| CONTENTS |
Chapter 1. Introduction
- 1.1 Setting the Stage
- 1.2 Enterprise JavaBeans Defined
- 1.3 Distributed Object Architectures
- 1.4 Component Models
- 1.5 Component Transaction Monitors
- 1.6 CTMs and Server-Side Component Models
- 1.7 Titan Cruises: An Imaginary Business
- 1.8 What's Next?
This book is about Enterprise JavaBeans 2.0 and 1.1, which are the third and second versions of the Enterprise JavaBeans specification. Just as the Java platform has revolutionized the way we think about software development, Enterprise JavaBeans has revolutionized the way we think about developing mission-critical enterprise software. It combines server-side components with distributed object technologies and asynchronous messaging to greatly simplify the task of application development. It automatically takes into account many of the requirements of business systems, including security, resource pooling, persistence, concurrency, and transactional integrity.
This book shows you how to use Enterprise JavaBeans to develop scalable, portable business systems. But before we can start talking about EJB itself, we'll need a brief introduction to the technologies addressed by EJB, such as component models, distributed objects, component transaction monitors (CTMs), and asynchronous messaging. It's particularly important to have a basic understanding of component transaction monitors, the technology that lies beneath EJB. In Chapter 2 and Chapter 3, we'll start looking at EJB itself and see how enterprise beans are put together. The rest of this book is devoted to developing enterprise beans for an imaginary business and discussing advanced issues.
It is assumed that you're already familiar with Java; if you're not, Learning Java™, by Patrick Niemeyer and Josh Peck (O'Reilly), is an excellent introduction. This book also assumes that you're conversant in the JDBC API, or at least in SQL. If you're not familiar with JDBC, see Database Programming with JDBC™ and Java™ by George Reese (O'Reilly).
One of Java's most important features is platform independence. Since it was first released, Java has been marketed as "write once, run anywhere." While the hype has gotten a little heavy-handed at times, code written with Sun's Java programming language is remarkably platform independent. Enterprise JavaBeans isn't just platform independent—it's also implementation independent. If you've worked with JDBC, you know a little about what this means. Not only can the JDBC API run on a Windows machine or on a Unix machine, it can also access relational databases of many different vendors (DB2, Oracle, Sybase, SQLServer, etc.) by using different JDBC drivers. You don't have to code to a particular database implementation—just change JDBC drivers and you change databases. It's the same with EJB. Ideally, an EJB component, an enterprise bean, can run in any application server that implements the EJB specification.[1] This means that you can develop and deploy your EJB business system in one server, such as Orion or BEA's WebLogic, and later move it to a different EJB server, such as Pramati, Sybase EAServer, IBM's WebSphere, or an open source project such as OpenEJB, JOnAS, or JBoss. Implementation independence means that your business components are not dependent on the brand of server, which gives you many more options before, during, and after development and deployment.
1.1 Setting the Stage
Before defining Enterprise JavaBeans more precisely, let's set the stage by discussing a number of important concepts: distributed objects, business objects, component transaction monitors, and asynchronous messaging.
1.1.1 Distributed Objects
Distributed computing allows a business system to be more accessible. Distributed systems allow parts of the system to be located on separate computers, possibly in many different locations, where they make the most sense. In other words, distributed computing allows business logic and data to be reached from remote locations. Customers, business partners, and other remote parties can use a business system at any time from almost anywhere. The most recent development in distributed computing is distributed objects. Distributed object technologies such as Java RMI, CORBA, and Microsoft's .NET allow objects running on one machine to be used by client applications on different computers.
Distributed objects evolved from a legacy form of three-tier architecture used in transaction processing (TP) monitor systems such as IBM's CICS and BEA's TUXEDO. These systems separate the presentation, business logic, and database into three distinct tiers (or layers). In the past, these legacy systems were usually composed of a "green screen" or dumb terminal for the presentation tier (first tier), COBOL or PL/1 applications as the middle tier (second tier), and some sort of database, such as DB2, as the backend (third tier). The introduction of distributed objects in recent years has given rise to a new form of three-tier architecture. Distributed object technologies make it possible to replace the procedural COBOL and PL/1 applications on the middle tier with business objects. A three-tier distributed-business-object architecture might have a sophisticated graphical or web-based interface on the first tier, business objects on the middle tier, and a relational or some other database on the backend. More complex architectures often have many tiers: different objects reside on different servers and interact to get the job done. Creating these n-tier architectures with Enterprise JavaBeans is relatively easy.
1.1.2 Server-Side Components
Object-oriented languages, such as Java, C++, and Smalltalk, are used to write software that is flexible, extensible, and reusable—the three axioms of object-oriented development. In business systems, object-oriented languages are used to improve development of GUIs, to simplify access to data, and to encapsulate the business logic. The encapsulation of business logic into business objects is a fairly recent focus in the information-technology industry. Business is fluid, which means that a business's products, processes, and objectives evolve over time. If the software that models the business can be encapsulated into business objects, it becomes flexible, extensible, and reusable, and therefore evolves as the business evolves.
A server-side component model may define an architecture for developing distributed business objects that combine the accessibility of distributed object systems with the fluidity of objectified business logic. Server-side component models are used on the middle-tier application servers, which manage the components at runtime and make them available to remote clients. They provide a baseline of functionality that makes it easy to develop distributed business objects and assemble them into business solutions.
Server-side components can also be used to model other aspects of a business system, such as presentation and routing. The Java servlet, for example, is a server-side component that is used to generate HTML and XML data for the presentation layer of a three-tier architecture. EJB 2.0 message-driven beans, which are discussed later in this book, are server-side components that are used to consume and process asynchronous messages.
