of the bean class. If you need to implement a different superclass later, one that captures business logic, you will have to modify the class inheritance.
15.5 Implementing a Common Interface
This book discourages implementing the remote interface in the bean class, even though this makes it a little more difficult to enforce consistency between the business methods defined in the remote interface and the corresponding methods on the bean class. There are good reasons for not implementing the remote interface in the bean class, but there is also a need for a common interface to ensure that the bean class and remote interface define the same business methods. This section describes a design alternative that allows you to use a common interface to ensure consistency between the bean class and the remote interface.
15.5.1 Why the Bean Class Should Not Implement the Remote Interface
There should be no difference, other than the missing java.rmi.RemoteException, between the business methods defined in the ShipBean class and their corresponding business methods defined in the ShipRemote interface. EJB requires you to match the method signatures so that the remote interface can accurately represent the bean class on the client. Why not implement the remote interface com.titan.ShipRemote in the ShipBean class to ensure that these methods are matched correctly?
EJB allows a bean class to implement its remote interface, but this practice is discouraged for a couple of reasons. First, the remote interface is actually an extension of the javax.ejb.EJBObject interface, which you learned about in Chapter 5. This interface defines several methods that are implemented by the EJB container when the bean is deployed. Here is the definition of the javax.ejb.EJBObject interface:
public interface javax.ejb.EJBObject extends java.rmi.Remote {
public abstract EJBHome getEJBHome();
public abstract Handle getHandle();
public abstract Object getPrimaryKey();
public abstract boolean isIdentical(EJBObject obj);
public abstract void remove();
}
The methods defined here are implemented and supported by the EJB object for use by client software and are not implemented by the javax.ejb.EntityBean class. In other words, these methods are intended for the remote interface's implementation, not the bean instance's. The bean instance implements the business methods defined in the remote interface, but it does so indirectly. The EJB object receives all the method invocations made on the remote interface; those that are business methods (like the getName() or setCapacity() methods in Ship) are delegated to the bean instance. The other methods, defined by the EJBObject, are handled by the container and are never delegated to the bean instance.
Just for kicks, change the ShipBean definition so that it implements the Ship interface as shown here:
public class ShipBean implements ShipRemote {
When you recompile the ShipBean, you should have five errors stating that the ShipBean must be declared abstract because it does not implement the methods from the javax.ejb.EJBObject interface. EJB allows you to implement the remote interface, but in so doing you clutter the bean class's definition with a bunch of methods that have nothing to do with its functionality. You can hide these methods in an adapter class; however, using an adapter for methods that have empty implementations is one thing, but using an adapter for methods that should not be in the class at all is decidedly bad practice.
Another reason that beans should not implement the remote interface is that a client can be an application on a remote computer or it can be another bean. Beans as clients are very common. When calling a method on an object, the caller sometimes passes itself as one of the parameters.[1] In normal Java programming, an object passes a reference to itself using the this keyword. In EJB, however, clients—even bean clients—are allowed to interact only with the remote interfaces of beans. When one bean calls a method on another bean, it is not allowed to pass the this reference; it must obtain its own remote reference from its context and pass that reference instead. The fact that a bean class does not implement its remote interface prevents you from passing the this reference and forces you to get a reference to the interface from the context. The bean class will not compile if you attempt to use this as a remote reference. For example, assume that the ShipBean needs to call someMethod(ShipRemote ship). It cannot simply call someMethod(this), because ShipBean does not implement ShipRemote. If, however, the bean instance implements the remote interface, you could mistakenly pass the bean instance reference using the this keyword to another bean.
Beans should always interact with the remote references of other beans so that method invocations are intercepted by the EJB objects. Remember that the EJB objects apply security, transaction, concurrency, and other system-level constraints to method calls before they are delegated to the bean instance; the EJB object works with the container to manage the bean at runtime.
The proper way to obtain a bean's remote reference, within the bean class, is to use the EJBContext. Here is an example of how this works:
public class HypotheticalBean extends EntityBean {
public EntityContext ejbContext;
public void someMethod() throws RemoteException {
Hypothetical mySelf = (Hypothetical) ejbContext.getEJBObject();
// Do something interesting with the remote reference.
}
// More methods follow.
}
15.5.2 EJB 2.0: Why the Bean Class Should Not Implement the Local Interface
In EJB 2.0, the bean class should not implement the local interface for the exact same reasons that it should not implement the remote interface. Specifically, the bean instance would have to support the methods of the javax.ejb.EJBLocalObject interface, which are not germane to the bean class.
15.5.3 EJB 1.1: The Business Interface Alternative
Although it is undesirable for the bean class to implement its remote interface, we can define an intermediate interface that is used by both the bean class and the remote interface to ensure consistent business-method definitions. We will call this intermediate interface the business interface.
