Chapter 6
Name Service and Resolver ConfigurationContents:
The Resolver Library
How DNS Works
Running named
As we discussed in Chapter 2, Issues of TCP/IP Networking, TCP/IP networking may rely on different schemes to convert names into addresses. The simplest way is a host table stored in /etc/hosts. This is useful only for small LANs that are run by one single administrator and otherwise have no IP traffic with the outside world. The format of the hosts file has already been described in Chapter 5, Configuring TCP/IP Networking.
Alternatively, you can use the Berkeley Internet Name Domain service (BIND) for resolving hostnames to IP addresses. Configuring BIND can be a real chore, but once you've done it, you can easily make changes in the network topology. On Linux, as on many other Unixish systems, name service is provided through a program called named. At startup, it loads a set of master files into its internal cache and waits for queries from remote or local user processes. There are different ways to set up BIND, and not all require you to run a name server on every host.
This chapter can do little more than give a rough sketch of how DNS works and how to operate a name server. It should be sufficient if you have a small LAN and an Internet uplink. For the most current information, you may want to check the documentation contained in the BIND source package, which supplies manual pages, release notes, and the BIND Operator's Guide (BOG). Don't let this name scare you off; it's actually a very useful document. For a more comprehensive coverage of DNS and associated issues, you may find DNS and BIND by Paul Albitz and Cricket Liu (O'Reilly) a useful reference. DNS questions may be answered in a newsgroup called comp.protocols.tcp-ip.domains. For technical details, the Domain Name System is defined by RFC numbers 1033, 1034, and 1035.
The Resolver Library
The term resolver refers not to a special application, but to the resolver library. This is a collection of functions that can be found in the standard C library. The central routines are gethostbyname(2) and gethostbyaddr(2), which look up all IP addresses associated with a host name, and vice versa. They may be configured to simply look up the information in hosts, to query a number of DNS name servers, or to use the hosts database of Network Information Service (NIS).
The resolver functions read configuration files when they are invoked. From these configuration files, they determine what databases to query, in which order, and other details relevant to how you've configured your environment. The older Linux standard library, libc, used /etc/host.conf as its master configuration file, but Version 2 of the GNU standard library, glibc, uses /etc/nsswitch.conf. We'll describe each in turn, since both are commonly used.
The host.conf File
The /etc/host.conf tells the older Linux standard library resolver functions which services to use, and in what order.
Options in host.conf must appear on separate lines. Fields may be separated by white space (spaces or tabs). A hash sign (#) introduces a comment that extends to the next newline. The following options are available:
- order
This option determines the order in which the resolving services are tried. Valid options are bind for querying the name server, hosts for lookups in /etc/hosts, and nis for NIS lookups. Any or all of them may be specified. The order in which they appear on the line determines the order in which the respective services are tried.
- multi
multitakes on or off as options. This determines if a host in /etc/hosts is allowed to have several IP addresses, which is usually referred to as being "multi-homed." The default is off. This flag has no effect on DNS or NIS queries.
- nospoof
As we'll explain in the section "Reverse Lookups", DNS allows you to find the hostname belonging to an IP address by using the in-addr.arpa domain. Attempts by name servers to supply a false hostname are called spoofing. To guard against this, the resolver can be configured to check whether the original IP address is in fact associated with the obtained hostname. If not, the name is rejected and an error is returned. This behavior is turned on by setting nospoof on.
- alert
This option takes on or off as arguments. If it is turned on, any spoof attempts will cause the resolver to log a message to the syslog facility.
- trim
This option takes an argument specifying a domain name that will be removed from hostnames before lookup. This is useful for hosts entries, for which you might only want to specify hostnames without a local domain. If you specify your local domain name here, it will be removed from a lookup of a host with the local domain name appended, thus allowing the lookup in /etc/hosts to succeed. The domain name you add must end with the (.) character (e.g., :
linux.org.au.) iftrimis to work correctly.trim options accumulate; you can consider your host as being local to several domains.
A sample file for vlager is shown in Example 6.1.
Example 6.1: Sample host.conf File
# /etc/host.conf # We have named running, but no NIS (yet) order bind,hosts # Allow multiple addrs multi on # Guard against spoof attempts nospoof on # Trim local domain (not really necessary). trim vbrew.com.Resolver environment variables
The settings from host.conf may be overridden using a number of environment variables:
- RESOLV_HOST_CONF
This variable specifies a file to be read instead of /etc/host.conf.
- RESOLV_SERV_ORDER
This variable overrides the order option given in host.conf. Services are given as hosts, bind, and nis, separated by a space, comma, colon, or semicolon.
- RESOLV_SPOOF_CHECK
This variable determines the measures taken against spoofing. It is completely disabled by off. The values warn and warn off enable spoof checking by turning logging on and off, respectively. A value of * turns on spoof checks, but leaves the logging facility as defined in host.conf.
- RESOLV_MULTI
This variable uses a value of on or off to override the multi options from host.conf.
- RESOLV_OVERRIDE_TRIM_DOMAINS
This variable specifies a list of trim domains that override those given in host.conf. Trim domains were explained earlier when we discussed the trim keyword.
- RESOLV_ADD_TRIM_DOMAINS
This variable specifies a list of trim domains that are added to those given in host.conf.
The nsswitch.conf File
Version 2 of the GNU standard library includes a more powerful and flexible replacement for the older host.conf mechanism. The concept of the name service has been extended to include a variety of different types of information. Configuration options for all of the different functions that query these databases have been brought back into a single configuration file; the nsswitch.conf file.
The nsswitch.conf file allows the system administrator to configure a wide variety of different databases. We'll limit our discussion to options that relate to host and network IP address resolution. You can easily find more information about the other features by reading the GNU standard library documentation.
Options in nsswitch.conf must appear on separate lines. Fields may be separated by whitespace (spaces or tabs). A hash sign (#) introduces a comment that extends to the next newline. Each line describes a particular service; hostname resolution is one of these. The first field in each line is the name of the database, ending with a colon. The database name associated with host address resolution is hosts. A related database is networks, which is used for resolution of network names into network addresses. The remainder of each line stores options that determine the way lookups for that database are performed.
The following options are available:
- dns
Use the Domain Name System (DNS) service to resolve the address. This makes sense only for host address resolution, not network address resolution. This mechanism uses the /etc/resolv.conf file that we'll describe later in the chapter.
- files
Search a local file for the host or network name and its corresponding address. This option uses the traditional /etc/hosts and /etc/network files.
- nis or nisplus
Use the Network Information System (NIS) to resolve the host or network address. NIS and NIS+ are discussed in detail in Chapter 13, The Network Information System.
The order in which the services to be queried are listed determines the order in which they are queried when attempting to resolve a name. The query-order list is in the service description in the /etc/nsswitch.conf file. The services are queried from left to right and by default searching stops when a resolution is successful.
