Show Contents Previous Page Next Page Chapter 4 - Content Handlers / Chaining Content Handlers The stacked handlers we looked at in the previous example didn't interact. When one was finished processing, the next took over. A more sophisticated set of handlers might want to pipeline their results in such a way that the output of one handler becomes the input to the next. This would allow the handlers to modify each other's output in classic Unix filter fashion. This sounds difficult, but in fact it's pretty simple. This section will show you how to set up a filter pipeline. As an aside, it will also introduce you to the concept of Apache Perl API method handlers. The trick to achieving a handler pipeline is to use "tied" filehandles to connect the neighbors together. In the event that you've never worked with a tied filehandle before, it's a way of giving a filehandle seemingly magic behavior. When you print() to a tied filehandle, the data is redirected to a method in a user-defined class rather than going through the usual filesystem routines. To create a tied filehandle, you simply declare a class that defines a method named TIEHANDLE() and various methods to handle the sorts of things one does with a filehandle, such as PRINT() and READ(). Here's a concrete example of a tied filehandle class that interfaces to an antique daisywheel printer of some sort: package DaisyWheel;
sub TIEHANDLE {
my($class, $printer_name) = @_;
open_daisywheel($printer_name);
bless { 'printer' => $printer_name }, $class;
}
sub PRINT {
my $self = shift;
send_to_daisywheel($self->{'printer'}, @_);
}
sub DESTROY {
my $self = shift;
close_daisywheel($self->{'printer'});
}
1; __END__ The TIEHANDLE() method gets called first. It is responsible for opening the daisywheel printer driver (routine not shown here!) and returning a blessed object containing its instance variables. The PRINT() method is called whenever the main program prints to the tied filehandle. Its arguments are the blessed object and a list containing the arguments to print(). It recovers the printer name from its instance variables and then passes it, and the items to print, to an internal routine that does the actual work. DESTROY() is called when the filehandle is untie()d or closed. It calls an internal routine that closes the printer driver. To use this class, a program just has to call tie() with the name of an appropriate printer: use DaisyWheel (); tie *DAISY, 'DaisyWheel', 'dwj002'; print DAISY "Daisy... Daisy... Daisy the Kangaroo.\n"; print DAISY "She wanted to live in a private home,\n"; print DAISY "So she ran away from the zoo!\n"; close DAISY; A more complete tied filehandle class might include a PRINTF() method, a READ() method, a READLINE() method, and a GETC() method, but for output-only filehandles PRINT() is usually enough. Now back to Apache. The strategy will be for each filter in the pipeline, including the very first and last ones, to print to STDOUT, rather than directly invoking the Apache::print() method via the request object. We will arrange for STDOUT to be tied() in each case to a PRINT() method defined in the next filter down the chain. The whole scheme looks something like this: -> ::PRINT() [STDOUT tied to ]
-> ::PRINT() [STDOUT tied to ]
-> ::PRINT() [STDOUT tied to ]
.
.
.
-> Apache::PRINT() [STDOUT tied to Apache]
Interestingly enough, the last filter in the chain doesn't have to get special treatment. Internally, the Apache request ties STDOUT to Apache::PRINT(), which in turn calls Apache::print(). This is why handlers can use To simplify setting up these pipelines, we'll define a utility class called Apache::Forward.4 Apache::Forward is a null filter that passes its input through to the next filter in the chain unmodified. Modules that inherit from this class override its PRINT() method to do something interesting with the data. Example 4-22 gives the source code for Apache::Forward. We'll discuss the code one section at a time. package Apache::Forward; use strict; use Apache::Constants qw(OK SERVER_ERROR); use vars qw($VERSION); $VERSION = '1.00'; sub handler ($$) {
my($class, $r) = @_;
my $next = tied *STDOUT || return SERVER_ERROR;
tie *STDOUT, $class, $r, $next or return SERVER_ERROR;
$r->register_cleanup(sub { untie *STDOUT });
OK;
}
