Show Contents Previous Page Next Page Chapter 4 - Content Handlers / Processing Input
Recall that after Apache parses an incoming URI to figure out what module to invoke, there may be some extra bits left over. This extra stuff becomes the "additional path information" and is available for your module to use in any way it wishes. Because it is hierarchical, the additional path information part of the URI follows all the same relative path rules as the rest of the URI. For example, Apache modules fetch additional path information by calling the request object's path_info() method. If desired, they can then turn the path information into a physical filename by calling lookup_uri(). An example of how additional path information can be used as a virtual document tree is shown in Example 4-11, which contains the code for Apache::TreeBrowser. This module generates a series of documents that are organized in a browseable tree hierarchy that is indistinguishable to the user from a conventional HTML file hierarchy. However, there are no physical files. Instead, the documents are generated from a large treelike Perl data structure that specifies how each "document" should be displayed. Here is an excerpt: 'bark'=>{
-title=>'The Wrong Tree',
-contents=>'His bark was worse than his bite.',
'smooth'=>{
-title=>'Like Butter',
-contents=>'As smooth as silk.'
},
'rough'=>{
-title=>'Ruffled',
-contents=>"Don't get rough with me."
},
}...
In this bit of the tree, a document named "bark" has the title "The Wrong Tree" and the contents "His bark was worse than his bite." Beneath this document are two subdocuments named "smooth" and "rough." The "smooth" document has the title "Like Butter" and the contents "As smooth as silk." The "rough" document is similarly silly. These subdocuments can be addressed with the additional path information /bark/smooth and /bark/rough, respectively. The parent document, naturally enough, is addressed by /bark. Within the module, we call each chunk of this data structure a "node." Using the information contained in the data structure, Apache::TreeBrowser constructs the document and displays its information along with a browseable set of links organized in hierarchical fashion (see Figure 4-5). As the user moves from document to document, the currently displayed document is highlighted--sort of a hierarchical navigation bar! Figure 4-5. Apache::TreeBrowser creates a hierarchical navigation tree. 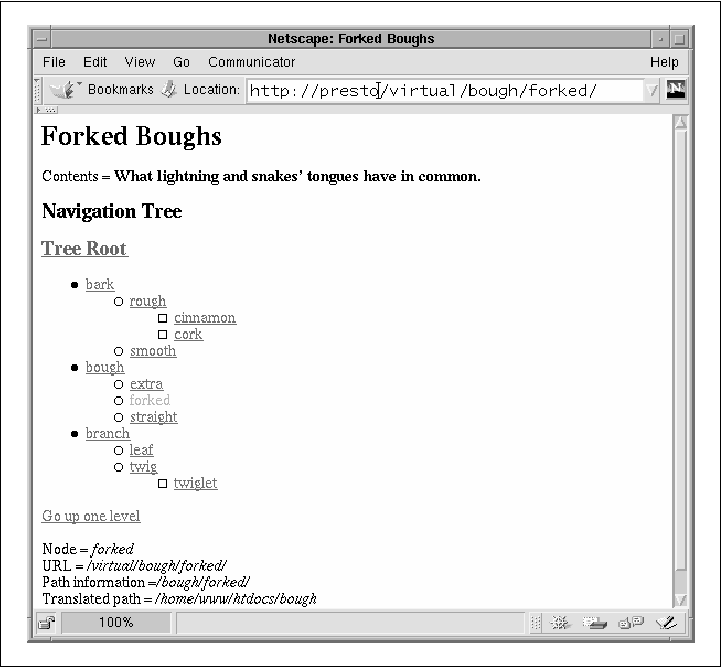 The source code listing is long, so we'll run through it a chunk at a time: package Apache::TreeBrowser; use strict; use Apache::Constants qw(:common REDIRECT); my $TREE = make_tree(); sub handler {
my $r = shift;
The module starts by importing the usual Apache constants and the my $path_info = $r->path_info; my $path_translated = $r->lookup_uri($path_info)->filename; my $current_uri = $r->uri; Now's the time to process the additional path information. The handler fetches the path information by calling the request object's path_info() method and fetches the module's base URI by calling uri(). Even though we won't be using it, we transform the additional path information into a physical pathname by calling lookup_uri() and filename(). This is useful for seeing how Apache does URI translation. unless ($path_info) {
$r->header_out(Location => "$current_uri/");
return REDIRECT;
}
For this module to work correctly, some additional path information has to be provided, even if it's only a $r->content_type('text/html');
$r->send_http_header;
return OK if $r->header_only;
my($junk, @components) = split "/", $path_info;
# follow the components down
my($node, $name) = ($TREE, '');
foreach (@components) {
last unless $node->{$_};
$name = $_;
$node = $node->{$_};
}