A simple example of host and network database specification that would mimic our configuration using the older libc standard library is shown in Example 6.2.
Example 6.2: Sample nsswitch.conf File
# /etc/nsswitch.conf # # Example configuration of GNU Name Service Switch functionality. # Information about this file is available in the `libc6-doc' package. hosts: dns files networks: filesThis example causes the system to look up hosts first in the Domain Name System, and the /etc/hosts file, if that can't find them. Network name lookups would be attempted using only the /etc/networks file.
You are able to control the lookup behavior more precisely using "action items" that describe what action to take given the result of the previous lookup attempt. Action items appear between service specifications, and are enclosed within square brackets, [ ]. The general syntax of the action statement is:
[ [!] status = action ... ]There are two possible actions:
The optional (!) character specifies that the status value should be inverted before testing; that is, it means "not."
- return
Controls returns to the program that attempted the name resolution. If a lookup attempt was successful, the resolver will return with the details, otherwise it will return a zero result.
- continue
The resolver will move on to the next service in the list and attempt resolution using it.
The available status values on which we can act are:
- success
The requested entry was found without error. The default action for this status is return.
- notfound
There was no error in the lookup, but the target host or network could not be found. The default action for this status is continue.
- unavail
The service queried was unavailable. This could mean that the hosts or networks file was unreadable for the files service or that a name server or NIS server did not respond for the dns or nis services. The default action for this status is continue.
- tryagain
This status means the service is temporarily unavailable. For the files files service, this would usually indicate that the relevant file was locked by some process. For other services, it may mean the server was temporarily unable to accept connections. The default action for this status is continue.
A simple example of how you might use this mechanism is shown in Example 6.3.
Example 6.3: Sample nsswitch.conf File Using an Action Statement
# /etc/nsswitch.conf # # Example configuration of GNU Name Service Switch functionality. # Information about this file is available in the `libc6-doc' package. hosts: dns [!UNAVAIL=return] files networks: filesThis example attempts host resolution using the Domain Name Service system. If the return status is anything other than unavailable, the resolver returns whatever it has found. If, and only if, the DNS lookup attempt returns an unavailable status, the resolver attempts to use the local /etc/hosts. This means that we should use the hosts file only if our name server is unavailable for some reason.
Configuring Name Server Lookups Using resolv.conf
When configuring the resolver library to use the BIND name service for host lookups, you also have to tell it which name servers to use. There is a separate file for this called resolv.conf. If this file does not exist or is empty, the resolver assumes the name server is on your local host.
To run a name server on your local host, you have to set it up separately, as will be explained in the following section. If you are on a local network and have the opportunity to use an existing name server, this should always be preferred. If you use a dialup IP connection to the Internet, you would normally specify the name server of your service provider in the resolv.conf file.
The most important option in resolv.conf is name server, which gives the IP address of a name server to use. If you specify several name servers by giving the name server option several times, they are tried in the order given. You should therefore put the most reliable server first. The current implementation allows you to have up to three name server statements in resolv.conf. If no name server option is given, the resolver attempts to connect to the name server on the local host.
Two other options, domain and search, let you use shortcut names for hosts in your local domain. Usually, when just telnetting to another host in your local domain, you don't want to type in the fully qualified hostname, but use a name like gauss on the command line and have the resolver tack on the mathematics.groucho.edu part.
This is just the domain statement's purpose. It lets you specify a default domain name to be appended when DNS fails to look up a hostname. For instance, when given the name gauss, the resolver fails to find gauss. in DNS, because there is no such top-level domain. When given mathematics.groucho.edu as a default domain, the resolver repeats the query for gauss with the default domain appended, this time succeeding.
That's just fine, you may think, but as soon you get out of the Math department's domain, you're back to those fully qualified domain names. Of course, you would also want to have shorthands like quark.physics for hosts in the Physics department's domain.
This is when the search list comes in. A search list can be specified using the search option, which is a generalization of the domain statement. Where the latter gives a single default domain, the former specifies a whole list of them, each to be tried in turn until a lookup succeeds. This list must be separated by blanks or tabs.
The search and domain statements are mutually exclusive and may not appear more than once. If neither option is given, the resolver will try to guess the default domain from the local hostname using the getdomainname(2) system call. If the local hostname doesn't have a domain part, the default domain will be assumed to be the root domain.
If you decide to put a search statement into resolv.conf, you should be careful about what domains you add to this list. Resolver libraries prior to BIND 4.9 used to construct a default search list from the domain name when no search list was given. This default list was made up of the default domain itself, plus all of its parent domains up to the root. This caused some problems because DNS requests wound up at name servers that were never meant to see them.
Assume you're at the Virtual Brewery and want to log in to foot.groucho.edu. By a slip of your fingers, you mistype foot as foo, which doesn't exist. GMU's name server will therefore tell you that it knows no such host. With the old-style search list, the resolver would now go on trying the name with vbrew.com and com appended. The latter is problematic because groucho.edu.com might actually be a valid domain name. Their name server might then even find foo in their domain, pointing you to one of their hosts -- which clearly was not intended.
For some applications, these bogus host lookups can be a security problem. Therefore, you should usually limit the domains on your search list to your local organization, or something comparable. At the Mathematics department of Groucho Marx University, the search list would commonly be set to maths.groucho.edu and groucho.edu.
If default domains sound confusing to you, consider this sample resolv.conf file for the Virtual Brewery:
# /etc/resolv.conf # Our domain domain vbrew.com # # We use vlager as central name server: name server 172.16.1.1When resolving the name vale, the resolver looks up vale and, failing this, vale.vbrew.com.
Resolver Robustness
When running a LAN inside a larger network, you definitely should use central name servers if they are available. The name servers develop rich caches that speed up repeat queries, since all queries are forwarded to them. However, this scheme has a drawback: when a fire destroyed the backbone cable at Olaf's university, no more work was possible on his department's LAN because the resolver could no longer reach any of the name servers. This situation caused difficulties with most network services, such as X terminal logins and printing.
Although it is not very common for campus backbones to go down in flames, one might want to take precautions against cases like this.
One option is to set up a local name server that resolves hostnames from your local domain and forwards all queries for other hostnames to the main servers. Of course, this is applicable only if you are running your own domain.
Alternatively, you can maintain a backup host table for your domain or LAN in /etc/hosts. This is very simple to do. You simply ensure that the resolver library queries DNS first, and the hosts file next. In an /etc/host.conf file you'd use "order bind,hosts", and in an /etc/nsswitch.conf file you'd use "hosts: dns files", to make the resolver fall back to the hosts file if the central name server is unreachable.
