Show Contents Previous Page Next Page Chapter 3 - The Apache Module Architecture and API In this section...
Apache's life cycle is straightforward (Figure 3-2). It starts up, initializes, forks off several copies of itself (on Unix systems only), and then enters a loop in which it processes incoming requests. When it is done, Apache exits the loop and shuts itself down. Most of the interesting stuff happens within the request loop, but both Perl and C-language modules can intervene at other stages as well. They do so by registering short code routines called "handlers" that Apache calls at the appropriate moment.4 A phase may have several handlers registered for it, a single handler, or none at all. If multiple modules have registered their interest in handling the same phase, Apache will call them in the reverse order in which they registered. This in turn will depend on the order in which the modules were loaded, either at compile time or at runtime when Apache processes its LoadModule directives. If no module handlers are registered for a phase, it will be handled by a default routine in the Apache core. Figure 3-2. The Apache server life cycle 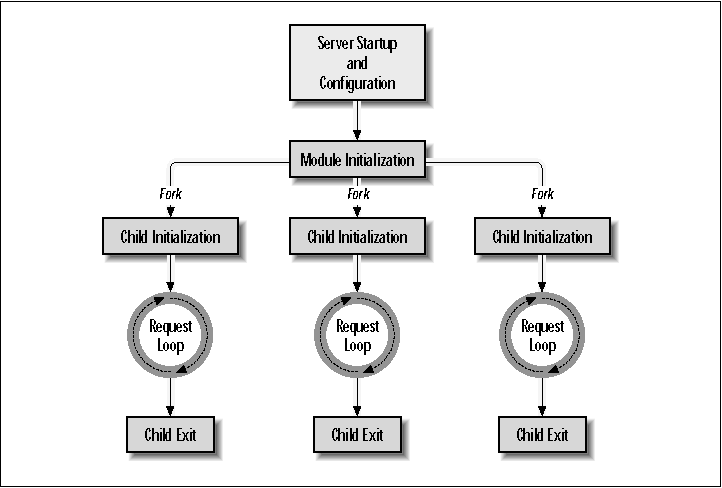 Server Startup and Configuration Show Contents Go to Top Previous Page Next PageWhen the server is started, Apache initializes globals and other internal resources and parses out its command-line arguments. It then locates and parses its various configuration files. The configuration files may contain directives that are implemented by external modules. Apache parses each directive according to a prototype found in the command table that is part of each module and passes the parsed information to the module's configuration-handling routines. Apache processes the configuration directives on a first-come, first-serve basis, so in certain cases, the order in which directives appear is important. For example, before Apache can process a directive that is implemented by a module configured as a dynamically shared object, that module must be pulled in with the LoadModule directive. The process of module configuration is actually somewhat complex because Apache recognizes multiple levels of configuration directives, including global directives, directives that are specific for a particular virtual host, and directives that apply only to a particular directory or partial URI. We defer the full discussion of this topic to Chapters 9, 10, and 11. Once Apache has processed the configuration files, it knows the location of the various log files. It opens each configured log file, such as ErrorLog and TransferLog. Apache then writes its PID to the file indicated by the PidFile directive. The file indicated by the ErrorLog directive is slightly special.
After Apache opens the ErrorLog file, it closes the existing Apache will usually be started as root (on Unix systems), so that it can open port 80. This also allows it to open log files that are owned by root. Later, Apache will normally fork multiple child processes which will run under an unprivileged user ID. By virtue of having a copy of the still-open log file descriptors, child processes will have write access to the log files, even though their privileges wouldn't ordinarily give them this right. Show Contents Go to Top Previous Page Next Page
Next, Apache initializes its modules. Each module has an initialization routine that is passed information about the server in a data structure called a Perl module authors can step in at the module initialization phase by using
the PerlRequire and PerlModule directives.5
These directives both cause a Perl script to be evaluated at When the server is restarted, the configuration and module initialization phases are called again. To ensure that such restarts will be uneventful, Apache actually runs these two phases twice during server startup just to check that all modules can survive a restart. Show Contents Go to Top Previous Page Next PageOn Unix systems Apache now forks itself one or more times to create a set of child processes that will do the actual work of accepting incoming requests. Before accepting any connections, the child processes immediately set their user and group IDs to those of an unprivileged user (such as "nobody" or "guest"). The original parent process (still running as root) hangs around to monitor the status of its children and to launch new ones should the number of child processes drop below a specified level. Just before each child enters its request loop, each module is given another chance at initialization. Although this would seem redundant with the module initialization phase, it's necessary because some data structures, such as database handles, are not stable across forks. Modules that need to (re)initialize themselves get another chance every time a new child process is created. You might also want to use this phase to perform some action that should be done as an unprivileged user. In the C API, the module's child_init() function is called. In the Perl API, you can install a handler for this phase using the PerlChildInitHandler directive. Chapter 7, Other Request Phases, discusses the use of child init handlers in more detail. Show Contents Go to Top Previous Page Next PageWe'll