Server-side components, like other components, can be bought and sold as independent pieces of executable software. They conform to a standard component model and can be executed without direct modification in a server that supports that component model. Server-side component models often support attribute-based programming, which allows the runtime behavior of the component to be modified when it is deployed, without having to change the programming code in the component. Depending on the component model, the server administrator can declare a server-side component's transactional, security, and even persistence behavior by setting these attributes to specific values.
As an organization's services, products, and operating procedures evolve, server-side components can be reassembled, modified, and extended so that the business system reflects those changes. Imagine a business system as a collection of server-side components that model concepts such as customers, products, reservations, and warehouses. Each component is like a Lego™ block that can be combined with other components to build a business solution. Products can be stored in the warehouse or delivered to a customer; a customer can make a reservation or purchase a product. You can assemble components, take them apart, use them in different combinations, and change their definitions. A business system based on server-side components is fluid because it is objectified, and it is accessible because the components can be distributed.
1.1.3 Component Transaction Monitors
A new breed of software called application servers has recently evolved to manage the complexities associated with developing business systems in today's Internet world. An application server is often made up of some combination of several different technologies, including web servers, object request brokers (ORBs), message-oriented middleware ( MOM), databases, and so forth. An application server can also focus on one technology, such as distributed objects. Application servers that are based on distributed objects vary in sophistication. The simplest are ORBs, which facilitate connectivity between the client applications and the distributed objects. ORBs allow client applications to locate and use distributed objects easily. However, ORBs have frequently proven to be inadequate in high-volume transactional environments. They provide a communication backbone for distributed objects but fail to provide the kind of robust infrastructure that is needed to handle larger user populations and mission-critical work. In addition, ORBs provide a fairly crude server-side component model that places the burden of handling transactions, concurrency, persistence, and other system-level considerations on the shoulders of the application developer. These services are not automatically supported in an ORB. Application developers must explicitly access these services (if they are available) or, in some cases, develop them from scratch.
Early in 1999, Anne Manes[2] coined the term component transaction monitor (CTM) to describe the most sophisticated distributed object application servers. CTMs evolved as a hybrid of traditional TP monitors and ORB technologies. They implement robust server-side component models that make it easier for developers to create, use, and deploy business systems. CTMs provide an infrastructure that can automatically manage transactions, object distribution, concurrency, security, persistence, and resource management. They are capable of handling huge user populations and mission-critical work but also provide value to smaller systems because they are easy to use. CTMs are the ultimate application servers. Other terms for these kinds of technology include object transaction monitor (OTM), component transaction server, distributed component server, and COMware. This book uses the term "component transaction monitor" because it embraces the three key characteristics of this technology: the use of a component model, the focus on transactional management, and the resource and service management typically associated with monitors.
1.2 Enterprise JavaBeans Defined
Sun Microsystems' definition of Enterprise JavaBeans is:
The Enterprise JavaBeans architecture is a component architecture for the development and deployment of component-based distributed business applications. Applications written using the Enterprise JavaBeans architecture are scalable, transactional, and multi-user secure. These applications may be written once, and then deployed on any server platform that supports the Enterprise JavaBeans specification.[3]
That's a mouthful, but it's not atypical of how Sun defines many of its Java technologies—have you ever read the definition of the Java language itself? It's about twice as long. This book offers a shorter definition of EJB:
Enterprise JavaBeans is a standard server-side component model for component transaction monitors.
We have already set the stage for this definition by briefly defining the terms "distributed objects," "server-side components," and "component transaction monitors." To provide you with a complete and solid foundation for learning about Enterprise JavaBeans, this chapter will now expand on these definitions.
If you already have a clear understanding of distributed objects, transaction monitors, CTMs, and asynchronous messaging, feel free to skip the rest of this chapter and move on to Chapter 2.
1.3 Distributed Object Architectures
EJB is a component model for component transaction monitors, which are based on distributed object technologies. Therefore, to understand EJB you need to understand how distributed objects work. Distributed object systems are the foundation for modern three-tier architectures. In a three-tier architecture, as shown in Figure 1-1, the presentation logic resides on the client (first tier), the business logic resides on the middle tier (second tier), and other resources, such as the database, reside on the backend (third tier).
Figure 1-1. Three-tier architecture
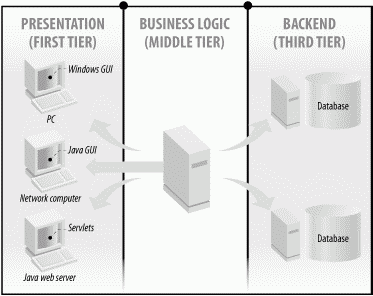
All distributed object protocols are built on the same basic architecture, which is designed to make an object on one computer look like it's residing on a different computer. Distributed object architectures are based on a network communication layer that is really very simple. Essentially, there are three parts to this architecture: the business object, the skeleton, and the stub.
The business object resides on the middle tier. It's an instance of an object that models the state and business logic of some real-world concept, such as a person, order, or account. Every business object class has matching stub and skeleton classes built specifically for that type of business object. So, for example, a distributed business object called Person would have matching Person_Stub and Person_Skeleton classes. As shown in Figure 1-2, the business object and skeleton reside on the middle tier, and the stub resides on the client.