How DNS Works
DNS organizes hostnames in a domain hierarchy. A domain is a collection of sites that are related in some sense -- because they form a proper network (e.g., all machines on a campus, or all hosts on BITNET), because they all belong to a certain organization (e.g., the U.S. government), or because they're simply geographically close. For instance, universities are commonly grouped in the edu domain, with each university or college using a separate subdomain, below which their hosts are subsumed. Groucho Marx University have the groucho.edu domain, while the LAN of the Mathematics department is assigned maths.groucho.edu. Hosts on the departmental network would have this domain name tacked onto their hostname, so erdos would be known as erdos.maths.groucho.edu. This is called the fully qualified domain name (FQDN), which uniquely identifies this host worldwide.
Figure 6.1 shows a section of the namespace. The entry at the root of this tree, which is denoted by a single dot, is quite appropriately called the root domain and encompasses all other domains. To indicate that a hostname is a fully qualified domain name, rather than a name relative to some (implicit) local domain, it is sometimes written with a trailing dot. This dot signifies that the name's last component is the root domain.
Figure 6.1: A part of the domain namespace
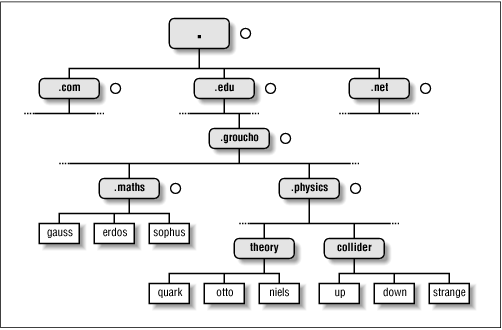
Depending on its location in the name hierarchy, a domain may be called top-level, second-level, or third-level. More levels of subdivision occur, but they are rare. This list details several top-level domains you may see frequently:
Domain Description edu (Mostly U.S.) educational institutions like universities.
com Commercial organizations and companies.
org Non-commercial organizations. Private UUCP networks are often in this domain.
net Gateways and other administrative hosts on a network.
mil U.S. military institutions.
gov U.S. government institutions.
uucp Officially, all site names formerly used as UUCP names without domains have been moved to this domain.
Historically, the first four of these were assigned to the U.S., but recent changes in policy have meant that these domains, named global Top Level Domains (gTLD), are now considered global in nature. Negotiations are currently underway to broaden the range of gTLDs, which may result in increased choice in the future.
Outside the U.S., each country generally uses a top-level domain of its own named after the two-letter country code defined in ISO-3166. Finland, for instance, uses the fi domain; fr is used by France, de by Germany, and au by Australia. Below this top-level domain, each country's NIC is free to organize hostnames in whatever way they want. Australia has second-level domains similar to the international top-level domains, named com.au and edu.au. Other countries, like Germany, don't use this extra level, but have slightly long names that refer directly to the organizations running a particular domain. It's not uncommon to see hostnames like ftp.informatik.uni-erlangen.de. Chalk that up to German efficiency.
Of course, these national domains do not imply that a host below that domain is actually located in that country; it means only that the host has been registered with that country's NIC. A Swedish manufacturer might have a branch in Australia and still have all its hosts registered with the se top-level domain.
Organizing the namespace in a hierarchy of domain names nicely solves the problem of name uniqueness; with DNS, a hostname has to be unique only within its domain to give it a name different from all other hosts worldwide. Furthermore, fully qualified names are easy to remember. Taken by themselves, these are already very good reasons to split up a large domain into several subdomains.
DNS does even more for you than this. It also allows you to delegate authority over a subdomain to its administrators. For example, the maintainers at the Groucho Computing Center might create a subdomain for each department; we already encountered the math and physics subdomains above. When they find the network at the Physics department too large and chaotic to manage from outside (after all, physicists are known to be an unruly bunch of people), they may simply pass control of the physics.groucho.edu domain to the administrators of this network. These administrators are free to use whatever hostnames they like and assign them IP addresses from their network in whatever fashion they desire, without outside interference.
To this end, the namespace is split up into zones, each rooted at a domain. Note the subtle difference between a zone and a domain: the domain groucho.edu encompasses all hosts at Groucho Marx University, while the zone groucho.edu includes only the hosts that are managed by the Computing Center directly; those at the Mathematics department, for example. The hosts at the Physics department belong to a different zone, namely physics.groucho.edu. In Figure 6.1, the start of a zone is marked by a small circle to the right of the domain name.
Name Lookups with DNS
At first glance, all this domain and zone fuss seems to make name resolution an awfully complicated business. After all, if no central authority controls what names are assigned to which hosts, how is a humble application supposed to know?
Now comes the really ingenious part about DNS. If you want to find the IP address of erdos, DNS says, "Go ask the people who manage it, and they will tell you."
In fact, DNS is a giant distributed database. It is implemented by so-called name servers that supply information on a given domain or set of domains. For each zone there are at least two, or at most a few, name servers that hold all authoritative information on hosts in that zone. To obtain the IP address of erdos, all you have to do is contact the name server for the groucho.edu zone, which will then return the desired data.
Easier said than done, you might think. So how do I know how to reach the name server at Groucho Marx University? In case your computer isn't equipped with an address-resolving oracle, DNS provides for this, too. When your application wants to look up information on erdos, it contacts a local name server, which conducts a so-called iterative query for it. It starts off by sending a query to a name server for the root domain, asking for the address of erdos.maths.groucho.edu. The root name server recognizes that this name does not belong to its zone of authority, but rather to one below the edu domain. Thus, it tells you to contact an edu zone name server for more information and encloses a list of all edu name servers along with their addresses. Your local name server will then go on and query one of those, for instance, a.isi.edu. In a manner similar to the root name server, a.isi.edu knows that the groucho.edu people run a zone of their own, and points you to their servers. The local name server will then present its query for erdos to one of these, which will finally recognize the name as belonging to its zone, and return the corresponding IP address.
This looks like a lot of traffic being generated for looking up a measly IP address, but it's really only miniscule compared to the amount of data that would have to be transferred if we were still stuck with HOSTS.TXT. There's still room for improvement with this scheme, however.
To improve response time during future queries, the name server stores the information obtained in its local cache. So the next time anyone on your local network wants to look up the address of a host in the groucho.edu domain, your name server will go directly to the groucho.edu name server.[1]
[1] If information weren't cached, then DNS would be as inefficient as any other method because each query would involve the root name servers.
Of course, the name server will not keep this information forever; it will discard it after some time. The expiration interval is called the time to live, or TTL. Each datum in the DNS database is assigned such a TTL by administrators of the responsible zone.
Types of Name Servers
Name servers that hold all information on hosts within a zone are called authoritative for this zone, and sometimes are referred to as master name servers. Any query for a host within this zone will end up at one of these master name servers.