Most of the work is done in the handler() subroutine, which is responsible for correctly tying the STDOUT filehandle. Notice that the function prototype for handler() is Apache::Forward->handler($r); The result is that the handler() receives the class name as its first argument, and the request object as the second argument. This object-oriented calling style allows Apache::Forward to be subclassed. The handler() subroutine begins by recovering the identity of the next handler in the pipeline. It does this by calling tied() on the STDOUT filehandle. tied() returns a reference to whatever object a filehandle is tied to. It will always return a valid object, even when the current package is the last filter in the pipeline. This is because Apache ties STDOUT to itself, so the last filter will get a reference to the Apache object. Nevertheless, we do check that tied() returns an object and error out if not--just in case. Next the subroutine reties STDOUT to itself, passing tie() the request object and the reference to the next filter in the pipeline. This call shouldn't fail, but if it does, we return a server error at this point. Before finishing up, the handler() method needs to ensure that the filehandle will be untied before the transaction terminates. We do this by registering a handler for the cleanup phase. This is the last handler to be called before a transaction terminates and is traditionally reserved for this kind of garbage collection. We use register_cleanup() to push an anonymous subroutine that unties STDOUT. When the time comes, the filehandle will be untied, automatically invoking the class's DESTROY() method. This gives the object a chance to clean up, if it needs to. Note that the client connection will be closed before registered cleanups are run, so class DESTROY() methods should not attempt to send any data to the client. sub TIEHANDLE {
my($class, $r, $next) = @_;
bless { 'r' => $r, # request object
'next' => $next # next in the chain
}, $class;
}
The next routine to consider is TIEHANDLE(), whose job is to return a new blessed object. It creates a blessed hash containing the keys sub PRINT {
my $self = shift;
# Subclasses should do something interesting here
$self->forward(@_);
}
The PRINT() method is invoked whenever the caller wants to print something to the tied filehandle. The arguments consist of the blessed object and a list of data items to be processed. Subclasses will want to modify the data items in some way, but we just forward them unmodified to the next filter in line by calling an internal routine named forward(). #sub DESTROY {
# my $self = shift;
# # maybe clean up here
#}
DESTROY() is normally responsible for cleaning up. There's nothing to do in the general case, so we comment out the definition to avoid being called, saving a bit of overhead. sub forward {
shift()->{'next'}->PRINT(@_);
}
forward() is called by PRINT() to forward the modified data items to the next filter in line. We shift the blessed object off the argument stack, find the next filter in line, and invoke its PRINT() method. Example 4-22. A Chained Content Handler package Apache::Forward; use strict; use Apache::Constants qw(OK SERVER_ERROR); use vars qw($VERSION); $VERSION = '1.00'; sub handler ($$) {
my($class, $r) = @_;
my $next = tied *STDOUT || return SERVER_ERROR;
tie *STDOUT, $class, $r, $next or return SERVER_ERROR; sub PRINT {
my $self = shift;
# Subclasses should do something interesting here
$self->forward(@_);
}
#sub DESTROY {
# my $self = shift;
# # maybe clean up here
#}
sub forward {
shift()->{'next'}->PRINT(@_);
}
1; __END__ Having defined the filter base class, we can now define filters that actually do something. We'll show a couple of simple ones to give you the idea first, then create a larger module that does something useful. Apache::Upcase (Example 4-23) transforms everything it receives into uppercase letters. It inherits from Apache::Forward and then overrides the PRINT() method. PRINT() loops through the list of data items, calling uc() on each. It then forwards the modified data to the next filter in line by calling its forward() method (which we do not need to override). Example 4-23. Apache::Upcase Transforms Its Input into Uppercase package Apache::Upcase; use strict; use Apache::Forward (); use vars qw(@ISA $VERSION); @ISA = qw(Apache::Forward); $VERSION = '1.00'; sub PRINT {
my $self = shift;
$self->forward(map { uc $_ } @_);
}
1; __END__ Along the same lines, Example 4-24. A Handler that Removes Four-Letter Words package Apache::Censor;
use strict;
use Apache::Forward ();
se vars qw(@ISA $VERSION);
@ISA = qw(Apache::Forward);
$VERSION = '1.00';
sub PRINT {
my($self, @data) = @_;
foreach (@data) { s/\b(\w)\w{2}(\w)\b/$1**$2/g; } $self->forward(@data); } 1; __END__ To watch these filters in action, we need a data source. Here's a very simple content handler that emits a constant string. It is very important that the content be sent with a regular print() statement rather than the specialized $r->print() method. If you call Apache::print() directly, rather than through the tied STDOUT filehandle, you short-circuit the whole chain! package Apache::TestFilter; use strict; use Apache::Constants 'OK'; sub handler {
my $r = shift;
$r->content_type('text/plain');
$r->send_http_header;
print(<<END);
This is some text that is being sent out with a print()
statement to STDOUT. We do not know whether STDOUT is tied
to Apache or to some other source, and in fact it does not
really matter. We are just the content source. The filters
come later.