The stub and the skeleton are responsible for making the business object on the middle tier look as if it is running locally on the client machine. This is accomplished through some kind of remote method invocation ( RMI) protocol. An RMI protocol is used to communicate method invocations over a network. CORBA, Java RMI, and Microsoft .NET all use their own RMI protocols.[4] Every instance of the business object on the middle tier is wrapped by an instance of its matching skeleton class. The skeleton is set up on a port and IP address and listens for requests from the stub, which resides on the client machine and is connected via the network to the skeleton. The stub acts as the business object's surrogate on the client and is responsible for communicating requests from the client to the business object through the skeleton. Figure 1-2 illustrates the process of communicating a method invocation from the client to the server object and back. The stub and the skeleton hide the communication specifics of the RMI protocol from the client and the implementation class, respectively.
Figure 1-2. RMI loop
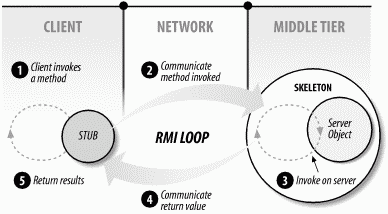
The business object implements a public interface that declares its business methods. The stub implements the same interface as the business object, but the stub's methods do not contain business logic. Instead, the business methods on the stub implement whatever networking operations are required to forward the request to the business object and receive the results. When a client invokes a business method on the stub, the request is communicated over the network by streaming the name of the method invoked, and the values passed in as parameters, to the skeleton. When the skeleton receives the incoming stream, it parses the stream to discover which method is requested, then invokes the corresponding business method on the business object. Any value that is returned from the method invoked on the business object is streamed back to the stub by the skeleton. The stub then returns the value to the client application as if it had processed the business logic locally.
1.3.1 Rolling Your Own Distributed Object
The best way to illustrate how distributed objects work is to show how you can implement a distributed object yourself, with your own distributed object protocol. This will give you some appreciation for what a true distributed object protocol like CORBA does. Actual distributed object systems such as DCOM, CORBA, and Java RMI are, however, much more complex and robust than the simple example we will develop here. The distributed object system we develop in this chapter is only illustrative; it is not a real technology, nor is it part of Enterprise JavaBeans. The purpose is to provide you with some understanding of how a more sophisticated distributed object system works.
Here's a very simple distributed business object called PersonServer that implements the Person interface. The Person interface captures the concept of a person business object. It has two business methods: getAge() and getName(). In a real application, we would probably define many more behaviors for the Person business object, but two methods are enough for this example:
public interface Person {
public int getAge() throws Throwable;
public String getName() throws Throwable;
}
The implementation of this interface, PersonServer, doesn't contain anything surprising. It defines the business logic and state for the Person:
public class PersonServer implements Person {
int age;
String name;
public PersonServer(String name, int age){
this.age = age;
this.name = name;
}
public int getAge(){
return age;02. }
public String getName(){
return name;
}
}
Now we need some way to make the PersonServer available to a remote client. That's the job of the Person_Skeleton and Person_Stub. The Person interface describes the concept of a person independent of implementation. Both the PersonServer and the Person_Stub implement the Person interface because they are both expected to support the concept of a person. The PersonServer implements the interface to provide the actual business logic and state; the Person_Stub implements the interface so that it can look like a Person business object on the client and relay requests back to the skeleton, which in turn sends them to the object itself. Here's what the stub looks like:
import java.io.ObjectOutputStream;
import java.io.ObjectInputStream;
import java.net.Socket;
public class Person_Stub implements Person {
Socket socket;
public Person_Stub() throws Throwable {
/* Create a network connection to the skeleton.
Use "localhost" or the IP Address of the skeleton
if it's on a different machine. */
socket = new Socket("localhost",9000);
}
public int getAge() throws Throwable {
// When this method is invoked, stream the method name to the skeleton.
ObjectOutputStream outStream =
new ObjectOutputStream(socket.getOutputStream());
outStream.writeObject("age");
outStream.flush();
ObjectInputStream inStream =
new ObjectInputStream(socket.getInputStream());
return inStream.readInt();
}
public String getName() throws Throwable {
// When this method is invoked, stream the method name to the skeleton.
ObjectOutputStream outStream =
new ObjectOutputStream(socket.getOutputStream());
outStream.writeObject("name");
outStream.flush();
ObjectInputStream inStream =
new ObjectInputStream(socket.getInputStream());
return (String)inStream.readObject();
}
}
When a method is invoked on the Person_Stub, a String token is created and streamed to the skeleton. The token identifies the method that was invoked on the stub. The skeleton parses the method-identifying token, invokes the corresponding method on the business object, and streams back the result. When the stub reads the reply from the skeleton, it parses the value and returns it to the client. From the client's perspective, the stub processes the request locally. Now let's look at the skeleton:
import java.io.ObjectOutputStream;
import java.io.ObjectInputStream;
import java.net.Socket;
import java.net.ServerSocket;
public class Person_Skeleton extends Thread {
PersonServer myServer;
public Person_Skeleton(PersonServer server){
// Get a reference to the business object that this skeleton wraps.
this.myServer = server;
}
public void run(){
try {
// Create a server socket on port 9000.
ServerSocket serverSocket = new ServerSocket(9000);
// Wait for and obtain a socket connection from the stub.
Socket socket = serverSocket.accept();
while (socket != null){
// Create an input stream to receive requests from the stub.
ObjectInputStream inStream =
new ObjectInputStream(socket.getInputStream());
// Read the next method request from the stub. Block until the
// request is sent.
String method = (String)inStream.readObject();
// Evaluate the type of method requested.
if (method.equals("age")){
// Invoke the business method on the server object.
int age = myServer.getAge();
// Create an output stream to send return values back to
// the stub.