Master servers must be fairly well synchronized. Thus, the zone's network administrator must make one the primary server, which loads its zone information from data files, and make the others secondary servers, which transfer the zone data from the primary server at regular intervals.
Having several name servers distributes workload; it also provides backup. When one name server machine fails in a benign way, like crashing or losing its network connection, all queries will fall back to the other servers. Of course, this scheme doesn't protect you from server malfunctions that produce wrong replies to all DNS requests, such as from software bugs in the server program itself.
You can also run a name server that is not authoritative for any domain.[2] This is useful, as the name server will still be able to conduct DNS queries for the applications running on the local network and cache the information. Hence it is called a caching-only server.
[2] Well, almost. A name server has to provide at least name service for localhost and reverse lookups of 127.0.0.1.
The DNS Database
We have seen that DNS not only deals with IP addresses of hosts, but also exchanges information on name servers. DNS databases may have, in fact, many different types of entries.
A single piece of information from the DNS database is called a resource record (RR). Each record has a type associated with it describing the sort of data it represents, and a class specifying the type of network it applies to. The latter accommodates the needs of different addressing schemes, like IP addresses (the IN class), Hesiod addresses (used by MIT's Kerberos system), and a few more. The prototypical resource record type is the A record, which associates a fully qualified domain name with an IP address.
A host may be known by more than one name. For example you might have a server that provides both FTP and World Wide Web servers, which you give two names: ftp.machine.org and www.machine.org. However, one of these names must be identified as the official or canonical hostname, while the others are simply aliases referring to the official hostname. The difference is that the canonical hostname is the one with an associated A record, while the others only have a record of type CNAME that points to the canonical hostname.
We will not go through all record types here, but we will give you a brief example. Example 6.4 shows a part of the domain database that is loaded into the name servers for the physics.groucho.edu zone.
Example 6.4: An Excerpt from the named.hosts File for the Physics Department
; Authoritative Information on physics.groucho.edu. @ IN SOA niels.physics.groucho.edu. janet.niels.physics.groucho.edu. { 1999090200 ; serial no 360000 ; refresh 3600 ; retry 3600000 ; expire 3600 ; default ttl } ; ; Name servers IN NS niels IN NS gauss.maths.groucho.edu. gauss.maths.groucho.edu. IN A 149.76.4.23 ; ; Theoretical Physics (subnet 12) niels IN A 149.76.12.1 IN A 149.76.1.12 name server IN CNAME niels otto IN A 149.76.12.2 quark IN A 149.76.12.4 down IN A 149.76.12.5 strange IN A 149.76.12.6 ... ; Collider Lab. (subnet 14) boson IN A 149.76.14.1 muon IN A 149.76.14.7 bogon IN A 149.76.14.12 ...Apart from the A and CNAME records, you can see a special record at the top of the file, stretching several lines. This is the SOA resource record signaling the Start of Authority, which holds general information on the zone the server is authoritative for. The SOA record comprises, for instance, the default time to live for all records.
Note that all names in the sample file that do not end with a dot should be interpreted relative to the physics.groucho.edu domain. The special name (@) used in the
SOArecord refers to the domain name by itself.We have seen earlier that the name servers for the groucho.edu domain somehow have to know about the physics zone so that they can point queries to their name servers. This is usually achieved by a pair of records: the NS record that gives the server's FQDN, and an A record that associates an address with that name. Since these records are what holds the namespace together, they are frequently called glue records. They are the only instances of records in which a parent zone actually holds information on hosts in the subordinate zone. The glue records pointing to the name servers for physics.groucho.edu are shown in Example 6.5.
Example 6.5: An Excerpt from the named.hosts File for GMU
; Zone data for the groucho.edu zone. @ IN SOA vax12.gcc.groucho.edu. joe.vax12.gcc.groucho.edu. { 1999070100 ; serial no 360000 ; refresh 3600 ; retry 3600000 ; expire 3600 ; default ttl } .... ; ; Glue records for the physics.groucho.edu zone physics IN NS niels.physics.groucho.edu. IN NS gauss.maths.groucho.edu. niels.physics IN A 149.76.12.1 gauss.maths IN A 149.76.4.23 ...Reverse Lookups
Finding the IP address belonging to a host is certainly the most common use for the Domain Name System, but sometimes you'll want to find the canonical hostname corresponding to an address. Finding this hostname is called reverse mapping, and is used by several network services to verify a client's identity. When using a single hosts file, reverse lookups simply involve searching the file for a host that owns the IP address in question. With DNS, an exhaustive search of the namespace is out of the question. Instead, a special domain, in-addr.arpa, has been created that contains the IP addresses of all hosts in a reversed dotted quad notation. For instance, an IP address of 149.76.12.4 corresponds to the name 4.12.76.149.in-addr.arpa. The resource-record type linking these names to their canonical hostnames is PTR.
Creating a zone of authority usually means that its administrators have full control over how they assign addresses to names. Since they usually have one or more IP networks or subnets at their hands, there's a one-to-many mapping between DNS zones and IP networks. The Physics department, for instance, comprises the subnets 149.76.8.0, 149.76.12.0, and 149.76.14.0.
Consequently, new zones in the in-addr.arpa domain have to be created along with the physics zone, and delegated to the network administrators at the department: 8.76.149.in-addr.arpa, 12.76.149.in-addr.arpa, and 14.76.149.in-addr.arpa. Otherwise, installing a new host at the Collider Lab would require them to contact their parent domain to have the new address entered into their in-addr.arpa zone file.
The zone database for subnet 12 is shown in Example 6.6. The corresponding glue records in the database of their parent zone are shown in Example 6.7.
Example 6.6: An Excerpt from the named.rev File for Subnet 12
; the 12.76.149.in-addr.arpa domain. @ IN SOA niels.physics.groucho.edu. janet.niels.physics.groucho.edu. { 1999090200 360000 3600 3600000 3600 } 2 IN PTR otto.physics.groucho.edu. 4 IN PTR quark.physics.groucho.edu. 5 IN PTR down.physics.groucho.edu. 6 IN PTR strange.physics.groucho.edu.Example 6.7: An Excerpt from the named.rev File for Network 149.76
; the 76.149.in-addr.arpa domain. @ IN SOA vax12.gcc.groucho.edu. joe.vax12.gcc.groucho.edu. { 1999070100 360000 3600 3600000 3600 } ... ; subnet 4: Mathematics Dept. 1.4 IN PTR sophus.maths.groucho.edu. 17.4 IN PTR erdos.maths.groucho.edu. 23.4 IN PTR gauss.maths.groucho.edu. ... ; subnet 12: Physics Dept, separate zone 12 IN NS niels.physics.groucho.edu. IN NS gauss.maths.groucho.edu. niels.physics.groucho.edu. IN A 149.76.12.1 gauss.maths.groucho.edu. IN A 149.76.4.23 ...in-addr.arpa system zones can only be created as supersets of IP networks. An even more severe restriction is that these networks' netmasks have to be on byte boundaries. All subnets at Groucho Marx University have a netmask of 255.255.255.0, hence an in-addr.arpa zone could be created for each subnet. However, if the netmask were 255.255.255.128 instead, creating zones for the subnet 149.76.12.128 would be impossible, because there's no way to tell DNS that the 12.76.149.in-addr.arpa domain has been split into two zones of authority, with hostnames ranging from 1 through 127, and 128 through 255, respectively.