At this point we begin to construct the document. We set the content type to text/html, send out the HTTP header, and exit if header_only() returns true. Otherwise, we split the path information into its components and then traverse the tree, following each component name until we either reach the last component on the list or come to a component that doesn't have a corresponding entry in the tree (which sometimes happens when users type in the URI themselves). By the time we reach the end of the tree traversal, the variable $r->print(<<END);
<HTML>
<HEAD>
<TITLE>$node->{-title}</TITLE>
</HEAD>
<BODY BGCOLOR="white">
<H1>$node->{-title}</H1>
Contents = <b>$node->{-contents}</b>
<H2>Navigation Tree</H2>
END
my $prefix = "../" x @components;
print $prefix ?
qq(<H3><A HREF="$prefix">Tree Root</A></H3>\n) :
qq(<H3><FONT COLOR="red">Tree Root</FONT></H3>);
We now call print() to print out the HTML document. We first display the current document's title and contents. We then print a hyperlink that points back to the "root" (really the top level) of the tree. Notice how we construct this link by creating a relative URI based on the number of components in the additional path information. If the additional path information is currently print_node('', $TREE, $node, $prefix);
print qq(<A HREF="../">Go up one level</A><P>) if $name;
The next task is to construct the hierarchical navigation system shown in
Figure 4-5. We do this by calling print_node(),
an internal function. This is followed by a link to the next-higher document,
which is simply the relative path $r->print(<<END); Node = <EM>$name</EM><br> URI = <EM>$current_uri</EM><br> Path information =<EM>$path_info</EM><br> Translated path = <EM>$path_translated</EM> </BODY> </HTML> END return OK; } Last, we print out some more information about the current document, including the internal name of the document, the current URI, the additional path information, and the translated path information. Let's now look at the print_node() subroutine: sub print_node {
my ($name, $node, $current, $prefix) = @_;
my (@branches) = grep !/^-/, sort keys %$node;
if ($name) {
# print the node itself
print $node != $current ?
qq(<LI><A HREF="$prefix$name/">$name</A></LI>\n) :
qq(<LI><FONT COLOR="red">$name</FONT></LI>\n);
# print branches underneath it
$prefix .= "$name/";
}
return unless @branches;
print "<UL>\n";
foreach (@branches) {
print_node($_, $node->{$_}, $current, $prefix);
}
print "</UL>\n";
}
This subroutine is responsible for displaying a tree node as a nested list. It starts by finding all the branches beneath the requested node, which just happens to be all the hash keys that don't begin with a hyphen. It then prints out the name of the node. If the node being displayed corresponds to the current document, the name is surrounded by <FONT> tags to display it in red. Otherwise, the node name is turned into a hyperlink that points to the appropriate document. Then, for each subdocument beneath the current node, it invokes itself recursively to display the subdocument. The most obscure part of this subroutine is the need to append a
The last function in this module is make_tree(). It simply reads in the text following the sub make_tree {
local $/;
my $data = <DATA>;
eval $data;
}
1; __DATA__ Example 4-11. Using Path Information to Browse a Tree package Apache::TreeBrowser; # file: Apache/TreeBrowser.pm use strict; use Apache::Constants qw(:common REDIRECT); my $TREE = make_tree(); sub handler {
my $r = shift;
my $path_info = $r->path_info;
my $path_translated = $r->lookup_uri($path_info)->filename;
my $current_uri = $r->uri;
unless ($path_info) {
$r->header_out(Location => "$current_uri/");
return REDIRECT;
}
$r->content_type('text/html');
$r->send_http_header;
return OK if $r->header_only;
my($junk, @components) = split "/", $path_info;
# follow the components down
my($node, $name) = ($TREE, '');
foreach (@components) {
last unless $node->{$_};
$name = $_;
$node = $node->{$_};
}
$r->print(<<END);
<HTML>
<HEAD>
<TITLE>$node->{-title}</TITLE>
</HEAD>
<BODY BGCOLOR="white">
<H1>$node->{-title}</H1>
Contents = <b>$node->{-contents}</b>
<H2>Navigation Tree</H2> END my $prefix = "../" x @components;
print $prefix ?