ObjectOutputStream outStream =
new ObjectOutputStream(socket.getOutputStream());
// Send results back to the stub.
outStream.writeInt(age);
outStream.flush();
} else if(method.equals("name")){
// Invoke the business method on the server object.
String name = myServer.getName();
// Create an output stream to send return values back to
// the stub.
ObjectOutputStream outStream =
new ObjectOutputStream(socket.getOutputStream());
// Send results back to the stub.
outStream.writeObject(name);
outStream.flush();
}
}
} catch(Throwable t) {t.printStackTrace();System.exit(0); }
}
public static void main(String args [] ){
// Obtain a unique Person instance .
PersonServer person = new PersonServer("Richard", 36);
Person_Skeleton skel = new Person_Skeleton(person);
skel.start();
}
}
The Person_Skeleton routes requests received from the stub to the business object, PersonServer. Essentially, the Person_Skeleton spends all its time waiting for the stub to stream it a request. Once a request is received, it is parsed and delegated to the corresponding method on the PersonServer. The return value from the business object is then streamed back to the stub, which returns it as if it was processed locally.
Now that we've created all the machinery, let's look at a simple client that makes use of the Person:
public class PersonClient {
public static void main(String [] args){
try {
Person person = new Person_Stub();
int age = person.getAge();
String name = person.getName();
System.out.println(name+" is "+age+" years old");
} catch(Throwable t) {t.printStackTrace();}
}
}
This client application shows how the stub is used on the client. Except for the instantiation of the Person_Stub at the beginning, the client is unaware that the Person business object is actually a network proxy to the real business object on the middle tier. In Figure 1-3, the RMI loop diagram is changed to represent the RMI process as applied to our code.
Figure 1-3. RMI loop with Person business object
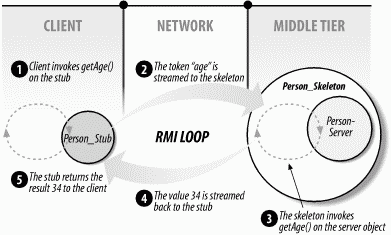
As you examine Figure 1-3, notice how the RMI loop was implemented by our distributed Person object. RMI is the basis of distributed object systems and is responsible for making distributed objects location transparent. Location transparency means that a server object's actual location—usually on the middle tier—is unknown and unimportant to the client using it. In this example, the client could be located on the same machine or on a different machine very far away, but the client's interaction with the business object is the same. One of the biggest benefits of distributed object systems is location transparency. Although transparency is beneficial, you cannot treat distributed objects as local objects in your design because of the performance differences. This book will provide you with good distributed object design strategies that take advantage of transparency while maximizing the distributed system's performance.
When this book talks about the stub on the client, we will often refer to it as a remote reference to the business object. This allows us to talk more directly about the business object and its representation on the client.
Distributed object protocols such as CORBA, DCOM, and Java RMI provide much more infrastructure for distributed objects than the Person example. Most implementations of distributed object protocols provide utilities that automatically generate the appropriate stubs and skeletons for business objects. This eliminates custom development of these constructs and allows much more functionality to be included in the stub and skeleton.
Even with automatic generation of stubs and skeletons, the Person example hardly scratches the surface of a sophisticated distributed object protocol. Real-world protocols such as Java RMI and CORBA IIOP provide error- and exception-handling, parameter-passing, and other services such as the passing of transaction and security context. In addition, distributed object protocols support much more sophisticated mechanisms for connecting the stub to the skeleton. The direct stub-to-skeleton connection in the Person example is fairly primitive.
Real distributed object protocols, like CORBA, also provide an object request broker, which allows clients to locate and communicate with distributed objects across the network. ORBs are the communication backbone, the switchboard, for distributed objects. In addition to handling communications, ORBs generally use a naming system for locating objects and many other features such as reference passing, distributed garbage collection, and resource management. However, ORBs are limited to facilitating communication between clients and distributed business objects. While they may support services like transaction management and security, use of these services is not automatic. With ORBs, most of the responsibility for creating system-level functionality or incorporating services falls on the shoulders of the application developer.
1.4 Component Models
The term "component model" has many different interpretations. Enterprise JavaBeans specifies a server-side component model. Using a set of classes and interfaces from the javax.ejb package, developers can create, assemble, and deploy components that conform to the EJB specification.
The original JavaBeans™ is also a component model, but it's not a server-side component model like EJB. In fact, other than sharing the name "JavaBeans," these two component models are completely unrelated. In the past, a lot of the literature referred to EJB as an extension of the original JavaBeans, but this is a misrepresentation. The two APIs serve very different purposes, and EJB does not extend or use the original JavaBeans component model.
JavaBeans is intended to be used for intraprocess purposes, while EJB is designed for inter process components. In other words, the original JavaBeans was not intended for distributed components. JavaBeans can be used to solve a variety of problems, but it is primarily used to build clients by assembling visual (GUI) and nonvisual widgets. It's an excellent component model, possibly the best one ever devised for intraprocess development, but it's not a server-side component model. EJB, on the other hand, is explicitly designed to address issues involved with managing distributed business objects in a three-tier architecture.
Given that JavaBeans and Enterprise JavaBeans are completely different, why are they both called component models? In this context, a component model defines a set of contracts between the component developer and the system that hosts the component. The contracts express how a component should be developed and packaged. Once a component is defined, it becomes an independent piece of software that can be distributed and used in other applications. A component is developed for a specific purpose but not a specific application. In the original JavaBeans, a component might be a push button or a spreadsheet that can be used in any GUI application according to the rules specified in the original JavaBeans component model. In EJB, a component might be a customer business object that can be deployed in any EJB server and used to develop any business application that needs a customer business object. Other types of Java component models include servlets, JSP pages ( JSPs), and applets.