Running named
named (pronounced name-dee) provides DNS on most Unix machines. It is a server program originally developed for BSD to provide name service to clients, and possibly to other name servers. BIND Version 4 was around for some time and appeared in most Linux distributions. The new release, Version 8, has been introduced in most Linux distributions, and is a big change from previous versions.[3] It has many new features, such as support for DNS dynamic updates, DNS change notifications, much improved performance, and a new configuration file syntax. Please check the documentation contained in the source distribution for details.
[3] BIND 4.9 was developed by Paul Vixie, paul@vix.com, but BIND is now maintained by the Internet Software Consortium, bind-bugs@isc.org.
This section requires some understanding of the way DNS works. If the following discussion is all Greek to you, you may want to reread the section "How DNS Works".
named is usually started at system boot time and runs until the machine goes down again. Implementations of BIND prior to Version 8 take their information from a configuration file called /etc/named.boot and various files that map domain names to addresses. The latter are called zone files. Versions of BIND from Version 8 onwards use /etc/named.conf in place of /etc/named.boot.
To run named at the prompt, enter:
#/usr/sbin/namednamed will come up and read the named.boot file and any zone files specified therein. It writes its process ID to /var/run/named.pid in ASCII, downloads any zone files from primary servers, if necessary, and starts listening on port 53 for DNS queries.
The named.boot File
The BIND configuration file prior to Version 8 was very simple in structure. BIND Version 8 has a very different configuration file syntax to deal with many of the new features introduced. The name of the configuration file changed from /etc/named.boot, in older versions of BIND, to /etc/named.conf in BIND Version 8. We'll focus on configuring the older version because it is probably what most distributions are still using, but we'll present an equivalent named.conf to illustrate the differences, and we'll talk about how to convert the old format into the new one.
The named.boot file is generally small and contains little but pointers to master files containing zone information and pointers to other name servers. Comments in the boot file start with the (#) or (;) characters and extend to the next newline. Before we discuss the format of named.boot in more detail, we will take a look at the sample file for vlager given in Example 6.8.
Example 6.8: The named.boot File for vlager
; ; /etc/named.boot file for vlager.vbrew.com ; directory /var/named ; ; domain file ;----------------- cache . named.ca primary vbrew.com named.hosts primary 0.0.127.in-addr.arpa named.local primary 16.172.in-addr.arpa named.revLet's look at each statement individually. The directory keyword tells named that all filenames referred to later in this file, zone files for example, are located in the /var/named directory. This saves a little typing.
The primary keyword shown in this example loads information into named. This information is taken from the master files specified as the last of the parameters. These files represent DNS resource records, which we will look at next.
In this example, we configured named as the primary name server for three domains, as indicated by the three primary statements. The first of these statements instructs named to act as a primary server for vbrew.com, taking the zone data from the file named.hosts.
The cache keyword is very special and should be present on virtually all machines running a name server. It instructs named to enable its cache and to load the root name server hints from the cache file specified (named.ca in our example). We will come back to the name server hints in the following list.
Here's a list of the most important options you can use in named.boot:
There are two options that we will not describe here: sortlist and domain. Two other directives may also be used inside these database files: $INCLUDE and $ORIGIN. Since they are rarely needed, we will not describe them here, either.
- directory
This option specifies a directory in which zone files reside. Names of files in other options may be given relative to this directory. Several directories may be specified by repeatedly using directory. The Linux file system standard suggests this should be /var/named.
- primary
This option takes a domain name and filename as an argument, declaring the local server authoritative for the named domain. As a primary server, named loads the zone information from the given master file.
There will always be at least one primary entry in every boot file used for reverse mapping of network 127.0.0.0, which is the local loopback network.
- secondary
This statement takes a domain name, an address list, and a filename as an argument. It declares the local server a secondary master server for the specified domain.
A secondary server holds authoritative data on the domain, too, but it doesn't gather it from files; instead, it tries to download it from the primary server. The IP address of at least one primary server thus must be given to named in the address list. The local server contacts each of them in turn until it successfully transfers the zone database, which is then stored in the backup file given as the third argument. If none of the primary servers responds, the zone data is retrieved from the backup file instead.
named then attempts to refresh the zone data at regular intervals. This process is explained later in connection with the SOA resource record type.
- cache
This option takes a domain name and filename as arguments. This file contains the root server hints, which is a list of records pointing to the root name servers. Only NS and A records will be recognized. The domain should be the root domain name, a simple period (.).
This information is absolutely crucial to named; if the cache statement does not occur in the boot file, named will not develop a local cache at all. This situation/lack of development will severely degrade performance and increase network load if the next server queried is not on the local net. Moreover, named will not be able to reach any root name servers, and thus won't resolve any addresses except those it is authoritative for. An exception from this rule involves forwarding servers (see the forwarders option that follows).
- forwarders
This statement takes a whitespace-separated list of addresses as an argument. The IP addresses in this list specify a list of name servers that named may query if it fails to resolve a query from its local cache. They are tried in order until one of them responds to the query. Typically, you would use the name server of your network provider or another well-known server as a forwarder.
- slave
This statement makes the name server a slave server. It never performs recursive queries itself, but only forwards them to servers specified in the forwarders statement.
The BIND 8 host.conf File
BIND Version 8 introduced a range of new features, and with these came a new configuration file syntax. The named.boot, with its simple single line statements, was replaced by the named.conf file, with a syntax like that of gated and resembling C source syntax.
The new syntax is more complex, but fortunately a tool has been provided that automates conversion from the old syntax to the new syntax. In the BIND 8 source package, a perl program called named-bootconf.pl is provided that will read your existing named.boot file from
stdinand convert it into the equivalent named.conf format onstdout. To use it, you must have the perl interpreter installed.You should use the script somewhat like this:
The script then produces a named.conf that looks like that shown in Example 6.9. We've cleaned out a few of the helpful comments the script includes to help show the almost direct relationship between the old and the new syntax.#cd /etc
#named-bootconf.pl <named.boot >named.confExample 6.9: The BIND 8 equivalent named.conf File for vlager
// // /etc/named.boot file for vlager.vbrew.com options { directory "/var/named"; }; zone "." { type hint; file "named.ca"; }; zone "vbrew.com" { type master; file "named.hosts"; }; zone "0.0.127.in-addr.arpa" { type master; file "named.local"; }; zone "16.172.in-addr.arpa" { type master; file "named.rev"; };If you take a close look, you will see that each of the one-line statements in named.boot has been converted into a C-like statement enclosed within {} characters in the named.conf file.