skip forward now to the child exit phase, leaving the request loop for detailed consideration in the next section. After processing some number of requests, each child process will eventually exit, dying either a natural death when it reaches the limit set by MaxRequestsPerChild or because the server as a whole has received a restart or termination request. Under ordinary circumstances, the child will call each module's child_exit handler, giving it a chance to clean up after itself before the process disappears. The module can commit database transactions, close files, or do whatever else it needs to. Perl API modules can install a handler for this phase by declaring a PerlChildExitHandler in the configuration file. Examples of putting this to use are given in Chapter 7. The child exit routine is not guaranteed to be called in all cases. If the child exits because of a server crash or other untrappable errors, your routine may never be called. Show Contents Go to Top Previous Page Next PageBetween the initialization/configuration phase and the exit phase is the request loop (shown in Figure 3-3). This is where the server and its modules spend most of their time as they wait for incoming requests. Here's where the fun begins. Figure 3-3. The Apache request. The main transaction path is shown in black, and the path taken when a handler returns an error is shown in gray. Phases that you are most likely to write handlers for are shown in bold. 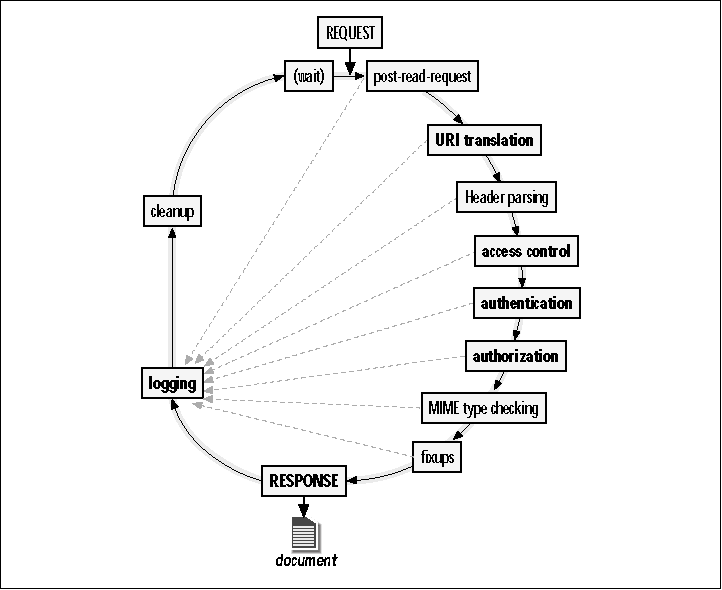 The Apache server core handles the most common aspects of an HTTP conversation: listening for a request, parsing the incoming request line and headers, and composing the outgoing HTTP response message. Each time through the request loop, there are a variety of decisions to make about the incoming request. External modules can define custom handlers to enhance or supersede each decision. If no handler is defined, Apache falls back to its default behavior. Here are the eight decisions that Apache makes for each request:
The requested URI could refer to a physical file, a virtual document produced on the fly by an external script, or a document generated by an internal module. The server needs to have an early idea of what the URI maps to before other questions can be asked and answered. Apache's default translation routines use directives including Alias, ScriptAlias, and DocumentRoot to translate the URI into a file path. External modules, such as the optional Rewrite module, can seize control during this phase to perform more sophisticated translations.
Some documents are restricted by the server's configuration so that not everybody has the right to retrieve them. These three decisions, described in more detail in Chapter 6, determine who can get access to the document.
This step derives a preliminary guess of the requested document's MIME type. Because certain documents (such as CGI scripts and image map files) need to be processed differently than run-of-the-mill static HTML files, the MIME type checking phase must be run before Apache can figure out how to process the document. The server's configuration file determines how it makes this decision. The decision may be based on the document's filename, file extension, or location in the document tree. After type-mapping is done, Apache uses this information to select the "content handler" to generate or transmit the document itself during the response phase.
If Apache decides that an extension module should handle the content generation, the document's URI and all the information accumulated about the document so far are passed to the appropriate module. For historical reasons, the handler responsible for the response phase is known as the "content handler." The content handler will usually begin by adjusting the HTTP response header to suit its needs. For example, it may change the document's content type from the default value provided by the MIME type checking step. It will then tell Apache to send the (possibly modified) HTTP header to the client. After the header is sent, the module will usually create the content of the document itself and forward it to the client. This may involve reading a static file from disk or creating the document from scratch. Sometimes content handlers will fail for one reason or another, in which case they must return the appropriate error code to Apache so that the server can inform the user.
Whether the content handler's response is a pretty image, a fancy HTML page, or an error of some sort, the outcome should be logged. Apache provides a default logging system that writes to flat files. It is also possible to install a custom log handler to do customized logging, such as writing log entries into a relational database.
Finally, the request is over, and there may be some tidying up left to do. Modules may register cleanup handlers to deallocate resources they allocated earlier, close databases, free memory, and so forth. This phase is distinct from the child exit phase that we described earlier. Whereas the child exit phase happens once per child process, the request cleanup phase happens after each and every transaction. Show Contents Go to Top Previous Page Next PageCopyright © 1999 by O'Reilly & Associates, Inc. |