1.5 Component Transaction Monitors
The CTM industry grew out of both the ORB and TP monitor industries. The CTM is really a hybrid of these two technologies that provides a powerful, robust distributed object platform. To better understand what a CTM is, we will examine the strengths and weakness of TP monitors and ORBs.
1.5.1 Transaction Processing Monitors
Transaction processing (TP) monitors have been evolving for about 30 years (CICS, the Customer Information Control System, was introduced in 1968) and have become powerful, high-speed server platforms for mission-critical applications. Some TP products, such as CICS and TUXEDO, may be familiar to you. TP monitors are operating systems for business applications written in languages such as COBOL. It may seem strange to call a TP monitor an "operating system," but because it controls an application's entire environment, it's a fitting description. TP monitor systems automatically manage the entire environment in which a business application runs, including transactions, resource management, and fault tolerance. The business applications that run in TP monitors are written in procedural programming languages (e.g., COBOL and C) that are often accessed through network messaging or remote procedure calls (RPCs). Messaging allows a client to send a message to a TP monitor requesting that some application be run with certain parameters. It's similar in concept to the Java event model. Messaging can be synchronous or asynchronous, meaning that the sender may or may not be required to wait for a response. RPC, which is the ancestor of RMI, is a distributed mechanism that allows clients to invoke procedures on applications in a TP monitor as though the procedures were executed locally. The primary difference between RPC and RMI is that RPC is used for procedure-based applications and RMI is used for distributed object systems. With RMI, methods can be invoked on a specific object identity; i.e., a specific business entity. In RPC, a client can call procedures on a specific type of application, but there is no concept of object identity. RMI is object-oriented; RPC is procedural.
TP monitors have been around for a long time, so the technology behind them is as solid as a rock; that is why they are used in many mission-critical systems today. But TP monitors are not object-oriented. Instead, they work with procedural code that can perform complex tasks but has no sense of identity. Accessing a TP monitor through RPC is like executing a static method; there's no such thing as a unique object. In addition, because TP monitors are based on procedural applications and not on objects, the business logic in a TP monitor is not as flexible, extensible, or reusable as business objects in a distributed object system.
1.5.2 Object Request Brokers
Distributed object systems allow unique objects that have state and identity to be accessed across a network. Distributed object technologies like CORBA and Java RMI grew out of RPC with one significant difference: when you invoke a distributed object method, it's on an object instance, not an application procedure. Distributed objects are usually deployed on some kind of ORB, which is responsible for helping client applications find distributed objects easily.
ORBs, however, do not define an "operating system" for distributed objects. They are simply communications backbones that are used to access and interact with unique remote objects. When you develop a distributed object application using an ORB, all the responsibility for concurrency, transactions, resource management, and fault tolerance falls on your shoulders. These services may be supported by an ORB, but the application developer is responsible for incorporating them into the business objects. In an ORB, there is no concept of an operating system in which system-level functionality is handled automatically. The lack of implicit system-level infrastructure places an enormous burden on the application developer. Developing the infrastructure required to handle concurrency, transactions, security, persistence, and everything else needed to support large user populations is a Herculean task that few corporate development teams are equipped to accomplish.
1.5.3 CTMs: The Hybrid of ORBs and TP Monitors
As the advantages of distributed objects became apparent, the number of systems deployed using ORBs increased rapidly. ORBs support distributed objects by employing a somewhat crude server-side component model that allows distributed objects to be connected to a communication backbone, but they don't implicitly support transactions, security, persistence, and resource management. These services must be explicitly accessed through APIs by the distributed object, resulting in more complexity and, frequently, more development problems. In addition, resource-management strategies such as instance swapping, resource pooling, and activation may not be supported at all. These types of strategies make it possible for a distributed object system to scale, improving performance and throughput and reducing latency. Without automatic support for resource management, application developers must implement homegrown resource-management solutions, which requires a very sophisticated understanding of distributed object systems. ORBs fail to address the complexities of managing a component in a high-volume, mission-critical environment, an area in which TP monitors have always excelled.
With three decades of TP-monitor experience, it wasn't long before companies such as IBM and BEA began developing a hybrid of ORBs and TP-monitor systems, which we refer to as component transaction monitors (CTMs). These types of application servers combine the fluidity and accessibility of distributed object systems based on ORBs with the robust "operating system" of a TP monitor. CTMs provide a comprehensive environment for server-side components by automatically managing concurrency, transactions, object distribution, load balancing, security, and resource management. While application developers still need to be aware of these facilities, they don't have to explicitly implement them when using a CTM.
The basic features of a CTM are distributed objects, an infrastructure that includes transaction management and other services, and a server-side component model. CTMs support these features in varying degrees; choosing the most robust and feature-rich CTM is not always as critical as choosing one that best meets your needs. Very large and robust CTMs can be enormously expensive and may be overkill for smaller projects. CTMs have come out of several areas, including the relational database, application server, web server, CORBA ORB, and TP monitor industries. Each vendor offers products that reflect their particular area of expertise. However, when you're getting started, choosing a CTM that supports the Enterprise JavaBeans component model may be much more important than any particular feature set. Because Enterprise JavaBeans is implementation independent, choosing an EJB CTM provides the business system with the flexibility to scale to larger CTMs as needed. We will discuss the importance of EJB as a standard component model for CTMs later in this chapter.