The comments, which in the named.boot file were indicated by a semicolon (;), are now indicated by two forward slashes (//).
The directory statement has been translated into an options paragraph with a directory clause.
The cache and primary statements have been converted into zone paragraphs with type clauses of hint and master, respectively.
The zone files do not need to be modified in any way; their syntax remains unchanged.
The new configuration syntax allows for many new options that we haven't covered here. If you'd like information on the new options, the best source of information is the documentation supplied with the BIND Version 8 source package.
The DNS Database Files
Master files included with named, like named.hosts, always have a domain associated with them, which is called the origin. This is the domain name specified with the cache and primary options. Within a master file, you are allowed to specify domain and host names relative to this domain. A name given in a configuration file is considered absolute if it ends in a single dot, otherwise it is considered relative to the origin. The origin by itself may be referred to using (@).
The data contained in a master file is split up in resource records(RRs). RRs are the smallest units of information available through DNS. Each resource record has a type. A records, for instance, map a hostname to an IP address, and a CNAME record associates an alias for a host with its official hostname. To see an example, look at Example 6.11, which shows the named.hosts master file for the Virtual Brewery.
Resource record representations in master files share a common format:
[domain] [ttl] [class] type rdataFields are separated by spaces or tabs. An entry may be continued across several lines if an opening brace occurs before the first newline and the last field is followed by a closing brace. Anything between a semicolon and a newline is ignored. A description of the format terms follows:
- domain
This term is the domain name to which the entry applies. If no domain name is given, the RR is assumed to apply to the domain of the previous RR.
- ttl
In order to force resolvers to discard information after a certain time, each RR is associated a time to live (ttl). The ttl field specifies the time in seconds that the information is valid after it has been retrieved from the server. It is a decimal number with at most eight digits.
If no ttl value is given, the field value defaults to that of the minimum field of the preceding SOA record.
- class
This is an address class, like IN for IP addresses or HS for objects in the Hesiod class. For TCP/IP networking, you have to specify IN.
If no class field is given, the class of the preceding RR is assumed.
- type
This describes the type of the RR. The most common types are A, SOA, PTR, and NS. The following sections describe the various types of RRs.
- rdata
This holds the data associated with the RR. The format of this field depends on the type of RR. In the following discussion, it will be described for each RR separately.
The following is partial list of RRs to be used in DNS master files. There are a couple more of them that we will not explain; they are experimental and of little use, generally.
- SOA
This RR describes a zone of authority (SOA means "Start of Authority"). It signals that the records following the SOA RR contain authoritative information for the domain. Every master file included by a primary statement must contain an SOA record for this zone. The resource data contains the following fields:
- origin
This field is the canonical hostname of the primary name server for this domain. It is usually given as an absolute name.
- contact
This field is the email address of the person responsible for maintaining the domain, with the "@" sign replaced by a dot. For instance, if the responsible person at the Virtual Brewery were janet, this field would contain janet.vbrew.com.
- serial
This field is the version number of the zone file, expressed as a single decimal number. Whenever data is changed in the zone file, this number should be incremented. A common convention is to use a number that reflects the date of the last update, with a version number appended to it to cover the case of multiple updates occurring on a single day, e.g., 2000012600 being update 00 that occurred on January 26, 2000.
The serial number is used by secondary name servers to recognize zone information changes. To stay up to date, secondary servers request the primary server's SOA record at certain intervals and compare the serial number to that of the cached SOA record. If the number has changed, the secondary servers transfer the whole zone database from the primary server.
- refresh
This field specifies the interval in seconds that the secondary servers should wait between checking the SOA record of the primary server. Again, this is a decimal number with at most eight digits.
Generally, the network topology doesn't change too often, so this number should specify an interval of roughly a day for larger networks, and even more for smaller ones.
- retry
This number determines the intervals at which a secondary server should retry contacting the primary server if a request or a zone refresh fails. It must not be too low, or a temporary failure of the server or a network problem could cause the secondary server to waste network resources. One hour, or perhaps one-half hour, might be a good choice.
- expire
This field specifies the time in seconds after which a secondary server should finally discard all zone data if it hasn't been able to contact the primary server. You should normally set this field to at least a week (604,800 seconds), but increasing it to a month or more is also reasonable.
- minimum
This field is the default ttl value for resource records that do not explicitly contain one. The ttl value specifies the maximum amount of time other name servers may keep the RR in their cache. This time applies only to normal lookups, and has nothing to do with the time after which a secondary server should try to update the zone information.
If the topology of your network does not change frequently, a week or even more is probably a good choice. If single RRs change more frequently, you could still assign them smaller ttls individually. If your network changes frequently, you may want to set minimum to one day (86,400 seconds).
- A
This record associates an IP address with a hostname. The resource data field contains the address in dotted quad notation.
For each hostname, there must be only one A record. The hostname used in this A record is considered the official or canonical hostname. All other hostnames are aliases and must be mapped onto the canonical hostname using a CNAME record. If the canonical name of our host were vlager, we'd have an A record that associated that hostname with its IP address. Since we may also want another name associated with that address, say news, we'd create a CNAME record that associates this alternate name with the canonical name. We'll talk more about CNAME records shortly.
- NS
NS records are used to specify a zone's primary server and all its secondary servers. An NS record points to a master name server of the given zone, with the resource data field containing the hostname of the name server.
You will meet NS records in two situations: The first situation is when you delegate authority to a subordinate zone; the second is within the master zone database of the subordinate zone itself. The sets of servers specified in both the parent and delegated zones should match.
The NS record specifies the name of the primary and secondary name servers for a zone. These names must be resolved to an address so they can be used. Sometimes the servers belong to the domain they are serving, which causes a "chicken and egg" problem; we can't resolve the address until the name server is reachable, but we can't reach the name server until we resolve its address. To solve this dilemma, we can configure special A records directly into the name server of the parent zone. The A records allow the name servers of the parent domain to resolve the IP address of the delegated zone name servers. These records are commonly called glue records because they provide the "glue" that binds a delegated zone to its parent.
- CNAME
This record associates an alias with a host's canonical hostname. It provides an alternate name by which users can refer to the host whose canonical name is supplied as a parameter. The canonical hostname is the one the master file provides an A record for; aliases are simply linked to that name by a CNAME record, but don't have any other records of their own.
- PTR
This type of record is used to associate names in the in-addr.arpa domain with hostnames. It is used for reverse mapping of IP addresses to hostnames. The hostname given must be the canonical hostname.