The following code contains an example of a business interface defined for the Ship bean, called ShipBusiness. All the business methods formerly defined in the ShipRemote interface are now defined in the ShipBusiness interface. The business interface defines all the business methods, including every exception that will be thrown from the remote interface at runtime:
package com.titan.ship;
import java.rmi.RemoteException;
public interface ShipBusiness {
public String getName() throws RemoteException;
public void setName(String name) throws RemoteException;
public void setCapacity(int cap) throws RemoteException;
public int getCapacity() throws RemoteException;
public double getTonnage() throws RemoteException;
public void setTonnage(double tons) throws RemoteException;
}
Once the business interface is defined, it can be extended by the remote interface. The remote interface extends both the ShipBusiness and EJBObject interfaces, giving it all the business methods and the EJBObject methods that the container will implement at deployment time:
package com.titan.ship;
import javax.ejb.EJBObject;
public interface ShipRemote extends ShipBusiness, javax.ejb.EJBObject {
}
Finally, we can implement the business interface in the bean class as we would any other interface:
public class ShipBean implements ShipBusiness, javax.ejb.EntityBean {
public int id;
public String name;
public int capacity;
public double tonnage;
public String getName() {
return name;
}
public void setName(String n) {
name = n;
}
public void setCapacity(int cap) {
capacity = cap;
}
public int getCapacity() {
return capacity;
}
public double getTonnage() {
return tonnage;
}
public void setTonnage(double tons) {
tonnage = tons;
}
// More methods follow...
}
In this case, we chose not to throw the RemoteException. Classes that implement interfaces can choose not to throw exceptions defined in the interface. They cannot, however, add exceptions. This is why the business interface must declare that its methods throw the RemoteException and all application exceptions. The remote interface should not modify the business interface definition. The bean class can choose not to throw the RemoteException, but it must throw all the application-specific exceptions.
The business interface is an easily implemented design strategy that will make it easier for you to develop beans. This book recommends that you use the business interface strategy in your own implementations. Remember not to pass the business interface in method calls; always use the bean's remote interface in method parameters and as return types.
15.6 Entity Beans Without Create Methods
If an entity bean is never meant to be created by a client, you can simply not implement a create() method on the home interface. This means that the entity in question can be obtained only by using the find() methods on the home interface. Titan might implement this strategy with their Ship beans, so that new Ships must be created by directly inserting records into the database—a privilege that might be reserved for the database administrator (they wouldn't want some crazed travel agent inserting random ships into their cruise line).
15.7 EJB 1.1: Object-to-Relational Mapping Tools
Some EJB vendors provide object-to-relational mapping tools that, using wizards, can create object representations of relational databases, generate tables from objects, or map existing objects to existing tables. These tools are outside the scope of this book because they are proprietary in nature and cannot generally be used to produce beans that can be used across EJB servers. In other words, in many cases, once you have begun to rely on a mapping tool to define a bean's persistence, you might not be able to migrate your beans to a different EJB server; the bean definition is bound to that mapping tool.
Mapping tools can make bean developers much more productive, but you should consider the implementation-specific details of your tool before using it. If you will need to migrate your application to a bigger, faster EJB server in the future, make sure the mapping tool you use is supported in other EJB servers.
Some products that perform object-to-relational mapping use JDBC. Object People's TOPLink and Watershed's ROF are examples of this type of product. These products provide more flexibility for mapping objects to relational databases and are not as dependent on the EJB server. However, EJB servers must support these products in order for them to be used, so again let caution guide your decisions about using these products.
15.8 Avoid Emulating Entity Beans with Session Beans
Session beans that implement the SessionSynchronization interface (discussed in Chapter 14) can emulate some of the functionality of bean-managed entity beans. This approach provides a couple of advantages. First, these session beans, like entity beans, can represent entity business concepts; second, dependency on vendor-specific object-to-relational mapping tools is avoided.
Unfortunately, session beans were not designed to represent data directly in the database, so using them as a replacement for entity beans is problematic. Entity beans fulfill this duty nicely because they are transactional objects. When the attributes of a bean are changed, the changes are reflected in the database automatically in a transactionally safe manner. This is not possible in stateful session beans because, although they are transactionally aware, they are not transactional objects. The difference is subtle but important. Stateful session beans are not shared like entity beans. There is no concurrency control when two clients attempt to access the same bean at the same time. With stateful session beans each client gets its own instance, so many copies of the same session bean representing the same entity data can be in use concurrently. Database isolation can prevent some problems, but the danger of obtaining and using dirty data is high.
Another problem is that session beans emulating entity beans cannot have find methods in their home interfaces. Entity beans support find methods as a convenient way to locate data. Find methods could be placed in the session bean's remote interface, but this would be inconsistent with the EJB component model. Also, a stateful session bean must use the SessionSynchronization interface to be transactionally safe, which requires that it be used only in the scope of the client's transaction. This is because methods such as ejbCreate() and ejbRemove() are not transactional. In addition, ejbRemove() has a significantly different function in session beans than in entity beans. Should ejbRemove() end the conversation, delete data, or both?