1.5.4 Analogies to Relational Databases
This chapter spends a lot of time talking about CTMs because they are essential to the definition of EJB. The discussion of CTMs is not over, but to make things as clear as possible before proceeding, we will use relational databases as an analogy for CTMs.
Relational databases provide a simple development environment for application developers, in combination with a robust infrastructure for data. As an application developer using a relational database, you might design the table layouts, decide which columns are primary keys, and define indexes and stored procedures, but you don't develop the indexing algorithm, the SQL parser, or the cursor-management system. These types of system-level functionality are left to the database vendor; you simply choose the product that best fits your needs. Application developers are concerned with how business data is organized, not how the database engine works. It would be a waste of resources for an application developer to write a relational database from scratch when vendors such as Microsoft and Oracle already provide them.
Distributed business objects, if they are to be effective, require the same system-level management from CTMs as business data requires from relational databases. System-level functionality like concurrency, transaction management, and resource management is necessary if the business system is going to be used for large user populations or mission-critical work. It is unrealistic and wasteful to expect application developers to reinvent this system-level functionality when commercial solutions already exist.
CTMs are to business objects what relational databases are to data. CTMs handle all the system-level functionality, allowing the application developer to focus on the business problems. With a CTM, application developers can focus on the design and development of the business objects without having to waste thousands of hours developing the infrastructure in which the business objects operate.
1.6 CTMs and Server-Side Component Models
CTMs require that business objects adhere to the server-side component model implemented by the vendor. A good component model is critical to the success of a development project because it defines how easily an application developer can write business objects for the CTM. The component model is a contract that defines the responsibilities of the CTM and the business objects. With a good component model, a developer knows what to expect from the CTM, and the CTM understands how to manage the business object. Server-side component models are great at describing the responsibilities of the application developer and CTM vendor.
Server-side component models are based on a specification. As long as the component adheres to the specification, it can be used by the CTM. The relationship between the server-side component and the CTM is like the relationship between a CD-ROM and a CD player. As long as the component (CD-ROM) adheres to the player's specifications, you can play it.
A CTM's relationship with its component model is also similar to the relationship the railway system has with trains. The railway system manages the train's environment, providing alternate routes for load balancing, multiple tracks for concurrency, and a traffic-control system for managing resources. The railway provides the infrastructure on which trains run. Similarly, a CTM provides server-side components with the entire infrastructure needed to support concurrency, transactions, load balancing, etc.
Trains on the railway are like server-side components: they all perform different tasks but they do so using the same basic design. The train focuses on performing a task, such as moving cars, not on managing the environment. For the engineer, the person driving the train, the interface for controlling the train is fairly simple: a brake and a throttle. For the application developer, the interface to the server-side component is similarly limited.
Different CTMs may implement different component models, just as different railways have different kinds of trains. The differences between the component models vary, like railway systems having different track widths and different controls, but the fundamental operations of CTMs are the same. They all ensure that business objects are managed so that they can support large populations of users in mission-critical situations. This means that resources, concurrency, transactions, security, persistence, load balancing, and distribution of objects can be handled automatically, limiting the application developer to a simple interface. This allows the application developer to focus on the business logic instead of the enterprise infrastructure.
1.6.1 Microsoft's .NET Framework
Microsoft was the first vendor to ship a CTM. Originally called the Microsoft Transaction Server (MTS), it was later renamed COM+. Microsoft's COM+ is based on the Component Object Model (COM), originally designed for use on the desktop but eventually pressed into service as a server-side component model. For distributed access, COM+ clients use the Distributed Component Object Model (DCOM).
When MTS was introduced in 1996, it was exciting because it provided a comprehensive environment for business objects. With MTS, application developers could write COM components without worrying about system-level concerns. Once a business object was designed to conform to the COM model, MTS (and now COM+) would take care of everything else, including transaction management, concurrency, and resource management.
Recently, COM+ has become part of Microsoft's new .NET Framework. The core functionality provided by COM+ services remains essentially the same in .NET, but the way it appears to a developer has changed significantly. Rather than writing components as COM objects, .NET Framework developers build applications as managed objects. All managed objects, and in fact all code written for the .NET Framework, depends on a Common Language Runtime (CLR). For Java-oriented developers, the CLR is much like a Java virtual machine (VM), and a managed object is analogous to an instance of a Java class; i.e., to a Java object.
Although the .NET Framework provides many interesting features, as an open standard, it falls short. The COM+ services in the .NET Framework are Microsoft's proprietary CTM, which means that using this technology binds you to the Microsoft platform. This may not be so bad, because .NET promises to work well, and the Microsoft platform is pervasive. In addition, the .NET Framework's support for the Simple Object Access Protocol (SOAP) will enable business objects in the .NET world to communicate with objects on any other platform written in any language. This can potentially make business objects in .NET universally accessible, a feature that is not easily dismissed.
If, however, your company is expected to deploy server-side components on a non-Microsoft platform, .NET is not a viable solution. In addition, the COM+ services in the .NET Framework are focused on stateless components; there's no built-in support for persistent transactional objects. Although stateless components can offer higher performance, business systems need the kind of flexibility offered by CTMs that include stateful and persistent components.
1.6.2 EJB and CORBA CTMs
Until the fall of 1997, non-Microsoft CTMs were pretty much nonexistent. Promising products from IBM, BEA, and Hitachi were on the drawing board, while MTS was already on the market. Although the non-MTS designs were only designs, they all had one thing in common: they used CORBA as a distributed object service.