END
OK;
}
1;
__END__
The last step is to provide a suitable entry in the configuration file. The PerlHandler directive should declare the components of the pipeline in reverse order. As Apache works its way forward from the last handler in the pipeline to the first, each of the handlers unties and reties STDOUT. The last handler in the series is the one that creates the actual content. It emits its data using print() and the chained handlers do all the rest. Here's a sample entry: <Location /Filter> SetHandler perl-script PerlHandler Apache::Upcase Apache::Censor Apache::TestFilter </Location> Figure 4-11 shows the page that appears when the pipeline runs. Figure 4-11. The final output from three chained content handlers 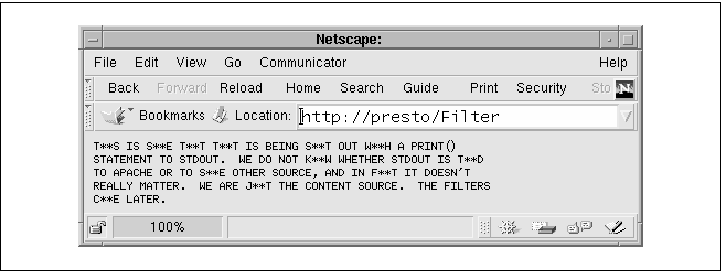 The last filter we'll show you is actually useful in its own right. When inserted into a filter pipeline, it compresses the data stream using the GZip protocol, and flags the browser that the data has been GZip-encoded by adding a Content-Encoding field to the HTTP header. Browsers that support on-the-fly decompression of GZip data will display the original document without any user intervention.5
This filter requires the
The filter is a little more complicated than the previous ones because GZip works best when the entire document is compressed in a single large segment. However, the filter will be processing a series of print() statements on data that is often as short as a single line. Although we could compress each line as a single segment, compression efficiency suffers dramatically. So instead we buffer the output, using Example 4-25 gives the complete code for Apache::GZip. Although it inherits its core functionality from Apache::Forward, each subroutine has to be tweaked a bit to support the unique requirements of GZip compression. package Apache::GZip; use strict; use Apache::Constants qw(:common); use Compress::Zlib qw(deflateInit crc32 MAX_WBITS Z_DEFLATED); use Apache::Forward (); use vars qw($VERSION @ISA); use constant GZIP_MAGIC => 0x1f8b; use constant OS_MAGIC => 0x03; $VERSION = '1.00'; @ISA = qw(Apache::Forward);
After the usual preamble, we import the compression routines from Compress::Zlib, and bring in the Apache::Forward class. We then define a couple of constants needed for the GZip header (in case you're wondering, we got these constants by looking at the sub handler ($$) {
my($class, $r) = @_;
#return DECLINED unless $r->header_in("Accept-Encoding") =~ /gzip/;
$r->content_encoding('gzip');
$class->SUPER::handler($r);
}
In order for the browser to automatically decompress the data, it needs to see a Content-Encoding field with the value The commented line that comes before the call to content_encoding() is an attempt to "do the right thing." Browsers are supposed to send a header named Accept-Encoding if they can accept compressed or otherwise encoded data formats. This line tests whether the browser can accept the GZip format and declines the transaction if it can't. Unfortunately, it turns out that many Netscape browsers don't transmit this essential header, so we skip the test.6 sub TIEHANDLE {
my $class = shift;
my $r = shift;
my $self = $class->SUPER::TIEHANDLE($r, @_);
my $d = deflateInit(-WindowBits => -MAX_WBITS()) || return;
@{$self}{'crc','d','l','h'} = (crc32(undef),$d,0,0);
$r->push_handlers(PerlHandler => sub { $self->flush });
return $self;
}
All the compression work is done in TIEHANDLE(), PRINT(),
and flush(). TIEHANDLE() begins by invoking the superclass's
handler() method to create an object blessed into the current class.