- MX
This RR announces a mail exchanger for a domain. Mail exchangers are discussed in "Mail Routing on the Internet". The syntax of an MX record is:
[domain] [ttl] [class] MX preference hosthost names the mail exchanger for domain. Every mail exchanger has an integer preference associated with it. A mail transport agent that wants to deliver mail to domain tries all hosts who have an MX record for this domain until it succeeds. The one with the lowest preference value is tried first, then the others, in order of increasing preference value.
- HINFO
This record provides information on the system's hardware and software. Its syntax is:
[domain] [ttl] [class] HINFO hardware softwareThe hardware field identifies the hardware used by this host. Special conventions are used to specify this. A list of valid "machine names" is given in the Assigned Numbers RFC (RFC-1700). If the field contains any blanks, it must be enclosed in double quotes. The software field names the operating system software used by the system. Again, a valid name from the Assigned Numbers RFC should be chosen.
An
HINFOrecord to describe an Intel-based Linux machine should look something like:andtao 36500 IN HINFO IBM-PC LINUX2.2HINFOrecords for Linux running on Motorola 68000-based machines might look like:cevad 36500 IN HINFO ATARI-104ST LINUX2.0 jedd 36500 IN HINFO AMIGA-3000 LINUX2.0
Caching-only named Configuration
There is a special type of named configuration that we'll talk about before we explain how to build a full name server configuration. It is called a caching-only configuration. It doesn't really serve a domain, but acts as a relay for all DNS queries produced on your host. The advantage of this scheme is that it builds up a cache so only the first query for a particular host is actually sent to the name servers on the Internet. Any repeated request will be answered directly from the cache in your local name server. This may not seem useful yet, but it will when you are dialing in to the Internet, as described in Chapter 7, Serial Line IP and Chapter 8, The Point-to-Point Protocol.
A named.boot file for a caching-only server looks like this:
; named.boot file for caching-only server directory /var/named primary 0.0.127.in-addr.arpa named.local ; localhost network cache . named.ca ; root serversIn addition to this named.boot file, you must set up the named.ca file with a valid list of root name servers. You could copy and use Example 6.10 for this purpose. No other files are needed for a caching-only server configuration.
Writing the Master Files
Example 6.10, Example 6.11, Example 6.12, and Example 6.13 give sample files for a name server at the brewery, located on vlager. Due to the nature of the network discussed (a single LAN), the example is pretty straightforward.
The named.ca cache file shown in Example 6.10 shows sample hint records for a root name server. A typical cache file usually describes about a dozen name servers. You can obtain the current list of name servers for the root domain using the nslookup tool described in the next section.[4]
[4] Note that you can't query your name server for the root servers if you don't have any root server hints installed. To escape this dilemma, you can either make nslookup use a different name server, or use the sample file in Example 6.10 as a starting point, and then obtain the full list of valid servers.
Example 6.10: The named.ca File
; ; /var/named/named.ca Cache file for the brewery. ; We're not on the Internet, so we don't need ; any root servers. To activate these ; records, remove the semicolons. ; ;. 3600000 IN NS A.ROOT-SERVERS.NET. ;A.ROOT-SERVERS.NET. 3600000 A 198.41.0.4 ;. 3600000 NS B.ROOT-SERVERS.NET. ;B.ROOT-SERVERS.NET. 3600000 A 128.9.0.107 ;. 3600000 NS C.ROOT-SERVERS.NET. ;C.ROOT-SERVERS.NET. 3600000 A 192.33.4.12 ;. 3600000 NS D.ROOT-SERVERS.NET. ;D.ROOT-SERVERS.NET. 3600000 A 128.8.10.90 ;. 3600000 NS E.ROOT-SERVERS.NET. ;E.ROOT-SERVERS.NET. 3600000 A 192.203.230.10 ;. 3600000 NS F.ROOT-SERVERS.NET. ;F.ROOT-SERVERS.NET. 3600000 A 192.5.5.241 ;. 3600000 NS G.ROOT-SERVERS.NET. ;G.ROOT-SERVERS.NET. 3600000 A 192.112.36.4 ;. 3600000 NS H.ROOT-SERVERS.NET. ;H.ROOT-SERVERS.NET. 3600000 A 128.63.2.53 ;. 3600000 NS I.ROOT-SERVERS.NET. ;I.ROOT-SERVERS.NET. 3600000 A 192.36.148.17 ;. 3600000 NS J.ROOT-SERVERS.NET. ;J.ROOT-SERVERS.NET. 3600000 A 198.41.0.10 ;. 3600000 NS K.ROOT-SERVERS.NET. ;K.ROOT-SERVERS.NET. 3600000 A 193.0.14.129 ;. 3600000 NS L.ROOT-SERVERS.NET. ;L.ROOT-SERVERS.NET. 3600000 A 198.32.64.12 ;. 3600000 NS M.ROOT-SERVERS.NET. ;M.ROOT-SERVERS.NET. 3600000 A 202.12.27.33 ;Example 6.11: The named.hosts File
; ; /var/named/named.hosts Local hosts at the brewery ; Origin is vbrew.com ; @ IN SOA vlager.vbrew.com. janet.vbrew.com. ( 2000012601 ; serial 86400 ; refresh: once per day 3600 ; retry: one hour 3600000 ; expire: 42 days 604800 ; minimum: 1 week ) IN NS vlager.vbrew.com. ; ; local mail is distributed on vlager IN MX 10 vlager ; ; loopback address localhost. IN A 127.0.0.1 ; ; Virtual Brewery Ethernet vlager IN A 172.16.1.1 vlager-if1 IN CNAME vlager ; vlager is also news server news IN CNAME vlager vstout IN A 172.16.1.2 vale IN A 172.16.1.3 ; ; Virtual Winery Ethernet vlager-if2 IN A 172.16.2.1 vbardolino IN A 172.16.2.2 vchianti IN A 172.16.2.3 vbeaujolais IN A 172.16.2.4 ; ; Virtual Spirits (subsidiary) Ethernet vbourbon IN A 172.16.3.1 vbourbon-if1 IN CNAME vbourbonExample 6.12: The named.local File
; ; /var/named/named.local Reverse mapping of 127.0.0 ; Origin is 0.0.127.in-addr.arpa. ; @ IN SOA vlager.vbrew.com. joe.vbrew.com. ( 1 ; serial 360000 ; refresh: 100 hrs 3600 ; retry: one hour 3600000 ; expire: 42 days 360000 ; minimum: 100 hrs ) IN NS vlager.vbrew.com. 1 IN PTR localhost.Example 6.13: The named.rev File
; ; /var/named/named.rev Reverse mapping of our IP addresses ; Origin is 16.172.in-addr.arpa. ; @ IN SOA vlager.vbrew.com. joe.vbrew.com. ( 16 ; serial 86400 ; refresh: once per day 3600 ; retry: one hour 3600000 ; expire: 42 days 604800 ; minimum: 1 week ) IN NS vlager.vbrew.com. ; brewery 1.1 IN PTR vlager.vbrew.com. 2.1 IN PTR vstout.vbrew.com. 3.1 IN PTR vale.vbrew.com. ; winery 1.2 IN PTR vlager-if2.vbrew.com. 2.2 IN PTR vbardolino.vbrew.com. 3.2 IN PTR vchianti.vbrew.com. 4.2 IN PTR vbeaujolais.vbrew.com.Verifying the Name Server Setup
nslookup is a great tool for checking the operation of your name server setup. It can be used both interactively with prompts and as a single command with immediate output. In the latter case, you simply invoke it as:
$nslookup
hostnamenslookup queries the name server specified in resolv.conf for hostname. (If this file names more than one server, nslookup chooses one at random.)