Weighing all the benefits against the problems and risks of data inconsistency, I recommend that you do not use stateful session beans to emulate entity beans.
15.9 Direct Database Access from Session Beans
Perhaps the most straightforward and portable option for using a server that supports only session beans is direct database access. We did some of this with the ProcessPayment bean and the TravelAgent bean in Chapter 12. When entity beans are not an option, we simply take this option a step further. The following code is an example of the TravelAgent bean's bookPassage() method, coded with direct JDBC data access instead of using entity beans:
public Ticket bookPassage(CreditCard card, double price)
throws RemoteException, IncompleteConversationalState {
if (customerID == 0 || cruiseID == 0 || cabinID == 0) {
throw new IncompleteConversationalState();
}
Connection con = null;
PreparedStatement ps = null;;
try {
con = getConnection();
// Insert reservation.
ps = con.prepareStatement("insert into RESERVATION "+
"(CUSTOMER_ID, CRUISE_ID, CABIN_ID, PRICE) values (?,?,?,?)");
ps.setInt(1, customerID);
ps.setInt(2, cruiseID);
ps.setInt(3, cabinID);
ps.setDouble(4, price);
if (ps.executeUpdate() != 1) {
throw new RemoteException ("Failed to add Reservation to database");
}
// Insert payment.
ps = con.prepareStatement("insert into PAYMENT "+
"(CUSTOMER_ID, AMOUNT, TYPE, CREDIT_NUMBER, CREDIT_EXP_DATE) "+
"values(?,?,?,?,?)");
ps.setInt(1, customerID);
ps.setDouble(2, price);
ps.setString(3, card.type);
ps.setLong(4, card.number);
ps.setDate(5, new java.sql.Date(card.experation.getTime()));
if (ps.executeUpdate() != 1) {
throw new RemoteException ("Failed to add Reservation to database");
}
Ticket ticket = new Ticket(customerID,cruiseID,cabinID,price);
return ticket;
} catch (SQLException se) {
throw new RemoteException (se.getMessage());
}
finally {
try {
if (ps != null) ps.close();
if (con!= null) con.close();
} catch(SQLException se){
se.printStackTrace();
}
}
}
No mystery here: we have simply redefined the TravelAgent bean so that it works directly with the data through JDBC rather than using entity beans. This method is transactionally safe because an exception thrown anywhere within the method will cause all the database inserts to be rolled back. Very clean and simple.
The idea behind this strategy is to continue to model workflow or processes with session beans. The TravelAgent bean models the process of making a reservation. Its conversational state can be changed over the course of a conversation, and safe database changes can be made based on the conversational state.
Object-to-relational mapping provides another mechanism for "direct" access to data in a stateful session bean. The advantage of object-to-relational mapping tools is that data can be encapsulated as an object-like entity bean. So, for example, an object-to-relational mapping approach could end up looking very similar to our entity bean design. The problem with object-to-relational mapping is that most tools are proprietary and may not be reusable across EJB servers. In other words, the object-to-relational tool may bind you to one brand of EJB server. Object-to-relational mapping tools are, however, an expedient, safe, and productive mechanism for obtaining direct database access when entity beans are not available.
15.10 Avoid Chaining Stateful Session Beans
In developing session-only systems, you may be tempted to use stateful session beans from inside other stateful session beans. While this appears to be a good modeling approach, it is problematic. Chaining stateful session beans can lead to problems when beans time out or throw exceptions that cause them to become invalid. Figure 15-1 shows a chain of stateful session beans, each of which maintains conversational state on which the other beans depend to complete the operation encapsulated by bean A.
Figure 15-1. Chain of stateful session beans
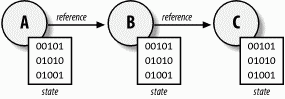
If any one of the beans in this chain times out—say, bean B—the conversational state trailing that bean is lost. If this conversational state was built up over a long time, considerable work can be lost. The chain of stateful session beans is only as strong as its weakest link. If one bean times out or becomes invalid, the entire conversational state on which bean A depends becomes invalid. Avoid chaining stateful session beans.
Using stateless session beans from within stateful session beans is not a problem, because a stateless session bean does not maintain any conversational state. Use stateless session beans from within stateful session beans as much as you need.
Using a stateful session bean from within a stateless session bean is almost nonsensical because the benefit of the stateful session bean's conversational state cannot be leveraged beyond the scope of the stateless session bean's method.
[1] This is frequently done in loopbacks, where the invokee needs information about the invoker. Loopbacks are discouraged in EJB because they require reentrant programming, which should be avoided.
| CONTENTS |