The method then creates a new Compress::Zlib deflation object by calling
deflateInit(), using an argument of sub gzheader {
pack("nccVcc", GZIP_MAGIC, Z_DEFLATED, 0,time,0, OS_MAGIC)
}
sub PRINT {
my $self = shift;
$self->forward(gzheader()) unless $self->{'h'}++;
foreach (@_) {
my $data = $self->{d}->deflate($_);
$self->{l} += length($_);
$self->{crc} = crc32($_, $self->{crc});
$self->forward($data);
}
}
The PRINT() method is called once each time the previous filter in the pipeline calls print(). It first checks whether the GZip header has already been sent, and sends it if not. The GZip header is created by the gzheader() routine and consists of a number of constants packed into a 10-byte string. It then passes each of its arguments to the deflation object's deflate() method to compress the information, then forwards whatever compressed data is returned to the next filter in the chain (or Apache, if this is the last filter). The subroutine also updates the running total of bytes compressed and calculates the CRC, using Compress::Zlib's crc32() subroutine. sub flush {
my $self = shift;
my $data = $self->{d}->flush;
return unless $self->{'h'};
$self->forward($data);
$self->forward(pack("V V", $self->{'crc'}, $self->{'l'}));
}
The flush() routine is called when the last of our chained handlers is run. Because Apache::GZip will usually go last in the filter chain, like this: <Location /Compressed> SetHandler perl-script PerlHandler Apache::GZip OneFilter AnotherFilter </Location> You can use Apache::GZip with any content handler that prints directly to STDOUT. Most of the modules given in this chapter send data via $r->print(). Simply delete the $r-> part to make them compatible with Apache::GZip and other chained content handlers. Example 4-25. A Handler That Compresses Its Input Before Forwarding It package Apache::GZip; use strict; use Apache::Constants qw(:common); use Compress::Zlib qw(deflateInit crc32 MAX_WBITS Z_DEFLATED); use Apache::Forward (); use vars qw($VERSION @ISA); use constant GZIP_MAGIC => 0x1f8b; use constant OS_MAGIC => 0x03; $VERSION = '1.00'; @ISA = qw(Apache::Forward); sub handler ($$) {
my($class, $r) = @_;
#return DECLINED unless $r->header_in("Accept-Encoding") =~ /gzip/; sub TIEHANDLE {
my $class = shift;
my $r = shift;
my $self = $class->SUPER::TIEHANDLE($r, @_);
my $d = deflateInit(-WindowBits => -MAX_WBITS()) || return;
@{$self}{'crc','d','l','h'} = (crc32(undef),$d,0,0);
$r->push_handlers(PerlHandler => sub { $self->flush });
return $self;
}
sub gzheader {
pack("nccVcc", GZIP_MAGIC, Z_DEFLATED, 0,time,0, OS_MAGIC)
}
sub PRINT {
my $self = shift;
$self->forward(gzheader()) unless $self->{'h'}++;
foreach (@_) {
my $data = $self->{d}->deflate($_);
$self->{l} += length($_);
$self->{crc} = crc32($_, $self->{crc});
$self->forward($data);
}
}
sub flush {
my $self = shift;
my $data = $self->{d}->flush;
return unless $self->{'h'};
$self->forward($data);
$self->forward(pack("V V", $self->{'crc'}, $self->{'l'}));
}
1; __END__ Readers who are interested in content handler pipelines should be aware of Jan Pazdziora's Apache::OutputChain module. It accomplishes the same thing as Apache::Forward but uses an object model that is less transparent than this one (among other things, the Apache::OutputChain module must always appear first on the PerlHandler list). You should also have a look at Andreas Koenig's Apache::PassFile and Apache::GZipChain modules. The former injects a file into an OutputChain and is an excellent way of providing the input to a set of filters. The latter implements compression just as Apache::GZip does but doesn't buffer the compression stream, losing efficiency when print() is called for multiple small data segments. Just as this book was going to press, Ken Williams announced Apache::Filter, a chained content handler system that uses a more devious scheme than that described here. Among the advantages of this system is that you do not have to list the components of the pipeline in reverse order. Show Contents Previous Page Next PageCopyright © 1999 by O'Reilly & Associates, Inc. |