The interactive mode, however, is much more exciting. Besides looking up individual hosts, you may query for any type of DNS record and transfer the entire zone information for a domain.
When invoked without an argument, nslookup displays the name server it uses and enters interactive mode. At the > prompt, you may type any domain name you want to query. By default, it asks for class A records, those containing the IP address relating to the domain name.
You can look for record types by issuing:
>set type=typein which type is one of the resource record names described earlier, or ANY.
You might have the following nslookup session:
$nslookup
Default Server: tao.linux.org.au Address: 203.41.101.121 >metalab.unc.edu
Server: tao.linux.org.au Address: 203.41.101.121 Name: metalab.unc.edu Address: 152.2.254.81 >The output first displays the DNS server being queried, and then the result of the query.
If you try to query for a name that has no IP address associated with it, but other records were found in the DNS database, nslookup returns with an error message saying "
No type A records found." However, you can make it query for records other than type A by issuing the set type command. To get the SOA record of unc.edu, you would issue:>unc.edu
Server: tao.linux.org.au Address: 203.41.101.121 *** No address (A) records available for unc.edu >set type=SOA
>unc.edu
Server: tao.linux.org.au Address: 203.41.101.121 unc.edu origin = ns.unc.edu mail addr = host-reg.ns.unc.edu serial = 1998111011 refresh = 14400 (4H) retry = 3600 (1H) expire = 1209600 (2W) minimum ttl = 86400 (1D) unc.edu name server = ns2.unc.edu unc.edu name server = ncnoc.ncren.net unc.edu name server = ns.unc.edu ns2.unc.edu internet address = 152.2.253.100 ncnoc.ncren.net internet address = 192.101.21.1 ncnoc.ncren.net internet address = 128.109.193.1 ns.unc.edu internet address = 152.2.21.1In a similar fashion, you can query for MX records:
>set type=MX
>unc.edu
Server: tao.linux.org.au Address: 203.41.101.121 unc.edu preference = 0, mail exchanger = conga.oit.unc.edu unc.edu preference = 10, mail exchanger = imsety.oit.unc.edu unc.edu name server = ns.unc.edu unc.edu name server = ns2.unc.edu unc.edu name server = ncnoc.ncren.net conga.oit.unc.edu internet address = 152.2.22.21 imsety.oit.unc.edu internet address = 152.2.21.99 ns.unc.edu internet address = 152.2.21.1 ns2.unc.edu internet address = 152.2.253.100 ncnoc.ncren.net internet address = 192.101.21.1 ncnoc.ncren.net internet address = 128.109.193.1Using a type of ANY returns all resource records associated with a given name.
A practical application of nslookup, besides debugging, is to obtain the current list of root name servers. You can obtain this list by querying for all NS records associated with the root domain:
>set type=NS
>.
Server: tao.linux.org.au Address: 203.41.101.121 Non-authoritative answer: (root) name server = A.ROOT-SERVERS.NET (root) name server = H.ROOT-SERVERS.NET (root) name server = B.ROOT-SERVERS.NET (root) name server = C.ROOT-SERVERS.NET (root) name server = D.ROOT-SERVERS.NET (root) name server = E.ROOT-SERVERS.NET (root) name server = I.ROOT-SERVERS.NET (root) name server = F.ROOT-SERVERS.NET (root) name server = G.ROOT-SERVERS.NET (root) name server = J.ROOT-SERVERS.NET (root) name server = K.ROOT-SERVERS.NET (root) name server = L.ROOT-SERVERS.NET (root) name server = M.ROOT-SERVERS.NET Authoritative answers can be found from: A.ROOT-SERVERS.NET internet address = 198.41.0.4 H.ROOT-SERVERS.NET internet address = 128.63.2.53 B.ROOT-SERVERS.NET internet address = 128.9.0.107 C.ROOT-SERVERS.NET internet address = 192.33.4.12 D.ROOT-SERVERS.NET internet address = 128.8.10.90 E.ROOT-SERVERS.NET internet address = 192.203.230.10 I.ROOT-SERVERS.NET internet address = 192.36.148.17 F.ROOT-SERVERS.NET internet address = 192.5.5.241 G.ROOT-SERVERS.NET internet address = 192.112.36.4 J.ROOT-SERVERS.NET internet address = 198.41.0.10 K.ROOT-SERVERS.NET internet address = 193.0.14.129 L.ROOT-SERVERS.NET internet address = 198.32.64.12 M.ROOT-SERVERS.NET internet address = 202.12.27.33To see the complete set of available commands, use the help command in nslookup.
Other Useful Tools
There are a few tools that can help you with your tasks as a BIND administrator. We will briefly describe two of them here. Please refer to the documentation that comes with these tools for more information on how to use them.
hostcvt helps you with your initial BIND configuration by converting your /etc/hosts file into master files for named. It generates both the forward (A) and reverse mapping (PTR) entries, and takes care of aliases. Of course, it won't do the whole job for you, as you may still want to tune the timeout values in the SOA record, for example, or add MX records. Still, it may help you save a few aspirins. hostcvt is part of the BIND source, but can also be found as a standalone package on a few Linux FTP servers.
After setting up your name server, you may want to test your configuration. Some good tools that make this job much simpler: the first is called dnswalk, which is a Perl-based package. The second is called nslint. They both walk your DNS database looking for common mistakes and verify that the information they find is consistent. Two other useful tools are host and dig, which are general purpose DNS database query tools. You can use these tools to manually inspect and diagnose DNS database entries.
These tools are likely to be available in prepackaged form. dnswalk and nslint are available in source from http://www.visi.com/~barr/dnswalk/ and ftp://ftp.ee.lbl.gov/nslint.tar.Z. The host and dig source codes can be found at ftp://ftp.nikhef.nl/pub/network/ and ftp://ftp.is.co.za/networking/ip/dns/dig/.