qq(<H3><A HREF="$prefix">Tree Root</A></H3>\n) :
qq(<H3><FONT COLOR="red">Tree Root</FONT></H3>);
print_node('', $TREE, $node, $prefix);
print qq(<A HREF="../">Go up one level</A><P>) if $name;
$r->print(<<END); Node = <EM>$name</EM><br> URI = <EM>$current_uri</EM><br> Path information =<EM>$path_info</EM><br> Translated path = <EM>$path_translated</EM> </BODY> </HTML> END return OK; } sub print_node {
my ($name, $node, $current, $prefix) = @_;
my (@branches) = grep !/^-/, sort keys %$node;
if ($name) {
# print the node itself
print $node != $current ?
qq(<LI><A HREF="$prefix$name/">$name</A></LI>\n) :
qq(<LI><FONT COLOR="red">$name</FONT></LI>\n);
# print branches underneath it
$prefix .= "$name/";
}
return unless @branches;
print "<UL>\n";
foreach (@branches) {
print_node($_, $node->{$_}, $current, $prefix);
}
print "</UL>\n";
}
# create a sample tree to browse
sub make_tree {
local $/;
my $data = <DATA>;
eval $data;
}
__DATA__
return {
-title => 'The Root of All Evil',
-contents => 'And so it begins...',
'bark' => {
-title => 'The Wrong Tree',
-contents => 'His bark was worse than his bite.',
'smooth' => {
-title => 'Like Butter',
-contents => 'As smooth as silk.',
},
'rough' => {
-title => 'Ruffled',
-contents => "Don't get rough with me.",
'cork' => {
-title => 'Corked',
-contents => "Corks don't grow on trees...or do they?",
},
'cinnamon' => {
-title => 'The Cinnamon Tree',
-contents => 'Little bird, little bird in the cinnamon tree...', },
}
},
'bough' => {
-title => 'Stealing a Bough',
-contents => "I've taken a bough of silence.",
'forked' => {
-title => 'Forked Boughs',
-contents => 'What lightning and snakes\' tongues have in common.',
},
'straight' => {
-title => 'Single Boughs',
-contents => 'Straight, but not narrow.',
},
'extra' => {
-title => 'Take a Bough',
-contents => 'Nothing beats that special feeling,
when you are stealing that extra bough!',
},
},
'branch' => {
-title => 'The Branch Not Taken',
-contents => 'Branch or be branched.',
'twig' => {
-title => 'Twiggy',
-contents => 'Anorexia returns!',
'twiglet' => {
-title => 'The Leastest Node',
-contents => 'Winnie the Pooh, Eeyore, and Twiglet.',
},
},
'leaf' => {
-title => 'Leaf me Alone!',
-contents => 'Look back, Leaf Ericksonn.',
}
},
}
Here is a sample configuration file entry to go with <Location /virtual> SetHandler perl-script PerlHandler Apache::TreeBrowser </Location>Show Contents Previous Page Next Page Copyright © 1999 by O'Reilly & Associates, Inc. |
