Show Contents Previous Page Next Page Chapter 4 - Content Handlers In this section...
You can make the virtual documents generated by the Apache API interactive in exactly the way that you would documents generated by CGI scripts. Your module will generate an HTML form for the user to fill out. When the user completes and submits the form, your module will process the parameters and generate a new document, which may contain another fill-out form that prompts the user for additional information. In addition, you can store information inside the URI itself by placing it in the additional path information part. Show Contents Go to Top Previous Page Next Page
When a fill-out form is submitted, the contents of its fields are turned into a series of name=value parameter pairs that are available for your module's use. Unfortunately, correctly processing these parameter pairs is annoying because, for a number of historical reasons, there are a variety of formats that you must know about and deal with. The first complication is that the form may be submitted using either the HTTP GET or POST method. If the GET method is used, the URI encoded parameter pairs can be found separated by ampersands in the "query string," the part of the URI that follows the http:////?=&=&=...
To recover the parameters from a GET request, If the client uses the POST method to submit the fill-out form, the parameter pairs can be found in something called the "client block." C API users must call three functions named setup_client_block(), should_client_block(), and get_client_block() in order to retrieve the information.
While these methods are also available in the Perl API, To show you the general technique for prompting and processing user input,
Example 4-10 gives a new version of Figure 4-4. The Apache::Hello2 module can process user input. 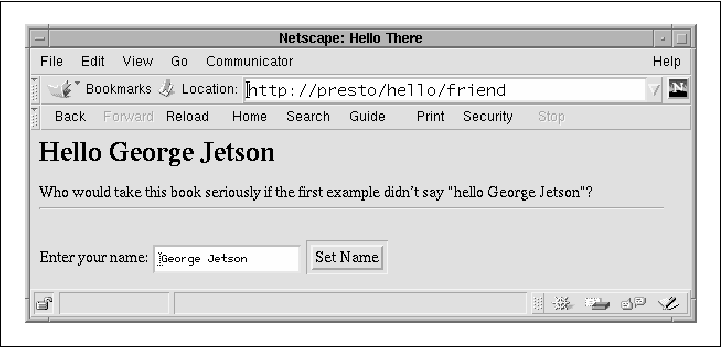
The code is very simple. On entry to handler() the module calls the request object's method() method to determine whether the handler was invoked using a POST request, or by some other means (usually GET). If the POST method was used, the handler calls the request object's content() method to retrieve the posted parameters. Otherwise, it attempts to retrieve the information from the query string by calling args(). The parsed name=value pairs are now stuffed into a hash named Having processed the user input, if any, the handler retrieves the value of the user_name parameter from the hash and stores it in a variable. If the parameter is empty, we default to "Unknown User." The next step is to generate the document. We set the content type to text/html as before and emit the HTTP header. We again call the request object's header_only() to determine whether the client has requested the entire document or just the HTTP header information. This is followed by a single long Apache::print() statement. We create the HTML header and body, along with a suitable fill-out form. Notice that we use the current value of the user name variable to initialize the appropriate text field. This is a frill that we have always thought was kind of neat. Example 4-10. Processing User Input with the Apache Perl API package Apache::Hello2; # file: Apache/Hello2.pm use strict; use Apache::Constants qw(:common); sub handler {
my $r = shift;
my %params = $r->method eq 'POST' ? $r->content : $r->args;
my $user_name = $params{'user_name'} || 'Unknown User';
$r->content_type('text/html');
$r->send_http_header;
return OK if $r->header_only;
$r->print(<<END); <HTML> <HEAD> <TITLE>Hello There</TITLE> </HEAD> <BODY> <H1>Hello $user_name</H1> Who would take this book seriously if the first example didn\'t say "hello $user_name"? <HR> <FORM METHOD="POST"> Enter your name: <INPUT TYPE="text" NAME="user_name" VALUE="$user_name"> return OK; } 1; __END__
A <Location /hello/friend> SetHandler perl-script PerlHandler Apache::Hello2 </Location> This method of processing user input is only one of several equally valid alternatives. For example, you might want to work with query string and POSTed parameters simultaneously, to accommodate this type of fill-out form: <FORM ACTION="/hello/friend?day=saturday" METHOD="POST"> <INPUT TYPE="text" NAME="user_name"> <INPUT TYPE="submit"> </FORM> In this case, you could recover the values of both the day and user_name parameters using a code fragment like this one: my %params = ($r->args, $r->content); If the same parameter is present in both the query string and the POSTed values, then the latter will override the former. Depending on your application's logic, you might like this behavior. Alternatively, you could store the two types of parameter in different places or take different actions depending on whether the parameters were submitted via GET or POST. For example, you might want to use query string parameters to initialize the default values of the fill-out form and enter the information into a database when a POST request is received. When you store the parsed parameters into a hash, you lose information about parameters that are present more than once. This can be bad if you are expecting multivalued parameters, such as those generated by a selection list or a series of checkboxes linked by the same name. To keep multivalued information, you need to do something like this: my %params;
my @args = ($r->args, $r->content);
while (my($name,$value) = splice @args,0,2) {
push @{$params{$name}}, $value;
}
This bit of code aggregates the GET and POST parameters into a single array named vegetable=kale&vegetable=broccoli&vegetable=carrots you can recover the complete vegetable list in this manner: @vegetables = @{$params{'vegetable'}};
An alternative is to use a module that was still in development at the time this chapter was written. This module, named Apache::Request, uses the CGI.pm-style method calls to process user input but does so efficiently by going directly to the request object. With this module, the user input parameters are retrieved by calling param(). Call param() without any arguments to retrieve a list of all the parameter names. Call param() with a parameter name to return a list of the values for that parameter in an array context, and the first member of the list in a scalar context. Unlike the vanilla request object, input of type multipart/form-data is handled correctly, and uploaded files can be recovered too (using the same API as CGI.pm). To take advantage of Apache::Request in our "Hello World" module, we modify the top part of the module to read as follows: package Apache::Hello3; # file: Apache/Hello3.pm use strict; use Apache::Constants qw(:common); use Apache::Request; sub handler {
my $r = Apache::Request->new(shift);
my $user_name = $r->param('user_name') || 'Unknown User';
$r->content_type('text/html');
$r->print(<<END);
Who cares if every single example
says "Hello World"???!
END
;
...
The main detail here is that instead of retrieving the request object directly, we wrap it inside an Like CGI.pm, Apache::Request allows you to handle browser file uploading, although it is somewhat different in detail from the interface provided in CGI.pm versions 2.46 and lower (the two libraries have been brought into harnony in Version 2.47). As in ordinary CGI, you create a file upload field by defining an <INPUT> element of type "file" within a <FORM> section of type "multipart/form-data". After the form is POSTed, you retrieve the file contents by reading from a filehandle returned by the Apache::Request upload() method. This code fragment illustrates the technique: my $r = Apache::Request->new(shift);
my $moose = 0;
my $uploaded_file = $r->upload('uploaded-file');
my $uploaded_name = $r->param('uploaded-file');
while (<$uploaded_file>) {
$moose++ if /moose/;
}
print "$moose moose(s) found in $uploaded_name\n";
Show Contents Go to Top Previous Page Next PageCopyright © 1999 by O'Reilly & Associates, Inc. |