Most non-Microsoft CTMs were focused on what was at the time the more open standard of CORBA, so they could be deployed on non-Microsoft platforms and support non-Microsoft clients. CORBA is both language and platform independent, so CORBA CTM vendors could provide their customers with more implementation options.[5] The problem with CORBA CTM designs was that they all had different server-side component models. In other words, if you developed a component for one vendor's CTM, you couldn't turn around and use that same component in another vendor's CTM. The component models were too different.
With Microsoft's MTS far in the lead by 1997 (it had already been around for a year), CORBA-based CTM vendors needed a competitive advantage. One problem CTMs faced was a fragmented CORBA market in which each vendor's product was different from the next. A fragmented market didn't benefit anyone, so the CORBA CTM vendors needed a standard around which to rally. Besides the CORBA protocol, the most obvious standard needed was a component model, which would allow clients and third-party vendors to develop their business objects to one specification that would work in any CORBA CTM. Microsoft was, of course, pushing their component model as a standard—which was attractive because MTS was an actual working product—but Microsoft didn't support CORBA. The Object Management Group (OMG), the same people who developed the CORBA standard, were defining an alternative server-side component model. This model held promise because it was sure to be tailored to CORBA, but the OMG was slow in developing a standard—too slow for the evolving CTM market.[6]
In 1997, Sun Microsystems was developing the most promising standard yet for server-side components: Enterprise JavaBeans. Sun offered some key advantages. First, Sun was respected and was known for working with vendors to define Java-based and vendor-agnostic APIs for common services. Sun had a habit of adopting the best ideas in the industry and then making the Java implementation an open standard—usually successfully. The Java database connectivity API, called JDBC, was a perfect example. Based largely on Microsoft's ODBC, JDBC offered vendors a more flexible model for plugging in their own database access drivers. In addition, developers found the JDBC API much easier to work with than ODBC. Sun was doing the same thing in its newer technologies, such as the JavaMail API and the Java Naming and Directory Interface ( JNDI). These technologies were still being defined, but the collaboration among vendors was encouraging, and the openness of the APIs was attractive.
Although CORBA offered an open standard, it attempted to standardize low-level facilities such as security and transactions. Vendors could not justify rewriting existing products such as TUXEDO and CICS to the CORBA standards. EJB got around that problem by saying that how you implement the low-level services doesn't matter; all that matters is that all the facilities are applied to the components according to the specification—a much more palatable solution for existing and prospective CTM vendors. In addition, the Java language offered some pretty enticing advantages, not all of them purely technical. First, Java was a hot and sexy technology, and simply making your product Java-compatible seemed to boost your exposure in the market. Java was more or less platform independent, and component models defined in the Java language had definite marketing and technical benefits.
As it turned out, Sun had not been idle after it announced Enterprise JavaBeans. Sun's engineers had been working with several leading vendors to define a flexible and open standard to which vendors could easily adapt their existing products. This was a tall order because vendors had various kinds of servers, including web servers, relational database servers, application servers, and early CTMs. It's likely that no one wanted to sacrifice their architecture for the common good, but eventually the vendors agreed on a model that was flexible enough to accommodate different implementations yet solid enough to support real mission-critical development. In December of 1997, Sun Microsystems released the first draft specification of Enterprise JavaBeans, EJB 1.0, and vendors have been flocking to the server-side component model ever since.
1.6.3 Benefits of a Standard Server-Side Component Model
So what does it mean to be a standard server-side component model? Quite simply, it means that you can develop business objects using the Enterprise JavaBeans component model and expect them to work in any CTM that supports the complete EJB specification. This is a pretty powerful statement, because it largely eliminates the biggest problem faced by potential customers of CORBA-based CTM products: fear of vendor "lock-in." With a standard server-side component model, customers can commit to using an EJB-compliant CTM with the knowledge that they can migrate to a better CTM if one becomes available. Obviously, care must be taken when using proprietary extensions developed by vendors, but this is nothing new. Even in the relational database industry—which has been using the SQL standard for a couple of decades—optional proprietary extensions abound.
Having a standard server-side component model has benefits beyond implementation independence. A standard component model provides a vehicle for growth in the third-party products. If numerous vendors support EJB, creating add-on products and component libraries is more attractive to software vendors. The IT industry has seen this type of cottage industry grow up around other standards, such as SQL; hundreds of add-on products can now be purchased to enhance business systems whose data is stored in SQL-compliant relational databases. Report-generating tools and data-warehouse products are typical examples. The GUI component industry has also seen the growth of its own third-party products. A healthy market for component libraries already exists for GUI component models such as Microsoft's ActiveX and Sun's original JavaBeans component model.
Many third-party products for Enterprise JavaBeans exist today. Add-on products for credit card processing, legacy database access, and other business services have been introduced for various EJB-compliant systems. These types of products make development of EJB systems simpler and faster than the alternatives, making the EJB component model attractive to corporate IS and server vendors alike. The market is growing for prepackaged EJB components in several domains, including sales, finance, education, web-content management, collaboration, and other areas.
1.6.4 EJB 2.0: Asynchronous Messaging
In addition to supporting RMI-based distributed business objects, Enterprise JavaBeans 2.0 supports advanced asynchronous messaging. Asynchronous messaging is an important distributed computing paradigm that has become an important part of EJB.
An asynchronous messaging system allows two or more applications to exchange information in the form of messages. A message, in this case, is a self-contained package of business data and network-routing headers. The business data contained in a message can be anything—depending on the business scenario—and usually contains information about some business transaction. In enterprise messaging systems, messages inform an application of some event or occurrence in another system.
Messages are transmitted from one application to another on a network using message-oriented middleware (MOM). MOM products ensure that messages are properly distributed among applications. In addition, MOM usually provides fault tolerance, load balancing, scalability, and transactional support for enterprises that need to reliably exchange large quantities of messages.
MOM vendors use different message formats and network protocols for exchanging messages, but the basic semantics are the same. An API is used to create a message, give it a payload (application data), assign it routing information, and then send the message. The same API is used to receive messages produced by other applications.
In all modern enterprise-messaging systems, applications exchange messages through virtual channels called destinations. When you send a message, it's addressed to a destination, not to a specific application. Any application that subscribes or registers an interest in that destination may receive that message. In this way, the applications that receive messages and those that send messages are decoupled. Senders and receivers are not bound to each other in any way and may send and receive messages as they see fit.
Enterprise JavaBeans 2.0 integrates the functionality of MOM into its component model for CTMs. This integration extends the EJB platform's "operating system" so that it supports both RMI and asynchronous messaging. EJB 2.0 supports asynchronous messaging through the Java Message Service and a new kind of component called the message-driven bean.
1.6.4.1 Java Message Service
Each MOM vendor implements its own networking protocols, routing, and administration facilities, but the basic semantics of the developer API provided by different MOMs are the same. It's this similarity in APIs that makes the Java Message Service ( JMS) possible.
JMS is a vendor-agnostic Java API that can be used with many different MOM vendors. JMS is very similar to JDBC in that an application developer can reuse the same API to access many different systems. If a vendor provides a compliant service provider for JMS, the JMS API can be used to send messages to and receive messages from that vendor. For example, you can use the same JMS API to send messages with Progress' SonicMQ as with IBM's MQSeries.
1.6.4.2 Message-driven beans
All JMS vendors provide application developers with the same API for sending and receiving messages, and sometimes they provide a component model for developing routers that can receive and send messages. These component models, however, are proprietary and not portable across MOM vendors.
Enterprise JavaBeans 2.0 introduces a new kind of component, called a message-driven bean, which is a kind of standard JMS bean. It can receive and send asynchronous JMS messages, and because it's co-located with other kinds of RMI beans (i.e., entity and session beans) it can also interact with RMI components.
Message-driven beans in EJB 2.0 act as an integration point for an EJB application, allowing other applications to send asynchronous messages that can be captured and processed by the application. This is an extremely important feature that will allow EJB applications to better integrate with legacy and other proprietary systems.
Message-driven beans are also transactional and require all the infrastructure associated with other RMI-based transactional server-side components. Like other RMI-based components, message-driven beans are considered business objects, which fulfill the important role of routing and interpreting requests and coordinating the application of those requests against other RMI-based components, namely enterprise beans. Message-driven beans are a good fit for the CTM landscape and are an excellent addition to the EJB platform.
1.7 Titan Cruises: An Imaginary Business
To make things a little easier, and more fun, we will discuss all the concepts in this book in the context of one imaginary business, a cruise line called Titan. A cruise line makes a particularly interesting example because it incorporates several different businesses: it has ship cabins that are similar to hotel rooms, it serves meals like a restaurant, it offers various recreational opportunities, and it needs to interact with other travel businesses.
This type of business is a good candidate for a distributed object system because many of the system's users are geographically dispersed. Commercial travel agents, for example, who need to book passage on Titan ships will need to access the reservation system. Supporting many—possibly hundreds—of travel agents requires a robust transactional system to ensure that agents have access and that reservations are completed properly.
Throughout this book, we will build a fairly simple slice of Titan's EJB system that focuses on the process of making a reservation for a cruise. This will give us an opportunity to develop Ship, Cabin, TravelAgent, ProcessPayment, and other enterprise beans. In the process, you will need to create relational database tables for persisting data used in the example. It is assumed that you are familiar with relational database management systems and that you can create tables according to the SQL statements provided. EJB can be used with any kind of database or legacy application, but relational databases seem to be the most commonly understood database, so we have chosen this as the persistence layer.
1.8 What's Next?
To develop business objects using EJB, you have to understand the life cycle and architecture of EJB components. This means understanding conceptually how EJB's components are managed and made available as distributed objects. Developing an understanding of the EJB architecture is the focus of the next two chapters.
[1] Provided that the bean components and EJB servers comply with the specification, and no proprietary functionality is used in development.
[2] At the time that Ms. Manes coined the term, she worked for the Patricia Seybold Group under the name Anne Thomas. Ms. Manes is now the Director of Business Strategy for Sun Microsystems, Sun Software division.
[3] Sun Microsystems' Enterprise JavaBeans™ Specification, v2.0, Copyright 2001 by Sun Microsystems, Inc.
[4] The acronym RMI isn't specific to Java RMI. This section uses the term RMI to describe distributed object protocols in general. Java RMI is the Java language version of a distributed object protocol.
[5] The recent introduction of SOAP brings into question the future of the CORBA Internet Inter-Operability Protocol (IIOP). It's obvious that these two protocols are competing to become the standard language-independent protocol for distributed computing. IIOP has been around for several years and is therefore far more mature, but SOAP may quickly catch up by leveraging lessons learned in the development of IIOP.
[6] CORBA's CTM component model, the CORBA Component Model (CCM), was eventually released. It has seen lackluster acceptance in general, and was forced to adopt Enterprise JavaBeans as part of its component model just to be viable and interesting.
| CONTENTS |